2022CUDA夏季训练营Day4实践之原子操作


2022CUDA夏季训练营Day1实践 https://bbs.huaweicloud.com/blogs/364478
2022CUDA夏季训练营Day2实践 https://bbs.huaweicloud.com/blogs/364479
2022CUDA夏季训练营Day3实践 https://bbs.huaweicloud.com/blogs/364480
2022CUDA夏季训练营Day4实践之统一内存 https://bbs.huaweicloud.com/blogs/364481
今天是第四天,主题是统一内存、原子操作等。
(二)原子操作
CUDA的原子操作针对的是Global Memory或者是Shared Memory。
为什么要引入原子操作这个概念。我们从前几天的训练营课程得知:
- Shared Memory是可被同一个block的所有thread访问(读写)的。
- Global Memory相当于显存,可以被所有thread访问(读写)的。
那么,这两种Memory,就很可能会遇到多个thread同时读写同一块内存区域的问题。
假如两个线程都在做“读取-修改-写入"操作,如果在这个操作中,出现互相交错的情况,就会出现混乱。举个例子,比如有块内存里面的值是10,A、B两个用途为”加一“的线程同时读该块内存,然后各自都加1,A将值变为11,再写回去;B也将值改为11,也写了回去。这个时候,结果就变成了11。但是显然我们要求的结果应为12。
我们只好要求将“读取-修改-写入"捆绑成一个逻辑上的单体操作,不可拆分,逻辑上顺序进行,保证一次性成功。这样才能确保任何一次的操作对变量的操作结果的正确性。
常用的原子操作函数如下:
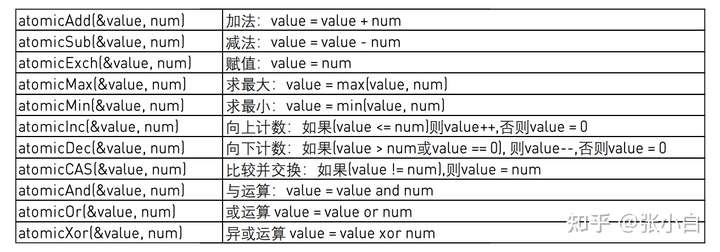
这些函数大多会返回原子操作前的变量值。
原子操作的函数存在多态,适用于不同数据类型和精度的版本,以atomicAdd为例:

我们来实战吧!
(a)实战1:对1000万的整型数组求和
关于对向量所有元素求和这个事情,讲师何老师提供了一个框架。他通过ppt介绍了这个框架的原理。看起来比较复杂。他以只有32个数据的求和为例图示了这个过程:

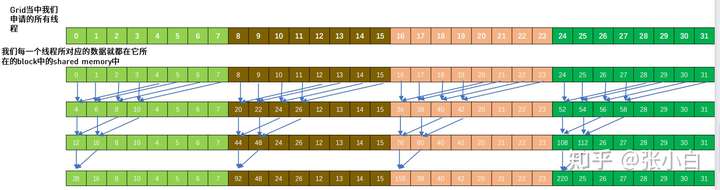
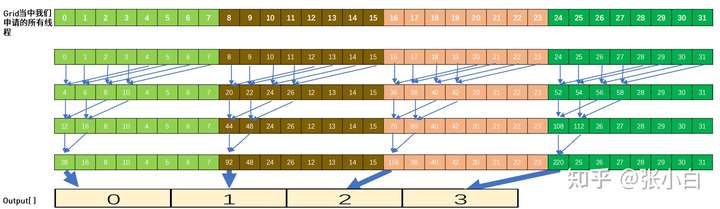
具体的代码如下:
sum.cu
#include<stdio.h>
#include<stdint.h>
#include<time.h> //for time()
#include<stdlib.h> //for srand()/rand()
#include<sys/time.h> //for gettimeofday()/struct timeval
#include"error.cuh"
#define N 10000000
#define BLOCK_SIZE 256
#define BLOCKS ((N + BLOCK_SIZE - 1) / BLOCK_SIZE)
__managed__ int source[N]; //input data
__managed__ int final_result[1] = {0}; //scalar output
__global__ void _sum_gpu(int *input, int count, int *output)
{
__shared__ int sum_per_block[BLOCK_SIZE];
int temp = 0;
for (int idx = threadIdx.x + blockDim.x * blockIdx.x;
idx < count;
idx += gridDim.x * blockDim.x
)
{
temp += input[idx];
}
sum_per_block[threadIdx.x] = temp; //the per-thread partial sum is temp!
__syncthreads();
//**********shared memory summation stage***********
for (int length = BLOCK_SIZE / 2; length >= 1; length /= 2)
{
int double_kill = -1;
if (threadIdx.x < length)
{
double_kill = sum_per_block[threadIdx.x] + sum_per_block[threadIdx.x + length];
}
__syncthreads(); //why we need two __syncthreads() here, and,
if (threadIdx.x < length)
{
sum_per_block[threadIdx.x] = double_kill;
}
__syncthreads(); //....here ?
} //the per-block partial sum is sum_per_block[0]
if (blockDim.x * blockIdx.x < count) //in case that our users are naughty
{
//the final reduction performed by atomicAdd()
if (threadIdx.x == 0) atomicAdd(output, sum_per_block[0]);
}
}
int _sum_cpu(int *ptr, int count)
{
int sum = 0;
for (int i = 0; i < count; i++)
{
sum += ptr[i];
}
return sum;
}
void _init(int *ptr, int count)
{
uint32_t seed = (uint32_t)time(NULL); //make huan happy
srand(seed); //reseeding the random generator
//filling the buffer with random data
for (int i = 0; i < count; i++) ptr[i] = rand();
}
double get_time()
{
struct timeval tv;
gettimeofday(&tv, NULL);
return ((double)tv.tv_usec * 0.000001 + tv.tv_sec);
}
int main()
{
//**********************************
fprintf(stderr, "filling the buffer with %d elements...\n", N);
_init(source, N);
//**********************************
//Now we are going to kick start your kernel.
cudaDeviceSynchronize(); //steady! ready! go!
fprintf(stderr, "Running on GPU...\n");
double t0 = get_time();
_sum_gpu<<<BLOCKS, BLOCK_SIZE>>>(source, N, final_result);
CHECK(cudaGetLastError()); //checking for launch failures
CHECK(cudaDeviceSynchronize()); //checking for run-time failurs
double t1 = get_time();
int A = final_result[0];
fprintf(stderr, "GPU sum: %u\n", A);
//**********************************
//Now we are going to exercise your CPU...
fprintf(stderr, "Running on CPU...\n");
double t2 = get_time();
int B = _sum_cpu(source, N);
double t3 = get_time();
fprintf(stderr, "CPU sum: %u\n", B);
//******The last judgement**********
if (A == B)
{
fprintf(stderr, "Test Passed!\n");
}
else
{
fprintf(stderr, "Test failed!\n");
exit(-1);
}
//****and some timing details*******
fprintf(stderr, "GPU time %.3f ms\n", (t1 - t0) * 1000.0);
fprintf(stderr, "CPU time %.3f ms\n", (t3 - t2) * 1000.0);
return 0;
}
由于其原理略有复杂,张小白是这么想的:
以上的代码其实是提供了一个GPU遍历所有字段的框架,这是一个分而治之的思路:
block中的多个线程负责多个数据点,这些点被规约(reduce/缩减)到一个标量。这样每个block中都有一个标量的结果。但blocks有很多,这些变量组成的数组/向量,还需要二次缩减到最终的1个标量值。
以上过程存在两步reduce,第一步用并行折半缩减(规约),第二步直接用原子操作函数atomicAdd规约。两步完成后,得到了单一点。
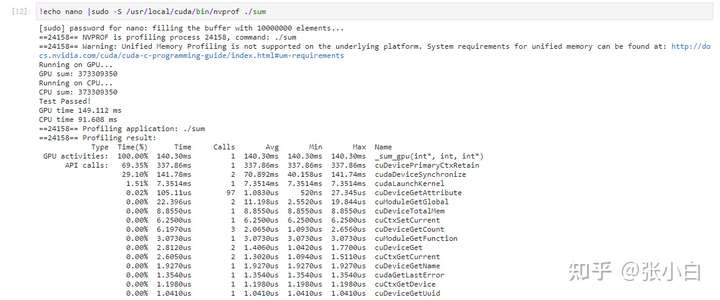
我们运行下试试:
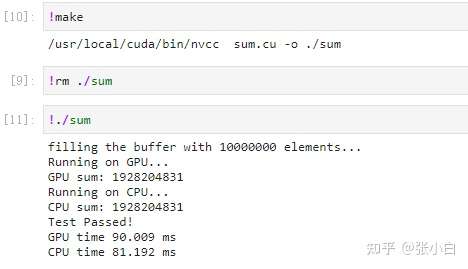
可见,CPU和GPU求和的结果是一致的,说明这个遍历所有字段的框架是没问题的。
看下性能:
(b)实战2:对1000万的整型数组求出最大值和最小值
基于上面实战1分析的原理,我们接着分析本题的解题思路:
同样使用两步reduce,第一步用并行折半缩减(规约),第二步直接用原子操作atomicMax和atomicMin规约。两步完成后,得到了单一点(最大值/最小值)。
于是我们就像搭积木那样,将一个sum改为一个max和一个min,代码变动如下:
min_or_max.cu
#include<stdio.h>
#include<stdint.h>
#include<time.h> //for time()
#include<stdlib.h> //for srand()/rand()
#include<sys/time.h> //for gettimeofday()/struct timeval
#include"error.cuh"
#define N 10000000
#define BLOCK_SIZE 256
#define BLOCKS ((N + BLOCK_SIZE - 1) / BLOCK_SIZE)
__managed__ int source[N]; //input data
//__managed__ int final_result[2] = {INT_MIN,INT_MAX}; //scalar output
__managed__ int final_result_max = INT_MIN; //scalar output
__managed__ int final_result_min = INT_MAX; //scalar output
__global__ void _sum_min_or_max(int *input, int count, int *max_output, int *min_output)
{
__shared__ int max_per_block[BLOCK_SIZE];
__shared__ int min_per_block[BLOCK_SIZE];
int max_temp = 0;
int min_temp = 0;
for (int idx = threadIdx.x + blockDim.x * blockIdx.x;
idx < count;
idx += gridDim.x * blockDim.x
)
{
//temp += input[idx];
max_temp = (input[idx] > max_temp) ? input[idx] :max_temp;
min_temp = (input[idx] < min_temp) ? input[idx] :min_temp;
}
max_per_block[threadIdx.x] = max_temp; //the per-thread partial max is temp!
min_per_block[threadIdx.x] = min_temp; //the per-thread partial max is temp!
__syncthreads();
//**********shared memory summation stage***********
for (int length = BLOCK_SIZE / 2; length >= 1; length /= 2)
{
int max_double_kill = -1;
int min_double_kill = -1;
if (threadIdx.x < length)
{
max_double_kill = (max_per_block[threadIdx.x] > max_per_block[threadIdx.x + length]) ? max_per_block[threadIdx.x] : max_per_block[threadIdx.x + length];
min_double_kill = (min_per_block[threadIdx.x] < min_per_block[threadIdx.x + length]) ? min_per_block[threadIdx.x] : min_per_block[threadIdx.x + length];
}
__syncthreads(); //why we need two __syncthreads() here, and,
if (threadIdx.x < length)
{
max_per_block[threadIdx.x] = max_double_kill;
min_per_block[threadIdx.x] = min_double_kill;
}
__syncthreads(); //....here ?
} //the per-block partial sum is sum_per_block[0]
if (blockDim.x * blockIdx.x < count) //in case that our users are naughty
{
//the final reduction performed by atomicAdd()
//if (threadIdx.x == 0) atomicAdd(output, max_per_block[0]);
if (threadIdx.x == 0) atomicMax(max_output, max_per_block[0]);
if (threadIdx.x == 0) atomicMin(min_output, min_per_block[0]);
}
}
int _max_min_cpu(int *ptr, int count, int *max1, int *min1)
{
int max = INT_MIN;
int min = INT_MAX;
for (int i = 0; i < count; i++)
{
//sum += ptr[i];
max = (ptr[i] > max)? ptr[i]:max;
min = (ptr[i] < min)? ptr[i]:min;
}
//printf(" CPU max = %d\n", max);
//printf(" CPU min = %d\n", min);
*max1 = max;
*min1 = min;
return 0;
}
void _init(int *ptr, int count)
{
uint32_t seed = (uint32_t)time(NULL); //make huan happy
//srand(seed); //reseeding the random generator
//filling the buffer with random data
for (int i = 0; i < count; i++)
{
//ptr[i] = rand() % 100000000;
ptr[i] = rand() ;
if (i % 2 == 0) ptr[i] = 0 - ptr[i] ;
}
}
double get_time()
{
struct timeval tv;
gettimeofday(&tv, NULL);
return ((double)tv.tv_usec * 0.000001 + tv.tv_sec);
}
int main()
{
//**********************************
fprintf(stderr, "filling the buffer with %d elements...\n", N);
_init(source, N);
//**********************************
//Now we are going to kick start your kernel.
cudaDeviceSynchronize(); //steady! ready! go!
fprintf(stderr, "Running on GPU...\n");
double t0 = get_time();
_sum_min_or_max<<<BLOCKS, BLOCK_SIZE>>>(source, N, &final_result_max, &final_result_min);
CHECK(cudaGetLastError()); //checking for launch failures
CHECK(cudaDeviceSynchronize()); //checking for run-time failures
double t1 = get_time();
//int A = final_result[0];
fprintf(stderr, " GPU max: %d\n", final_result_max);
fprintf(stderr, " GPU min: %d\n", final_result_min);
//**********************************
//Now we are going to exercise your CPU...
fprintf(stderr, "Running on CPU...\n");
double t2 = get_time();
int cpu_max=0;
int cpu_min=0;
int B = _max_min_cpu(source, N, &cpu_max, &cpu_min);
printf(" CPU max = %d\n", cpu_max);
printf(" CPU min = %d\n", cpu_min);
double t3 = get_time();
//fprintf(stderr, "CPU sum: %u\n", B);
//******The last judgement**********
if ( final_result_max == cpu_max && final_result_min == cpu_min )
{
fprintf(stderr, "Test Passed!\n");
}
else
{
fprintf(stderr, "Test failed!\n");
exit(-1);
}
//****and some timing details*******
fprintf(stderr, "GPU time %.3f ms\n", (t1 - t0) * 1000.0);
fprintf(stderr, "CPU time %.3f ms\n", (t3 - t2) * 1000.0);
return 0;
}
这里需要指出几点:
(1)初始化最大值变量final_result_max的时候,给它赋最小值INT_MIN;初始化最小值变量final_result_min的时候,给它赋最大值INT_MAX,这样在它比较的时候,就一定会被比下去,换成最新的值。如果有人不小心写反了,那么就完蛋了。不信大家可以试试。
(2)在产生1000万个随机数的时候,张小白采纳了何老师的建议,每两个数就有一个正数,有一个负数。这样不会导致原来取最小值永远是0的情况。
编译运行:
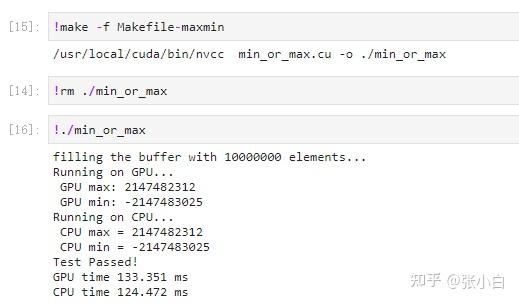
看起来CPU和GPU算出的结果都是一致的。怎么样?简单吧?
上面的代码,张小白偷懒,使用了两个managed变量记录结果,张小白看了看后面的作业,还有一道“找到1000万数据中前10个最大值”的题目,感觉还是用 数组会更合适点。也许可以无缝的升级解决后面这道题,于是张小白又做了以下改动:
#include<stdio.h>
#include<stdint.h>
#include<time.h> //for time()
#include<stdlib.h> //for srand()/rand()
#include<sys/time.h> //for gettimeofday()/struct timeval
#include"error.cuh"
#define N 10000000
#define BLOCK_SIZE 256
#define BLOCKS ((N + BLOCK_SIZE - 1) / BLOCK_SIZE)
__managed__ int source[N]; //input data
__managed__ int final_result[2] = {INT_MIN,INT_MAX}; //scalar output
//__managed__ int final_result_max = INT_MIN; //scalar output
//__managed__ int final_result_min = INT_MAX; //scalar output
//__global__ void _sum_min_or_max(int *input, int count, int *max_output, int *min_output)
__global__ void _sum_min_or_max(int *input, int count,int *output)
{
__shared__ int max_per_block[BLOCK_SIZE];
__shared__ int min_per_block[BLOCK_SIZE];
int max_temp = 0;
int min_temp = 0;
for (int idx = threadIdx.x + blockDim.x * blockIdx.x;
idx < count;
idx += gridDim.x * blockDim.x
)
{
//temp += input[idx];
max_temp = (input[idx] > max_temp) ? input[idx] :max_temp;
min_temp = (input[idx] < min_temp) ? input[idx] :min_temp;
}
max_per_block[threadIdx.x] = max_temp; //the per-thread partial max is temp!
min_per_block[threadIdx.x] = min_temp; //the per-thread partial max is temp!
__syncthreads();
//**********shared memory summation stage***********
for (int length = BLOCK_SIZE / 2; length >= 1; length /= 2)
{
int max_double_kill = -1;
int min_double_kill = -1;
if (threadIdx.x < length)
{
max_double_kill = (max_per_block[threadIdx.x] > max_per_block[threadIdx.x + length]) ? max_per_block[threadIdx.x] : max_per_block[threadIdx.x + length];
min_double_kill = (min_per_block[threadIdx.x] < min_per_block[threadIdx.x + length]) ? min_per_block[threadIdx.x] : min_per_block[threadIdx.x + length];
}
__syncthreads(); //why we need two __syncthreads() here, and,
if (threadIdx.x < length)
{
max_per_block[threadIdx.x] = max_double_kill;
min_per_block[threadIdx.x] = min_double_kill;
}
__syncthreads(); //....here ?
} //the per-block partial sum is sum_per_block[0]
if (blockDim.x * blockIdx.x < count) //in case that our users are naughty
{
//the final reduction performed by atomicAdd()
//if (threadIdx.x == 0) atomicAdd(output, max_per_block[0]);
//if (threadIdx.x == 0) atomicMax(max_output, max_per_block[0]);
//if (threadIdx.x == 0) atomicMin(min_output, min_per_block[0]);
if (threadIdx.x == 0) atomicMax(&output[0], max_per_block[0]);
if (threadIdx.x == 0) atomicMin(&output[1], min_per_block[0]);
}
}
int _max_min_cpu(int *ptr, int count, int *max1, int *min1)
{
int max = INT_MIN;
int min = INT_MAX;
for (int i = 0; i < count; i++)
{
//sum += ptr[i];
max = (ptr[i] > max)? ptr[i]:max;
min = (ptr[i] < min)? ptr[i]:min;
}
//printf(" CPU max = %d\n", max);
//printf(" CPU min = %d\n", min);
*max1 = max;
*min1 = min;
return 0;
}
void _init(int *ptr, int count)
{
uint32_t seed = (uint32_t)time(NULL); //make huan happy
srand(seed); //reseeding the random generator
//filling the buffer with random data
for (int i = 0; i < count; i++)
{
//ptr[i] = rand() % 100000000;
ptr[i] = rand() ;
if (i % 2 == 0) ptr[i] = 0 - ptr[i] ;
}
}
double get_time()
{
struct timeval tv;
gettimeofday(&tv, NULL);
return ((double)tv.tv_usec * 0.000001 + tv.tv_sec);
}
int main()
{
//**********************************
fprintf(stderr, "filling the buffer with %d elements...\n", N);
_init(source, N);
//**********************************
//Now we are going to kick start your kernel.
cudaDeviceSynchronize(); //steady! ready! go!
fprintf(stderr, "Running on GPU...\n");
double t0 = get_time();
//_sum_min_or_max<<<BLOCKS, BLOCK_SIZE>>>(source, N, &final_result_max, &final_result_min);
_sum_min_or_max<<<BLOCKS, BLOCK_SIZE>>>(source, N,final_result);
CHECK(cudaGetLastError()); //checking for launch failures
CHECK(cudaDeviceSynchronize()); //checking for run-time failures
double t1 = get_time();
//int A = final_result[0];
//fprintf(stderr, " GPU max: %d\n", final_result_max);
//fprintf(stderr, " GPU min: %d\n", final_result_min);
fprintf(stderr, " GPU max: %d\n", final_result[0]);
fprintf(stderr, " GPU min: %d\n", final_result[1]);
//**********************************
//Now we are going to exercise your CPU...
fprintf(stderr, "Running on CPU...\n");
double t2 = get_time();
int cpu_max=0;
int cpu_min=0;
int B = _max_min_cpu(source, N, &cpu_max, &cpu_min);
printf(" CPU max = %d\n", cpu_max);
printf(" CPU min = %d\n", cpu_min);
double t3 = get_time();
//fprintf(stderr, "CPU sum: %u\n", B);
//******The last judgement**********
//if ( final_result_max == cpu_max && final_result_min == cpu_min )
if ( final_result[0] == cpu_max && final_result[1] == cpu_min )
{
fprintf(stderr, "Test Passed!\n");
}
else
{
fprintf(stderr, "Test failed!\n");
exit(-1);
}
//****and some timing details*******
fprintf(stderr, "GPU time %.3f ms\n", (t1 - t0) * 1000.0);
fprintf(stderr, "CPU time %.3f ms\n", (t3 - t2) * 1000.0);
return 0;
}
分别在
定义:
__managed__ int final_result[2] = {INT_MIN,INT_MAX}; //scalar output核函数定义:
__global__ void _sum_min_or_max(int *input, int count,int *output)核函数操作:
if (threadIdx.x == 0) atomicMax(&output[0], max_per_block[0]);
if (threadIdx.x == 0) atomicMin(&output[1], min_per_block[0]); 以及核函数调用:
_sum_min_or_max<<<BLOCKS, BLOCK_SIZE>>>(source, N,final_result);这几个地方做了改动。
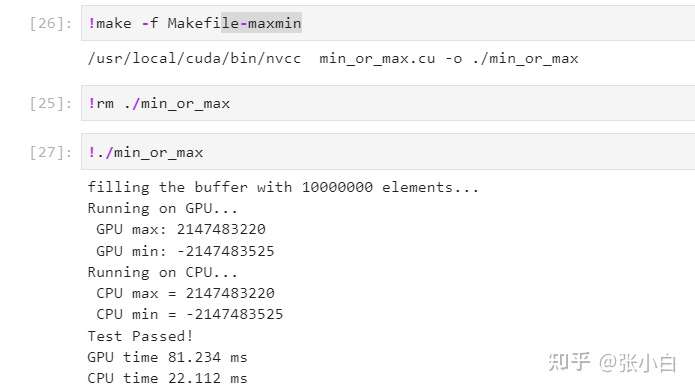
开始编译,运行:
(Quardo P1000上运行)
(Nano上运行)
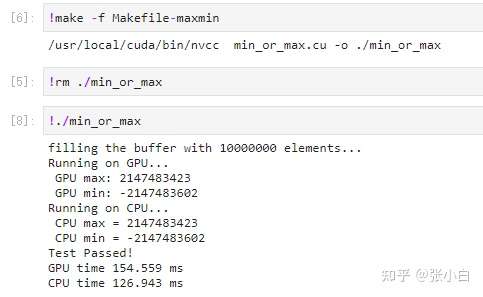
运行没问题,但是貌似GPU运行时间(81ms)比CPU运行时间(22ms)要慢一些。比较在Nano上GPU运行时间(154ms)比CPU运行时间(126ms),好像结果中确实GPU的速度并不占优势。这是什么原因呢?
计算包括访存密集型还是计算密集型等类型。无论是加法,还是max/min,都是访存密集的计算。除非独立显卡,且提前预取或者传输数据到显存,否则GPU无论是managed数据自动迁移,或者GPU和CPU一样的享受同样的带宽(Jetson上),都不会占据优势。
那么,将过程泛化到怎样的f(a,b)操作,才能让GPU具有显著的优势呢?哪怕是在Jetson这种CPU和GPU有同样的访存带宽,或者哪怕是强制走了慢速的PCI-E传输的带宽,GPU依然能比CPU的运算快得多呢?
这个问题,就留给大家思索了!听说阅读 樊哲勇老师的小红书《CUDA 编程:基础与实践》可以找到解决之路哦~~

(未完待续)

- 点赞
- 收藏
- 关注作者
评论(0)