2022CUDA夏季训练营Day6实践


2022CUDA夏季训练营Day1实践 https://bbs.huaweicloud.com/blogs/364478
2022CUDA夏季训练营Day2实践 https://bbs.huaweicloud.com/blogs/364479
2022CUDA夏季训练营Day3实践 https://bbs.huaweicloud.com/blogs/364480
2022CUDA夏季训练营Day4实践之统一内存 https://bbs.huaweicloud.com/blogs/364481
2022CUDA夏季训练营Day4实践之原子操作 https://bbs.huaweicloud.com/blogs/364482
2022CUDA夏季训练营Day5实践 https://bbs.huaweicloud.com/blogs/364483
“利用GPU计算TOP10”这件事情不一定非要用核函数,还可以用Thrust的CUDA加速工具库:
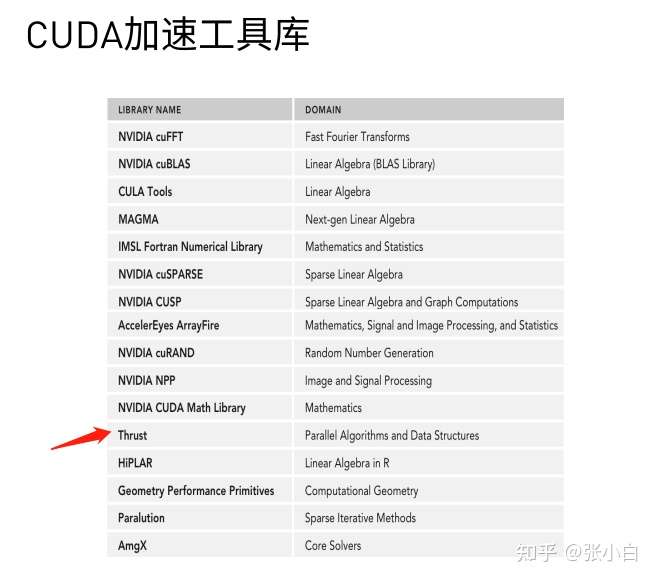
cub和Thrust其实也是可以排序的良方呢!
CUDA Thrust的资料在这里:https://docs.nvidia.com/cuda/thrust/index.html
我们先做个排序的尝试。
首先,张小白搜到了这个:https://blog.csdn.net/qq_23123181/article/details/122116099
里面有个例子,于是张小白就用自己的Nano上的Juputer做了尝试:
这是用cmake编译的,有以下文件:
CMakeLists.txt
CMAKE_MINIMUM_REQUIRED(VERSION 3.5)
PROJECT(thrust_examples)
set(CMAKE_BUILD_TYPE Release)
find_package(CUDA)
include_directories(${CUDA_INCLUDE_DIRS})
message(STATUS "${CUDA_INCLUDE_DIRS}")
message(STATUS "${CUDA_LIBRARIES}")
cuda_add_executable(thrust_examples sort.cu)sort.cu
这个张小白加了点打印信息,这样可以看得清楚些:
#include <thrust/host_vector.h>
#include <thrust/device_vector.h>
#include <thrust/generate.h>
#include <thrust/sort.h>
#include <thrust/copy.h>
#include <algorithm>
#include <vector>
#include <time.h>
#define TOPK 20
int main(void)
{
thrust::host_vector<int> h_vec(10000*1000);
std::generate(h_vec.begin(), h_vec.end(), rand);
std::cout<< "size()=" << h_vec.size() <<std::endl;
std::vector<int> vec(h_vec.size());
// h_vec->vec
thrust::copy(h_vec.begin(), h_vec.end(), vec.begin());
// h_vec->d_vec
thrust::device_vector<int> d_vec=h_vec;
clock_t time1,time2;
//sort d_vec
//std::cout<< "d_vec.size()=" << d_vec.size() <<std::endl;
std::cout<< "before sort d_vec..." <<std::endl;
for(int i = 0; i < TOPK; ++i)
{
std::cout << d_vec[i] << " ";
}
std::cout << std::endl;
std::cout << std::endl;
time1 = clock();
thrust::sort(d_vec.begin(), d_vec.end());
time2 = clock();
std::cout<<(double)(time2-time1)/CLOCKS_PER_SEC*1000<< " ms"<<std::endl;
std::cout << std::endl;
std::cout<< "after sort d_vec..." <<std::endl;
for(int i = 0; i < TOPK; ++i)
{
std::cout << d_vec[i] << " ";
}
std::cout << std::endl;
std::cout << std::endl;
//sort vec
//std::cout<< "vec.size()=" << vec.size() <<std::endl;
std::cout<< "before sort vec..." <<std::endl;
for(int i = 0; i < TOPK; ++i)
{
std::cout << vec[i] << " ";
}
std::cout << std::endl;
std::cout << std::endl;
time1 = clock();
std::sort(vec.begin(),vec.end());
time2 = clock();
std::cout<<(double)(time2-time1)/CLOCKS_PER_SEC*1000<< " ms"<<std::endl;
std::cout << std::endl;
std::cout<< "after sort vec..." <<std::endl;
for(int i = 0; i < TOPK; ++i)
{
std::cout << vec[i] << " ";
}
std::cout << std::endl;
std::cout << std::endl;
//sort h_vec
//std::cout<< "h_vec.size()=" << h_vec.size() <<std::endl;
std::cout<< "before sort h_vec..." <<std::endl;
for(int i = 0; i < TOPK; ++i)
{
std::cout << h_vec[i] << " ";
}
std::cout << std::endl;
std::cout << std::endl;
time1 = clock();
thrust::sort(h_vec.begin(), h_vec.end());
time2 = clock();
std::cout<<(double)(time2-time1)/CLOCKS_PER_SEC*1000<< " ms"<<std::endl;
std::cout << std::endl;
std::cout<< "after sort h_vec..." <<std::endl;
for(int i = 0; i < TOPK; ++i)
{
std::cout << h_vec[i] << " ";
}
std::cout << std::endl;
return 0;
}
这里面分别对三种类型进行了排序:
1.host_vector(thrust的)
2.vector(STL的)
3.device_vector(thrust的)
我们先执行下,看看效果:
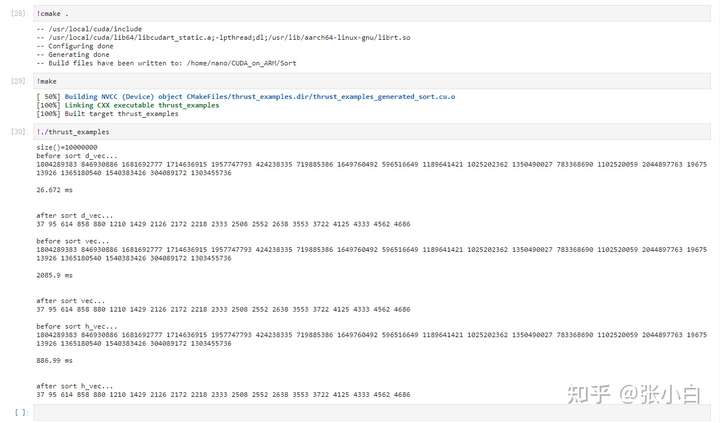
解读一下:
该代码先申请了一个host_vector类型的h_vec,并且随机生成了1000万条记录。
然后分别申请了vector类型的vec和 device_vector类型的d_vec,并将值赋成跟h_vec完全一致。
然后分别使用
thrust::sort(d_vec.begin(), d_vec.end());
std::sort(vec.begin(),vec.end());
thrust::sort(h_vec.begin(), h_vec.end());
分别给这三个1000万随机数排序(目前是升序)
并打印出了最小的10个数(与TOP10相对应,可能应该叫BOTTOM10吧?张小白这么想。。。)
其中第二个sort并非thrust库的。第一个和第三个sort用的是thrust库。
从最终算出的时间结果也可以看出:
标准库的sort耗时最长——2085.9ms
HOST上的thrust sort耗时较长——886.99ms
DEVICE上的thrust sort耗时最短——26.672ms。
这样看起来,貌似比昨天作业中所有的测试都出色了。
昨天TOP10的数据在这里:( 张小白:2022CUDA夏季训练营Day5实践之top10 )
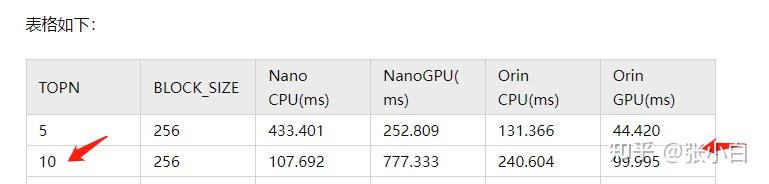
我们来把代码落实一下:
那就开干吧!
原代码如下:
sort2.cu
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include "error.cuh"
#define BLOCK_SIZE 256
#define N 1000000
#define GRID_SIZE ((N + BLOCK_SIZE - 1) / BLOCK_SIZE)
#define topk 10
__managed__ int source_array[N];
__managed__ int _1pass_results[topk * GRID_SIZE];
__managed__ int final_results[topk];
__device__ __host__ void insert_value(int* array, int k, int data)
{
for (int i = 0; i < k; i++)
{
if (array[i] == data)
{
return;
}
}
if (data < array[k - 1])
return;
for (int i = k - 2; i >= 0; i--)
{
if (data > array[i])
array[i + 1] = array[i];
else {
array[i + 1] = data;
return;
}
}
array[0] = data;
}
__global__ void top_k(int* input, int length, int* output, int k)
{
}
void cpu_result_topk(int* input, int count, int* output)
{
/*for (int i = 0; i < topk; i++)
{
output[i] = INT_MIN;
}*/
for (int i = 0; i < count; i++)
{
insert_value(output, topk, input[i]);
}
}
void _init(int* ptr, int count)
{
srand((unsigned)time(NULL));
for (int i = 0; i < count; i++) ptr[i] = rand();
}
int main(int argc, char const* argv[])
{
int cpu_result[topk] = { 0 };
cudaEvent_t start, stop;
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop));
//Fill input data buffer
_init(source_array, N);
printf("\n***********GPU RUN**************\n");
CHECK(cudaEventRecord(start));
top_k << <GRID_SIZE, BLOCK_SIZE >> > (source_array, N, _1pass_results, topk);
CHECK(cudaGetLastError());
top_k << <1, BLOCK_SIZE >> > (_1pass_results, topk * GRID_SIZE, final_results, topk);
CHECK(cudaGetLastError());
CHECK(cudaDeviceSynchronize());
CHECK(cudaEventRecord(stop));
CHECK(cudaEventSynchronize(stop));
float elapsed_time;
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));
printf("Time = %g ms.\n", elapsed_time);
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop));
cpu_result_topk(source_array, N, cpu_result);
int ok = 1;
for (int i = 0; i < topk; ++i)
{
printf("cpu top%d: %d; gpu top%d: %d \n", i + 1, cpu_result[i], i + 1, final_results[i]);
if (fabs(cpu_result[i] - final_results[i]) > (1.0e-10))
{
ok = 0;
}
}
if (ok)
{
printf("Pass!!!\n");
}
else
{
printf("Error!!!\n");
}
return 0;
}
先将代码框架移植到cmake编译器上:
CMakeLists.txt
CMAKE_MINIMUM_REQUIRED(VERSION 3.5)
PROJECT(thrust_examples)
set(CMAKE_BUILD_TYPE Release)
find_package(CUDA)
include_directories(${CUDA_INCLUDE_DIRS})
message(STATUS "${CUDA_INCLUDE_DIRS}")
message(STATUS "${CUDA_LIBRARIES}")
cuda_add_executable(thrust_examples sort2.cu)
其实很简单,将sort.cu改为sort2.cu即可。
然后给sort2.cu加上sort.cu头文件:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include "error.cuh"
#include <thrust/host_vector.h>
#include <thrust/device_vector.h>
#include <thrust/generate.h>
#include <thrust/sort.h>
#include <thrust/copy.h>
#include <algorithm>
#include <vector>
并注释掉GPU RUN的那部分代码。
并在GPU RUN的地方加入 thrust的相关代码。
printf("\n***********GPU RUN**************\n");
CHECK(cudaEventRecord(start));
//定义host_vector
thrust::host_vector<int> h_vec;
//遍历source_array,并赋值给host_vector
for(int i= 0; i< N; i++)
{
h_vec.push_back(source_array[i]);
}
printf("h_vec push ok!\n");
//定义device_vector,将host_vector复制到device_vector
thrust::device_vector<int> d_vec=h_vec;
printf("d_vec init ok!\n");
CHECK(cudaGetLastError());
//给device_vector排序
thrust::sort(d_vec.begin(), d_vec.end());
printf("d_vec sort ok!\n");
for (int i = 0; i < topk ; i++)
{
final_results[i] = d_vec[vec.size()-1-i];
}
printf("vec sort ok!\n");
后面与原来的代码一样,就是打印CPU TOP10,以及cudaEvent_t通过计算GPU时间.
我们全部显示一下:
sort2.cu
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include "error.cuh"
#include <thrust/host_vector.h>
#include <thrust/device_vector.h>
#include <thrust/generate.h>
#include <thrust/sort.h>
#include <thrust/copy.h>
#include <algorithm>
#include <vector>
#define BLOCK_SIZE 256
#define N 10000000
#define GRID_SIZE ((N + BLOCK_SIZE - 1) / BLOCK_SIZE)
#define topk 10
__managed__ int source_array[N];
__managed__ int _1pass_results[topk * GRID_SIZE];
__managed__ int final_results[topk];
__device__ __host__ void insert_value(int* array, int k, int data)
{
for (int i = 0; i < k; i++)
{
if (array[i] == data)
{
return;
}
}
if (data < array[k - 1])
return;
for (int i = k - 2; i >= 0; i--)
{
if (data > array[i])
array[i + 1] = array[i];
else {
array[i + 1] = data;
return;
}
}
array[0] = data;
}
__global__ void top_k(int* input, int length, int* output, int k)
{
}
void cpu_result_topk(int* input, int count, int* output)
{
/*for (int i = 0; i < topk; i++)
{
output[i] = INT_MIN;
}*/
for (int i = 0; i < count; i++)
{
insert_value(output, topk, input[i]);
}
}
void _init(int* ptr, int count)
{
srand((unsigned)time(NULL));
for (int i = 0; i < count; i++) ptr[i] = rand();
}
int main(int argc, char const* argv[])
{
int cpu_result[topk] = { 0 };
cudaEvent_t start, stop;
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop));
//Fill input data buffer
_init(source_array, N);
printf("\n***********GPU RUN**************\n");
CHECK(cudaEventRecord(start));
//定义host_vector
thrust::host_vector<int> h_vec;
//遍历source_array,并赋值给host_vector
for(int i= 0; i< N; i++)
{
h_vec.push_back(source_array[i]);
}
printf("h_vec push ok!\n");
//定义device_vector,将host_vector复制到device_vector
thrust::device_vector<int> d_vec=h_vec;
printf("d_vec init ok!\n");
CHECK(cudaGetLastError());
//给device_vector排序
thrust::sort(d_vec.begin(), d_vec.end());
printf("d_vec sort ok!\n");
//取出倒排的10位存入final_results数组
for (int i = 0; i < topk ; i++)
{
final_results[i] = d_vec[d_vec.size()-1-i];
}
printf("final_results set ok!\n");
/*
top_k << <GRID_SIZE, BLOCK_SIZE >> > (source_array, N, _1pass_results, topk);
top_k << <1, BLOCK_SIZE >> > (_1pass_results, topk * GRID_SIZE, final_results, topk);
CHECK(cudaGetLastError());
*/
//CHECK(cudaDeviceSynchronize());
CHECK(cudaEventRecord(stop));
CHECK(cudaEventSynchronize(stop));
float elapsed_time;
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop));
cpu_result_topk(source_array, N, cpu_result);
int ok = 1;
for (int i = 0; i < topk; ++i)
{
printf("cpu top%d: %d; gpu top%d: %d \n", i + 1, cpu_result[i], i + 1, final_results[i]);
if (fabs(cpu_result[i] - final_results[i]) > (1.0e-10))
{
ok = 0;
}
}
if (ok)
{
printf("Pass!!!\n");
}
else
{
printf("Error!!!\n");
}
printf("GPU Time = %g ms.\n", elapsed_time);
return 0;
}
编译执行:
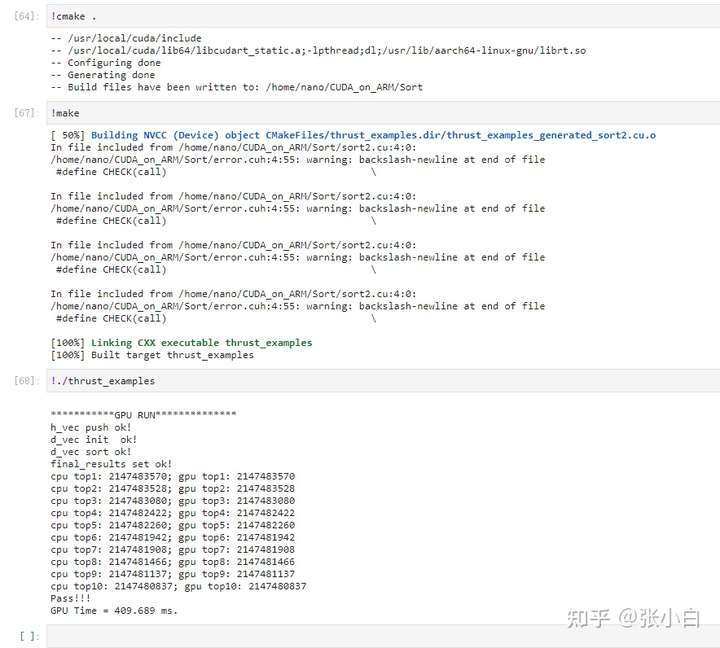
执行没问题。
只是,貌似确实有点耗时。主要是代码中先从source_array数组拷贝到 host_vector的h_vec,再从host_vector的h_vec拷贝到device_vector的d_vec,然后再排序的。
我们仔细打印下具体时间:
printf("\n***********GPU RUN**************\n");
CHECK(cudaEventRecord(start));
//定义host_vector
thrust::host_vector<int> h_vec;
//遍历source_array,并赋值给host_vector
for(int i= 0; i< N; i++)
{
h_vec.push_back(source_array[i]);
}
printf("h_vec push ok!\n");
CHECK(cudaGetLastError());
CHECK(cudaEventRecord(stop1));
CHECK(cudaEventSynchronize(stop1));
float elapsed_time;
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop1));
printf("h_vec push Time = %g ms.\n", elapsed_time);
//定义device_vector,将host_vector复制到device_vector
thrust::device_vector<int> d_vec=h_vec;
printf("d_vec init ok!\n");
CHECK(cudaGetLastError());
CHECK(cudaEventRecord(stop2));
CHECK(cudaEventSynchronize(stop2));
CHECK(cudaEventElapsedTime(&elapsed_time, stop1, stop2));
printf("d_vec init Time = %g ms.\n", elapsed_time);
//给device_vector排序
thrust::sort(d_vec.begin(), d_vec.end());
printf("d_vec sort ok!\n");
CHECK(cudaGetLastError());
CHECK(cudaEventRecord(stop3));
CHECK(cudaEventSynchronize(stop3));
CHECK(cudaEventElapsedTime(&elapsed_time, stop2, stop3));
printf("d_vec sort Time = %g ms.\n", elapsed_time);
//取出倒排的10位存入final_results数组
for (int i = 0; i < topk ; i++)
{
final_results[i] = d_vec[d_vec.size()-1-i];
}
printf("final_results set ok!\n");
CHECK(cudaGetLastError());
CHECK(cudaEventRecord(stop4));
CHECK(cudaEventSynchronize(stop4));
CHECK(cudaEventElapsedTime(&elapsed_time, stop3, stop4));
printf("final_results set Time = %g ms.\n", elapsed_time);
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop1));
CHECK(cudaEventDestroy(stop2));
CHECK(cudaEventDestroy(stop3));
CHECK(cudaEventDestroy(stop4));
重新编译执行:
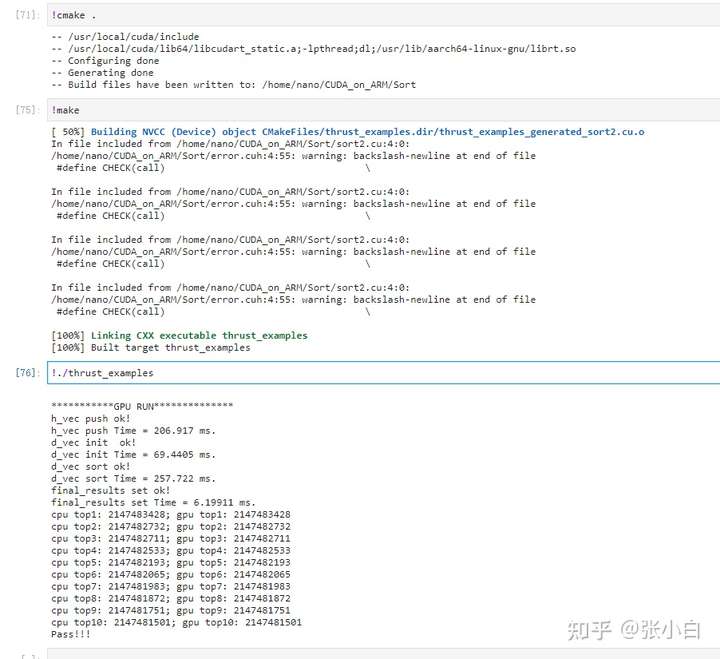
具体时间为:
- 从source_array数组拷贝到 host_vector:206ms
- 从host_vector拷贝到device_vector:89ms
- device_vector排序:257ms
- 复制结果到final_results:6ms
(以上数据存在抖动的可能性)
不过张小白试过想把source_array数组直接拷贝到device_vector,不过没有成功。
比如将代码写出这样:
float elapsed_time;
printf("\n***********GPU RUN**************\n");
CHECK(cudaEventRecord(start));
//定义host_vector
/*
thrust::host_vector<int> h_vec;
//遍历source_array,并赋值给host_vector
for(int i= 0; i< N; i++)
{
h_vec.push_back(source_array[i]);
}
printf("h_vec push ok!\n");
CHECK(cudaGetLastError());
CHECK(cudaEventRecord(stop1));
CHECK(cudaEventSynchronize(stop1));
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop1));
printf("h_vec push Time = %g ms.\n", elapsed_time);
*/
//定义device_vector,将host_vector复制到device_vector
//thrust::device_vector<int> d_vec=h_vec;
thrust::device_vector<int> d_vec;
//遍历source_array,并赋值给device_vector
for(int i= 0; i< N; i++)
{
d_vec.push_back(source_array[i]);
}
printf("d_vec init ok!\n");
CHECK(cudaGetLastError());
CHECK(cudaEventRecord(stop2));
CHECK(cudaEventSynchronize(stop2));
//CHECK(cudaEventElapsedTime(&elapsed_time, stop1, stop2));
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop2));
printf("d_vec init Time = %g ms.\n", elapsed_time);
//给device_vector排序
thrust::sort(d_vec.begin(), d_vec.end());
printf("d_vec sort ok!\n");
CHECK(cudaGetLastError());
CHECK(cudaEventRecord(stop3));
CHECK(cudaEventSynchronize(stop3));
CHECK(cudaEventElapsedTime(&elapsed_time, stop2, stop3));
printf("d_vec sort Time = %g ms.\n", elapsed_time);
//取出倒排的10位存入final_results数组
for (int i = 0; i < topk ; i++)
{
final_results[i] = d_vec[d_vec.size()-1-i];
}
printf("final_results set ok!\n");
CHECK(cudaGetLastError());
CHECK(cudaEventRecord(stop4));
CHECK(cudaEventSynchronize(stop4));
CHECK(cudaEventElapsedTime(&elapsed_time, stop3, stop4));
printf("final_results set Time = %g ms.\n", elapsed_time);
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop1));
CHECK(cudaEventDestroy(stop2));
CHECK(cudaEventDestroy(stop3));
CHECK(cudaEventDestroy(stop4));
运行的时候就直接卡死了,也不知道是什么原因:
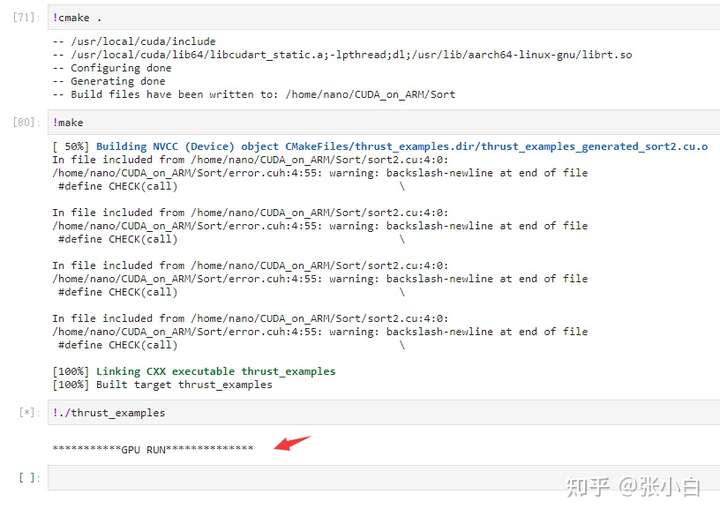
或许哪位大侠知道,可以告知我一下。
(全文完,谢谢阅读)

- 点赞
- 收藏
- 关注作者
评论(0)