2022CUDA夏季训练营Day3实践


2022CUDA夏季训练营Day1实践 https://bbs.huaweicloud.com/blogs/364478
2022CUDA夏季训练营Day2实践 https://bbs.huaweicloud.com/blogs/364479
今天是第三天,主题是Event,Memory和Shared Memory。
(一)Event
我们先来看第一个——Event。
Event是CUDA中的事件,用于分析、检测CUDA程序中的错误。
一般我们会定义一个宏:
#pragma once
#include <stdio.h>
#define CHECK(call) \
do \
{ \
const cudaError_t error_code = call; \
if (error_code != cudaSuccess) \
{ \
printf("CUDA Error:\n"); \
printf(" File: %s\n", __FILE__); \
printf(" Line: %d\n", __LINE__); \
printf(" Error code: %d\n", error_code); \
printf(" Error text: %s\n", \
cudaGetErrorString(error_code)); \
exit(1); \
} \
} while (0)并在适当的位置使用这个宏来打印CUDA的错误日志。
注:#pragma once, 不要放在源代码文件里,这个一般只放在头文件里的。(防止头文件被引入多次)
具体的调用过程如下:

具体的顺序如下:
(1)声明Event(这里以计算核函数运行时间前后的start Event和stop Event为例)
cudaEvent_t start, stop;(2)创建Event
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop));(3)添加Event(在合适的地方)
cudaEventRecord(start);
cudaEventRecord(stop);(4)等待Event完成
(a)非堵塞方式——可以用于一些不需要等待的处理
cudaEventQuery(start);(b)堵塞方式——可以用于执行核函数后等待核函数执行完毕后的处理
cudaEventSynchronize(stop);(5)计算两个Event间隔时间
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));(6)销毁Event
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop));完整的代码如下:
#pragma once
#include <stdio.h>
#define CHECK(call) \
do \
{ \
const cudaError_t error_code = call; \
if (error_code != cudaSuccess) \
{ \
printf("CUDA Error:\n"); \
printf(" File: %s\n", __FILE__); \
printf(" Line: %d\n", __LINE__); \
printf(" Error code: %d\n", error_code); \
printf(" Error text: %s\n", \
cudaGetErrorString(error_code)); \
exit(1); \
} \
} while (0)
#include <stdio.h>
#include <math.h>
#include "error.cuh"
#define BLOCK_SIZE 32
__global__ void gpu_matrix_mult(int *a,int *b, int *c, int m, int n, int k)
{
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
int sum = 0;
if( col < k && row < m)
{
for(int i = 0; i < n; i++)
{
sum += a[row * n + i] * b[i * k + col];
}
c[row * k + col] = sum;
}
}
void cpu_matrix_mult(int *h_a, int *h_b, int *h_result, int m, int n, int k) {
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
int tmp = 0.0;
for (int h = 0; h < n; ++h)
{
tmp += h_a[i * n + h] * h_b[h * k + j];
}
h_result[i * k + j] = tmp;
}
}
}
int main(int argc, char const *argv[])
{
int m=100;
int n=100;
int k=100;
//声明Event
cudaEvent_t start, stop, stop2, stop3 , stop4 ;
//创建Event
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop));
CHECK(cudaEventCreate(&stop2));
int *h_a, *h_b, *h_c, *h_cc;
CHECK(cudaMallocHost((void **) &h_a, sizeof(int)*m*n));
CHECK(cudaMallocHost((void **) &h_b, sizeof(int)*n*k));
CHECK(cudaMallocHost((void **) &h_c, sizeof(int)*m*k));
CHECK(cudaMallocHost((void **) &h_cc, sizeof(int)*m*k));
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
h_a[i * n + j] = rand() % 1024;
}
}
for (int i = 0; i < n; ++i) {
for (int j = 0; j < k; ++j) {
h_b[i * k + j] = rand() % 1024;
}
}
int *d_a, *d_b, *d_c;
CHECK(cudaMalloc((void **) &d_a, sizeof(int)*m*n));
CHECK(cudaMalloc((void **) &d_b, sizeof(int)*n*k));
CHECK(cudaMalloc((void **) &d_c, sizeof(int)*m*k));
// copy matrix A and B from host to device memory
CHECK(cudaMemcpy(d_a, h_a, sizeof(int)*m*n, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_b, h_b, sizeof(int)*n*k, cudaMemcpyHostToDevice));
unsigned int grid_rows = (m + BLOCK_SIZE - 1) / BLOCK_SIZE;
unsigned int grid_cols = (k + BLOCK_SIZE - 1) / BLOCK_SIZE;
dim3 dimGrid(grid_cols, grid_rows);
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
//开始start Event
cudaEventRecord(start);
//非阻塞模式
cudaEventQuery(start);
//gpu_matrix_mult<<<dimGrid, dimBlock>>>(d_a, d_b, d_c, m, n, k);
gpu_matrix_mult_shared<<<dimGrid, dimBlock>>>(d_a, d_b, d_c, m, n, k);
//开始stop Event
cudaEventRecord(stop);
//由于要等待核函数执行完毕,所以选择阻塞模式
cudaEventSynchronize(stop);
//计算时间 stop-start
float elapsed_time;
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));
printf("start-》stop:Time = %g ms.\n", elapsed_time);
cudaMemcpy(h_c, d_c, (sizeof(int)*m*k), cudaMemcpyDeviceToHost);
//cudaThreadSynchronize();
//开始stop2 Event
CHECK(cudaEventRecord(stop2));
//非阻塞模式
//CHECK(cudaEventSynchronize(stop2));
cudaEventQuery(stop2);
//计算时间 stop-stop2
float elapsed_time2;
cudaEventElapsedTime(&elapsed_time2, stop, stop2);
printf("stop-》stop2:Time = %g ms.\n", elapsed_time2);
//销毁Event
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop));
CHECK(cudaEventDestroy(stop2));
//CPU函数计算
cpu_matrix_mult(h_a, h_b, h_cc, m, n, k);
int ok = 1;
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
if(fabs(h_cc[i*k + j] - h_c[i*k + j])>(1.0e-10))
{
ok = 0;
}
}
}
if(ok)
{
printf("Pass!!!\n");
}
else
{
printf("Error!!!\n");
}
// free memory
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
cudaFreeHost(h_a);
cudaFreeHost(h_b);
cudaFreeHost(h_c);
return 0;
}编译时会有些警告,不用管它:
在Quardo P1000的GPU上执行:
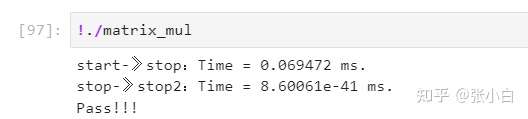
在Jetson Nano B01上执行:

这里以矩阵乘为例,打印了调用矩阵乘核函数的时间,以及后面 cudaMemcpy的时间。
我们强行将
CHECK(cudaMemcpy(d_b, h_b, sizeof(int)*n*k, cudaMemcpyHostToDevice));改为
CHECK(cudaMemcpy(d_b, h_b, sizeof(int)*n*k*2, cudaMemcpyHostToDevice));故意让其出界。
再重新编译,运行,看看效果:
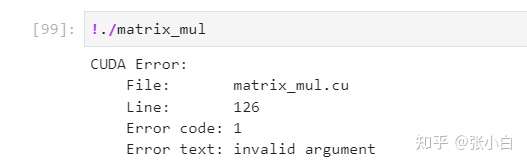
系统会告诉你 这行有错:
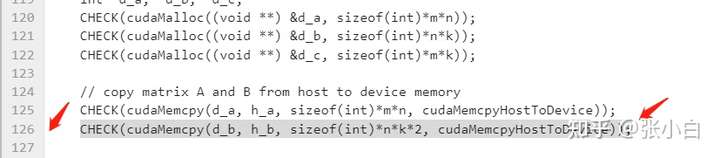
这样就可以跟踪出CUDA调用中的错误。
这里需要总结一下张小白在调试CHECK过程中发现的几个问题:
(1)如果没有 CHECK(cudaEventCreate()) 就直接调用 cudaEventRecord() 或者执行后面的Event函数,会导致打印不了信息。张小白当时对于stop2这个event就犯了这个错,导致 stop->stop2的时间怎么都打不出来。
(2)对于 cudaEventQuery() 是不能加 CHECK的,如果加了反而会报错:
在上面的环境中,如果您这样写:
CHECK(cudaEventQuery(stop2));编译执行就会出现以下错误:
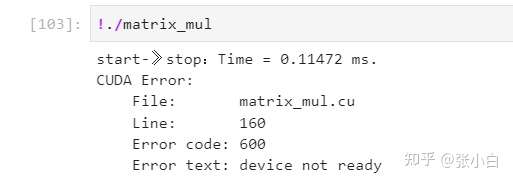
注:cudaEventQuery的cudaErrorNotReady代表了事件还没发生(还没有被记录),不代表错误。
使用Nano查看下性能:
!echo nano | sudo -S /usr/local/cuda/bin/nvprof ./matrix_mul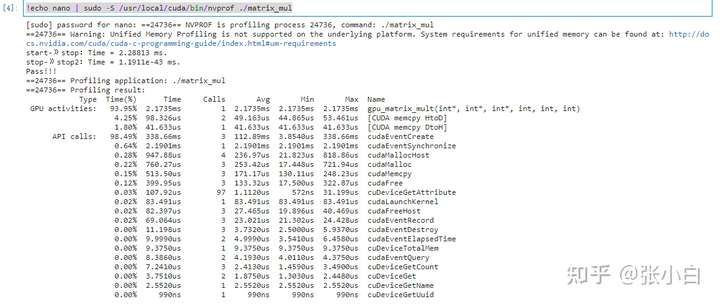
(二)Memory
这里讲的是CUDA存储单元,其实Day2也提到过:

今天再进一步说一下:
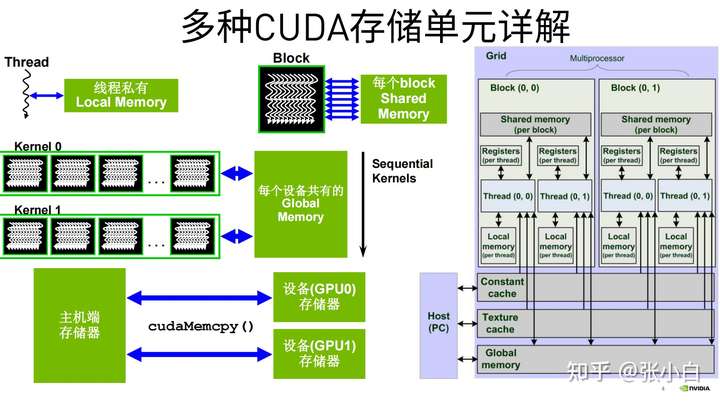
张小白整理了以下表格:(不见得全,还需要完善)
| 名称 | 位置 | 用途 | 使用方法 | 限制 | 备注 |
|---|---|---|---|---|---|
| Register寄存器 | GPU的SM上 | 存储局部变量 | 每个SM上有成千上万个 一个线程最大数量为256个 需要省着用 |
线程私有,最快 线程退出则失效 |
|
| Shared memory | GPU芯片上 | 实现Block内的线程通信,目前最快的多Thread沟通的地方 | __shared__修饰符 需要__syncThreads()同步 |
分为32个banks 需要省着用,会影响活动warp数量 |
可被1个block所有thread访问,次快 高带宽,低延迟 |
| Local memory | 存放单线程的大型数组和变量(Register不够时用它) | 没有特定的存储单元 | 线程私有,速度较慢,速度与Global memory接近 | ||
| Constant memory 常量内存 |
驻留在device memory中 | 用于同一warp的所有thread同时访问同样的常量数据,比如光线追踪 | __constant__修饰符 必须在host端使用 cudaMemcpyToSymbol初始化 |
没有特定的存储单元,但是有单独的缓存 | 只读,全局 |
| Global memory | 等同于GPU显存 驻留在device memory中 |
输入数据,写入结果 | 全局,速度较慢 | ||
| Texture memory 纹理内存 |
用于加速局部性访问,比如热传导模型 | 只读,全局,速度次于Shared Memory(延迟比Shared Memory高,带宽比hared Memory小) | |||
| Host memory: 可分页内存 |
主机端内存 | 使用malloc访问使用free释放 | 不可以使用DMA访问 | 内存页可以置换到磁盘中 | |
| 另一种Host memory: 又称: Page-locked Memory,Zero-Copy Memory |
主机端内存 | 使用cudaMallocHost访问 使用cudaFreeHost释放 |
属于另一种Global memory | ||
(三)Shared Memory
这里主要介绍了如何使用Shared Memory优化CUDA应用
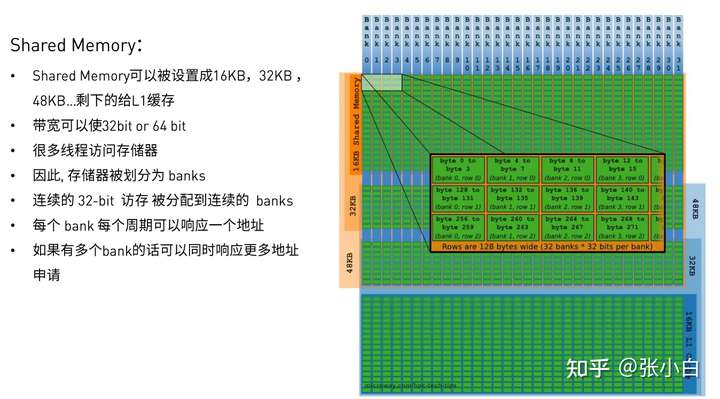
Shared Memory的特点是快的时候特别快,慢的时候特别慢。
什么时候快?
同一warp中所有线程访问不同的banks
或者 同一warp中所有线程读取同一地址(通过广播)
什么时候慢?
同一warp中多个线程访问同一个bank的不同地址(此时将产生 bank conflict)
串行访问
请注意:bank conflict发生的原因就是 warp的分配和bank的分配重叠了:

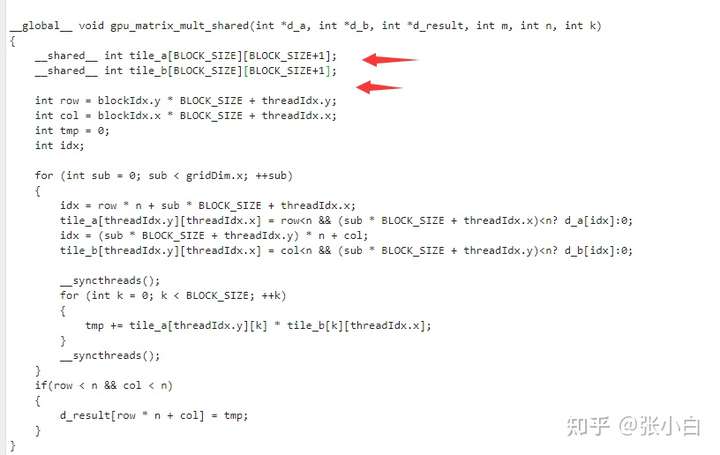
如何避免bank conflict,简单的方法是Padding法(好像叫做补边):
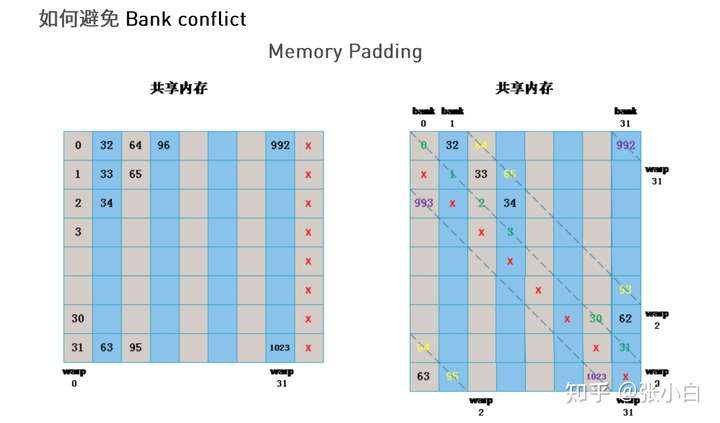
通过增加一个空列,让bank强行错位,使得每段连续的数据被分配到不同的bank中。
具体做法很简单:

就是在设置Shared Memory的时候,不设置成 方阵BLOCK_SIZE X BLOCK_SIZE,而设置成 BLOCK_SIZE X (BLOCK_SIZE+1).
最后,我们可以使用Shared Memory优化mXn, nXk的矩阵乘 的代码,提高访存的效率。
具体方法如下:
申请两块 Shared Memory,都是BLOCK_SIZE X BLOCK_SIZE 大小。一个沿着矩阵mXn滑动,一个沿着矩阵 nXk滑动。将 子集的结果累加到 目的矩阵中:
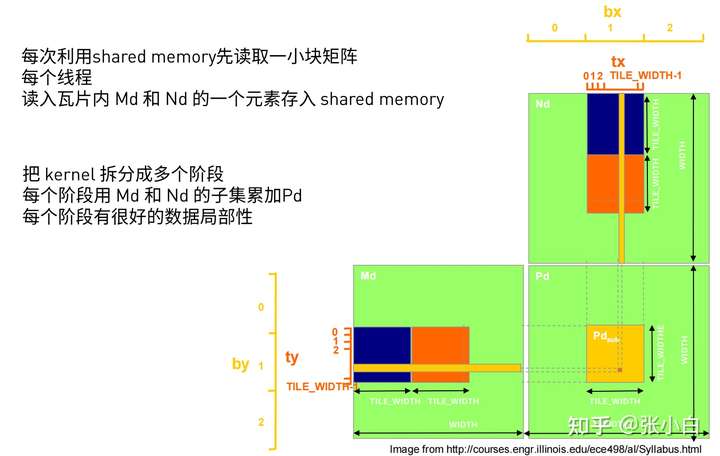
具体的代码如下:
__global__ void gpu_matrix_mult_shared(int *d_a, int *d_b, int *d_result, int m, int n, int k)
{
__shared__ int tile_a[BLOCK_SIZE][BLOCK_SIZE];
__shared__ int tile_b[BLOCK_SIZE][BLOCK_SIZE];
int row = blockIdx.y * BLOCK_SIZE + threadIdx.y;
int col = blockIdx.x * BLOCK_SIZE + threadIdx.x;
int tmp = 0;
int idx;
for (int sub = 0; sub < gridDim.x; ++sub)
{
idx = row * n + sub * BLOCK_SIZE + threadIdx.x;
tile_a[threadIdx.y][threadIdx.x] = row<n && (sub * BLOCK_SIZE + threadIdx.x)<n? d_a[idx]:0;
idx = (sub * BLOCK_SIZE + threadIdx.y) * n + col;
tile_b[threadIdx.y][threadIdx.x] = col<n && (sub * BLOCK_SIZE + threadIdx.y)<n? d_b[idx]:0;
__syncthreads();
for (int k = 0; k < BLOCK_SIZE; ++k)
{
tmp += tile_a[threadIdx.y][k] * tile_b[k][threadIdx.x];
}
__syncthreads();
}
if(row < n && col < n)
{
d_result[row * n + col] = tmp;
}
}
并将前面 代码中调用矩阵乘的地方:
gpu_matrix_mult<<<dimGrid, dimBlock>>>(d_a, d_b, d_c, m, n, k); 改为
gpu_matrix_mult_shared<<<dimGrid, dimBlock>>>(d_a, d_b, d_c, m, n, k); 其余不变。
开始编译,在Jetson Nano B01上执行:
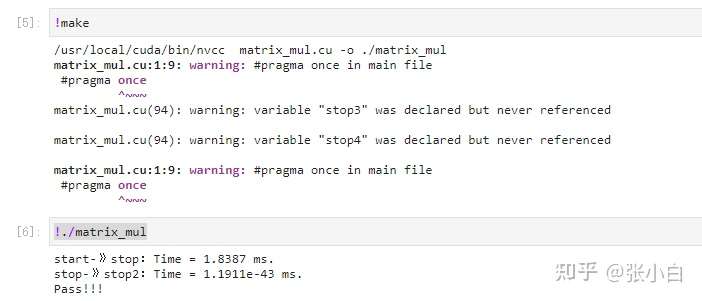
比较前面的矩阵乘代码,start-》stop:Time = 2.25109 ms 时间略有下降。
张小白于是修改blocksize,将其分别改为 16,8,4,再进行统计汇总:
| 矩阵MXN(m) | 矩阵NXK(n) | 矩阵NXK(k) | blocksize | stop-start(ms) |
|---|---|---|---|---|
| 100 | 100 | 100 | 32 | 1.83286 |
| 100 | 100 | 100 | 16 | 1.27365 |
| 100 | 100 | 100 | 8 | 1.23292 |
| 100 | 100 | 100 | 4 | 3.52865 |
| 100 | 100 | 100 | 6(补测) | 2.1999 |
| 100 | 100 | 100 | 12(补测) | 1.34755 |
从上面的结果来看,blocksize为8,16,32时好像差异不大,但是blocksize为4的时候速度降得比较厉害。从100为4的倍数来看。貌似是这个时候wrap和bank重叠了。
那我们使用Padding大法看看:

将tile_a和tile_b的方阵改为补边的不方阵:
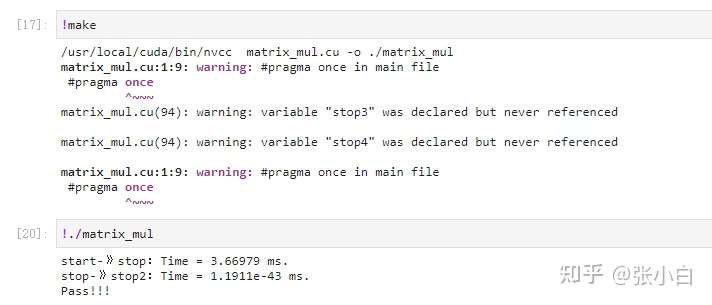
好像效果也不是很好。
注:在blocksize为4时,其实并没有发生bank conflict!而只是因为4X4,只有16个线程,而一个warp需要32个线程,所以相当于计算时,有一半算力被浪费掉了,进而速度慢了一倍。欢老师建议,至少应该NXN>32比较好。
于是张小白将blocksize设成6,又试了一下,结果插入了上述表格。当然,速度还是略有下降(下面也是一样)。我个人猜测,如果是六六三十六,其实32个线程一个warp,反而需要2个warp才能完成工作,所以速度还是不行。张小白猜想应该把blocksize的平方设成32的倍数是最合适的。比如八八六十四。。。12X12=32X4.5,好像也不大合适。。但是可能会因为使用较多而速度略有提高(事实证明好像也是如此)
张小白担心是矩阵太小的缘故,将 矩阵从100改为1000试试。
但是发现一旦改为1000后,CPU计算可能算不过来了:
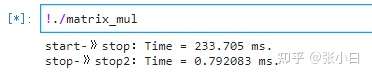
只好将CPU那部分代码和后面比较的代码屏蔽掉。

再重新统计:
| 矩阵MXN(m) | 矩阵NXK(n) | 矩阵NXK(k) | blocksize | stop-start(ms) |
|---|---|---|---|---|
| 1000 | 1000 | 1000 | 32 | 265.106 |
| 1000 | 1000 | 1000 | 16 | 228.09 |
| 1000 | 1000 | 1000 | 8 | 202.382 |
| 1000 | 1000 | 1000 | 4 | 518.315 |
| 1000 | 1000 | 1000 | 6(补测) | 386.171 |
| 1000 | 1000 | 1000 | 12(补测) | 246.29 |
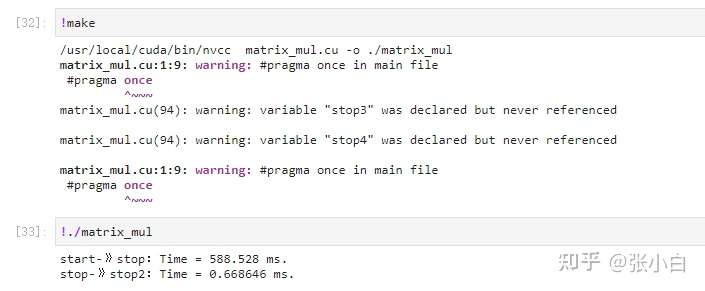
张小白用Padding法试了一下:
好像也没有得到提速的效果:(反而更慢了)
注:同理,其实并没有发生什么bank conflict,都是张小白心里在YY。。
(未完待续)

- 点赞
- 收藏
- 关注作者
评论(0)