【Datawhale动手学数据分析笔记】第一章 数据加载及探索性数据分析

第一章:数据加载
1.1 载入数据
数据集下载 https://www.kaggle.com/c/titanic/overview
1.1.1 导入numpy和pandas
import numpy as np
import pandas as pd
如果环境中没有安装numpy或者pandas,需要执行以下命令安装
pip install numpy
pip install pandas
1.1.2 载入数据
(1) 使用相对路径载入数据
df = pd.read_csv('train.csv')
df.head(3)
(2) 使用绝对路径载入数据
df = pd.read_csv('/code/hands-on-data-analysis/第一单元项目集合/train.csv') #此处填写绝对路径
df.head(3)
以上两段代码的运行结果如下:
 特别提示:如果不知道当前文件绝对路径的话可以使用以下代码:
特别提示:如果不知道当前文件绝对路径的话可以使用以下代码:
import os
os.getcwd()
运行结果:
/code/hands-on-data-analysis/第一单元项目集合
加载的数据是所有工作的第一步,我们的工作会接触到不同的数据格式(eg:.csv;.tsv;.xlsx),但是加载的方法和思路都是一样的,在以后工作和做项目的过程中,遇到之前没有碰到的问题,要多多查资料吗,使用google了解业务逻辑,明白输入和输出是什么。
1.1.3 每1000行为一个数据模块,逐块读取
chunker = pd.read_csv('train.csv', chunksize=1000)
1.1.4 将表头改成中文,索引改为乘客ID [对于某些英文资料,我们可以通过翻译来更直观的熟悉我们的数据]
PassengerId => 乘客ID
Survived => 是否幸存
Pclass => 乘客等级(1/2/3等舱位)
Name => 乘客姓名
Sex => 性别
Age => 年龄
SibSp => 堂兄弟/妹个数
Parch => 父母与小孩个数
Ticket => 船票信息
Fare => 票价
Cabin => 客舱
Embarked => 登船港口
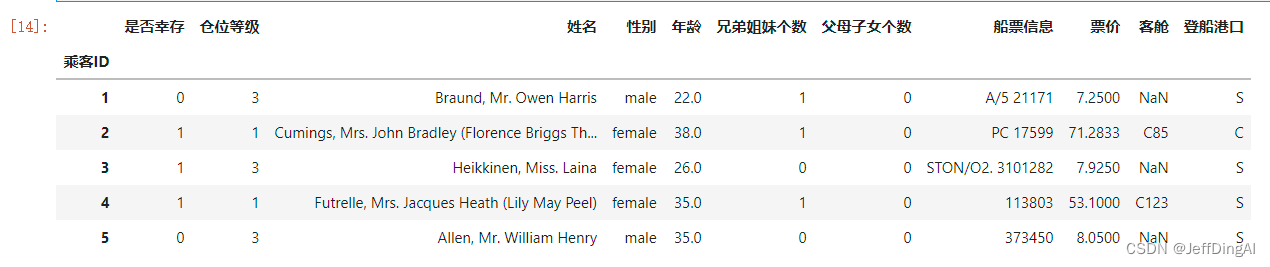
df = pd.read_csv('train.csv', names=['乘客ID','是否幸存','仓位等级','姓名','性别','年龄','兄弟姐妹个数','父母子女个数','船票信息','票价','客舱','登船港口'],index_col='乘客ID',header=0)
df.head()
运行结果:
1.2 初步观察
导入数据后,你可能要对数据的整体结构和样例进行概览,比如说,数据大小、有多少列,各列都是什么格式的,是否包含null等
1.2.1 查看数据的基本信息
df.info()
运行结果:
<class 'pandas.core.frame.DataFrame'>
Int64Index: 891 entries, 1 to 891
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 是否幸存 891 non-null int64
1 仓位等级 891 non-null int64
2 姓名 891 non-null object
3 性别 891 non-null object
4 年龄 714 non-null float64
5 兄弟姐妹个数 891 non-null int64
6 父母子女个数 891 non-null int64
7 船票信息 891 non-null object
8 票价 891 non-null float64
9 客舱 204 non-null object
10 登船港口 889 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 83.5+ KB
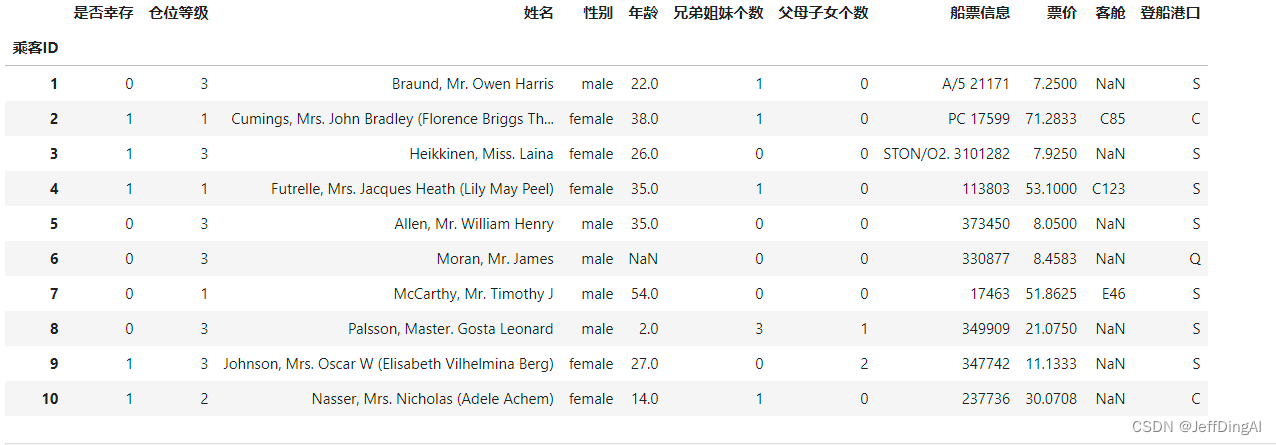
1.2.2 观察表格前10行的数据和后15行的数据
df.head(10) #查看表格前10行数据
运行结果:
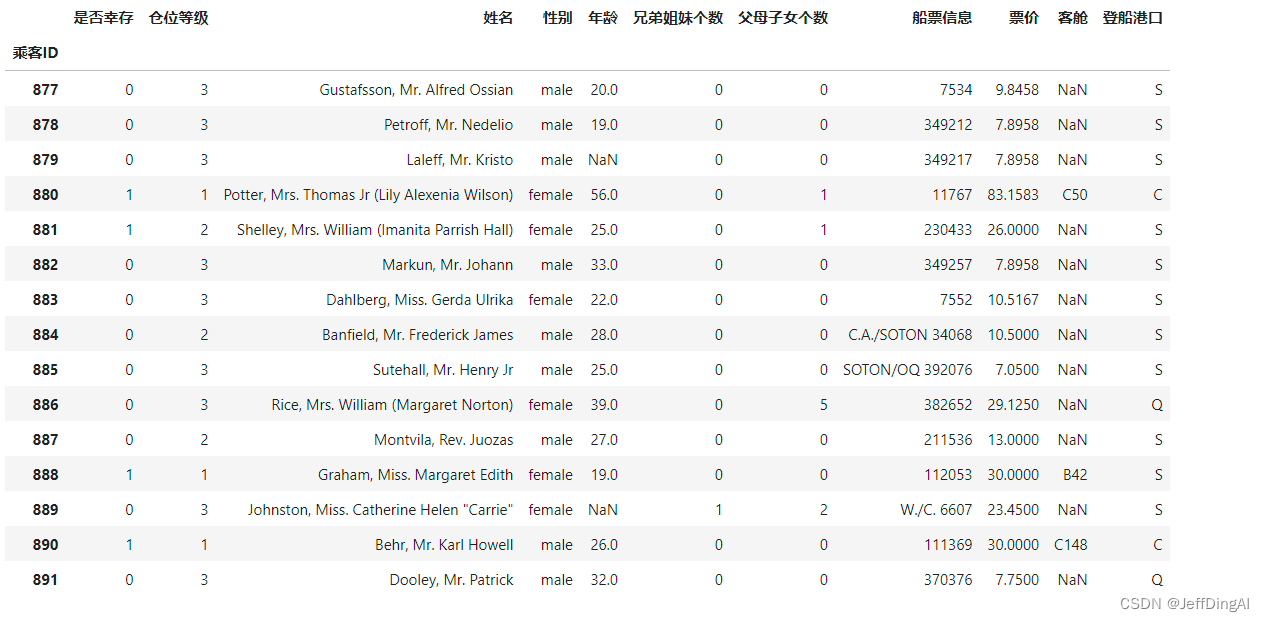
df.tail(15)#查看表格后15行数据
运行结果:
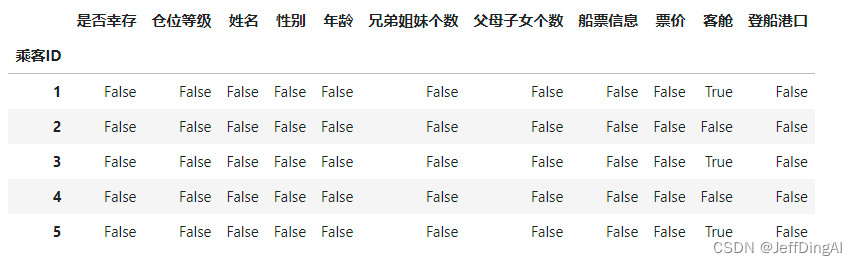
1.2.4 判断数据是否为空,为空的地方返回True,其余地方返回False
df.isnull().head()
运行结果:
上面的操作都是数据分析中对于数据本身的观察
1.3 保存数据
将你加载并做出改变的数据,在工作目录下保存为一个新文件train_chinese.csv
# 注意:不同的操作系统保存下来可能会有乱码。大家可以加入`encoding='GBK' 或者 ’encoding = ’utf-8‘‘`
df.to_csv('train_chinese.csv')
数据的加载以及入门,接下来就要接触数据本身的运算,我们将主要掌握numpy和pandas在工作和项目场景的运用。
数据分析的第一步,加载数据我们已经学习完毕了。当数据展现在我们面前的时候,我们所要做的第一步就是认识他,今天我们要学习的就是了解字段含义以及初步观察数据。
1.4 知道你的数据叫什么
我们学习pandas的基础操作,那么上一节通过pandas加载之后的数据,其数据类型是什么呢?
1.4.1 pandas中有两个数据类型DateFrame和Series,通过查找简单了解他们。然后自己写一个关于这两个数据类型的小例子
#使用Series
sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000}
example_1 = pd.Series(sdata)
example_1
运行结果:
Ohio 35000
Texas 71000
Oregon 16000
Utah 5000
dtype: int64
#使用DataFrame
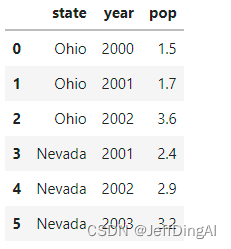
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002, 2003],'pop': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2]}
example_2 = pd.DataFrame(data)
example_2
运行结果:
1.4.2 载入"train_chinese.csv"文件
df = pd.read_csv('train_chinese.csv')
df.head(3)
运行结果:

1.4.3 查看DataFrame数据的每列的名称
df.columns
运行结果:
Index(['乘客ID', '是否幸存', '仓位等级', '姓名', '性别', '年龄', '兄弟姐妹个数', '父母子女个数', '船票信息',
'票价', '客舱', '登船港口'],
dtype='object')
1.4.4 查看"Cabin"这列的所有值 [有多种方法]
#方法一:
df['客舱'].head(3)
df.客舱.head(3)
运行结果:
0 NaN
1 C85
2 NaN
Name: 客舱, dtype: object
1.4.5 加载文件"test_1.csv",然后对比"train.csv",看看有哪些多出的列,然后将多出的列删除
test_1 = pd.read_csv('test_1.csv')
test_1.head(3)
运行结果:
](https://img-blog.csdnimg.cn/f86edc61f08546c3aab4b54d9723afc0.png)
# 删除多余的列
del test_1['a']
test_1.head(3)
运行结果:

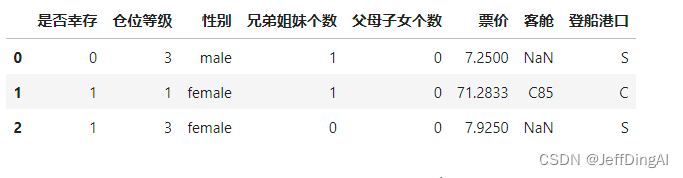
1.4.6 将[‘乘客ID’,‘姓名’,‘年龄’,‘船票信息’]这几个列元素隐藏,只观察其他几个列元素
df.drop(['乘客ID','姓名','年龄','船票信息'],axis=1).head(3)
运行结果:
如果想要完全的删除你的数据结构,使用inplace=True,因为使用inplace就将原数据覆盖了,所以这里没有用
1.5 筛选的逻辑
表格数据中,最重要的一个功能就是要具有可筛选的能力,选出我所需要的信息,丢弃无用的信息。
下面我们还是用实战来学习pandas这个功能。
1.5.1 我们以"年龄"为筛选条件,显示年龄在10岁以下的乘客信息。
df[df["年龄"]<10].head(3)
运行结果:

1.5.2 以"年龄"为条件,将年龄在10岁以上和50岁以下的乘客信息显示出来,并将这个数据命名为midage
midage = df[(df["年龄"]>10)& (df["年龄"]<50)]
midage.head(3)

1.5.3 将midage的数据中第100行的"仓位等级"和"性别"的数据显示出来
midage = midage.reset_index(drop=True)
midage.head(3)
运行结果:

reset_index()的作用
数据清洗时,会将带空值的行删除,此时DataFrame或Series类型的数据不再是连续的索引,可以使用reset_index()重置索引。
midage.loc[[100],['仓位等级','性别']]
运行结果:

1.5.4 使用loc方法将midage的数据中第100,105,108行的"仓位等级","姓名"和"性别"的数据显示出来
midage.loc[[100,105,108],['仓位等级','姓名','性别']]

1.5.5 使用iloc方法将midage的数据中第100,105,108行的"仓位等级","悉姓名"和"性别"的数据显示出来
midage.iloc[[100,105,108],[2,3,4]]

数据的加载以及入门,接下来就要接触数据本身的运算,我们将主要掌握numpy和pandas在工作和项目场景的运用。
探索性数据分析
数据准备
#载入之前保存的train_chinese.csv数据,关于泰坦尼克号的任务,我们就使用这个数据
text = pd.read_csv('train_chinese.csv')
text.head()

1.6了解你的数据
1.6.1 利用Pandas对示例数据进行排序,要求升序
#自己构建一个都为数字的DataFrame数据
frame = pd.DataFrame(np.arange(8).reshape((2, 4)),
index=['2', '1'],
columns=['d', 'a', 'b', 'c'])
frame
运行结果:

【代码解析】
pd.DataFrame() :创建一个DataFrame对象
np.arange(8).reshape((2, 4)) : 生成一个二维数组(2*4),第一列:0,1,2,3 第二列:4,5,6,7
index=['2, 1] :DataFrame 对象的索引列
columns=[‘d’, ‘a’, ‘b’, ‘c’] :DataFrame 对象的索引行
# 大多数时候我们都是想根据列的值来排序,所以,将你构建的DataFrame中的数据根据某一列,升序排列
frame.sort_values(by='c', ascending=True)
运行结果:

可以看到sort_values这个函数中by参数指向要排列的列,ascending参数指向排序的方式(升序还是降序)
总结一下不同的排序方式
# 让行索引升序排序
frame.sort_index()
运行结果:

# 让列索引升序排序
frame.sort_index(axis=1)
运行结果:

# 让列索引降序排序
frame.sort_index(axis=1, ascending=False)
运行结果:

# 让任选两列数据同时降序排序
frame.sort_values(by=['a', 'c'], ascending=False)
运行结果:

1.6.2 对泰坦尼克号数据(trian.csv)按票价和年龄两列进行综合排序(降序排列),从数据中你能发现什么
'''
在开始我们已经导入了train_chinese.csv数据,而且前面我们也学习了导入数据过程,根据上面学习,我们直接对目标列进行排序即可
head(20) : 读取前20条数据
'''
text.sort_values(by=['票价', '年龄'], ascending=False).head(3)
运行结果:

1.6.3 利用Pandas进行算术计算,计算两个DataFrame数据相加结果
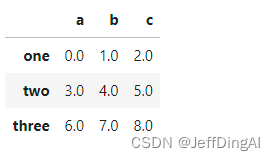
#建立一个例子
frame1_a = pd.DataFrame(np.arange(9.).reshape(3, 3),
columns=['a', 'b', 'c'],
index=['one', 'two', 'three'])
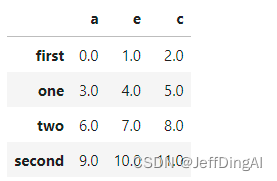
frame1_b = pd.DataFrame(np.arange(12.).reshape(4, 3),
columns=['a', 'e', 'c'],
index=['first', 'one', 'two', 'second'])
frame1_a的结果:
frame1_b的结果:
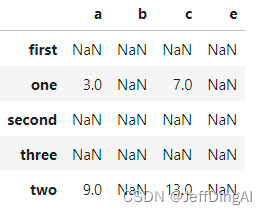
#将frame_a和frame_b进行相加
frame1_a + frame1_b
#将frame_a和frame_b进行相乘
frame1_a * frame1_b
运行结果:
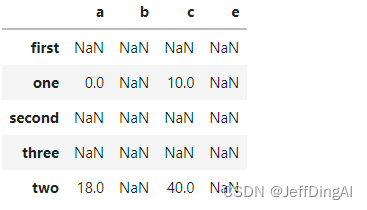
【提醒】两个DataFrame运算之后,会返回一个新的DataFrame,对应的行和列的值会进行运算,没有对应的会变成空值NaN。
当然,DataFrame还有很多算术运算,如减法,除法等,有兴趣的同学可以看《利用Python进行数据分析》第五章 算术运算与数据对齐 部分,多在网络上查找相关学习资料。
1.6.4 通过泰坦尼克号数据如何计算出在船上最大的家族有多少人?
'''
还是用之前导入的chinese_train.csv如果我们想看看在船上,最大的家族有多少人(‘兄弟姐妹个数’+‘父母子女个数’),我们该怎么做呢?
'''
max(text['兄弟姐妹个数'] + text['父母子女个数'])
运行结果:10
如上,很简单,我们只需找出兄弟姐妹个数和父母子女个数之和最大的数就行,先让这两列相加返回一个DataFrame,然后用max函数求出最大值,当然你还可以想出很多方法和思考角度,欢迎你来说出你的看法。
1.6.5 使用Pandas describe()函数查看数据基本统计信息
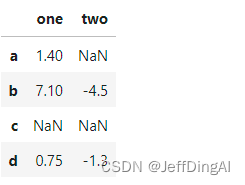
#建立一个例子
frame2 = pd.DataFrame([[1.4, np.nan],
[7.1, -4.5],
[np.nan, np.nan],
[0.75, -1.3]
], index=['a', 'b', 'c', 'd'], columns=['one', 'two'])
frame2
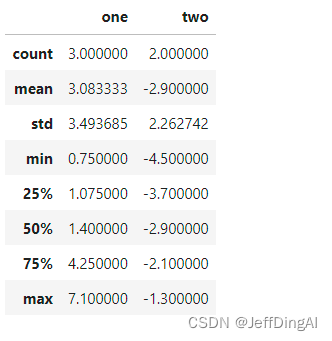
# 调用 describe 函数,观察frame2的数据基本信息
frame2.describe()
'''
count : 样本数据大小
mean : 样本数据的平均值
std : 样本数据的标准差
min : 样本数据的最小值
25% : 样本数据25%的时候的值
50% : 样本数据50%的时候的值
75% : 样本数据75%的时候的值
max : 样本数据的最大值
'''
运行结果:
1.6.6 别看看泰坦尼克号数据集中 票价、父母子女 这列数据的基本统计数据,你能发现什么?
'''
看看泰坦尼克号数据集中 票价 这列数据的基本统计数据
'''
text['票价'].describe()
运行结果:
count 891.000000
mean 32.204208
std 49.693429
min 0.000000
25% 7.910400
50% 14.454200
75% 31.000000
max 512.329200
Name: 票价, dtype: float64
从上面数据我们可以看出, 一共有891个票价数据, 平均值约为:32.20, 标准差约为49.69,说明票价波动特别大, 25%的人的票价是低于7.91的,50%的人的票价低于14.45,75%的人的票价低于31.00, 票价最大值约为512.33,最小值为0。
'''
通过上面的例子,我们再看看泰坦尼克号数据集中 父母子女个数 这列数据的基本统计数据,然后可以说出你的想法
'''
text['父母子女个数'].describe()
运行结果:
count 891.000000
mean 0.381594
std 0.806057
min 0.000000
25% 0.000000
50% 0.000000
75% 0.000000
max 6.000000
Name: 父母子女个数, dtype: float64
参考资料
Datawhale动手学数据分析:https://github.com/datawhalechina/hands-on-data-analysis
《利用Python进行数据分析》

- 点赞
- 收藏
- 关注作者
评论(0)