基于深度模型的日志序列异常检测

日志异常检测的核心是利用人工智能算法自动分析系统日志来发现并定位故障。根据送入检测模型的数据格式,日志异常检测算法模型分为序列模型和频率模型,其中序列模型又可以分为深度模型和聚类模型。自 2017 年 Min Du 等人提出 DeepLog 以来,基于序列的深度学习建模逐渐成为近年来研究的热点。
深度模型的日志异常检测基本流程
深度学习使用神经网络的多层体系结构,从原始输入中逐步提取特征,不同的层处理不同级别的特征抽象。由于神经网络在复杂关系建模方面表现出了卓越的能力,因此被广泛应用于基于日志的异常检测。日志数据异常检测的基本流程如下图所示,包括日志分区、特征提取、模型训练和在线更新四个步骤。
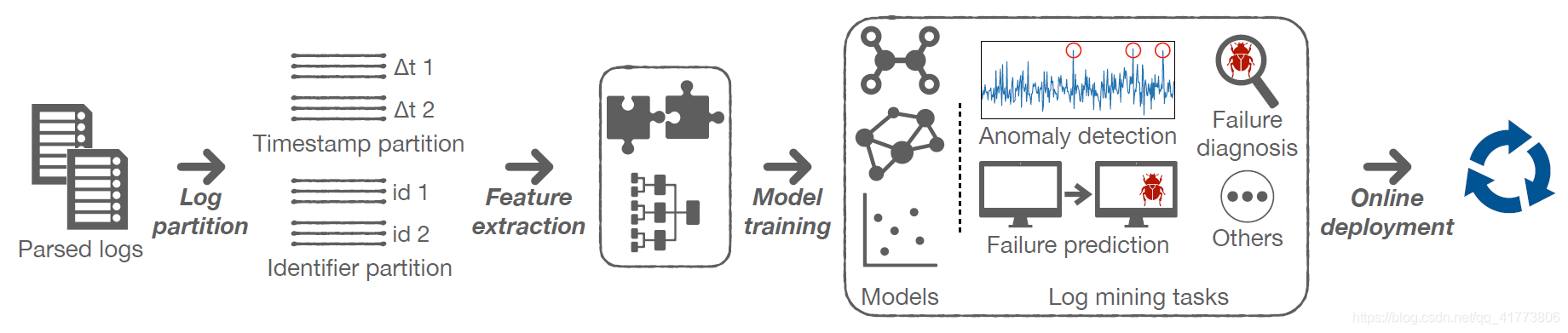
Log partition:现代软件系统通常采用微服务架构,并包含大量在多线程环境中运行的模块。不同的微服务或模块通常将它们的执行日志聚合到一个日志文件中,这阻碍了自动化的日志挖掘。为了解决这个问题,交错的日志应该被分成不同的组,每个组代表单个系统任务的执行。分区日志组是构建日志挖掘模型之前提取特征的基本单元,通常使用 Timestamp 时间戳和 Log Identifier 日志标识符作为日志分割器。
Feature Extraction:为了通过深度模型自动地分析日志,日志分区中的日志文本需要转换成适合机器学习算法的格式。一般使用两类基于日志的特征,即数字特征和图形特征。数字特征主要包含四类特征:Log event sequence 日志事件序列-记录系统活动的日志事件序列;Log event count vector 日志事件计数向量-记录日志分区中日志事件发生情况的特征向量,其中每个特征表示一个日志事件类型,该值对发生次数进行计数;Parameter value vector 参数值向量-记录日志中出现的参数值;Ad hoc features 日志中提取的一组相关和有代表性的特征,这些特征是使用对象软件系统和问题上下文的领域知识定义的。图形特征通常产生表征系统行为的有向图模型,发现系统组件和事件与日志之间的层次和顺序关系。
Model training:日志数据异常检测需要基于特定的问题选择适当的算法,基于提取的特征选择合适的模型。日志异常检测任务的一个基本假设是:大多数日志应该表现出符合系统正常行为的模式。例如,在异常检测中,不同的模型被训练成从不同的角度捕获各种模式,并被用来检测缺乏所需属性的异常。
Online Deployment:日志异常检测模型可以集成到软件产品中,以检测恶意系统行为并实时发出警报。由于软件系统可能在其产品生命周期中升级,先前训练的模型可能不适合模式变化,所以需要在线更新以适应前所未有的日志模式。
DeepLog 基于LSTM深度模型的系统日志异常检测
DeepLog
Du M , Li F , Zheng G , et al. DeepLog: Anomaly Detection and Diagnosis from System Logs through Deep Learning[C]// Acm Sigsac Conference on Computer & Communications Security. ACM, 2017.
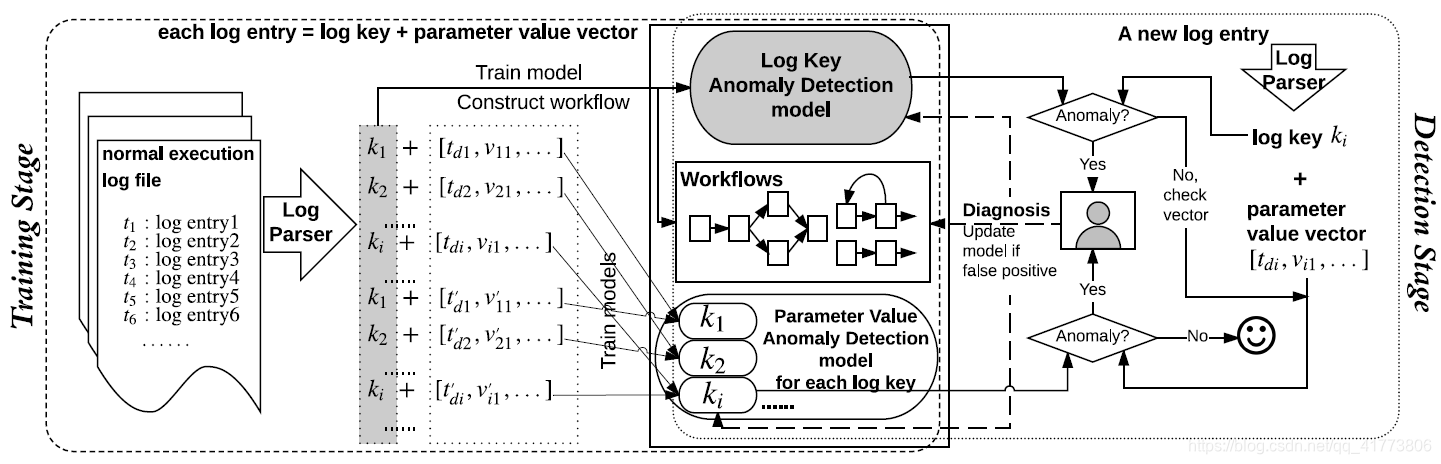
DeepLog 的总体架构如下图所示,分为训练和检测两个阶段。在训练阶段,大量的系统日志数据被日志解析器解析为日志键和一个参数值向量的组合;然后使用这些日志键序列来训练一个日志键异常检测模型,并构建用于诊断目标系统执行工作流模型。对于不用的日志键,用它们的参数值向量训练一个参数值异常检测模型来检测有这些参数值反映的系统性能异常。在检测阶段,当一个新的日志记录到达时,它也被日志解析器解析为一个日志键和一个参数值向量的组合,然后使用对应内容经过对应异常检测模型进行检测,如果任一检测模型检测结果为异常,则将其标记为异常日志记录。详细的 DeepLog 实现原理可参考:基于LSTM深度模型实现系统日志异常检测
DeepLog 存在的局限性
- DeepLog 模型对日志模板进行编码时只使用模板索引,这可能导致丢失有价值的信息,因为模板索引不能揭示日志的语义关系。
- 真实的现代软件系统是不断经历功能升级和系统更新的,因此,日志的模式可能会相应地漂移。DeepLog 模型难以应付不断变化的、有噪声的日志数据。
- DeepLog 深度学习模型虽然在一些数据集上取得了较好的成绩,但是仍然逃不脱类似黑盒预言的评价,模型可解释性较差。日志分析应该继续追求更易于解释和值得信赖的算法。
- DeepLog 模型主要是针对高于底层操作系统的分布式软件例如 HDFS,OpenStack 进行日志异常检测,在此类系统中出现的性能异常不同于在 HPC 系统中出现的硬件严重错误。所以在计算机群中的日志异常检测需要预测故障的前置时间,以避免严重宕机故障的发生。
基于语义理解的日志异常检测模型
日志数据是程序开发人员为辅助调试在程序中嵌入的打印输出代码所产生的文本数据,用以记录程序运行时的变量信息、程序执行状态等,所以一般情况下日志数据都含有丰富的语义信息。但是现有的研究中对日志数据的分析往往侧重于事件表示,而忽略了日志中嵌入的语义信息,这可能导致丢失有价值的信息。基于语义理解的日志异常检测模型致力于对日志的自动理解,这将消除日志数据概念漂移带来的问题的一种有效应对方法。此外,对于日志数据的语义理解还可以在日志语句的自动生成中发挥重要作用。
Template2Vec
Meng W, et al. “LogAnomaly - Unsupervised Detection of Sequential and Quantitative Anomalies in Unstructured Logs.” IJCAI (2019): 4739-4745.
文献主要工作:
LogAnomaly 以大部分系统日志是由系统程序输出的半结构化文本的事实为基础,将自然语言处理的方法应用或改进于日志异常检测。在模型设计中本文使用深度学习来离线学习日志模板的关系与对应参数值,为了保留日志模板之间的语义关系,本文不是使用简单的模板索引而是根据词嵌入的原理,设计了一种简单而有效的模板表示方法 Template2Vec,用来准确地从日志模板中提取语义和语法信息。这种方式不仅捕获了模板中单词上下文信息,还捕获了语义信息,语义信息有助于应对概念漂移,一般情况下将具有同义词的日志视为相似事件,反义词的日志通常指示不同的事件。除此之外,本文还设计了一种机制来合并新模板,这样可以自动化的更新日志异常检测模型,而无需操作员在两个相邻的训练之间进行人工反馈。
基于同义词反义词的Template2Vec方法:
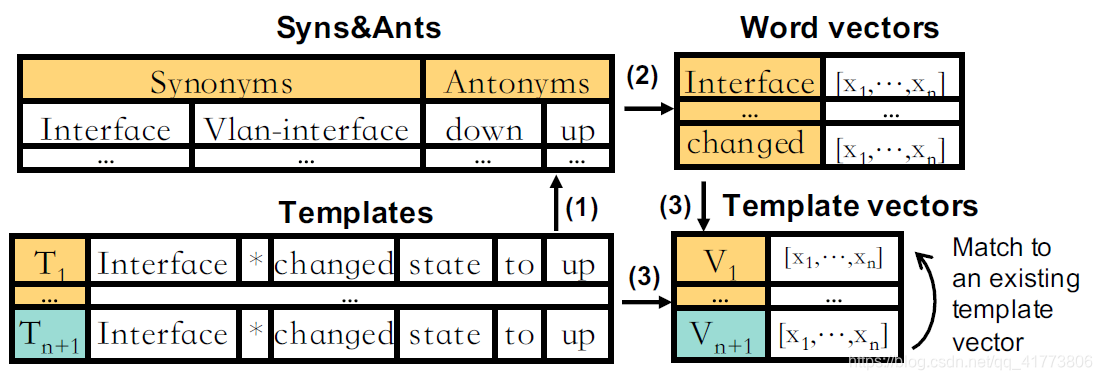
Template2Vec 在离线学习阶段包括三个步骤如下图所示,分别是构造同义词和反义词集合、生成词向量和计算模板向量
-
构造同义词和反义词集合:在一个英语词汇数据库 WordNet 中对模板内容中的自然语言单词进行同义词和反义词搜索,一些领域特定业务知识的同义词和反义词需要由运维人员进行识别,并将其转化为正常的自然语言词汇。
-
生成词向量:应用一个分布式词汇对比嵌入模型 dLCE 生成模板中单词的词向量
-
计算模板向量:模板向量是模板中单词的词向量的加权平均值。
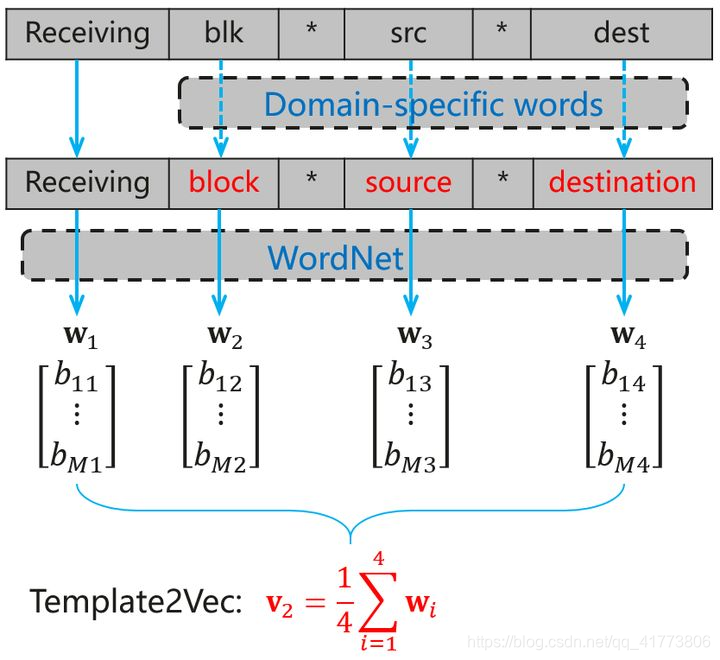
一个模板向量的生成实例如下图所示,首先将日志内容处理成自然语言词汇,然后以此为基础生成对应的词向量,最后计算模板中词向量的加权平均值生成模板向量:
模板合并机制:
在实时系统中,系统可以在线生成新的日志模板,但是现有方法不能处理新生成的模板索引。大量新日志模板的人工反馈在实践中是不可行的。虽然定期再培训可以缓解问题,但仍然需要处理连续两次离线培训之间出现的新日志模板。为此本文提出了一种模板合并机制,在线检测阶段,对于无法匹配任何现有模板的日志,首先应用 FT-Tree 从新日志中提取一个临时模板,并计算其模板向量。之后,根据模板向量之间的相似性,将这个临时模板向量与现有的模板向量进行匹配。由经验可知,一般情况下大部分新模板只是现有模板的一种变体,而不是全新的。基于模板近似的模板合并机制旨在处理两次连续离线训练之间新出现的日志模板,这是一种比操作者的劳动密集型手动反馈更好的方法。采用这种模板合并机制,出现新的日志模板,也不会对现有的模板向量的数量产生巨大影响,保证了模型的稳定性。
Log2Vec
Meng, Weibin, et al. “A semantic-aware representation framework for online log analysis.” 2020 29th International Conference on Computer Communications and Networks (ICCCN). IEEE, 2020.
文献主要工作:
现代系统中更新是常态,由于需要添加新功能、修复错误或提高系统性能等更改,系统中的软硬件更新是频繁的。这种情况下,特定领域的日志词汇会不断增长,提取这些特定领域词汇的语义信息对于日志分析来说存在困难,但其包含的语义信息却关键。另外,基于同义词反义词的语义信息提取方法 Template2Vec 存在缺陷,在很多情况下无法捕捉日志中许多单词的精确含义,因为一些对立含义的词汇可能有相似的上下文,即为相似日志事件。
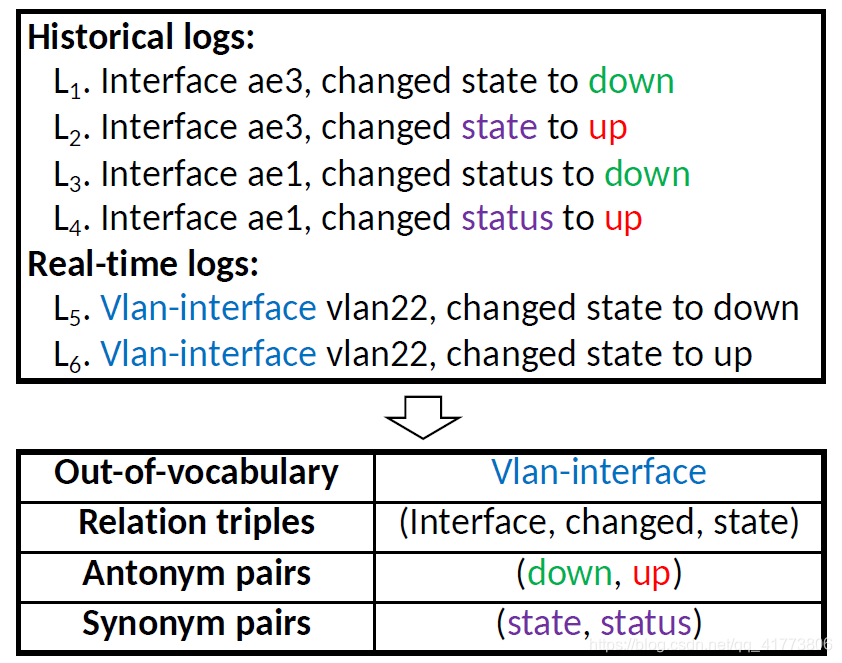
Log2Vec 是一个用于在线日志分析的语义感知表示框架,旨在解决上述挑战。为了解决 Tempalte2Vec 在一些情况下无法捕捉日志中许多单词的精确含义的问题,Log2Vec 使用一种特定于日志的单词嵌入方法 LSWE,以提取特定于日志的语义信息;并集成了一个 OOV (out of vocabulary) 单词处理器,以在运行时将新的日志词汇嵌入到词向量中,解决特定领域词汇语义信息提取的问题,当有新类型的日志出现时,操作者不需要对原始的词嵌入语料库中进行冗余的再训练。
基于 LWE 和 SWE 的日志单词嵌入方法:
LSWE 采用了两种单词嵌入方法,词汇信息单词嵌入 (LWE) 和语义单词嵌入 (SWE),将词汇对比整合到分布向量中,并加强了用于确定词相似度的特定领域语义和关系信息。对于给定对应于目标词的同义词和反义词集合的情况,本文使用 LWE 预测目标词,使得其向量表示的距离尽可能接近其同义词,并且尽可能远离其反义词。对于一般情况,本文使用 SWE 进行单词嵌入,将反义词集和关系三元组结合起来,以提高词向量的质量。具体做法是:首先对于通用的关系三元组采用 Dependence Trees 方法进行语义向量转化如下图所示,然后 对于业务领域范围内的关系三元组,加入专家经验来识别处理。
OOV 新词处理器:
LSWE 的显著优点是它能够对单词进行概括,这是通过将词汇和关系特征的嵌入集成到低维欧几里得空间中来实现的。这些低维嵌入可以捕捉分布的相似性,因此信息可以在倾向于出现在相似上下文中的单词之间共享。然而,不可能列举所有日志的全部词汇,并且会遗漏在以后的服务中出现的 OOV 单词。 为了在运行时处理 OOV 单词,本文采用了 MIMICK 方法,这是一种通过学习从拼写到分布式嵌入的函数来生成 OOV 词嵌入的方法,该方法在已有的词汇数据集上训练出可用的 MIMICK 模型;然后,使用该模型在 OOV 单词上将其转换为一个唯一的词向量。MIMICK 将 OOV 单词嵌入的问题视为一个生成问题:无论原始嵌入是如何创建的,MIMICK 都假设有一个基于生成词形的协议来创建这些嵌入。通过在现有的词汇上训练一个模型,MIMICK 可以在以后使用这个模型来预测前面没遇到的单词嵌入,感觉有点类似 GAN 的生成逻辑。
适应概念漂移的日志异常检测模型
大多数现有方法都是离线使用历史日志数据来训练模型。然而,现代软件系统不断经历功能升级和系统更新;因此,日志模板可能会相应地漂移。在线更新的一种常见策略是周期性地重新训练模型,但具有很高的假阳性率,这样的策略具有有限的泛化能力。能够具备在线学习和增量学习并适合概念漂移的日志异常检测模型,将更能应对实际的日志异常检测场景。
LogRobust
Zhang, Xu, et al. “Robust log-based anomaly detection on unstable log data.” Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 2019.
文献主要工作:
现有的日志异常检测方法主要使用从历史日志中提取的日志事件数据来构建检测模型。这些方法都有一个假设,即假设日志数据随着时间的推移是稳定的,并且一组不同的日志事件是已知的。然而,在实践中,日志数据往往包含以前没出现过的日志事件或日志序列。日志数据的不稳定性主要来源于两个方面,一个是系统软硬件更新带了的日志打印语句演化,另一个是日志数据的收集、检索和预处理过程中,不可避免地会在原始日志数据中引入一定程度的噪声。
本文提出了一种具有较好鲁棒性的日志异常检测模型,能够识别和处理不稳定的日志事件和日志序列。首先考虑提取日志事件的语义信息,将每个日志事件转换成一个向量,通过语义向量化的方式即使日志事件在演化过程中发生了变化或被噪声影响,其语义向量仍然可以表示为与原始日志事件相似的向量,使用这种方法就能够处理不稳定的日志事件。然后,本文使用基于注意力的 Bi-LSTM 神经网络进行检测异常,该模型能够捕获日志序列中的上下文信息,并学习为不同的日志事件分配不同的重要程度,自动了解不同日志事件的重要性,这样便能够处理不稳定的日志序列。基于上述方法,所以 LogRobust 能够对真实的、不断变化的、有噪声的日志数据进行准确而鲁棒的异常检测。
语义向量化:
LogRobust 采用的语义向量化方法包含三个步骤:日志事件预处理、单词向量化和基于 TF-IDF 的聚合
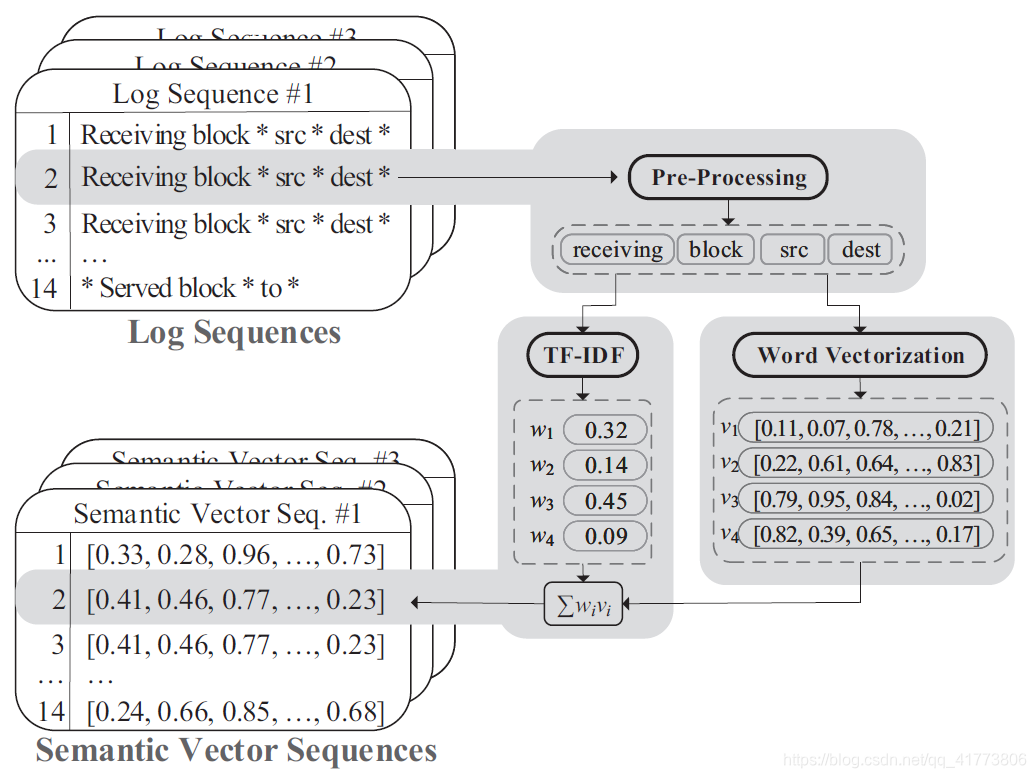
- Pre-processing of Log Events:首先从日志事件语句中移除所有非字符标记,如分隔符、运算符、标点符号和数字。然后去掉所有的停用词,如 a, the 等。另外需要考虑的是,日志事件经常出现一些驼峰形的变量名,它们实际上是单词的串联。比如变量名 TypeDeclaration 由 Type 和 Declaration 构成,LogRobust 根据驼峰规则将这些复合标记拆分为单个标记。
- Word Vectorization:使用区分度 Discrimination 语义向量应该能够高分辨地表示不同的日志事件;使用兼容性 Compatibility 语义向量应该能够识别语义相似的不稳定日志事件。使用 FastTex t算法充分捕捉自然语言中单词之间的内在关系,并将每个单词映射成词向量。
- TF-IDF Based Aggregation:使用 TF-IDF(TF:频度,IDF:反向文档里,类似停词)加权聚合方法可以有效地度量句子中单词的重要性,这正好满足了高区分度的要求。例如,如果单词 Block 经常出现在日志事件中,这意味着该单词可能更能代表该日志事件;相反,如果 Block 出现在绝大部分日志中,那可以将其视为停用词。
基于注意力的 Bi-LSTM 神经网络模型:
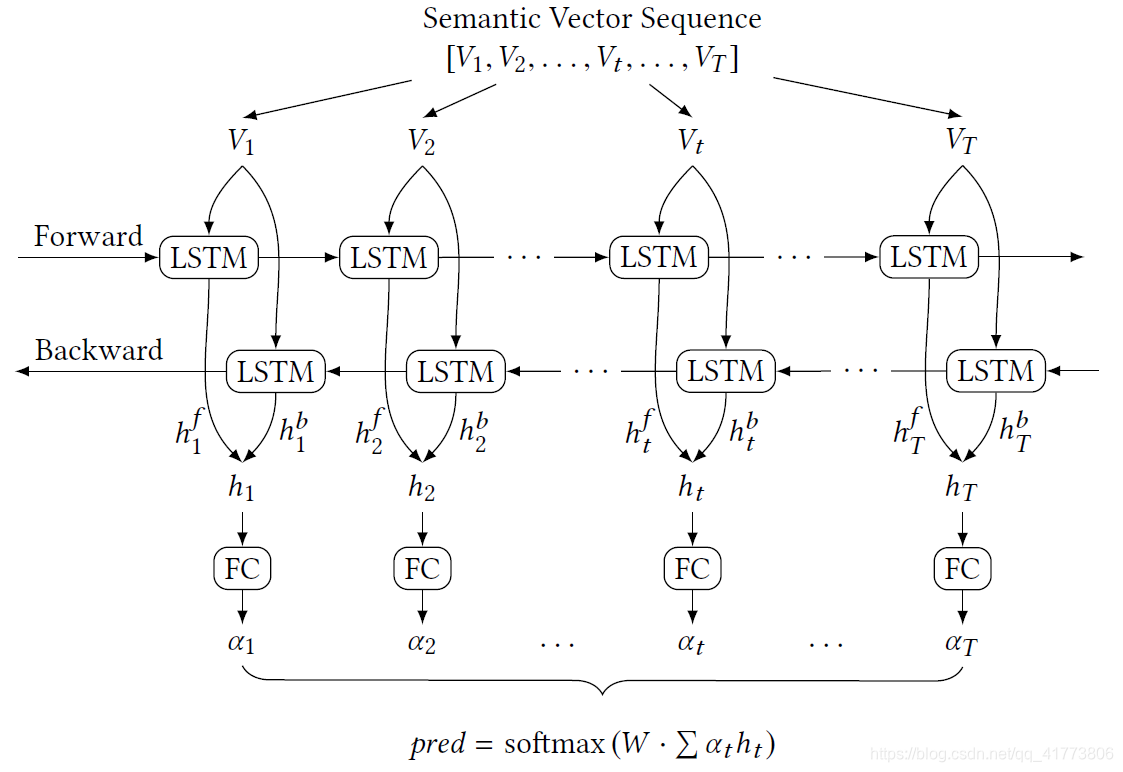
LSTM 模型是循环神经网络 RNN 的一个变种,由输入层、隐藏神经元层和输出层组成,经常被用于序列数据分析。其节点之间的连接沿着时间序列形成有向图,这种影响传播关系使得它能够捕获序列的上下文信息,这使得 LSTM 能够对动态变化的数据进行分析。Bi-LSTM 将标准的 LSTM 模型的隐藏神经元层分为两个方向,一个是前向通道和后向通道,这种方式使得 Bi-LSTM 模型可以在两个方向上捕获输入日志序列的足够信息,满足处理动态变化的处理需求。
由于不同的日志事件对分类结果有不同的影响,为了增强 Bi-LSTM 模型处理不稳定日志序列的能力,本文在 Bi-LSTM 模型中引入了注意机制,为日志事件分配不同的权重。这种方式可以将日志数据噪音的影响降低,因为那些有噪音的日志事件往往不太重要,更有可能被忽视。日志事件的重要性可以从注意力层自动学习,具体地说,如上图中的 FC 层这是一个完全连接层作为注意力层添加到串联的隐藏状态中,其输出是注意力权重,这反映了日志事件的重要性。权重越大,模型就越关注这个日志事件。最后,对所有这些权重的隐藏状态求和,然后构造一个输出层来输出分类结果。
Multi-CAD
Xie, Xueshuo, et al. “Confidence guided anomaly detection model for anti-concept drift in dynamic logs.” Journal of Network and Computer Applications 162 (2020): 102659.
文献主要工作:
前面的工作中一般使用定期的再培训来应对概念漂移,但是这总是需要领域知识和低效率,并且不能实际解决问题。主要有以下原因:
- 这些异常检测方法通常是粗粒度的异常检测,不考虑同一类中的日志差异或日志之间的不一致性;
- 之前的异常检测算法缺乏一种机制来随着数据分布或新日志与先前日志之间的关系的变化而动态更新先前的经验;
- 单个算法的决策在动态日志中缺乏鲁棒性,而多个算法的联合检测将纠正少数算法的错误检测。因此,当动态环境中的数据分布发生变化时,这些算法很难相应地改变决策,从而导致性能下降。
基于日志的异常检测算法的准确性将在动态日志中显著降低,因为系统比以前更加复杂,这种现象被称为概念漂移。本文设计了一个结合多种算法的置信度异常检测模型,称为 Multi-CAD。模型主要完成两个工作,一个是建立新旧日志的一致性的判断机制,二是构建基于置信度的多算法组合检测模型。首先,本文提出了一个统计值 p_value 来度量日志之间的不一致性,并在新日志和以前的日志中建立一个连接;另外,选择多个合适的算法作为不一致性度量来计算组合检测的分数用以判断日志之间的一致性。然后,针对动态日志中的反概念漂移设计了一种置信度引导的参数调整方法,并通过反馈机制从包含标签、非一致性分数和置信度的可信结果中更新带有相应标签的分数集,作为后续检测的前期经验。
- 如何区分同一类内的日志之间的不一致性?因为与以前日志的不一致可以用来决定新日志是否属于该类。
- 面对概念漂移问题,如何提高模型的健壮性?由于算法的鲁棒性会反映出动态日志中的准确性是否降低。
- 如何动态更新以前的经验,并使用所有经验来确定新预测的精确置信度?因为置信度表明算法对检测的确定程度。
主要方法:
Multi-CAD 主要分为预处理、不合格度量、多算法联合检测三个步骤。首先将非结构化原始日志预处理成结构化特征矩阵。在置信度的引导下,动态地选择多种算法来构成一个可插入的不合格度量模块。最后,调整显著性级别,为检测到的日志条目标记一个有置信度的标签,并反馈给相应的类作为后续检测的先前经验。
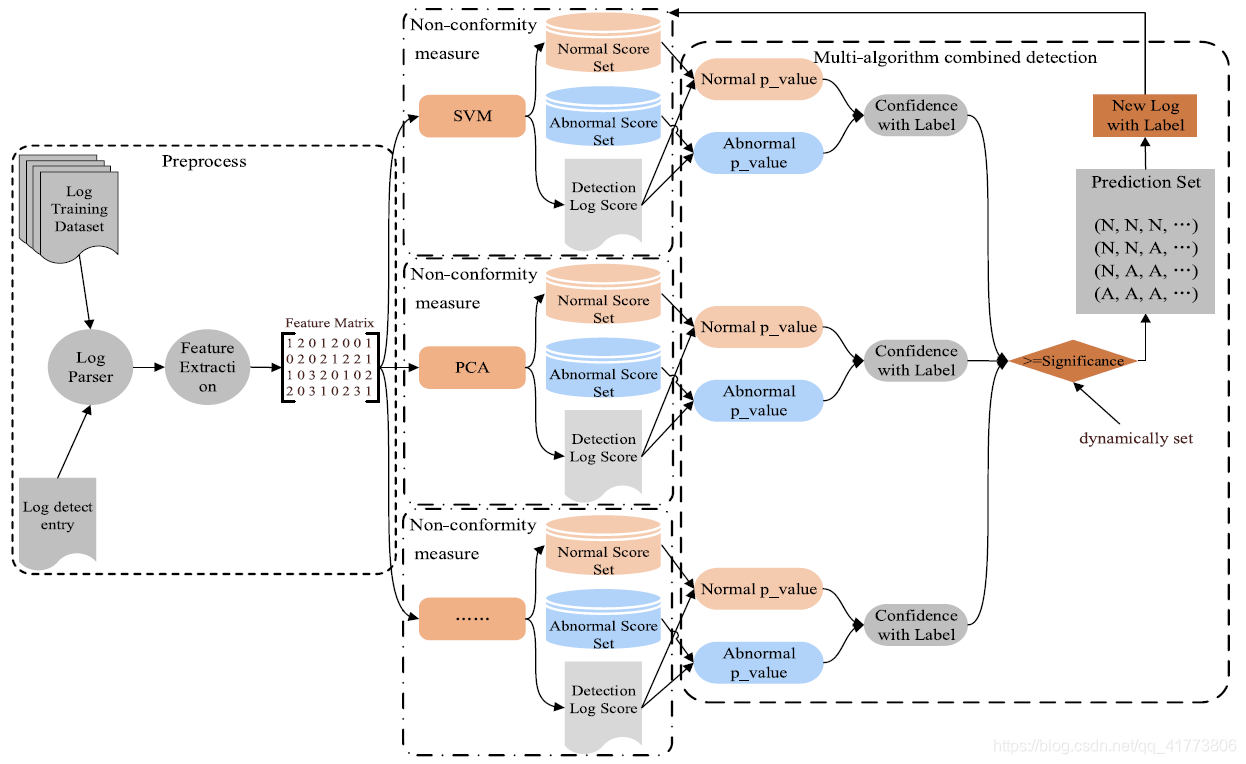
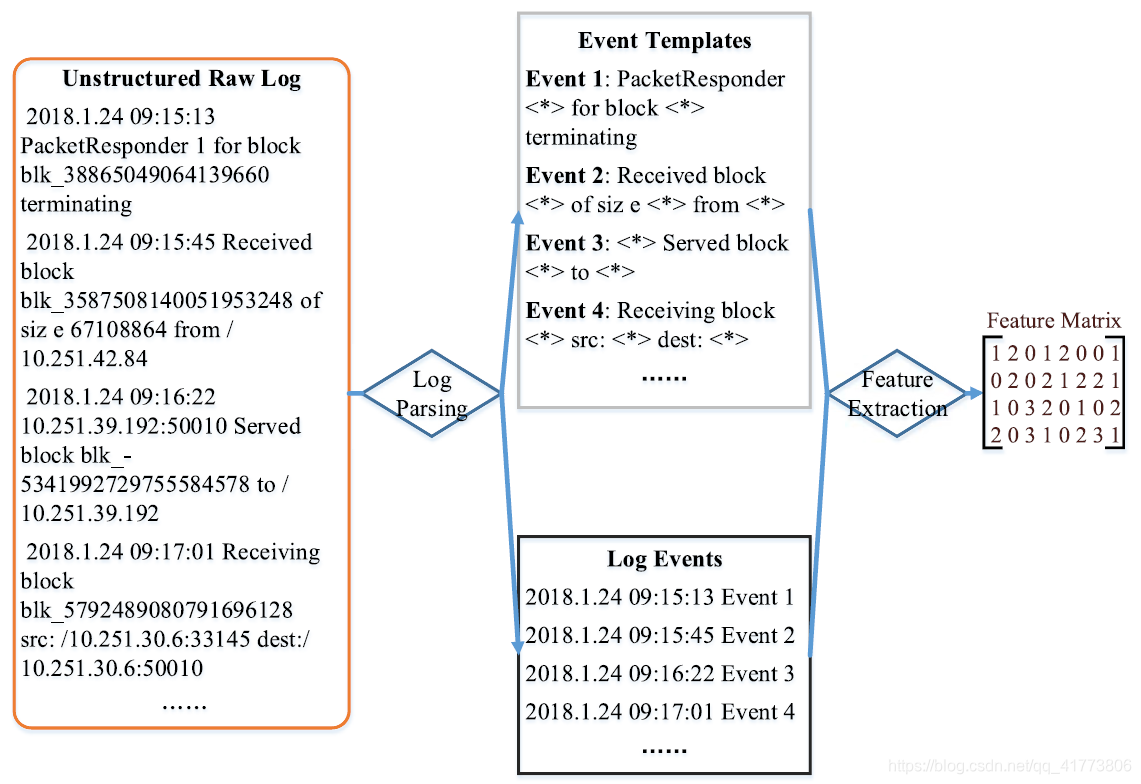
- Preprocess:日志解析的目的是提取非结构化原始日志的恒定部分,并形成事件模板。然后,将获取结构化的日志事件,以便在基于日志的异常检测中进行进一步的特征提取。基于不同设计技术的日志解析算法有很多,主要包括频繁模式挖掘、聚类、启发式规则等。在日志解析之后,需要进一步将日志事件编码成数字特征矩阵,从而可以应用基于日志的异常检测算法。特征提取器的输入是日志解析步骤中生成的日志事件,输出是特征矩阵。为此,特征提取器将使用不同的窗口技术(固定窗口、滑动窗口、会话窗口等) 来计算日志事件出现的次数,并形成特征矩阵 (或事件计数矩阵)。
- Non-conformity measure:本文提出了一个可插入的和算法无关的模块来计算非一致性分数,在置信度引导下或按需使用适当的算法作为不符合性度量。通过使用多种算法的计算将获得一个统计值 p_value。与概率不同的是 p_value 基于所有标签相同的分数计算的。p_value 值越高,新日志与具有相同标签的先前日志之间的一致性越好。很多以前分数较低的日志会证明新日志更接近这个类。因此,可以用来检测新的日志消息是否异常,并获得一个具有一定置信度的标签。(多个不同的算法对日志异常值进行打分)。最后,使用 p_value 在新数据 (即检测日志分数) 和以前的数据集 (即正常分数集和异常分数集) 之间建立连接,这将避免算法决策带来的错误,并忽略来自内部细节和算法实现的影响。因此,选择多个合适的算法来构成该模块,后续统计分析后,检测日志评分也会反馈到相应的评分集,作为后续检测的现有经验。
- Multi-algorithm combined detection:本文设计了两个置信度导向的动态调整参数分别是显著性水平和多数决策,将多种算法联合起来进行检测。每个算法都为每个日志条目检测获得一个有置信度的标签。然后每个算法给出的多个标签经过显著性水平过滤后会形成一个预测集。它将用于通过多数规则来检测异常,多算法联合决策将减少单个算法的误判,提高模型的准确性和抵抗数据分布动态变化的能力。
可解释性日志数据异常检测算法
日志分析算法是否能够提供可解释的结果对于管理员和日志分析师信任自动化分析日志数据并采取行动至关重要。一些传统的机器学习算法具有可解释性的优点。然而,深度学习模式虽然在异常检测上取得了较好的成绩,却被广泛批评为黑盒预言。因此,日志异常检测算法应该继续追求更易于解释和值得信赖的算法。
Attention-based RNN
Brown, Andy, et al. “Recurrent neural network attention mechanisms for interpretable system log anomaly detection.” Proceedings of the First Workshop on Machine Learning for Computing Systems. 2018.
文献主要工作:
之前工作中使用深度学习方法进行日志异常检测,它们在异常检测方面取得了较好的效果,但是使用者对模型的决策因素只能进行有限的理解,一定程度上只能视为黑盒预言。在本文中,作者寻求对具有优秀日志异常检测性能的深度学习模型进行改进,使其具备更好的可解释性。本文中,我们提出了增加对系统日志中异常检测的注意力机制的 RNN 日志异常检测模型。通过将注意力变量加入到RNN 语言模型,本文在不牺牲模型日志异常检测的情况下,创造了模型自省和分析的机会,提高了模型的可解释性。
主要方法:
在日志数据处理上,相对于 DeepLog 对系统日志的原始文本采用定制的解析方法来生成用于检测拒绝服务攻击的序列,本文的方法直接处理原始文本,除了使用已知的字段分隔符进行标记化之外,不进行任何预处理。
本文提出了Fixed Attention, Syntax Attention, Semantic Attention1, Semantic Attention2, Tiered Attention五种注意机制的来增强 RNN 模型在日志异常检测中的可解释性。固定注意变量 (Fixed Attention) 和句法注意变量对 (Syntax Attention) 具有固定结构的序列建模是有效的,而语义变量 (Semantic Attention) 对具有不同长度和更松散结构的输入序列更有效。在保持最先进性能的同时,注意机制提供关于特征重要性和特征之间关系映射的信息。此外,可以从应用的注意力中收集模型解视,这种方式可以设计出更有效的模型。
基于分布式机群的节点故障前置时间预测
计算机群规模的扩大使得组件数量和密度大大增加,导致中间件云服务器系统可能会出现更高的故障率。由于缺乏明确的故障指标,触发弹性缓解技术仍然是一项挑战。系统日志由非结构化文本组成,这些文本掩盖了其中包含的基本系统健康信息。在这种情况下,通过日志挖掘进行有效的故障预测预测前置时间可以使主动恢复机制提高可靠性。
Desh
Das, Anwesha, et al. “Desh: deep learning for system health prediction of lead times to failure in hpc.” Proceedings of the 27th International Symposium on High-Performance Parallel and Distributed Computing. 2018.
文献主要工作:
计算机群规模的扩大使得组件数量和密度大大增加,导致中间件云服务器系统可能会出现更高的故障率。本文旨在基于日志挖掘利用递归神经网络 LSTM 预测超级计算系统中发生的节点故障,并能够预测节点故障的前置时间。本文提出的 Desh 框架通过对操作系统和软件组件的日志数据进行普适性增强培训和分类来实现故障识别模型,这种方式避免的对日志数据地修改。Desh 使用一种三段深度学习方法,首先根据历史日志训练识别导致故障的日志事件链;然后重新训练识别具有预期故障前置时间的事件链;最后预测特定节点发生故障的前置时间。
词嵌入日志向量化方法:
Desh利用词嵌入来对日志条目进行向量化并计算故障链累积时间。通过提取这些常量消息,可以将它们编码为唯一可识别的数字。例如一个编码的短语序列,节点 N1{45,67,89,40},LSTM 模型无法在这种离散形式的数据中理解它们的语义或句法相关性。日志条目的内容一般都是用连字符连接的多词实体,使用基于分布式表示的向量空间模型有助于建立语义关联,可以用于检查一系列事件中目标事件短语之前和之后出现的内容。本文针对 TensorFlow模型使用传统的 N-gram 模型实现词嵌入对这些编码的短语进行向量化。
三阶段节点故障预测模型:
本文的节点故障检测的 Desh 框架如下图所示。该框架分为三个阶段,在第一阶段,使用词嵌入的方式将日志条目向量化,并提取导致节点故障的短语序列,通过 LSTM 模型训练识别导致故障的日志事件链。在第二阶段,来自阶段一的故障链被馈送到 LSTM 模型,以使其能计算故障链中较早的日志事件与指示节点故障的最终日志事件之间的累积时间差。在第三阶段,第二阶段的学习使框架能够估计未来故障的前置时间,并根据与训练数据不相交的测试数据指示未来发生故障的位置和前置时间。
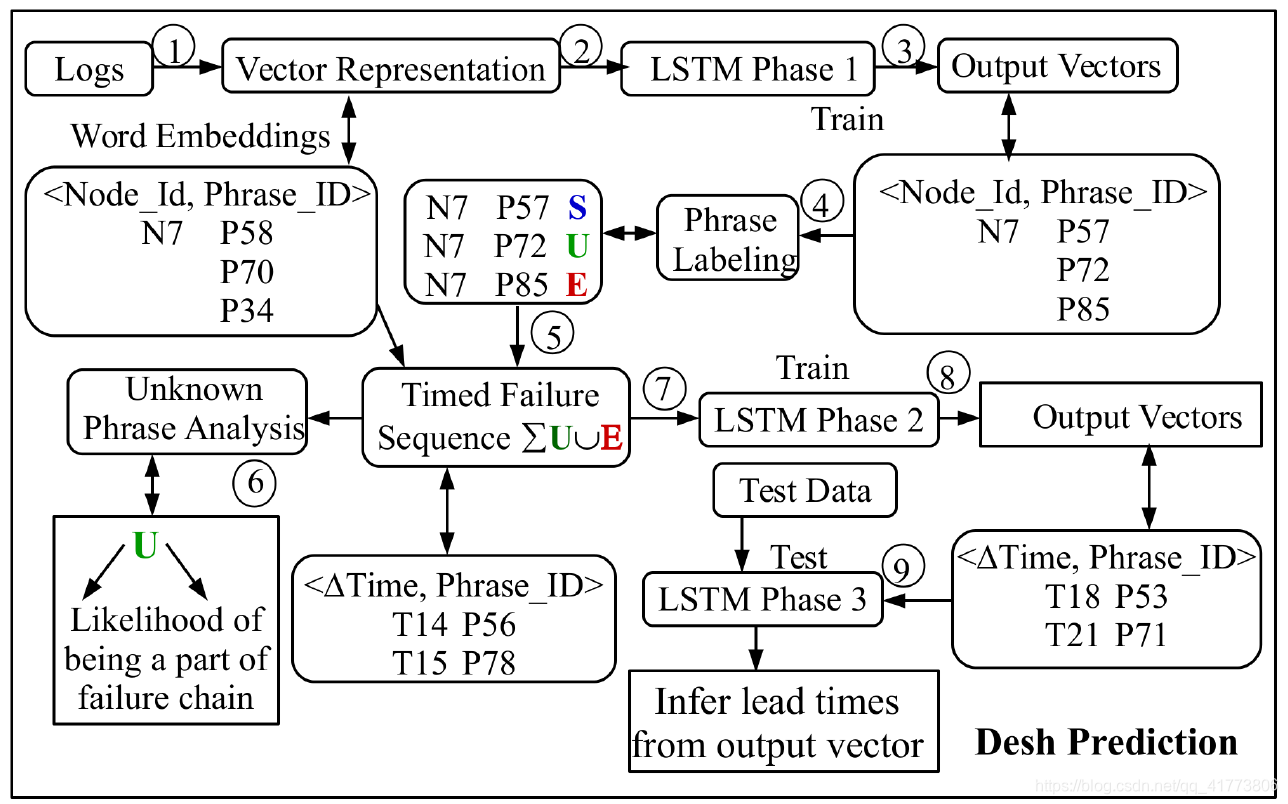
Desh 框架可以预测节点故障前置时间并跟踪节点 ID 定位故障点。例如,Desh 要预警在 2.5 分钟内,位于 Y 中的节点 X 预计将发生故障。其节点 ID 可能是(cA-cBcCsSnN) 其中包含准确的位置信息 (cabinet: AB, chassis: C, blade: S, number: #N) / (机柜:AB,机箱:C,刀片:S,编号:#N)。这种告警可提前防止在节点 X 上进一步调度作业,现有的应用程序可从该节点迁移到另一个健康的节点。这种主动行动可以减少服务中断和未来的任务执行失败。
基于工作流的非深度模型日志异常检测
执行异常检测对于大规模系统的开发、维护和性能调整非常重要。系统控制台日志是故障排除和问题诊断的重要来源。但是,由于日志文件的数量和复杂性不断增加,手动检查日志以检测异常是不可行的。因此,需要基于日志分析对日志数据进行自动化的异常检测。
CFG-based LogAnomaly
Bao, Liang, et al. “Execution anomaly detection in large-scale systems through console log analysis.” Journal of Systems and Software 143 (2018): 172-186.
文献主要工作:
本文提出了一种通用的方法来挖掘控制台日志,并以此检测系统问题。首先在计算系统源代码中提取日志语句集,生成可达性图来揭示日志语句的可达关系。然后,通过将日志语句的相关信息与信息检索技术相结合来解析日志文件以创建日志消息。这些消息根据它们的执行单元被分组到执行跟踪中。本文提出了一种新的异常检测算法,该算法将踪迹视为序列数据,并使用基于概率后缀树的方法来组织和区分序列所具有的重要统计特性。
主要方法:
本文的核心算法在于一种挖掘日志关系的分析技术和基于后缀树的异常检测方法。如下图所示,本文使用的日志分析技术是一种分析源代码以恢复所有日志语句的可达性图的技术,这种结构揭示了日志消息的所有可能组合,并且可以通过我们的检测算法进行分析。本文使用的异常检测方法是一种基于概率后缀树的统计方法,该方法可以有效地检测大量日志消息中的异常模式或异常。
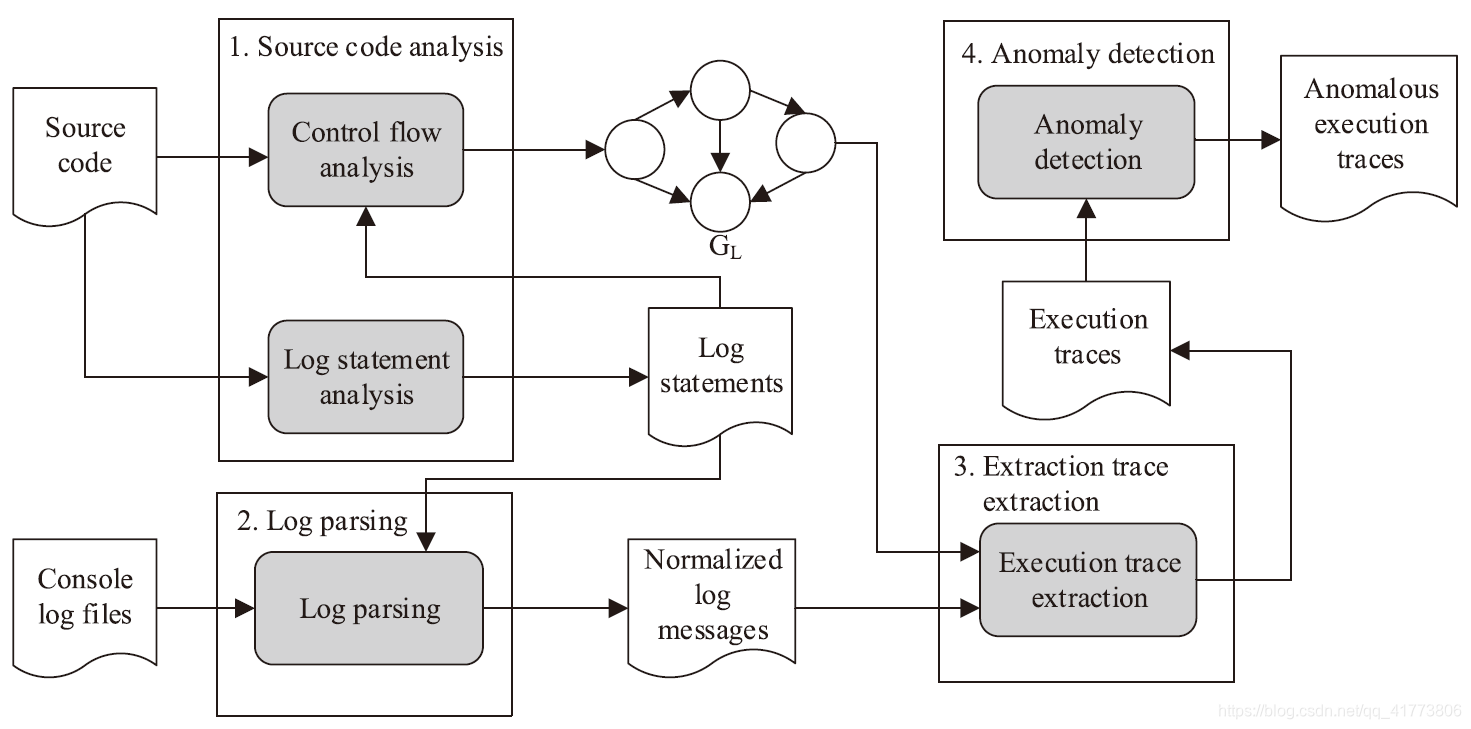
Source code analysis: 以源代码为输入,提取日志语句并生成可达性图来显示任意两个日志语句的可达关系,并从源码中获取日志键和参数变量 log statements。使用源代码作为参考来理解日志消息之间可能的逻辑关系,这使得日志分段的准确性很高,日志分段的准确性使得能够从日志文件中提取包含不同类型日志消息的完整执行轨迹。
Log parsing:使用一些预定义的正则表达式来解析每个日志消息,以获得其行号、时间戳、事件级别、出处和文本内容。然后,选择的日志语句和相应的线程标识符构成该日志消息,日志行被分为六个属性 行号、时间戳、层级、关联的日志键、进程ID和日志内容。对于每个日志消息,识别到其相关日志语句的链接,并记录相应的线程标识符。本算法使用这种链接将日志消息与以前生成的可达性图相关联,并在跟踪提取阶段通过线程标识符将相关的日志消息分组在一起。
Execution trace extraction:从日志消息中提取执行轨迹,提取算法首先对日志消息进行分割,然后根据可达性图中显示的可达关系提取不同的轨迹。
Anomaly detection:先为所有的执行轨迹定义轨迹异常索引,将执行轨迹视为序列数据,并使用序列聚类分析的方法,一种后缀树的变体,即概率后缀树,被用来组织和探索序列所具有的重要统计特性。
ADR
Zhang, Bo, et al. “Anomaly Detection via Mining Numerical Workflow Relations from Logs.” 2020 International Symposium on Reliable Distributed Systems (SRDS). IEEE, 2020.
文献主要工作:
本文提出了一种新的工作流关系异常检测方法,该方法利用矩阵零空间从日志数据中挖掘数值关系。这些挖掘出的关系可用于离线和在线异常检测,并可以用于故障诊断。对于在线异常检测,ADR (工作流关系异常检测 ) 算法采用粒子群优化算法寻找最优滑动窗口大小,实现快速异常检测。
主要方法:
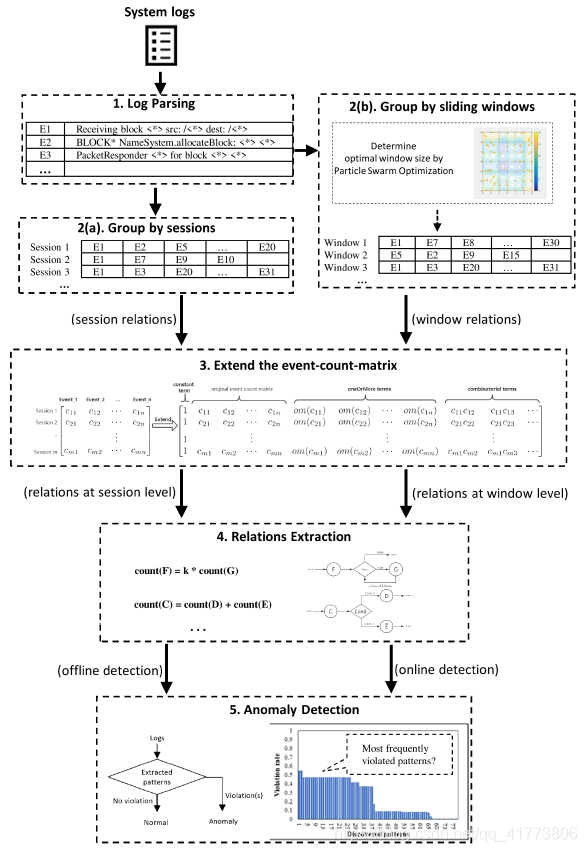
首先,将原始日志数据解析为结构化日志事件,计算事件的发生次数,并构建一个扩展的事件计数矩阵。然后,计算矩阵的零空间,矩阵零空间涵盖像顺序或条件工作流这种简单工作流和经过简单工作流组合的复杂工作流中的关系。使用这种日志解析方法,可以自动提取日志事件之间的关系,并将算法检测到的违反关系可用于异常识别,同时可以用于解释异常提搞算法的可解释性。
然后,通过使用粒子群优化算法PSO搜索动态选择合适的窗口大小,例如使用会话或滑动窗口将解析的日志事件分组为序列;对于每个会话或窗口,对其日志事件的发生进行计数,产生事件计数矩阵;接着,通过评估事件计数矩阵的零空间,从事件计数矩阵中提取可用的数值关系;最后,提取的关系用于以离线或在线方式检测异常日志序列。
并发场景的非深度模型日志异常检测
云系统一直都受到分布式并发错误的困扰,因为正确推理和处理多台机器上的并发执行太过于复杂。现实世界的分布式系统中广泛存在并发错误,而且这种错误难以检测,同时这写错误通常会导致数据丢失,有时会导致服务中断,带来巨大的损失。为此,需要一种能够对抗分布式并发缺陷的新策略。
CloudRaid
Lu, Jie, et al. “Cloudraid: hunting concurrency bugs in the cloud via log-mining.” Proceedings of the 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 2018.
文献主要工作:
本文提出了一种称为 CloudRaid 的分布式并发错误对抗策略。CloudRaid 通过分析和测试那些可能暴露错误的消息顺序,自动检测云系统中的并发错误。本文关注大规模在线云应用程序处理用户请求被广泛使用的消息排序排列。CloudRaid 从历史任务执行中挖掘日志数据,以发现那些可以执行但没有充分测试的消息顺序正确性的消息排序。例如,<s,p> 这样一对消息,它们可以并行发生,但是日志事件中 s 的日志总是在 p 之前到达,即执行顺序是p 依赖于 s。
主要方法:
CloudRaid 主要步骤如下图所示:首先将静态消息的日志模式表示为正则表达式 < C,F,L >。然后进行日志分析,使用日志模式将每个运行时日志实例映射到一个静态消息。ID 分析中根据记录变量与根据日志分析得到的其运行时间值之间的相关性;通过分析记录值之间的关系,将来自同一运行的消息可以与其他运行消息区分开来,并组合在一起。HB分析用于静态分析静态消息之间的先发生顺序。在消息对分析中使用来自 HB 分析和 ID 分析的分析结果,以选择用于进一步测试的消息顺序。最后,触发器将使用源代码来执行所选的消息排序,以发现执行正确但未充分测试的消息排序。
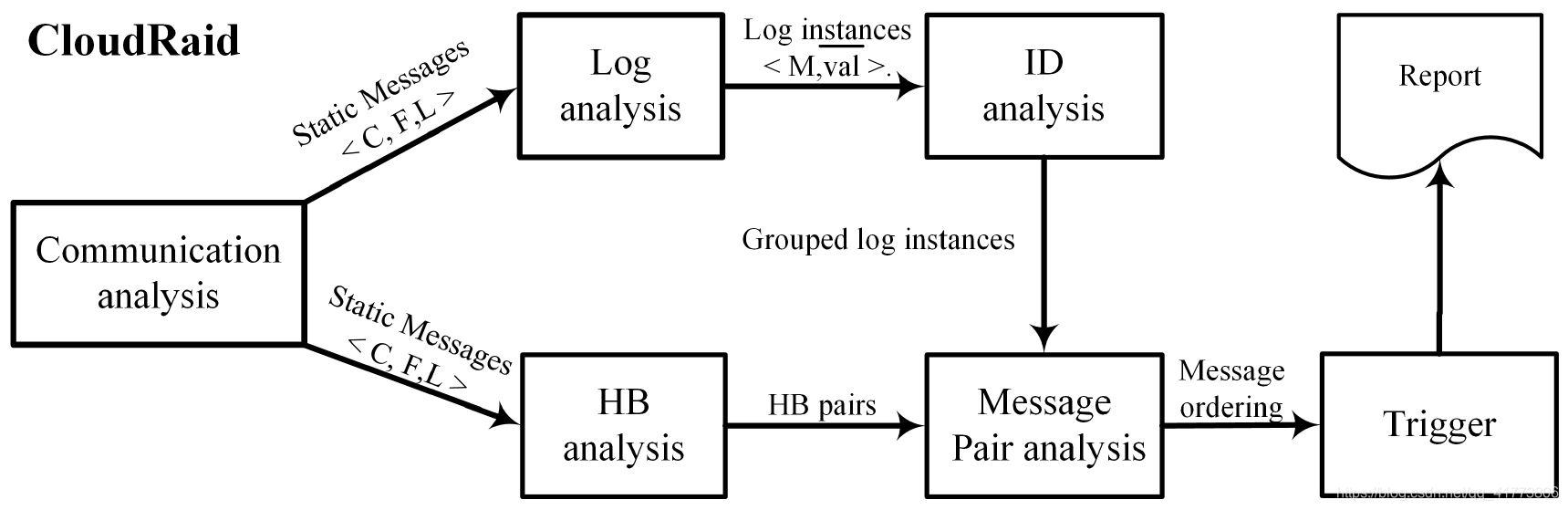
Communication analysis 将每个静态消息表示为 3 个元素的元组 < C,F,L >,其中 C 是发送消息的客户端,F 是对应的消息处理程序,L 是表达其日志模式的正则表达式。
3 EventProcessor.run Launching attempt_*
11 ContainerManagerImpl.startContainer Start request for container_*
Log analysis 日志分析试图将每个运行时日志实例与消息日志模式相匹配。日志实例被表示为一个元组,其中M是静态消息,Val记录了日志变量的运行时值
ID analysis 在分布式系统中,ID Values通常用于区分不同的请求和任务,基于 ID Values 进行ID分析,具有相同 ID Values的日志实例被分组在一起执行任务。一个任务用一个 ID Values进行索引,并可以进一步划分为子任务。如果两个任务的 ID Values相关,则它们是相关的。一个任务是另一个任务的子任务,如果它的 ID Values是另一个任务的子标识。
HB analysis 分析静态消息之间的可传递的先发生关系,例如 P:<C1,F1,L1> S:<C2,F2,L2>,如果 C2 在 F1中则P先于S发生,如果 C1 可以通过 RPC 控制 C2,则 P 也先于 S 发生。
Message Pair Analysis 对 HB Analysis 的消息关系的进一步检测,过以成对的方式比较它们的日志实例来检查 p 和 s 是否相关,以及 P > S 的顺序是否已经被执行。
Trigger 通过维护一个运行时的状态机来检测系统执行所选的消息顺序是否存在异常

- 点赞
- 收藏
- 关注作者
评论(0)