ava集合框架之Set与Map及其相关实现类

⭐️前面的话⭐️
本篇文章带大家认识集合框架—Set与Map及其相关实现类,这是关于集合框架的最后一篇文章,本文将介绍Set与Map及其相关实现类的使用,它们底层的实现原理暂不关心,重点是使用,后续文章将会介绍底层的原理。
📒博客主页:未见花闻的博客主页
🎉欢迎关注🔎点赞👍收藏⭐️留言📝
📌本文由未见花闻原创!
📆华为云首发时间:🌴2022年5月31日🌴
✉️坚持和努力一定能换来诗与远方!
💭参考书籍:📚《Java核心技术》,📚《Java编程思想》,📚《Effective Java》
💬参考在线编程网站:🌐牛客网🌐力扣
博主的码云gitee,平常博主写的程序代码都在里面。
博主的github,平常博主写的程序代码都在里面。
🍭作者水平很有限,如果发现错误,一定要及时告知作者哦!感谢感谢!
题外话:在正式开始之前,我们先来看一看集合框架,画上√的表示博主已经介绍完毕了,可以翻看JavaSE系列专栏进行寻找,画上⭐️表示本文所介绍的内容。
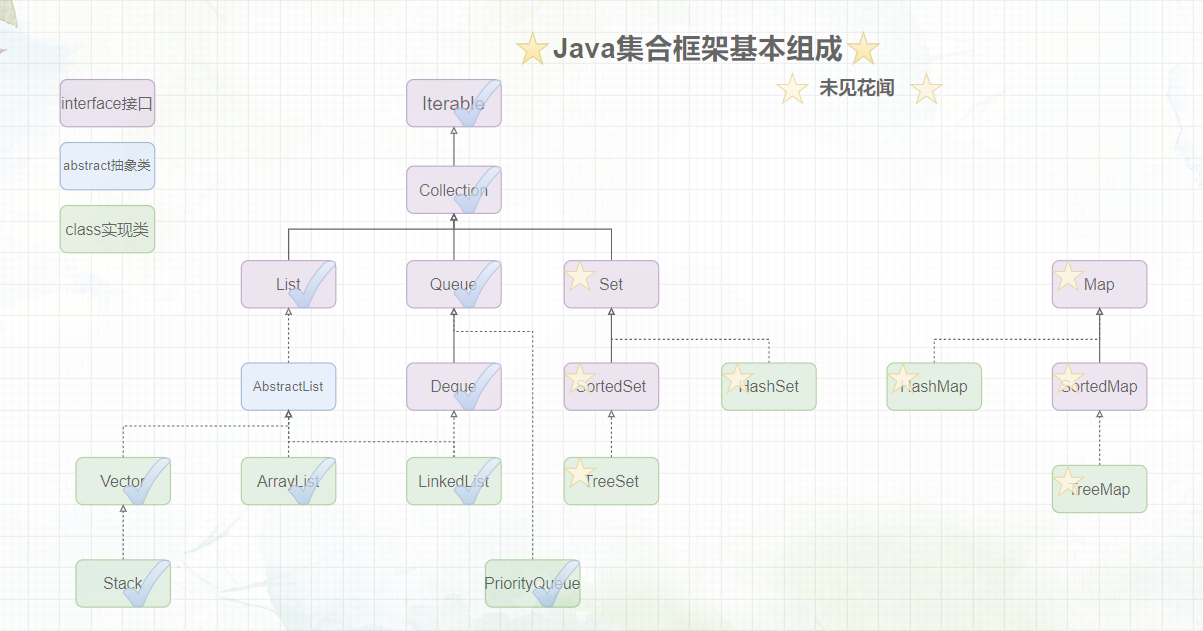
本文会把集合框架剩下的Map和Set介绍完毕,所以,这篇文章是集合框架的完结篇。
1. Map与Set
1.1关于Map与Set
Map和Set是一种专门用来进行搜索的容器或者数据结构,其搜索的效率与其具体的实例化对象有关。
前面我们学习过常见的搜索方式有两个,一个是暴力遍历,另一个是二分查找。
这些查找方法适合静态类型的查找,即一般不会对区间进行插入和删除操作了,而现实中的查找比如:
- 根据姓名查询考试成绩
- 通讯录,即根据姓名查询联系方式
- 不重复集合,即需要先搜索关键字是否已经在集合中
可能在查找时进行一些插入和删除的操作,即动态查找,那上述两种方式就不太适合了,本节介绍的Map和Set是一种适合动态查找的集合容器。
一般把搜索的数据称为关键字(Key),和关键字对应的称为值(Value),将其称之为Key-value的键值对,所以模型会有两种:
- 纯 key 模型,比如查找字典中是否存在一个字母或单词,Set就是一个纯key模型。
- Key-Value 模型,比如统计一个文档中词频情况,Map就是一个key-val模型。
Set表示集合,他不是集合框架中的那个集合,而是数学中的那个集合,所以Set中的元素是不能够重复的,同时Set是一个接口,不能被实例化,只能引用HashSet和TreeSet对象来进行使用,其中HashSet的底层是一个哈希表和TreeSet底层是红黑树,并且TreeSet实现了SortedSet,所以TreeSet对象可以对引用的所有元素进行排序,而HashSet不能,除了这一点,HashSet和TreeSet基本用法都是一样的。
Map表示键值对集合,和Set一样是一个接口,不可以被实例化,需要引用HashMap与TreeMap对象,和HashSet与TreeSet相似,前者通过哈希表实现,后者通过红黑树实现,TreeMap中的元素可以排序,HashMap中的元素不能排序,其他基本上都一样,所以本文只介绍HashSet与HashMap的实现类的具体用法,这两个类知道怎么使用,那么TreeSet与TreeMap类的用法自然也知道了,另一个原因是在工作中HashSet与HashMap用的更多。
Map没有继承自Collection接口,该实现该接口的实现类中存储的是<K,V>结构的键值对,并且K一定是唯一的,不能重复。HashMap对象中键值都可以为null,而TreeMap的键K不能为null值V可以为null。
1.2Map.entry键值对
Map.Entry<K, V> 是Map内部实现的用来存放<key, value>键值对映射关系的内部接口,该内部接口中主要提供了<key, value>的获取,value的设置以及Key的比较方式。
| 方法 | 作用 |
|---|---|
| K getKey(); | 获取Map.Entry<K, V>的key值 |
| V getValue(); | 获取Map.Entry<K, V>的value值 |
| V setValue(V value); | 修改当前Map.Entry<K, V>对象的value值 |
注意:Map.Entry<K,V>并没有提供设置Key的方法。
1.3Map接口中常用方法
| 方法 | 作用 |
|---|---|
| int size(); | 获取map中键值对个数 |
| boolean isEmpty(); | 判断map是否为空表 |
| boolean containsKey(Object key); | 判断map中是否包含关键字key |
| boolean containsValue(Object value); | 判断map中是否包含值value |
| V get(Object key); | 根据关键字key获取value |
| V put(K key, V value); | 增加键值对<key, value>,如果已经存在则更新value值 |
| V remove(Object key); | 根据关键字key删除键值对 |
| void putAll(Map<? extends K, ? extends V> m); | 根据传入的map插入键值对 |
| void clear(); | 清空map |
| Set<K> keySet(); | 获取map中所有的key并放入set集合中 |
| Collection<V> values(); | 获取map中所有的value,并放入collection集合中,可重复 |
| Set<Map.Entry<K, V>> entrySet(); | 将map中所有的键值对以Map.Entry<K,V>类型打包到set中 |
| default V getOrDefault(Object key, V defaultValue) | 返回 key 对应的 value,key 不存在,返回默认值 |
| default V replace(K key, V value) | 修改key关键字对应的value |
| default boolean replace(K key, V oldValue, V newValue) | 将关键字对应的oldValue修改为newValue |
Map中键值对的Key不能直接修改,value可以修改,如果要修改key,只能先将该key删除掉,然后再来进行重新插入。
1.4Set接口中常用方法
Set接口中大部分方法都是从Collection接口中扩展的,常用方法如下:
| 方法 | 作用 |
|---|---|
| int size(); | 获取集合中元素的个数 |
| boolean isEmpty(); | 判断集合是否为空表 |
| boolean contains(Object o); | 判断set是否包含对象o |
| Iterator<E> iterator(); | 获取集合迭代器 |
| Object[] toArray(); | 将set转换成Object数组 |
| <T> T[] toArray(T[] a); | 将set转换为数组 |
| boolean add(E e); | 增加元素e |
| boolean remove(Object o); | 删除元素o |
| boolean containsAll(Collection<?> c); | 判断set中是否含有collection对象中所有的元素 |
| boolean addAll(Collection<? extends E> c); | 插入c对象中所有的元素,可以去重 |
| boolean retainAll(Collection<?> c); | 根据c对象中所含有的元素,如果set中也含有该元素,则删除,否则保留 |
| boolean removeAll(Collection<?> c); | 根据c对象元素对应删除set中的元素 |
| void clear(); | 清空set对象里面所有元素 |
2.HashMap与TreeMap
HashMap与TreeMap都实现了Map接口,两者都是以键值对所组成的集合,用法上基本上可以说是一模一样,当然并不是完完全全相同,它们还是有一些区别的:
| Map底层结构 | TreeMap | HashMap |
|---|---|---|
| 底层结构 | 红黑树 | 哈希桶(表) |
| 插入/删除/查找时间复杂度 | O(1) | |
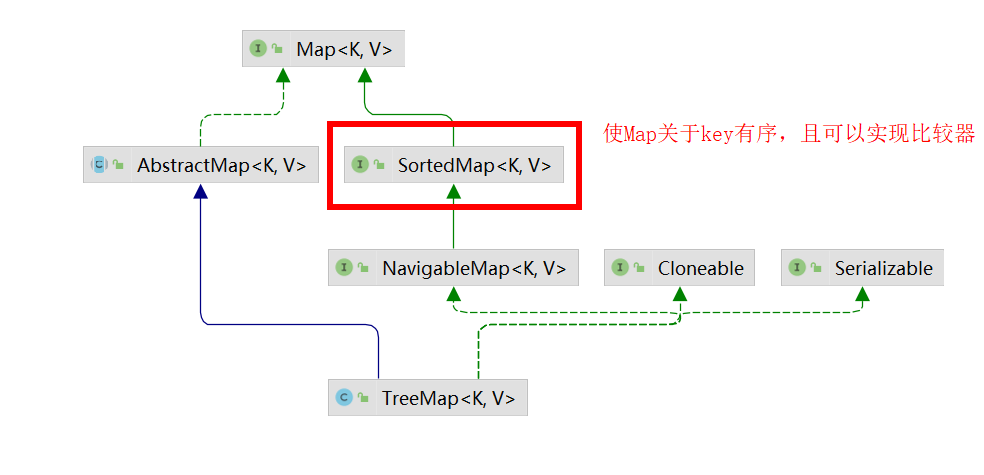
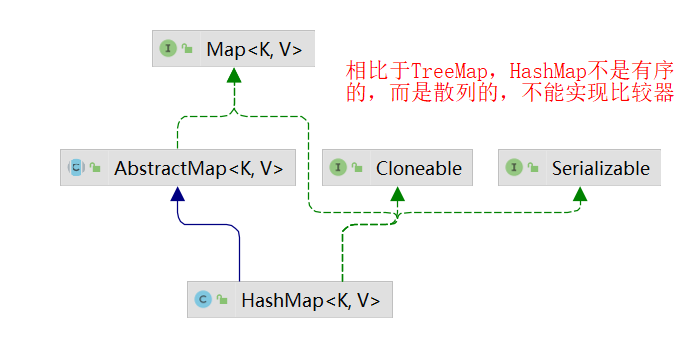
| 是否有序 | 关于Key有序 (因为实现了SortedMap接口) | 无序 (哈希表是散列表) |
| 线程安全 | 不安全 | 不安全 |
| 插入/删除/查找区别 | 需要进行元素比较 | 通过哈希函数计算哈希地址 |
| 比较与覆写 | key必须能够比较,否则会抛出ClassCastException异常 | 自定义类型需要覆写equals和 hashCode方法 |
| 应用场景 | 需要Key有序场景下 | Key是否有序不关心,需要更高的时间性能 |
TreeMap继承图:
HashMap继承图:
它们的增删查改等一些常用方法在介绍Map常用方法的时候都已经说过一遍了,下面只列出它们的构造方法和一些特有且常见的方法。
| TreeMap构造方法 | 作用 |
|---|---|
| public TreeMap() | 无参构造 |
| public TreeMap(Comparator<? super K> comparator) | 传入比较器,能够控制Mapk的key的排序 |
| public TreeMap(Map<? extends K, ? extends V> m) | 根据传入的map对象来构造新的Treemap对象 |
| public TreeMap(SortedMap<K, ? extends V> m) | 根据传入的SortedMap对象构造新的Treemap对象 |
| HashMap构造方法 | 作用 |
|---|---|
| public HashMap(int initialCapacity, float loadFactor) | 指定容量(必须是二的幂)和负载因子构造对象 |
| public HashMap(int initialCapacity) | 指定容量(必须是二的幂)构造对象 |
| public HashMap() | 无参构造 |
| public HashMap(Map<? extends K, ? extends V> m) | 根据map对象构造新HashMap对象 |
关于HashMap的扩容机制与负载因子会留在哈希表一文中,敬请期待!
3.HashSet与TreeSet
HashSet与TreeSet的区别和HashMap与TreeMap的区别非常相似,因为HashSet底层也是哈希表,TreeSet底层也是红黑树,题目两种用法可以说一模一样,只是TreeSet有序而已,不同点看表吧!
| Set底层结构 | TreeSet | HashSet |
|---|---|---|
| 底层结构 | 红黑树 | 哈希桶(表) |
| 插入/删除/查找时间复杂度 | O(1) | |
| 是否有序 | 关于Key有序 (因为实现了SortedSet接口) | 无序 (哈希表是散列表) |
| 线程安全 | 不安全 | 不安全 |
| 插入/删除/查找区别 | 按照红黑树的特性来进行插入和删除 | 1.先计算key哈希地址2.然后进行插入和删除 |
| 比较与覆写 | key必须能够比较,否则会抛出ClassCastException异常 | 自定义类型需要覆写equals和 hashCode方法 |
| 应用场景 | 需要Key有序场景下 | Key是否有序不关心,需要更高的 时间性能 |
TreeSet 继承图:
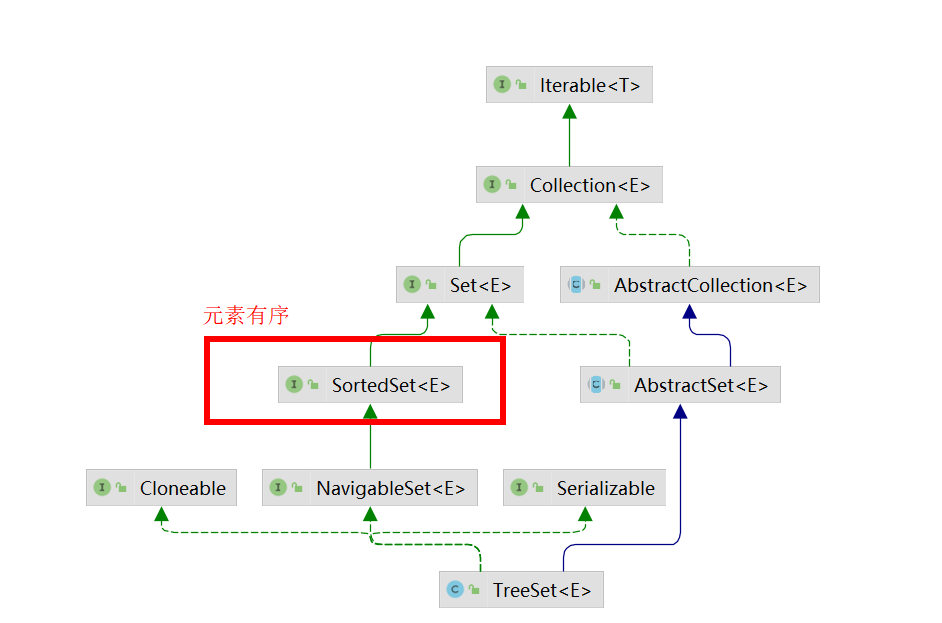
HashSet 继承图:
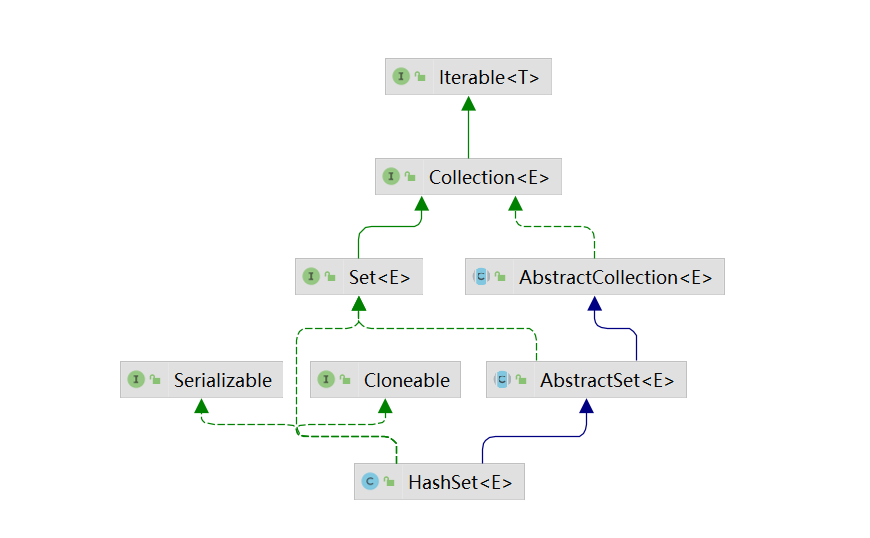
HashSet与TreeSet的常用方法基本一致,和Map接口的常用方法一致,来说一下两者的构造方法吧!
| TreeSet构造方法 | 作用 |
|---|---|
| public TreeSet() | 无参构造 |
| public TreeSet(Comparator<? super E> comparator) | 传入比较器,控制set的排序 |
| public TreeSet(Collection<? extends E> c) | 根据集合c的元素创建TreeSet |
| public TreeSet(SortedSet<E> s) | 根据SortedSet对象的元素创建TreeSet |
| HashSet构造方法 | 作用 |
|---|---|
| public HashSet() | 无参构造 |
| public HashSet(Collection<? extends E> c) | 根据集合对象c构造HashSet对象 |
| public HashSet(int initialCapacity, float loadFactor) | 指定容量(必须是二的幂)和负载因子构造HashSet对象 |
| public HashSet(int initialCapacity) | 指定容量(必须是二的幂)构造HashSet对象 |
Set中只存储了key,并且要求key一定要唯一,Set的底层是使用Map来实现的,其使用key与Object的一个默认对象作为键值对插入到Map中的,Set最大的功能就是对集合中的元素进行去重,Set中不能插入null的key。
注意:Set中的Key不能修改,如果要修改,先将原来的删除掉,然后再重新插入。
实现Set接口的常用类有TreeSet和HashSet,还有一个LinkedHashSet,LinkedHashSet是在HashSet的基础上维护了一个双向链表来记录元素的插入次序。
4.使用Set与Map解决问题
4.1只出现一次的数字
题目: 136. 只出现一次的数字
题目详情:
给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
说明:
你的算法应该具有线性时间复杂度。 你可以不使用额外空间来实现吗?
示例 1:
输入: [2,2,1]
输出: 1
示例 2:
输入: [4,1,2,1,2]
输出: 4
解题思路:
思路1:暴力遍历。两层循环,两两比较,里面那一层循环没有找到相同的数,那外层所遍历到的数就是唯一数,可能会超时。
思路2:异或。这个其实是最优思路,比下面的使用Set来解决重复问题要好,我们知道相同的两个数异或的结果是0,所以我们把数组所有数异或一遍,由于给定的数据一定有一个唯一的,所以最终得到的结果就是唯一数。
思路3:使用Set,由于Set中的元素不重复,所以我们先判断Set中是否含有这个数,如果含有这个数,就将Set里面的这个数删除,否则存入该数,最终Set剩下的数为唯一数。
因为本文介绍的Set与Map的用法,所以只展现思路3的代码。
参考代码:
class Solution {
public int singleNumber(int[] nums) {
Set<Integer> set = new HashSet<>();
for (int x : nums) {
if (set.contains(x)) {
set.remove(x);
} else {
set.add(x);
}
}
Iterator<Integer> it = set.iterator();//迭代器
return it.next();
}
}
4.2复制带随机指针的链表
题目: 138. 复制带随机指针的链表
题目详情:
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示Node.val的整数。random_index:随机指针指向的节点索引(范围从0到n-1);如果不指向任何节点,则为null。
你的代码 只 接受原链表的头节点 head 作为传入参数。
示例 1:
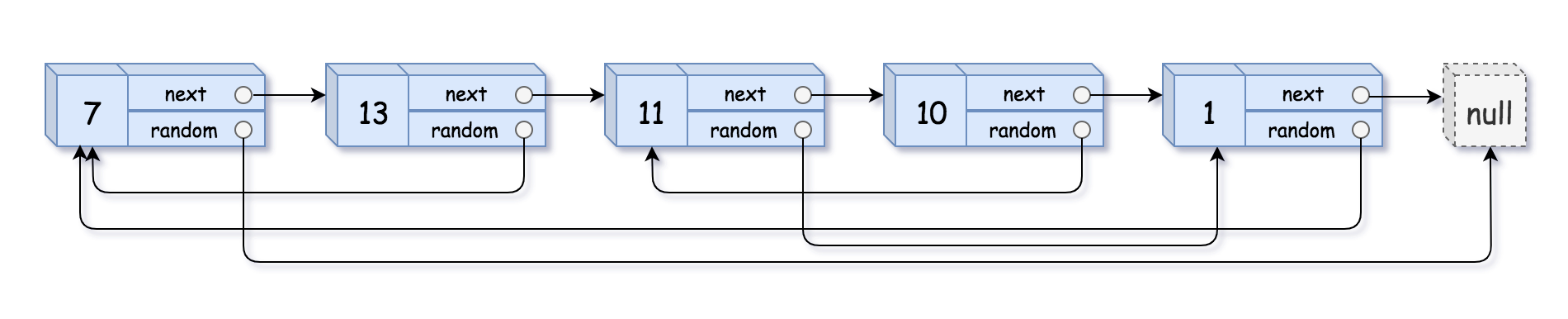
输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
示例 2:

输入:head = [[1,1],[2,1]]
输出:[[1,1],[2,1]]
示例 3:

输入:head = [[3,null],[3,0],[3,null]]
输出:[[3,null],[3,0],[3,null]]
提示:
0 <= n <= 1000-104 <= Node.val <= 104Node.random为null或指向链表中的节点。
解题思路:
想要解决这道题,先得知道题目的意思,首先链表的结点的结构有3个,数据域:val,后继指针域:next,随机指针域:random。
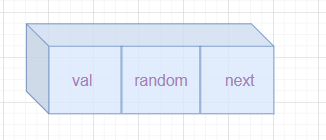
这道题的意思是给你一个链表,你要创建一个结构上一模一样的链表,并不是把链表中的值拷贝一遍,而是除了要拷贝数据以外,还要使随机指针的指向一样,比如第一个随机指针域指向第三个结点,那么复制出来的随机指针域也要指向复制链表中的第三个结点。
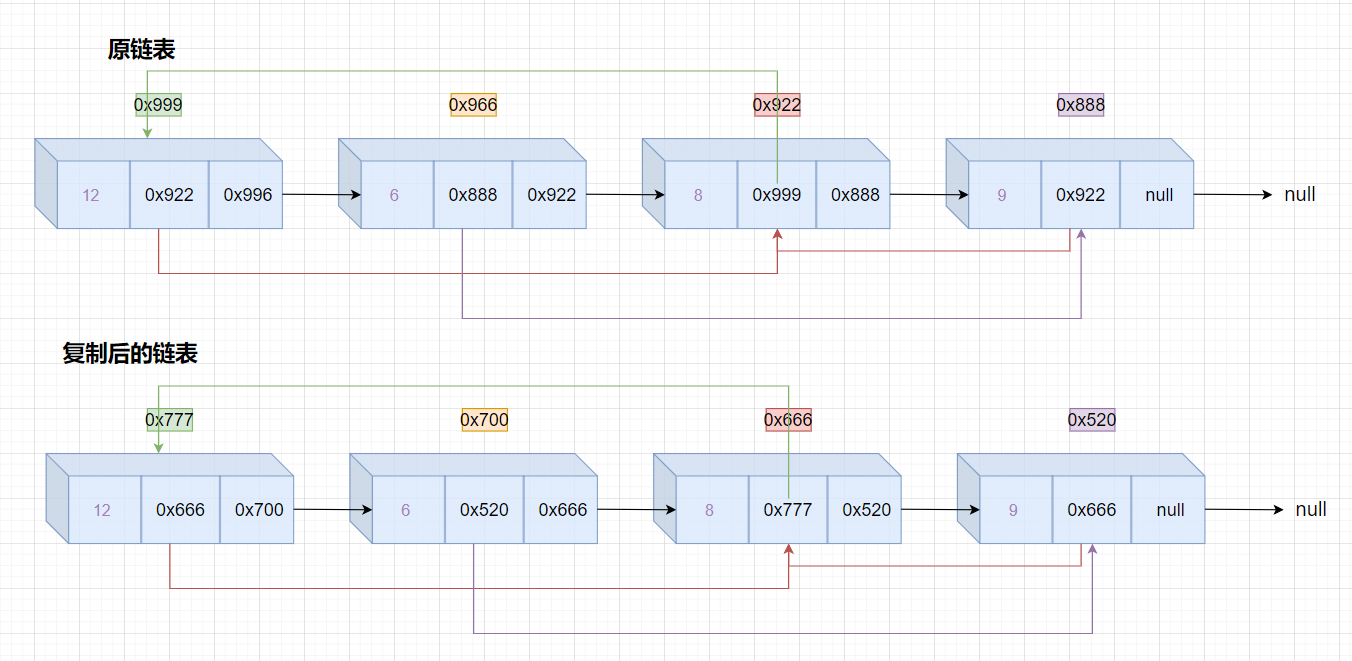
我有这样一个思路,就是使用Map,键值对为<已知链表结点地址, 复制链表结点地址>
第一次遍历已知链表时,创建复制链表对象的结点并将它们结点地址以<已知链表结点地址, 复制链表结点地址>键值对的形式存入Map中,然后第二次遍历已知链表,根据已知链表结点找到Map中对应复制链表的结点将复制链表结点链接起来,具体看代码吧。
参考代码:
/*
// Definition for a Node.
class Node {
int val;
Node next;
Node random;
public Node(int val) {
this.val = val;
this.next = null;
this.random = null;
}
}
*/
class Solution {
public Node copyRandomList(Node head) {
if(head == null) return null;
Map<Node, Node> map = new HashMap<>();
Node cur = head;
while (cur != null) {
Node node = new Node(cur.val);
map.put(cur, node);
cur = cur.next;
}
cur = head;
while (cur != null) {
map.get(cur).next = map.get(cur.next);
map.get(cur).random = map.get(cur.random);
cur = cur.next;
}
return map.get(head);
}
}
类似题:
剑指 Offer 35. 复杂链表的复制
4.3宝石与石头
题目:771. 宝石与石头
题目详情:
给你一个字符串 jewels 代表石头中宝石的类型,另有一个字符串 stones 代表你拥有的石头。 stones 中每个字符代表了一种你拥有的石头的类型,你想知道你拥有的石头中有多少是宝石。
字母区分大小写,因此 "a" 和 "A" 是不同类型的石头。
示例 1:
输入:jewels = "aA", stones = "aAAbbbb"
输出:3
示例 2:
输入:jewels = "z", stones = "ZZ"
输出:0
提示:
1 <= jewels.length, stones.length <= 50jewels和stones仅由英文字母组成jewels中的所有字符都是 唯一的
解题思路:
将宝石 jewels 放入Set中,然后遍历石头stones 判断 jewels中是否含有stones 中的字符,并计数就行。
参考代码:
class Solution {
public int numJewelsInStones(String jewels, String stones) {
Set<Character> set = new HashSet<>();
for (int i = 0; i < jewels.length(); i++) {
set.add(jewels.charAt(i));
}
int ans = 0;
for (int i = 0; i < stones.length(); i++) {
if (set.contains(stones.charAt(i))) ans++;
}
return ans;
}
}
4.4旧键盘
题目:[编程题]旧键盘
题目详情:
旧键盘上坏了几个键,于是在敲一段文字的时候,对应的字符就不会出现。现在给出应该输入的一段文字、以及实际被输入的文字,请你列出
肯定坏掉的那些键。
输入描述:
输入在2行中分别给出应该输入的文字、以及实际被输入的文字。每段文字是不超过80个字符的串,由字母A-Z(包括大、小写)、数字0-9、以及下划线“_”(代表空格)组成。题目保证2个字符串均非空。
输出描述:
按照发现顺序,在一行中输出坏掉的键。其中英文字母只输出大写,每个坏键只输出一次。题目保证至少有1个坏键。
输入
7_This_is_a_test
_hs_s_a_es
输出
7TI
解题思路:
根据题意,使用键盘输入文字,但存在坏键盘,如果敲到换键盘出的字母,输入无效,因此根据应该输入的文字得到实际被输入的文字,对比两者文字的区别,如果应该输入的文字中没有出现在实际被输入的文字的字母,则这些字母就是键盘中坏了的字母键。
我们可将实际被输入的文字填入Set中,然后遍历应该输入的文字,找到Set中不存在的字母,并输出这些字母,由于应该输入的文字存在重复的元素,且不能打乱输出顺序,我们可以采用一个辅助的集合Set用来查重,就是输出前判断这个集合中是否含有这个字符,如果含有则不输出,不含有则输出并将该元素放入辅助集合中。
参考代码:
import java.util.*;
public class Main {
//strExce:7_This_is_a_test strActual:_hs_s_a_es
public static void func(String strExce,String strActual) {
//字符串转大写
strExce = strExce.toUpperCase();
strActual = strActual.toUpperCase();
//建立机集合用来存放实际输出字符
Set<Character> setActual = new HashSet<>();
for (Character c : strActual.toCharArray()) {
setActual.add(c);
}
//辅助集合,输出前判断字符已经输出过
Set<Character> setAns = new HashSet<>();
for (Character c : strExce.toCharArray()) {
if (!setActual.contains(c) && !setAns.contains(c)) {
System.out.print(c);
setAns.add(c);
}
}
System.out.println();
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
while (sc.hasNextLine()) {
String s1 = sc.nextLine();
String s2 = sc.nextLine();
func(s1, s2);
}
}
}
4.5前K个高频单词
题目:692. 前K个高频单词
题目详情:
给定一个单词列表 words 和一个整数 k ,返回前 k 个出现次数最多的单词。
返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率, 按字典顺序 排序。
示例 1:
输入: words = ["i", "love", "leetcode", "i", "love", "coding"], k = 2
输出: ["i", "love"]
解析: "i" 和 "love" 为出现次数最多的两个单词,均为2次。
注意,按字母顺序 "i" 在 "love" 之前。
示例 2:
输入: ["the", "day", "is", "sunny", "the", "the", "the", "sunny", "is", "is"], k = 4
输出: ["the", "is", "sunny", "day"]
解析: "the", "is", "sunny" 和 "day" 是出现次数最多的四个单词,
出现次数依次为 4, 3, 2 和 1 次。
注意:
1 <= words.length <= 5001 <= words[i] <= 10words[i]由小写英文字母组成。k的取值范围是[1, **不同** words[i] 的数量]
解题思路:
第一步使用Map统计单词词频。
第二步利用topK求前k个词频频率最高的元素(所以需要小根堆),如果出现词频相同的单词,优先保留字典顺序在前的。
第三步将堆里面的元素存入List,并使用Collections类工具逆序List。
第四步返回List。
关于topK的一些细节:
需要创建基于小根堆的优先队列,但是在调整小根堆时除了考虑词频小的在堆顶以外,还需要考虑当词频相同时,究竟是字段顺序在前的单词放在堆顶还是字典顺序在后的单词放在堆顶,还是无所谓。
我们来讨论一下topK时堆中元素没有k个时,但是出现堆中元素词频相同情况,看看最终List逆序存入结果就知道了。
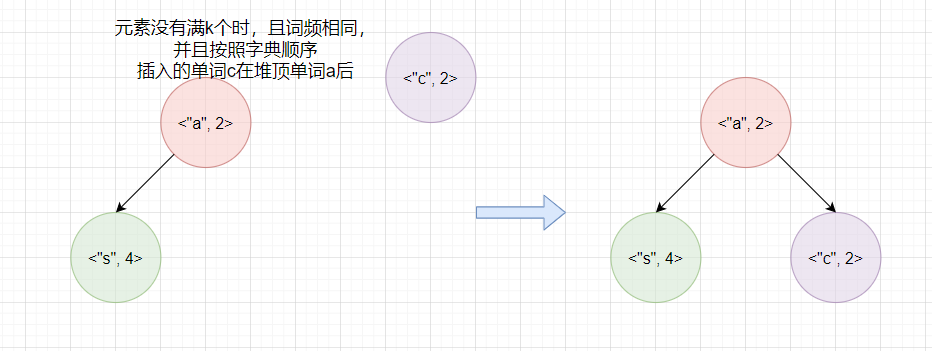
如图,如果字典顺序较前的元素在堆顶,我们看看最终List存入的是什么,是否与预期相符。

如上图,最终结果与预期不同,因此在重写比较器的compare方法时,除了考虑词频,还需要考虑词频相同时,将字典顺序较大的单词放在堆顶。
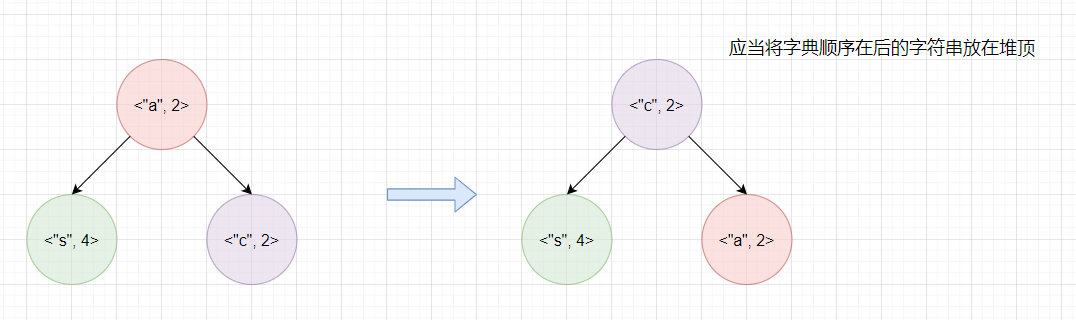
所以构造优先队列时代码如下:
PriorityQueue<Map.Entry<String, Integer>> minHeap = new PriorityQueue<>(new Comparator<Map.Entry<String, Integer>>() {
@Override
//词频相同时,按关键字优先字典顺序大的放在堆顶
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
if (o1.getValue().compareTo(o2.getValue()) == 0) {
return o2.getKey().compareTo(o1.getKey());
}
return o1.getValue() - o2.getValue();
}
});
解决了小根堆如何创建,然后就是topK了,当堆中元素个数小于k,直接入堆。
如果堆元素个数大于k有三种情况:
- 情况1: 待插入单词词频等于堆顶单词词频,则需要将字典顺序较前的元素放在堆顶,也就是待插入单词字典排序较前时与堆顶单词替换。
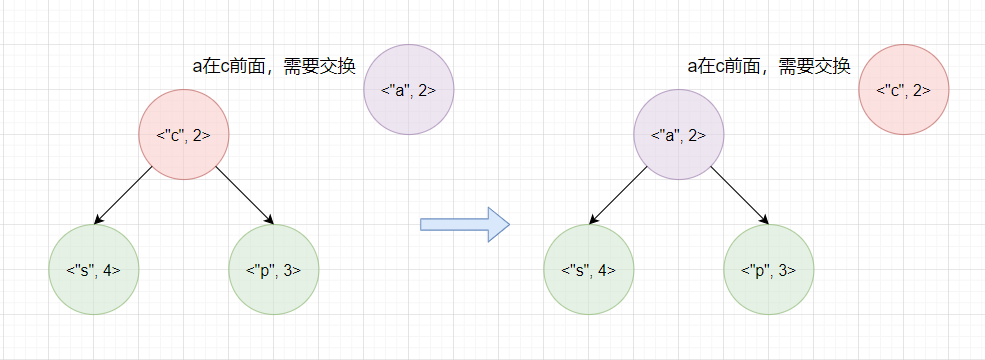
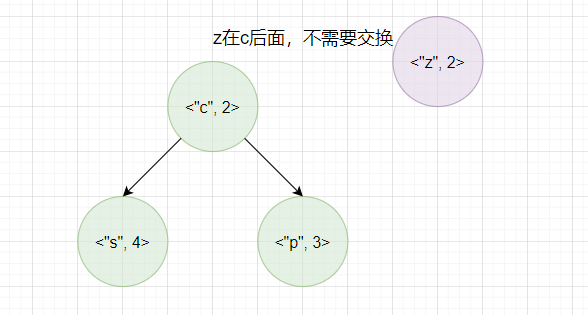
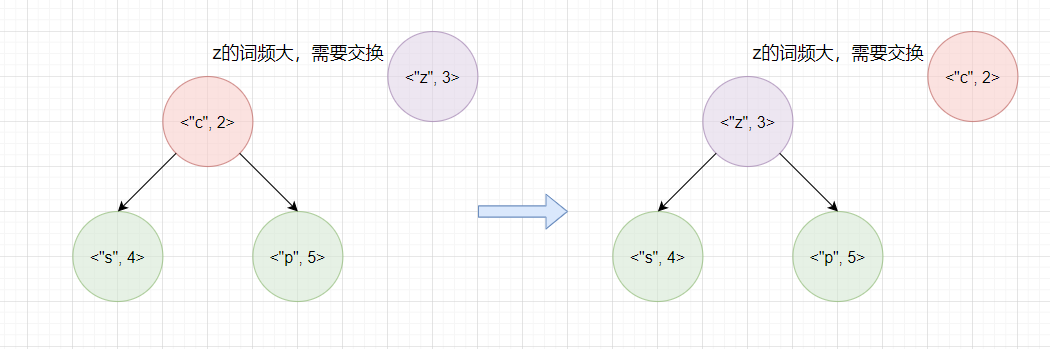
- 情况2: 词频较大的单词放在堆顶,即当待插入单词词频较大时,与堆顶单词替换。
- 情况3: 不属于情况1与情况2,不用待插入单词与堆顶单词不用交换。
参考代码:
class Solution {
public List<String> topKFrequent(String[] words, int k) {
//1.统计词频
Map<String, Integer> map = new HashMap<>();
for (String word: words) {
if (map.containsKey(word)) {
map.put(word, map.get(word) + 1);
} else {
map.put(word, 1);
}
}
//2.排序词频,Topk找词频最高的几个键值对,建小堆
PriorityQueue<Map.Entry<String, Integer>> minHeap = new PriorityQueue<>(new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
if (o1.getValue().compareTo(o2.getValue()) == 0) {
return o2.getKey().compareTo(o1.getKey());
}
return o1.getValue() - o2.getValue();
}
});
//3.遍历map,进行topK
for (Map.Entry<String, Integer> x: map.entrySet()) {
if (minHeap.size() < k) {
minHeap.offer(x);
} else {
Map.Entry<String, Integer> top = minHeap.peek();
if (x.getValue() == top.getValue() && x.getKey().compareTo(top.getKey()) < 0) {
minHeap.poll();
minHeap.offer(x);
} else if (x.getValue() > top.getValue()) {
minHeap.poll();
minHeap.offer(x);
}
}
}
//4.将minHeap元素逆序存入List
List<String> list = new ArrayList<>();
for (int i = 0; i < k; i++) {
if (!minHeap.isEmpty()) {
list.add(minHeap.poll().getKey());
}
}
Collections.reverse(list);
return list;
}
}
类似题:
剑指 Offer II 060. 出现频率最高的 k 个数字
347. 前 K 个高频元素
文章到底了,你学会了吗?

- 点赞
- 收藏
- 关注作者
评论(0)