数据量剧增怎么办?Redis 切片集群了解一下

前言
redis 在使用过程中,如果遇到未预知的剧烈数据量增长,整个实例容量不够时,你会如何应对?可能大家最容易想到的方案就是扩容了。比如当前实例配置是 16g 内存的,那么就扩容到 32g。
表面来看方案没有问题,但是在扩容后续使用中,有可能会出现响应很慢的问题。这是怎么回事呢?让我们一探究竟。
redis 保存更多数据的方法
redis 为保存更多数据,总的来说分为横向扩展和纵向扩展:
-
纵向扩展:升级单个 redis 实例的资源配置,包括增加内存容量、磁盘容以及换更高配置的 CPU。
-
横向扩展:横向增加当前 redis 实例的个数,也就是搭建切片集群。
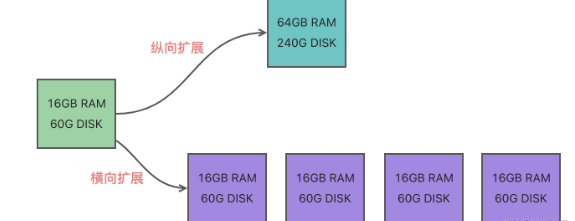
两种方法优缺点也很容易分析:
-
纵向扩展
-
优点是部署方便简单,直接升级实例配置
-
缺点就是如果使用 rdb 持久化,数据量大,在主线程 fork 子进程时容易阻塞;而且扩展的硬件成本高。
-
横向扩展
-
优点是容量扩展方便,只需要增加 redis 的实例个数。
-
缺点就是数据分布在各个切片中,数据的管理有难度。
可以看出,横向扩展的优点很明显,但是在数据管理上,我们需要明确数据的分布问题。
数据切片和实例的分布关系
在切片集群中,数据分布在不同的实例中。从 redis3.0 开始,Redis 官方就能通过 Redis cluster 方法实现切片集群,它采用哈希槽来映射数据和实例。
我们在部署切片集群时,可通过clustre create命令来创建集群,Redis 会平均将槽分布在各个实例上。我们也可通过cluster addslots命令手动分配哈希槽(在手动分配哈希槽时,需要把 16384 个槽都分配完,否则 Redis 集群无法正常工作)。
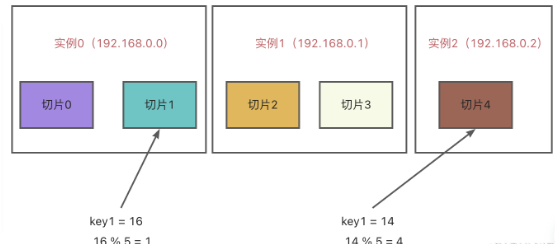
客户端是如何定位数据的
客户端和集群连接后,实例会将哈希槽的分配信息传到客户端。客户端收到哈希槽信息后,将信息缓存在本地,当客户端请求键值对时,首先会计算键值对所在的哈希槽,然后再将命令发送到哈希槽所在的实例上。
需要注意的是,实例和哈希槽的对应关系可能会变化的,主要有 2 种情况:
-
实例在新增或者删除时,Redis 需要重新分配哈希槽;
-
为了负载均衡,Redis 会在所有实例上 rehash(哈希槽重新分配)。
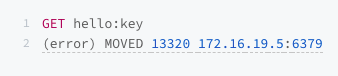
在哈希槽变化过程中,客户端需要对数据操作时,如果实例上没有相应的哈希槽,就会给客户端返回MOVED命令结果,而结果中就有新实例的访问地址。
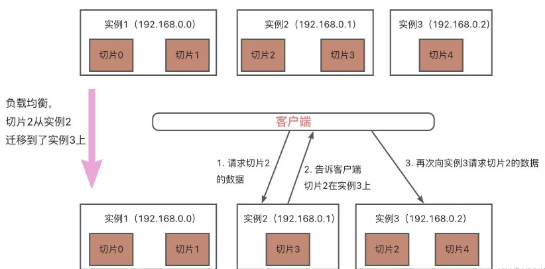
比如上图中的例子,如果切片 2 数据较多,客户端向实例 2 发送请求,但此时切片 2 有部分数据迁移到了实例 3,还有部分未迁移。此时客户端会收到一条 ASK 报错信息。表示键值在实例 3,但哈希槽正在迁移。之后客户端就可向实例 3 请求该数据。
Redis cluster 的哈希槽分配原理
Redis cluster 是通过哈希槽的方式将键值对分配到各个实例上,这个过程会对键值对的 key 做 CRC 计算,然后再和哈希槽做映射。
这样做的好处在于:
-
key 的数量不好预估,直接记录 key 对应的映射关系,映射表会很大,这样一来就会占用很大的内存空间;
-
当集群扩容、缩容、负载均衡时,节点间会进行数据迁移动作,如果修改每个 key 的映射关系,维护成本会很高。
-
当集群在扩容、缩容、数据均衡时,节点之间的操作如数据迁移,都以哈希槽为基本单位进行操作,简化了节点扩容、缩容的难度,便于集群的维护和管理。
小结
redis 切片集群的方式,以横向扩展的方式对 Redis 进行扩容。我们需要了解数据分布的映射原理,以便更好的管理数据。

- 点赞
- 收藏
- 关注作者
评论(0)