2022CUDA夏季训练营Day1实践


张小白曾经成功地运行了第一个CUDA程序,但是对其只是知其然不知其所以然。所以CUDA训练营是帮你知其所以然的。
我们把 CPU,内存这块区域叫做“主机(HOST)”,把GPU,显存这块区域叫做“设备(DEVICE)”。
CUDA的代码执行包含以下几步:
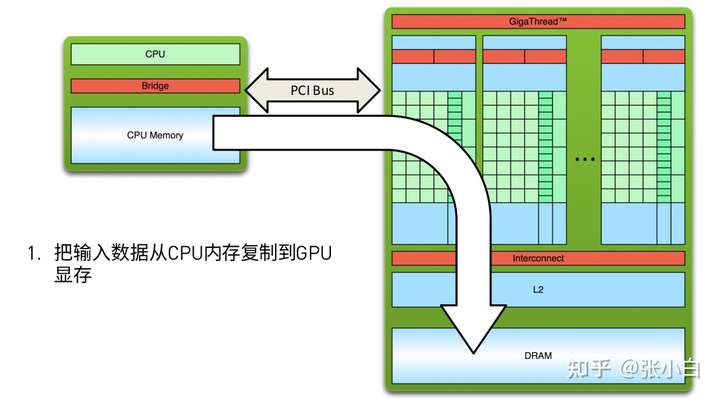
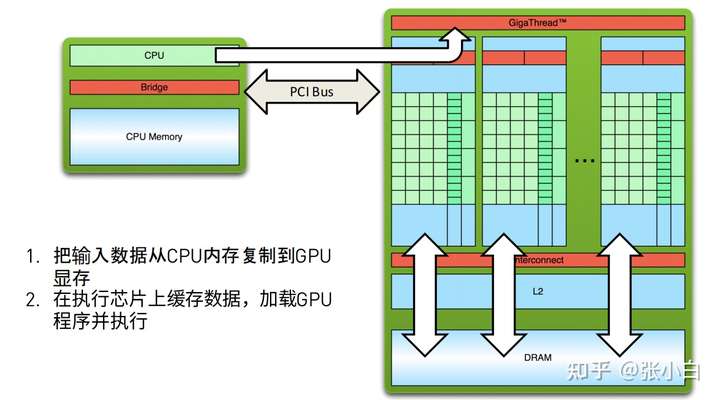
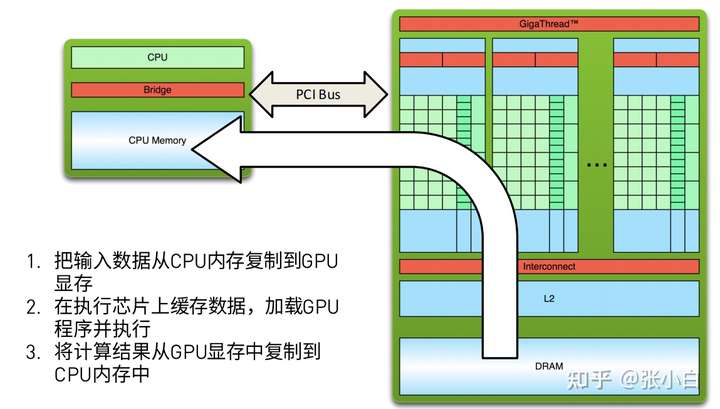
简述一下,就是 host_to_device-》在device上并行计算-》device_to_host。
cuda程序其实是一个对C的扩展程序。其后缀名为.cu,如果头文件则为.cuh。
这个.cu 程序除了C程序的语法外,还有一些cuda的特有部分,比如它在函数前面加了前缀,分为 __global__, __host__,__device__ 三种。
对于__global__,训练营是这么说的:

所谓的“执行配置”,下面会提到,比如说是 <<< >>>中间的内容。
这个标识符将一个C函数声明成一个 核函数。它只能在设备(device)上执行。
对于__host__ 是这么说的:

对于__device__ 是这么说的:

个人理解,这几个前缀定义了这些代码运行的设备,这会让程序决定在哪个设备上运行。
对于一个简单的Hello World代码而言:
#include <stdio.h>
void hello_from_cpu()
{
printf("Hello World from the CPU!\n");
}
int main(void)
{
hello_from_cpu();
return 0;
}如果我们想让它在GPU上运行,仅需要做两步:
(1)将被调用的函数 hello_from_cpu 改为 hello_from_gpu ,前面加上 __global__ 将其定义为核函数。
(2)在main主函数调用的时候,加上执行配置<<< >>>部分,如加上<<<1,1>>>则为并行1次,如加上<<<2,4>>>则运行 2X4次。
我们看看实际代码修改后的效果:
#include <stdio.h>
__global__ void hello_from_gpu()
{
printf("Hello World from the GPU!\n");
}
int main(void)
{
hello_from_gpu<<<1,1>>>();
return 0;
}cu代码必须使用nvcc编译,编译的时候要根据GPU架构的不同填不同的参数。

其中,arch参数如下:
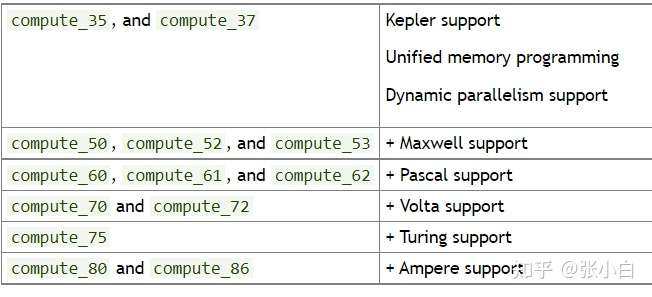
code参数如下:
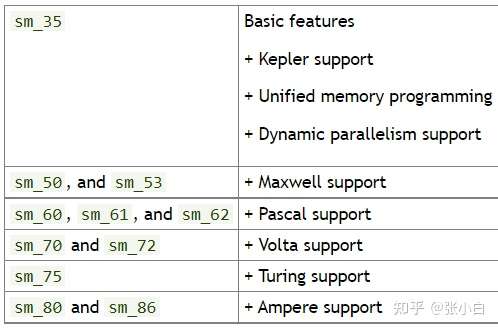
举个简单的例子,张小白这台笔记本的显卡是Quardo P1000,是Pascal架构,那么参数是compute_61和sm_61.
我们执行以下语句:
/usr/local/cuda/bin/nvcc -arch=compute_61 -code=sm_61 hello_cuda.cu -o hello_cuda
./hello_cuda
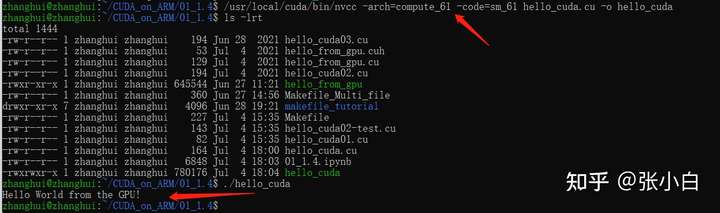
如果将执行配置改为2,4:

可以发现这个核函数被执行了8次。
下面我们来看看这段代码能不能使用jupyter lab执行。
我们解压下 训练营提供的 jupyter练习包:CUDA_on_ARM.zip
解压:unzip,要想执行先得装unzip:
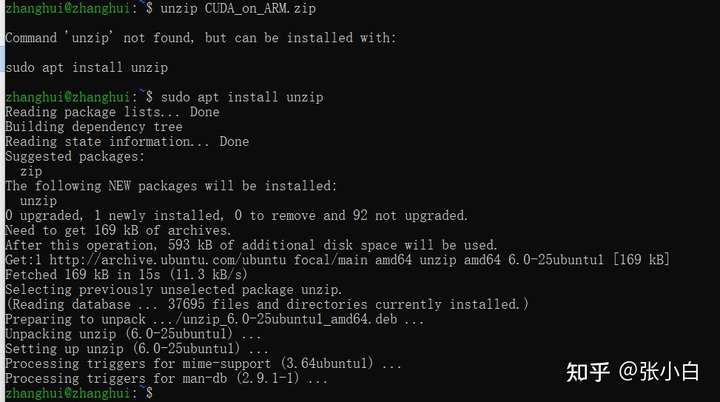
执行解压:unzip CUDA_on_ARM.zip
安装PIP:
sudo apt install python3-pip
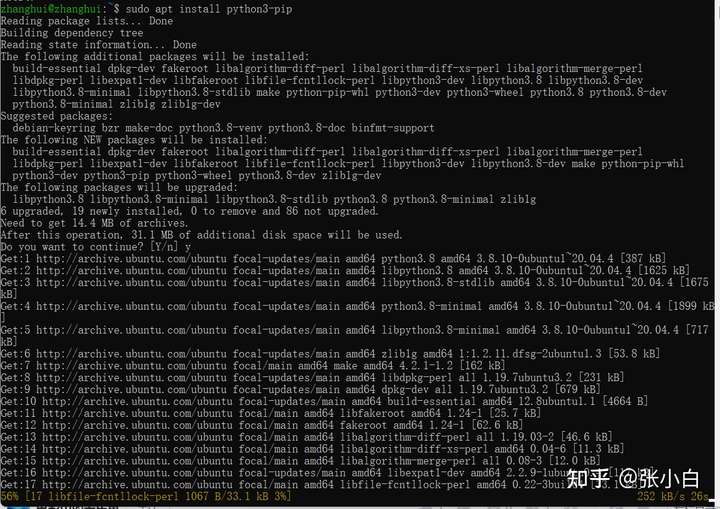
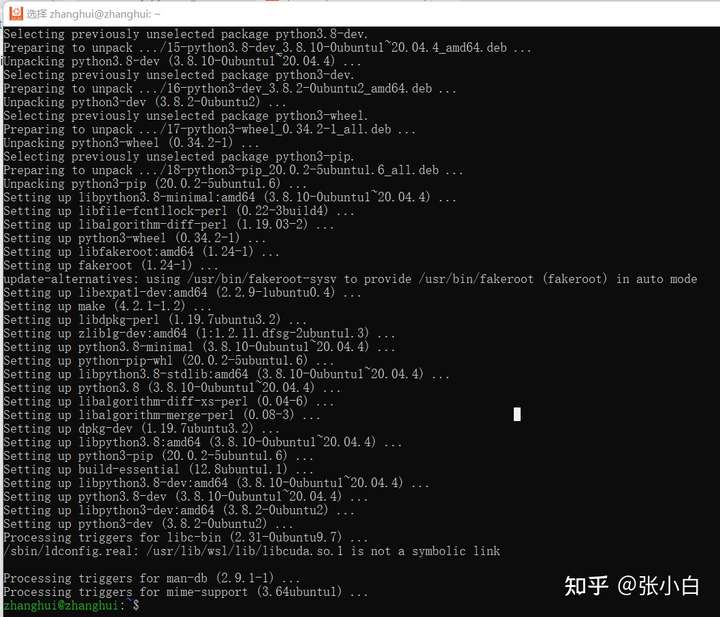

看来python3和pip都准备OK了。
pip install jupyterlab -i https://pypi.tuna.tsinghua.edu.cn/simple
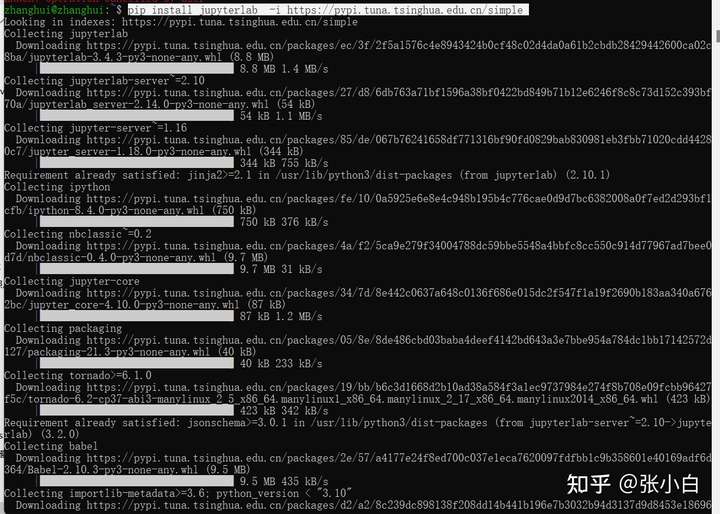
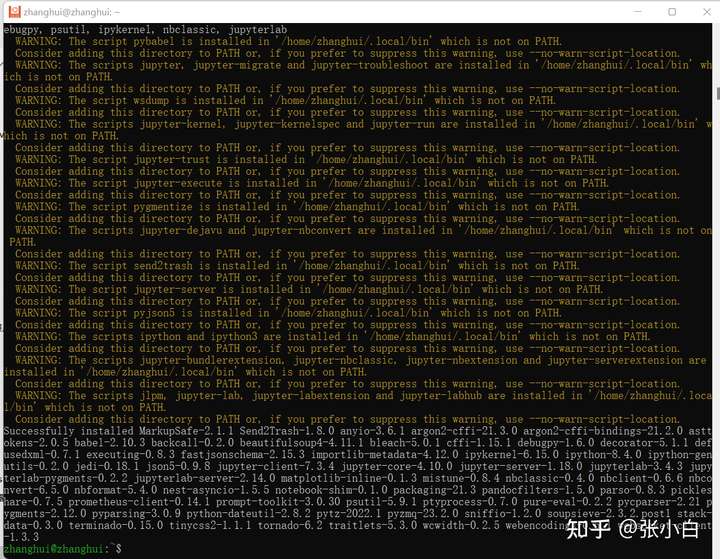
sudo apt install jupyter
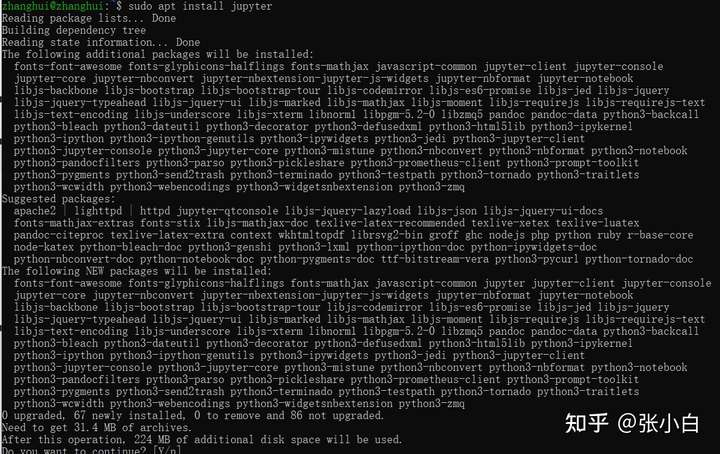
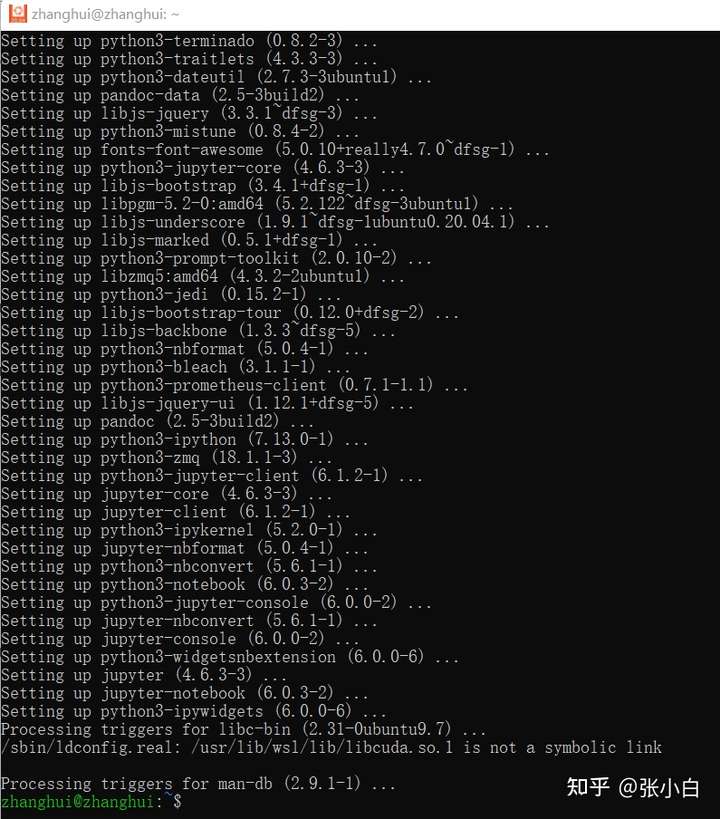
启动 jupyter lab --no-browser看看:
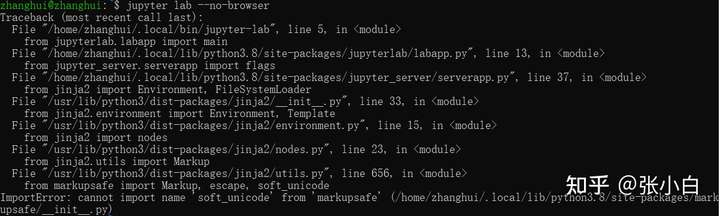
报错了,没关系,度娘一下:https://blog.csdn.net/weixin_45438997/article/details/124261720
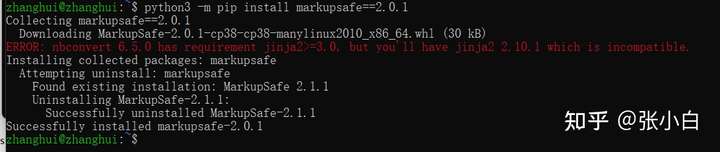
pip show markupsafe
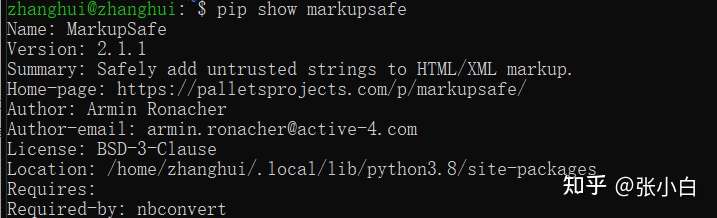
python -m pip install markupsafe==2.0.1
重新启动:jupyter lab --no-browser
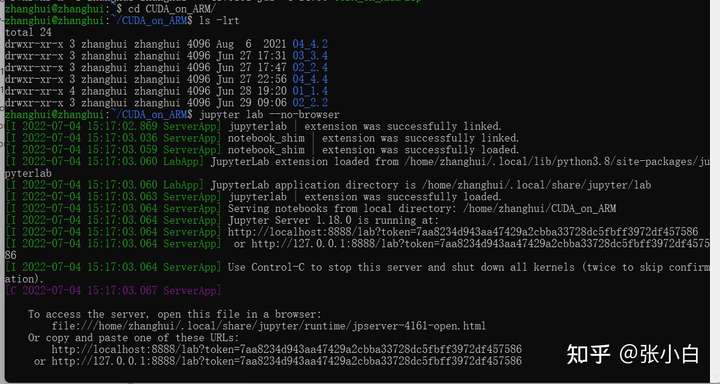
当然启动前可以先设一下密码:
jupyter server password
输入两次123456

浏览器打开:http://127.0.0.1:8888/lab
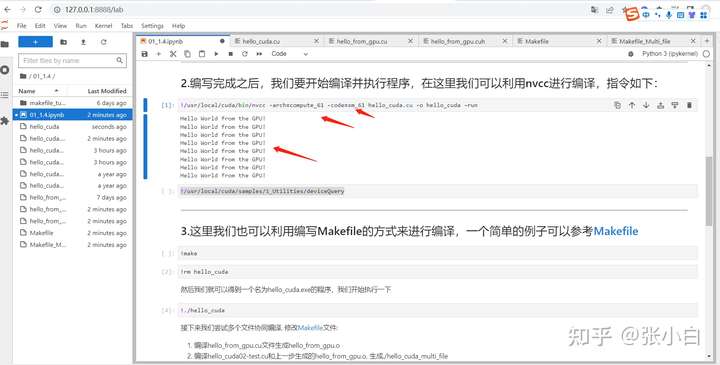
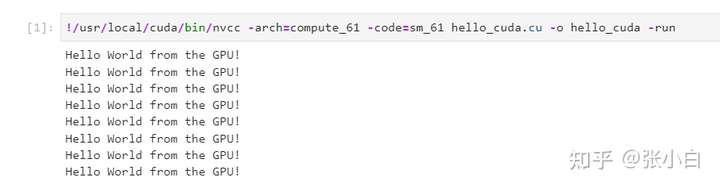
可见,在jupyter lab中也可以体验CUDA代码的。
(未完待续)

- 点赞
- 收藏
- 关注作者
评论(0)