KMP 算法的理解


关于字符串的子串模式匹配算法,最经典最简单的的算法是BP算法(Brude-Force)。
BP 算法
首先我们需要定义一些内容为了下面的解释:
- 主串 S 和 子串 T ,且 S.length > T.length
- 串的物理位置从0开始
基本思路是:主串从第一个字符与子串的第一个字符进行匹配,一直进行对等位置比较,会有两种情况:
- 从初始位置开始与子串完全匹配 -> 匹配成功
- 在 主串在 i 的位置上匹配失败(此时 子串位置为 j) -> 主串从第二个位置与子串的第一个字符重新开始匹配
注:当匹配失败时,需要返回到主串的一开始的位置,并前进一位(i - j + 1)。
如下图所示:
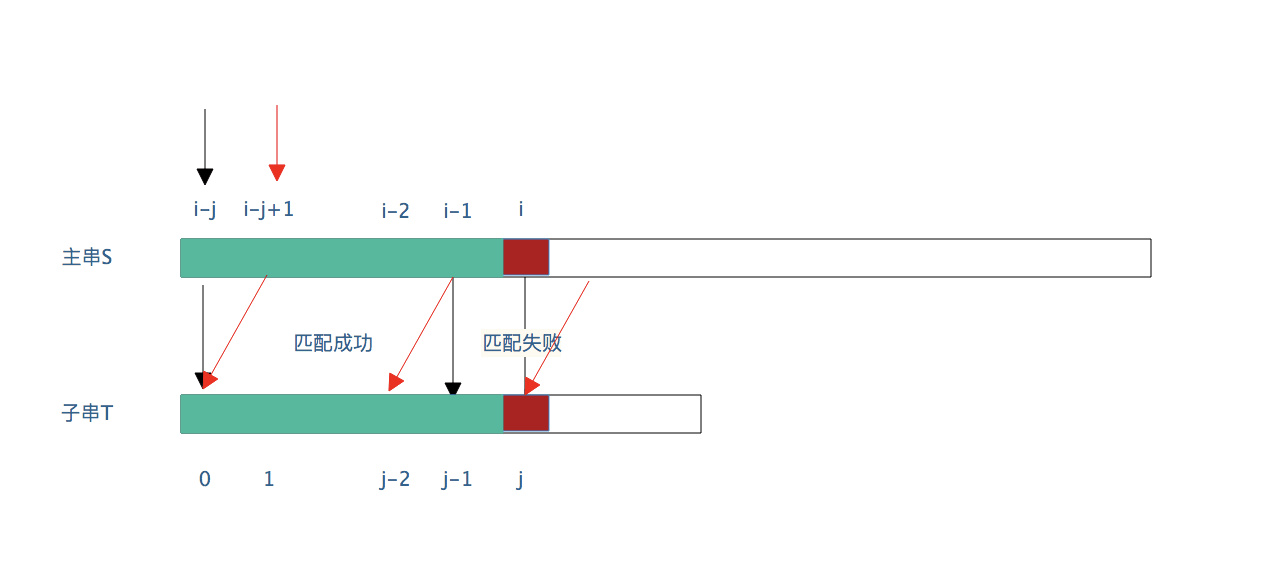
注:绿色区域为匹配成功(长度为j)红色区域表示匹配失败处 (在 i 的位置) 。
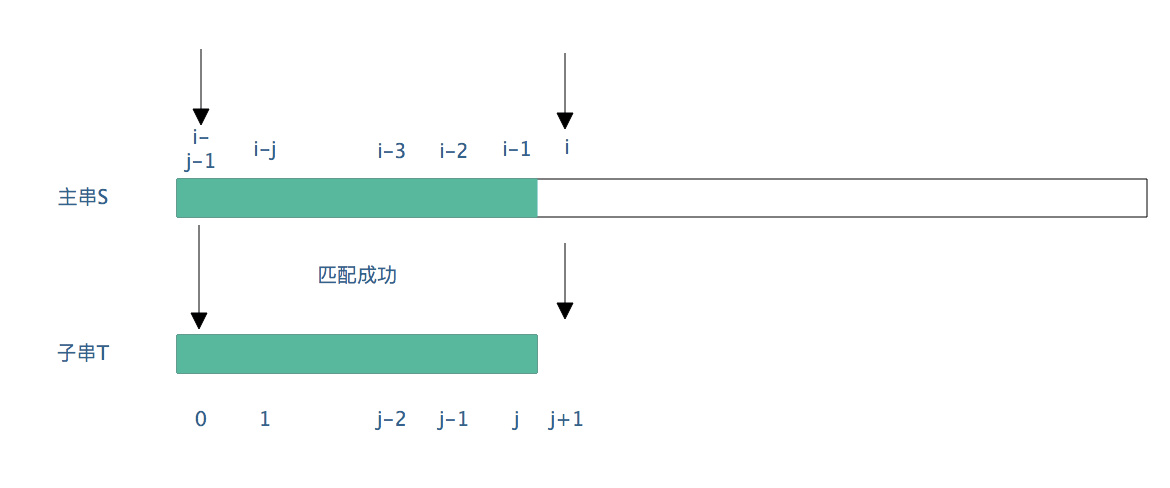
注: 表示成功匹配的结果
这种算法的代码是:
int index(String s, String t){
for (int i = 0,j=0;i<s.length && j < j.length;){
if (s[i] == t[j]){//目前匹配成功
j++;
i++;
}else{//该位置匹配失败,i需要返回到一开始的位置并加1重新检测匹配
i = i - j + 1;
j = 0;
}
}
//结束循环后,判断是否匹配成功
if (j >= t.length){//表示j已经访问了整个t子串了,即匹配成功
return i - j - 1; // 返回一开始成功匹配的位置
}else{
return -1;
}
}思考:这样的算法很符合我们的正常思维,但是有什么问题呢?
问题在于某些串本身会有"对称性(相似性)",我们应该利用这个性质(串的内在信息)。
- 这里的“对称性(相似性)”并不是一般的对称(一般的对称如某个图像关于X轴对称,这样沿着X轴折叠,两边可以重叠)。
- 举一些例子: 比如 子串
abab,相似的区域是ab。
关于子串的对称性有几点说明:
- 大部分的串或多或少都有一些相似性,如果没有任何“相似性”,BP算法仍然有优化空间(根据子串的不相似性减少不必要的检查,这个KMP部分会解释)
- 子串的两个相似区域不能完全重叠,必须偏移一定的距离。比如子串
aaaa,相似区域是aaa(相似区域不是aaaa,因为不能完全重叠)。
KMP算法的核心就是:
- 寻找模式子串每个字符前面的"小子串"的相似区域的长度。
- 利用这个相似区域减少不必要的检查匹配。
具体KMP原理看下面的解释。
KMP 算法
KMP算法能够优化寻找过程的依赖的性质有两点:
- 子串匹配失败处前面的“小子串”与上面的主串对应部分是完全相等的
- “小子串”具有“相似性”,即有相似区域
注:我们将子串匹配失败处前面的部分子串成为“小子串”,下同
如下图所示:
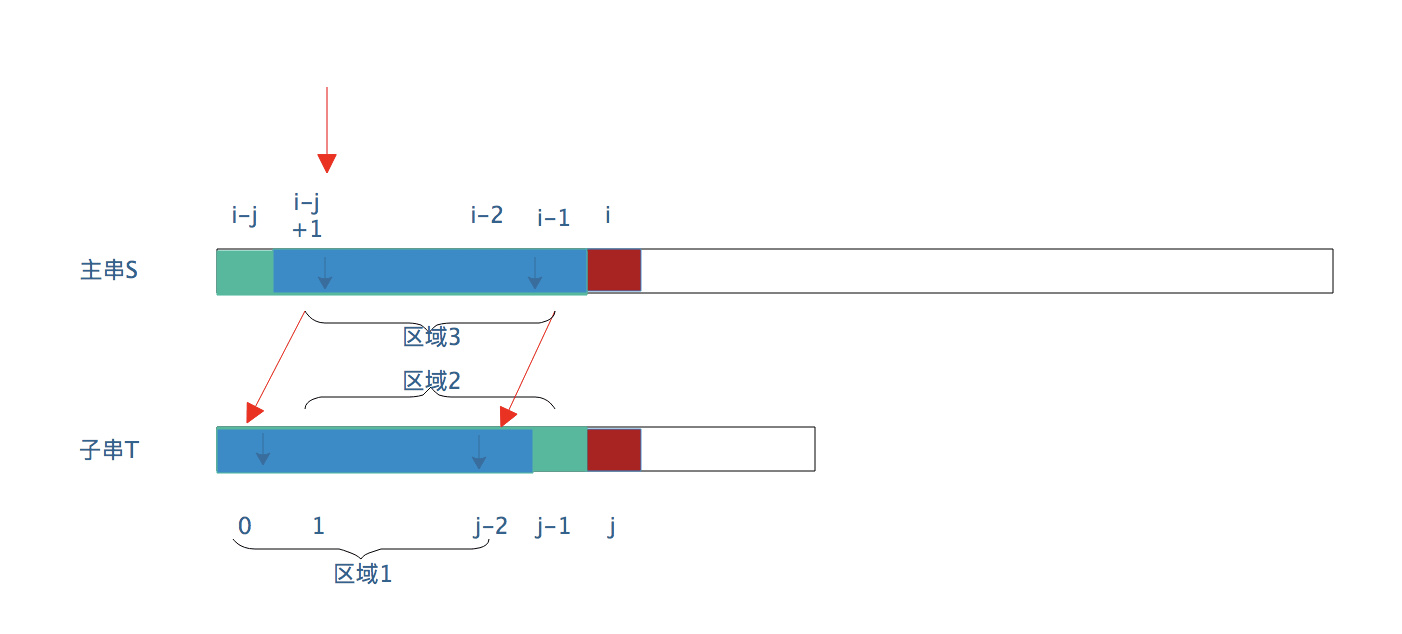
注:该图与BP算法的图是对应的,绿色是已匹配成功区域,红色是匹配失败的断点处。
我们假设子串t[j] 子串前面的“小子串“(即绿色匹配成功区域)具有相似区域:
且区域1 = 区域2,如下图所示,子串中具有两个相似区域:
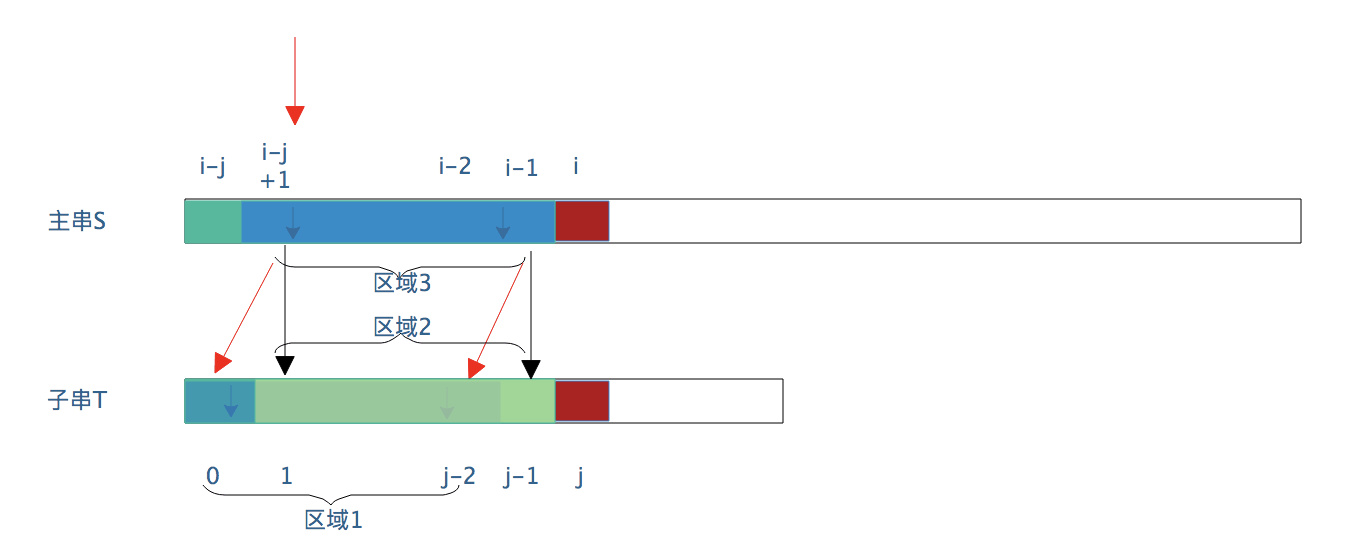
如果按照BP算法,主串应该从i-j+1 位置开始与子串的第一个字符进行匹配。即判断 区域3=?区域1。
这里区域2=区域3(因为这是绿色区域,是之前就已经匹配成功的),而区域1 = 区域2(假设的相似区域),所以必然区域1 = 区域3。
所以可以直接跳过区域3与区域1的比较,主串的 i 指针不需要返回到 i - j + 1,直接s[i] 与 t[j-1] 比较。
这是一种最简单的情况,相似区域的长度是“小子串”的长度减1(j-1)。
实际上相似区域可能并没那么长(第一种情况那么好)
如果区域1 != 区域2 。那么根据上面的推导,则区域3 != 区域1。
那么BP算法就没必要再将区域3与区域1进行比较,而是直接s[i-j+2] 与 t[0] 比较,如下图的过程所示:
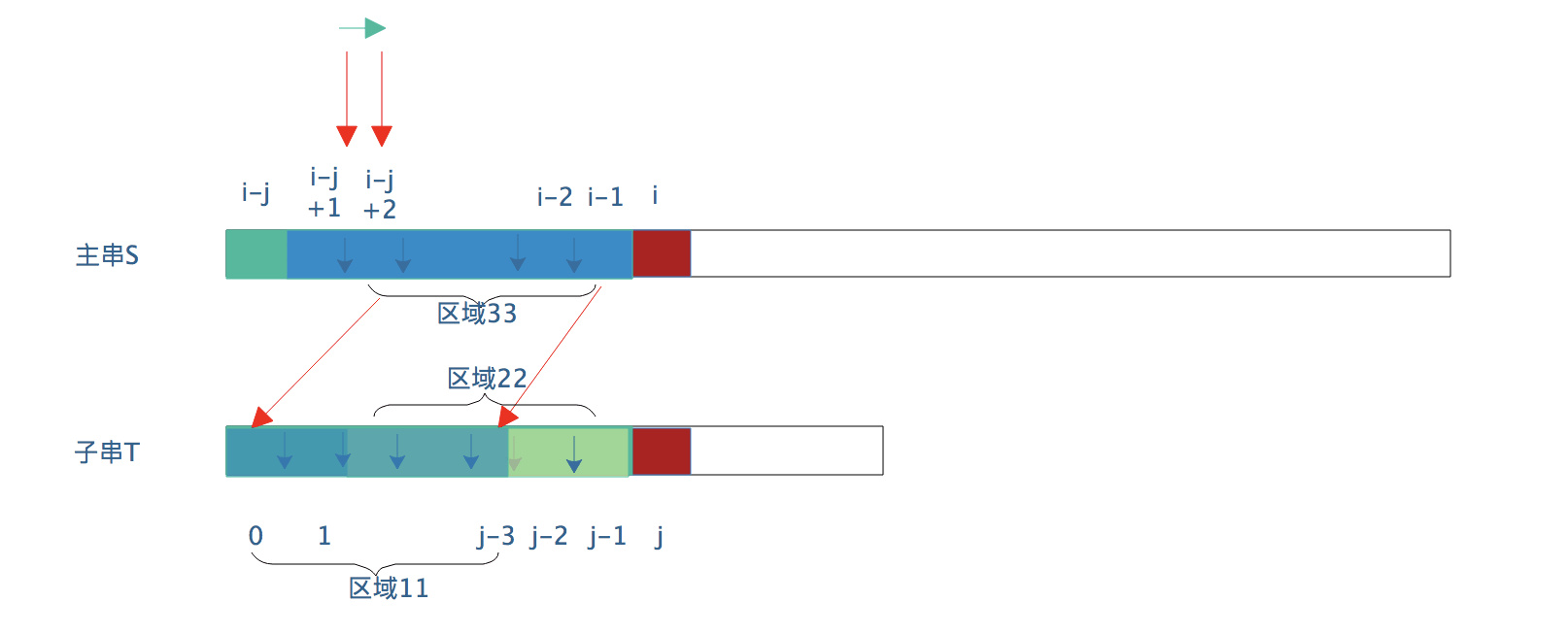
我们假设小子串相似区域缩小为现在的区域11 与 区域22(长度为j-2)。
因为区域11 == 区域 22,则区域11 ==区域33(区域22 一定 == 区域33)
则主串的i指针仍然不用返回,直接将S[i] 与 S[j-2] 比较即可。
按照上面的过程,
假设小子串相似区域缩小到 j - 3,那么主串的i指针仍然不用返回,直接将S[i] 与 S[j-3] 比较即可。
……
假设小子串没有任何的相似区域,那么主串的i指针仍然不用返回,直接将S[i] 与 S[0] 比较即可。
这种最差的情况(小子串没有相似性)相比较BP算法,我们仍然减少了一系列的检查匹配(如S[i-j+1] ?= T[0] S[j-j+2] = ? T[0])
上面的分析过程,我们知道KMP相比较BP算法关键有两点不同:
- 主串的 i 指针不需要返回
- s[i] 与 t[k] 直接比较,这里的k是小子串相似区域的长度。这个k的意义是,当子串j位置匹配失败,下一步子串j指针需要移动到k的位置上(j = k)然后s[i]与t[k]开始检测匹配。
问题的关键是对于模式子串的每一个位置j,我们怎么求出对应的k。
即对模式子串每个字符(位置为j),前面的小子串都有一个相似区域的长度(长度为k),我们把这个长度记录在next[j] = k
实际的KMP算法是一开始就求出模式子串的所有next数组的值,然后再进行匹配检测,即分为两步:
- 获取到模式子串的next数组
- 当匹配失败时,主串i指针不需要返回,模式子串j 移动到next[j]的位置,继续进行匹配检测,直到主串检测完毕(i>= s.length)
关于模式子串的next数组求法,根据上面分析很容易理解:
- (固定前两位的值)next[0] = -1;next [1] = 0;
- 然后从j=2开始,求出该位置前面的小子串的相似区域的长度即可。
注:这里说明一下,next[0] = -1 意思是,当主串s[i] 与子串0位置比较不匹配的时候,下一步是将主串i指针前移一位继续与子串0位置比较。换成代码的写法即:
if (j == -1){// 前面已经做了j = next[j],具体看下面完整代码
i++;// 主串 i 指针前移一位
j++;// j 变成0,即与t[0]进行匹配检测
}下面给出KMP算法的代码:
int KMPindex(String s,String t){
//1. 求出子串的next数组
int [] next = new int[MaxSize];
next[0] = -1;next[1] = 0;//固定的前两位的值
int k = -1;
for(int j= 0;j<t.length;){//对每一位找到小子串的相似区域的长度
// 手算next数组很简单的,但是用代码则不容易。李春葆《数据结构》上的代码非常精妙,仅用4行
// 如果按照课本上的代码过程发现确实能得到正确结果,但是自己根本想不到这么写啊
// 考研基本不考这部分代码,我先不深入研究了,会手算即可
if (k == -1 || t[j] == t[k]){
j++;
k++;
next[j] = k;
}else{
k = next[k];
}
}
//2. 开始匹配,可以看到匹配过程代码和BP算法基本一样,只是在匹配出错的地方处理不一样
for (int i = 0,j=0;i<s.length && j < j.length;){
if (j == -1 || s[i] == t[j]){//目前匹配成功 或者 匹配失败且j = (next[j] == -1)
j++;
i++;
}else{//该位置匹配失败,i不动,j移动到next[j]的位置继续与s[i]比较
j = next[j];
}
}
//结束循环后,判断是否匹配成功
if (j >= t.length){//表示j已经访问了整个t子串了,即匹配成功
return i - j - 1; // 返回一开始成功匹配的位置
}else{
return -1;
}
}注:上面的第二步开始匹配是课本上的写法,因为匹配成功或者匹配失败且next[j] == -1 两种情况写在一起了,都是i++;j++但是不好理解,可以改成下面我们比较容易理解的方式,执行效率一样,本质也是相同的
//2. 开始匹配,可以看到匹配过程代码和BP算法基本一样,只是在匹配出错的地方处理不一样
for (int i = 0,j=0;i<s.length && j < j.length;){
if (s[i] == t[j]){//目前匹配成功
j++;
i++;
}else{//该位置匹配失败,i不动
if(next[j] != -1){//j移动到next[j]的位置继续与s[i]比较
j = next[j];
}else{//如果next[j] == -1,表示该匹配失败处是子串的0位置,所以i需要前移一位,j仍然保持不变为0
j = 0;//这句话可以去掉,因为此时j一定为0
i ++;
}
}
}
//结束循环后,判断是否匹配成功
if (j >= t.length){//表示j已经访问了整个t子串了,即匹配成功
return i - j - 1; // 返回一开始成功匹配的位置
}else{
return -1;
}KMP算法的问题在于忽视了一种特殊的模式子串,如aaaaa,这种子串还能够利用本身的特殊值相等性质进一步简化检测匹配的过程。
我们重新回到KMP算法中,当子串在j位置上匹配失败,(break = j 我们用break 临时变量保存匹配失败的位置)j = next[j] 然后判断s[i] 是否与 t[j] 相等。
我们之前利用的是相似性 + 小子串与主串对应相等,这里我们还可以挖掘特殊值相等 + j(移动前的j即break) 位置与主串的对应位置i不相等。
因为t[break] != s[i],如果 t[j] = t[break] (这里的j是移动后的j了),那么t[j] 也一定不等于s[i],则我们可以跳过s[i] 与t[j] 比较这一步,而直接j再次移动到next[j] (j = next[j]),然后再s[i] 与 t[j] 比较。
总结:当子串在j位置匹配失败,且t[next[j]] = t[j] ,那么可以直接将s[i] 与t[next[next[j]]] 进行比较。
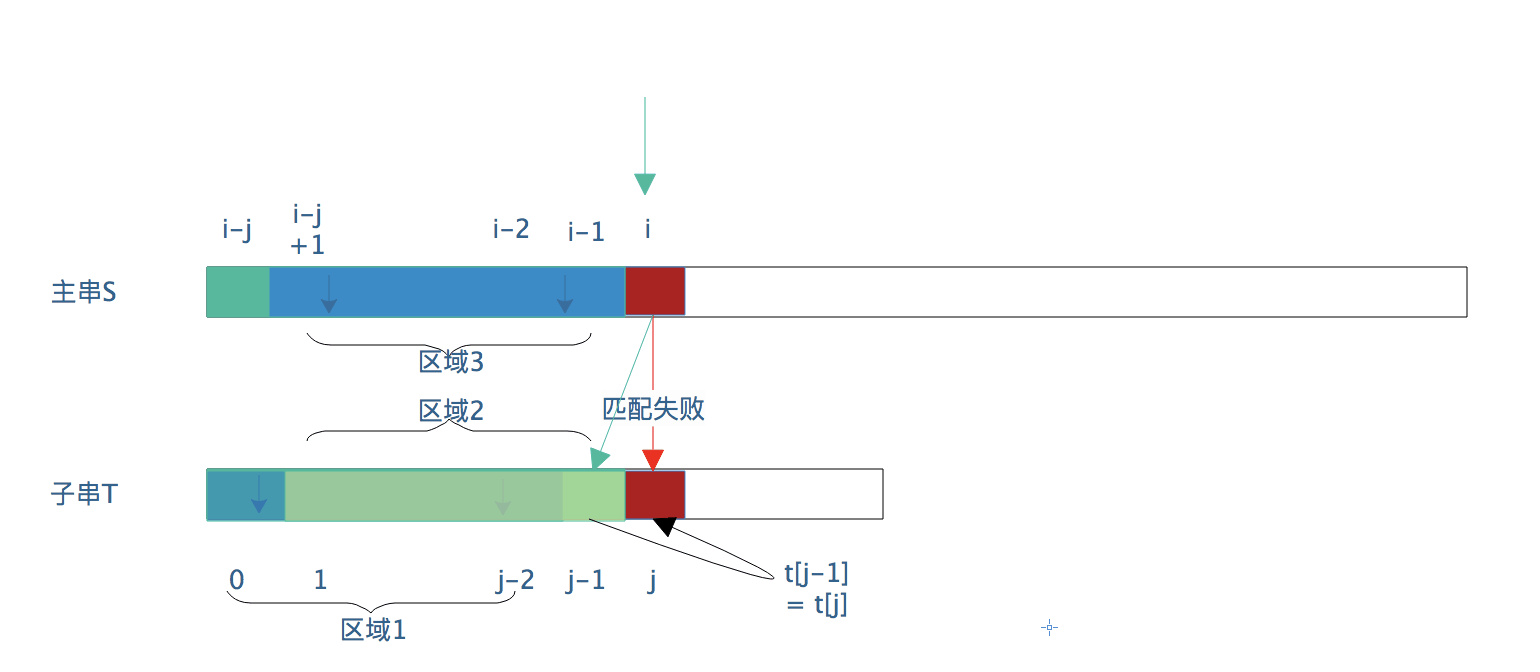
如上图所示,即可以直接将s[i] 与t[next[j-i]] 进行比较。
上面讲的是KMP算法为什么需要改进,具体改进方法见下面。
KMP 改进算法
根据上面的分析,其实我们只需要在计算next数组的时候考虑到t[j] 与 t[next[j]] 是否相等:
- 如果相等,next[j] =next[next[j]];
- 如果不相等话,next[j] 值还是以前的计算方法(小子串相似区域的长度)
为了以便和上个算法区分,我们将这个next数组改名为nextval数组。
事实上,nextval数组计算过程中是包含next数组的计算的,所以我们手算的时候都是先算next数组,再算nextval数组的,过程如下:
比较t[j]与t[next[j]]是否相等:
- 如果相等,next[j] =nextval[next[j]];
注:(next[j] 值肯定是小于j,所以nextval[next[j]]值之前已经计算出来了,这是因为小子串的相似区域的长度肯定小于小子串的长度(因为必须要偏移一定距离))
- 如果不相等话,nextval[j] = next[j]
这种过程和上面的过程是有一定区别的:
第一种方法是只有nextval一个数组,虽然计算过程中会计算小子串的相似区域长度,适用于算法代码
第二种方法是明确先求next数组,再求nextval数组,方便手算的。
KMP改进算法的代码:
int KMPindex(String s,String t){
//1. 求出子串的nextval数组
int [] nextval = new int[MaxSize];
nextval[0] = -1;//固定的前一位的值
int k = -1;
for(int j= 0;j<t.length;){//对每一位找到小子串的相似区域的长度
//同KMP,只要求手算结果即可,代码没有深入研究
}
//2. 开始匹配,可以看到匹配过程代码和BP算法基本一样,只是在匹配出错的地方处理不一样
for (int i = 0,j=0;i<s.length && j < j.length;){
if (s[i] == t[j]){//目前匹配成功
j++;
i++;
}else{//该位置匹配失败,i不动
if(next[j] != -1){//j移动到nextval[j]的位置继续与s[i]比较
j = nextval[j];
}else{//如果nextval[j] == -1,表示j最终会移动到0位置上,且 t[j] == t[0],所以
j = 0;//这句话一定不能去掉!!因为不仅只有0位置nextval[0] = -1还有别的位置也可能等于-1
i ++;
}
}
}
//结束循环后,判断是否匹配成功
if (j >= t.length){//表示j已经访问了整个t子串了,即匹配成功
return i - j - 1; // 返回一开始成功匹配的位置
}else{
return -1;
}
}最后
关于以上个人体会,有以下几点说明:
- 代码是在编辑器手敲的,没有经过代码运行,很大可能是运行有错误,只是用来展示算法思路
- 可以看到KMP(以及改进后)算法本质上都是在处理子串j位置匹配失败,子串的j需要如何移动。所以next(nextval)数组的意义就是如果该位置匹配失败了,当前位置应该移动到什么位置上
- KMP算法和BP算法在匹配成功的过程中是完全一致的
- 理解可能有错误之处,请不吝指正

- 点赞
- 收藏
- 关注作者
评论(0)