【数学建模】基于matlab模糊二元决策树【含Matlab源码 038期】

一、获取代码方式
获取代码方式1:
完整代码已上传我的资源:【数据建模】基于matlab模糊二元决策树【含Matlab源码 038期】
获取代码方式2:
通过订阅紫极神光博客付费专栏,凭支付凭证,私信博主,可获得此代码。
备注:
订阅紫极神光博客付费专栏,可免费获得1份代码(有效期为订阅日起,三天内有效);
二、简介
模糊模式树(FPT) 是一种机器学习的分类方法,类似于二元决策树(binary descision diagram,BDD)。其内部节点使用广义(模糊)逻辑和算数运算符标记,叶节点与给定输入属性集合上的(一元)模糊谓词相关联
模糊模式树(FPT)
在预测性能方面与其他机器学习竞争的方法相比是有竞争力的,由于物联网节点处理资源有限,他倾向于生成在解释方面非常有吸引力的紧凑模型。
其缺点也很明显:其计算复杂度高,运行时间可能变得令人无法接受。

二分决策树(BDD)
BDD是用来表达布尔函数的一种数据结构。是一种基于shannon分解的有向无环图。
设f为一组布尔变量集合的布尔函数(boolean function),且x为集合X中的变量,则shannon分解及其if-then-else(ite)形式为
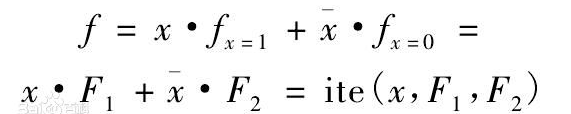
式中x和 x-bar 分别代表事件发生,事件不发生;fx=1(即F1)和fx=0(即F2)
分别代表了事件发生与事件不发生的布尔函数
二叉树表示为以下:

布尔函数(boolean function)
布尔函数基于对布尔输入,通过某种逻辑计算,输出布尔值。
F(b1,b2,b3,…,bn)
带有n个两元素布尔代数{0,1}的布尔变量bi,F的值也是在{0,1}中
一般定义域上值在{0,1}中的函数也被称为布尔值函数,所以布尔函数是特殊情况
三、部分代码
%%----- Main Program that should be run inorder to execute the code -----%%
% load the data file
load('earfeature15window700image.mat');
% Change following variable in case of number of user changes
noOfUsers = 100;
% Change following two variable in case you need to change ration of test
% and train case or when the number of data value for same user changes(right now its 7)
trainCasePerUser = 4;
testCasePerUser = 3;
if(testCasePerUser < 2)
disp('testCasePerUser should be greater then 1')
else
totalCasePerUser = trainCasePerUser + testCasePerUser;
% 3D matrix where 1st dimention is related the user, 2nd dimention related
% to datavalues per user and 3rd dimention are the feature values for datapoints
test = zeros([noOfUsers testCasePerUser 35]);
train = zeros([noOfUsers trainCasePerUser 35]);
%% this loop devides the data into testcases and trainingcase randomly
for i=1:noOfUsers
% matrix p is the random permutation of interger 1 to total number of datavalues per user
p = randperm(totalCasePerUser,totalCasePerUser);
% below two lines divide the data into tests and training data
test(i,:,:) = T_S1(:,(i-1)*totalCasePerUser + p(1:testCasePerUser))';
train(i,:,:) = T_S1(:,(i-1)*totalCasePerUser + p(testCasePerUser+1:totalCasePerUser))';
end
%% Following piece of code find creates the matching score matrix with 2 columns
% 1st column has the value of matching score and 2nd column has value 1 if
% its genuine and 0 if imposter
trainScore = zeros([noOfUsers*noOfUsers 2]);
testScore = zeros([noOfUsers*noOfUsers*(testCasePerUser-1) 2]);
% loop that creates the matrix of training sample.
for i=1:noOfUsers
for j=1:noOfUsers
score = zeros([trainCasePerUser 1]);
for k = 1:trainCasePerUser
score(k) = norm(squeeze((test(i,1,:) - train(j,k,:))),2);
end
% take the min of distance to get the matching score
trainScore((i-1)*noOfUsers + j,1) = min(score);
% if the users are same then its genuine class else imposter
if(i==j)
trainScore((i-1)*noOfUsers + j,2) = 1;
else
trainScore((i-1)*noOfUsers + j,2) = 0;
end
end
end
% loop that creates the matrix of testing sample
for z=0:testCasePerUser-2
for i=1:noOfUsers
for j=1:noOfUsers
score = zeros([trainCasePerUser 1]);
for k = 1:trainCasePerUser
score(k) = norm(squeeze((test(i,z+2,:) - train(j,k,:))),2);
end
testScore(z*noOfUsers*noOfUsers + (i-1)*noOfUsers + j,1) = min(score);
if(i==j)
testScore(z*noOfUsers*noOfUsers + (i-1)*noOfUsers + j,2) = 1;
else
testScore(z*noOfUsers*noOfUsers + (i-1)*noOfUsers + j,2) = 0;
end
end
end
end
% find the geninue class datapoint and put them in Gtrain Matrix
Gtrain = trainScore(find(trainScore(:,2) == 1), :);
% find the imposter class datapoint and put them in Itrain Matrix
Itrain = trainScore(find(trainScore(:,2) == 0), :);
% Create the final training matrix with score value in 1st column, membership
% value in 2nd column and class in 3rd column for creating dicision tree.
% change the membership function 2nd column in case you want to use
% different membership funtion
Mtrain = [Gtrain(:,1) GaussianMembership(Gtrain(:,1)) Gtrain(:,2); Itrain(:,1) TrapezoidalMembership(Itrain(:,1)) Itrain(:,2)];
%Mtrain = [Gtrain(:,1) TrapezoidalMembership(Gtrain(:,1)) Gtrain(:,2); Itrain(:,1) TrapezoidalMembership(Itrain(:,1)) Itrain(:,2)];
%% This part of code deals with growing the decision tree
% sort the training matrix according the matching score value.
[a b] = sort(Mtrain(:,1));
clear a;
data = Mtrain(b,:);
% grow the tree using sorted training matrix
tree = growTree( data );
%% This part of code deals with the predicting the class of testing score and
% calculation of FRR and FAR
testingSize = noOfUsers*noOfUsers*(testCasePerUser-1);
geniuneTestingSize = noOfUsers*(testCasePerUser-1);
trainingSize = noOfUsers*noOfUsers;
geniuneTrainingSize = noOfUsers;
pre = zeros([testingSize 2]);
% loop that predicts the values of all testing data
for i=1:testingSize
pre(i,1) = predict(tree, testScore(i,:));
pre(i,2) = testScore(i,2);
end
% calculation of FAR and FRR
FA = pre(find(pre(:,1) == 1 & pre(:,2) == 0),:); % False Acceptance
FR = pre(find(pre(:,1) == 0 & pre(:,2) == 1),:); % False Rejection
FAR = size(FA,1)/(testingSize-geniuneTestingSize); % False Acceptance Rate
FRR = size(FR,1)/geniuneTestingSize; % False Rejection Rate
%% histgram of normalized frequencies of matching score of Geniune and Imposter matching score
figure;
[m,yout] = hist(Itrain(:,1), 20);
m = m/(size(Itrain,1));
[n,xout] = hist(Gtrain(:,1), 20);
n = n/size(Gtrain,1);
bar(yout,m);
hold on;
bar(xout,n, 'r');
legend('Imposter Scores','Geniune Scores');
hold off;
end
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
四、备注
版本:2014a
文章来源: qq912100926.blog.csdn.net,作者:海神之光,版权归原作者所有,如需转载,请联系作者。
原文链接:qq912100926.blog.csdn.net/article/details/112153298

- 点赞
- 收藏
- 关注作者
评论(0)