【语音合成】基于matlab线性预测共振峰检测和基音参数语音合成【含Matlab源码 562期】

一、获取代码方式
获取代码方式1:
完整代码已上传我的资源:【语音合成】基于matlab线性预测共振峰检测和基音参数语音合成【含Matlab源码 562期】
获取代码方式2:
通过订阅紫极神光博客付费专栏,凭支付凭证,私信博主,可获得此代码。
备注:
订阅紫极神光博客付费专栏,可免费获得1份代码(有效期为订阅日起,三天内有效);
二、共振峰合成简介
参数合成方法实际上就是语音参数分析的逆过程,它把分析得到的每一帧语音参数,包
括浊音/清音判别、声源参数、能量、声道参数按时间顺序连续地输人到参数合成网络中,
参数合成器即可输出合成的语音。目前较为流行的语音合成技术分为两类:共振峰合成和
LPC合成。共振峰合成方法虽然比LPC合成方法复杂, 但可以产生较高质量的合成语音。
共振峰语音合成器模型是把声道视为一个谐振腔,利用腔体的谐振特性,如共振峰频率
及带宽,并以此为参数构成一个共振峰滤波器。因为音色各异的语音有不同的共振蜂模式,所以基于每个共振峰频率及其宽带为参数,都可以构成一个共振峰滤波器。将多个这种滤波器组合起来模拟声道的传输特性,对激励声源发生的信号进行调制,经过辐射即可得到合成语音。这便是共振峰语音合成器的构成原理。实际上,共振峰滤波器的个数和组合形式是固定的,只是共振峰滤波器的参数,随着每一帧输人的语音参数改变,以此表征音色各异的语音的不同的共振峰模式。
图10-1所示的是共振峰合成器的系统模型。从图中可以看出激励声源发生的信号,先经过模拟声道传输特性的共振峰滤波器调制,再经过辐射传输效应后即可得到合成的语音输出。由于发声时器官是运动的,所以模型的参数是随时间变化的。因此,一般要求共振峰合成器的参数逐帧修正。
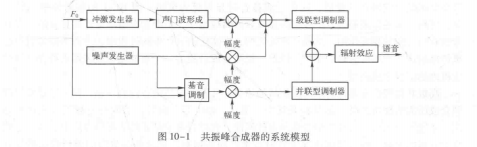
简单地将激励分成浊音和清音两种类型是有缺陷的。因为对浊辅音,尤其是浊擦音来说,声带振动产生的脉冲波和湍流是同时存在的,这时噪声的幅度要被声带振动周期性地调制。因此,为了得到高质量的合成语音,激励源应具备多种选择,以适应不同的发音情况。图10-1中激励源有三种类型:合成浊音语音时用周期冲激序列;合成清音语音时用伪随机
噪声;合成浊擦音时用周期冲激调制的噪声。激励源对合成语音的自然度有明显的影响。发浊音时,最简单的是三角波脉冲,但这种模型不够精确,对于高质量的语音合成,激励源的脉冲形状是十分重要的,可以采用其他更为精确的形式,如多项式波、滤波成形波等。合成清音时,激励源一般使用白嗓声,实际实现时用伪随机数发生器来产生。但是,实际清音激励源的频谱应该是平坦的,其波形样本幅度服从高斯分布。而伪随机数发生器产生的序列具有平坦的频谱,但幅度是均匀分布。根据中心极限定理,互相独立且具有相同分布的随机变量之和服从高斯分布。因此,将若干个(典型值为14~18)随机数叠加起来,可以得到近似高斯分布的激励源。
声学原理表明,语音信号谱中的谐振特性(对应声道传输函数中的极点)完全由声道形状决定,和激励源的位置无关;面反谐振特性(对应于声道传输函数的零点)在发大多数辅音(如摩擦音)和鼻音(包括鼻化元音)时存在。因此,对于鼻音和大多数的辅音,应采用极零模型。图10-1采用了两种声道模型。一种是将其模型化为二阶数字谐振器的级联。级联型结构可模拟声道谐振特性,能很好地逼近元音的频谱特性。这种形式结构简单,每个谐振器代表了一个共振峰特性,只需用一个参数来控制共振峰的幅度。采用二阶数字滤波器的原因是因为它对单个共振峰特性提供了良好的物理模型;同时在相同的频谱精度上,低阶的数字滤波器量化位数较小,在计算上也十分有效。另一种是将其模型化为并联形式。并联型结构能模拟谐振和反谐振特性,所以被用来合成辅音。事实上,并联型也可以模拟元音,但效果不如级联型好。并联型结构中的每个谐振器的幅度必须单独控制,从而产生合适的零点。
对于平均长度为17cm的声道(男性) , 在3kHz范围内大致包含3个或4个共振峰, 而在5kHz范围内包含4个或5个共振峰。语音合成的研究表明:表示浊音最主要的是前3个共振峰,只要用前3个时变共振峰频率就可以得到可懂度很好的合成浊音。所以在对声道模型参数进行逐帧修正时,高级的共振峰合成器要求前4个共振峰频率以及前3个共振峰带宽
都随时间变化,更高频率的共振峰参数变化可以忽略。对于要求简单的场合,则只改变共振峰频率F、F、F,而带宽则固定不变。例如,前3个共振峰的带宽保持在60Hz100Hz、
120Hz不变。根据不同的浊音,调整F,、Fy、F,以改变3个共振峰频率。但固定的共振峰带宽会影响合成语音的音质,这在合成鼻音时显得更为突出。图10-1的辐射模型比较简
单,可用一阶差分来逼近。一般的共振峰合成器模型中,声源和声道间是互相独立的,没有考虑它们之间的相互作用。然而,研究表明,在实际语言产生的过程中,声源的振动对声道里传播的声波有不可忽略的作用。因此,提高合成音质的一个重要途径是采用更符合语音产生机理的语音生成模型。
高级共振峰合成器可合成出高质量的语音,几乎和自然语音没有差别。但关键是如何得
到合成所需的控制参数,如共振峰频率、带宽、幅度等。而且,求取的参数还必须逐顿修
正,才能使合成语音与自然语音达到最佳匹配。在以音素为基元的共振峰合成中,可以存储每个音素的参数,然后根据连续发音时音素之间的影响,从这些参数内插得到控制参数轨迹。尽管共振峰参数理论上可以计算,但实验表明,这样产生的合成语音在自然度和可懂度方面均不令人满意。
理想的方法是从自然语音样本出发,通过调整共振峰合成参数,使合成出的语音和自然
语音样本在频谱的共振峰特性上最佳匹配,即误差最小,将此时的参数作为控制参数,这就是合成分析法。实验表明,如果合成语音的频谱峰值和自然语音的频谱峰值差能保持在几个分贝之内,且基音和声强变化曲线能较精确地吻合,则合成语音在自然度和可懂度方面均和自然语音没什么差别。为了避免连续时邻近音素的影响,对于比较稳定的音素,如元音、摩擦音等,控制参数可以由孤立的发音来提取;而对于瞬态的音素,如塞音,其特性受前后音素影响很大,其参数值应对不同连接情况下的自然语句取平均。根据语音产生的声学型,直接从自然语音样本中精确地提取共振峰参数还依赖于对激励源信息的获取。假定浊音激励。
源的频谱以-12dB/倍频程变化,那么经过预加重的自然语音波形的谱特性就与声道的谱特
性相当。虽然这时过分简化了激励源,但这种方法仍然是最常用和最有效的。
三、部分源代码
clear all; clc; close all;
[xx,fs]=audioread('2.wav');
- 1
- 2
- 3
- 4
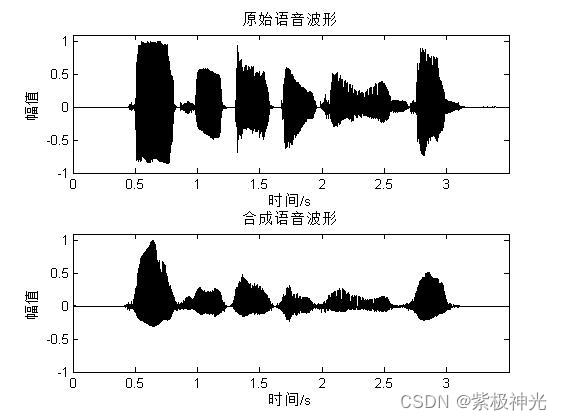
四、运行结果
五、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社,2019.
[2]柳若边.深度学习:语音识别技术实践[M].清华大学出版社,2019.
文章来源: qq912100926.blog.csdn.net,作者:海神之光,版权归原作者所有,如需转载,请联系作者。
原文链接:qq912100926.blog.csdn.net/article/details/114997134

- 点赞
- 收藏
- 关注作者
评论(0)