mobileNetV1网络解析,以及实现(pytorch)

Google提出了移动端模型MobileNet,其核心是采用了深度可分离卷积,其不仅可以降低模型计算复杂度,而且可以大大降低模型大小,适合应用在真实的移动端应用场景。在认识MobileNet之前,我们先了解一下什么是深度可分离卷积,以及和普通卷积的区别。
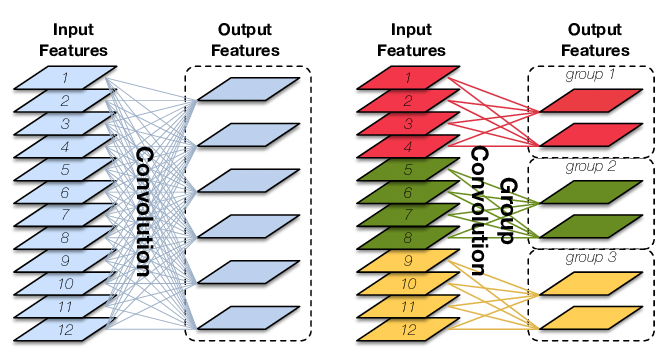
上面的图片展示了普通卷积和分组卷积的不同,下面我们通过具体的例子来看。
普通卷积
标准卷积运算量的计算公式:
计算公式参考:深度学习之(经典)卷积层计算量以及参数量总结 (考虑有无bias,乘加情况) - 琴影 - 博客园 (cnblogs.com)
参数量计算公式:
:输入的通道。
K:卷积核大小。
H,W:输出 feature map的大小
:输出通道的大小。
bias=False,即不考虑偏置的情况有-1,有True时没有-1。
举例:
输入的尺寸是227×227×3,卷积核大小是11×11,输出是6,输出维度是55×55,
我们带入公式可以计算出
参数量:
=2178
运算量:
=13176900
分组卷积
分组卷积则是对输入feature map进行分组,然后每组分别卷积。
假设输入feature map的尺寸仍为 ,输出feature map的数量为 个,如果设定要分成G个groups,则每组的输入feature map数量为 ,每组的输出feature map数量为 ,每个卷积核的尺寸为 ,卷积核的总数仍为 个,每组的卷积核数量为 ,卷积核只与其同组的输入map进行卷积,卷积核的总参数量为 ,总参数量减少为原来的 。
计算量公式:
分组卷积的参数量为:
举例:
输入的尺寸是227×227×3,卷积核大小是11×11,输出是6,输出维度是55×55,group为3
我们带入公式可以计算出
参数量:
=726
运算量:
=2205225
深度可分离卷积(Depthwise separable conv)
设输入特征维度为 ,M为通道数, 为卷积核大小,M为输入的通道数, N为输出的通道数,G为分组数。
当分组数量等于输入map数量,输出map数量也等于输入map数量,即M=N=G,N个卷积核每个尺寸为$D_{k}\times D_{k}\times 1 $时,Group Convolution就成了Depthwise Convolution。
逐点卷积就是把G组卷积用conv1x1拼接起来。如下图:

深度可分离卷积有深度卷积+逐点卷积。计算如下:
-
深度卷积:设输入特征维度为 ,M为通道数。卷积核的参数为 。输出深度卷积后的特征维度为: 。卷积时每个通道只对应一个卷积核(扫描深度为1),所以 FLOPs为:
-
逐点卷积:输入为深度卷积后的特征,维度为 。卷积核参数为 。输出维度为 。卷积过程中对每个特征做 的标准卷积, FLOPs为:
将上面两个参数量相加就是
所以深度可分离卷积参数量是标准卷积的
mobileNetV1
详见论文翻译:
https://blog.csdn.net/hhhhhhhhhhwwwwwwwwww/article/details/122692846
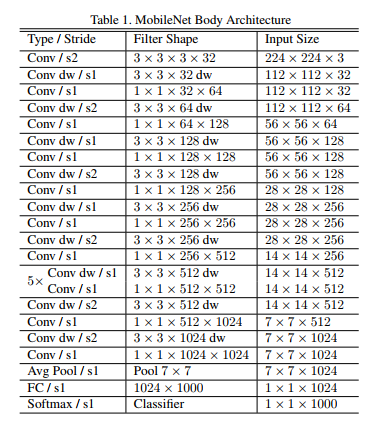
mobileNetV1的网络结构如下图.前面的卷积层中除了第一层为标准卷积层外,其他都是深度可分离卷积(Conv dw + Conv/s1),卷积后接了一个7*7的平均池化层,之后通过全连接层,最后利用Softmax激活函数将全连接层输出归一化到0-1的一个概率值,根据概率值的高低可以得到图像的分类情况。
pytorch版本
import torch
import torch.nn as nn
import torchvision
def BottleneckV1(in_channels, out_channels, stride):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels,out_channels=in_channels,kernel_size=3,stride=stride,padding=1,groups=in_channels),
nn.BatchNorm2d(in_channels),
nn.ReLU6(inplace=True),
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1),
nn.BatchNorm2d(out_channels),
nn.ReLU6(inplace=True)
)
class MobileNetV1(nn.Module):
def __init__(self, num_classes=1000):
super(MobileNetV1, self).__init__()
self.first_conv = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=32,kernel_size=3,stride=2,padding=1),
nn.BatchNorm2d(32),
nn.ReLU6(inplace=True),
)
self.bottleneck = nn.Sequential(
BottleneckV1(32, 64, stride=1),
BottleneckV1(64, 128, stride=2),
BottleneckV1(128, 128, stride=1),
BottleneckV1(128, 256, stride=2),
BottleneckV1(256, 256, stride=1),
BottleneckV1(256, 512, stride=2),
BottleneckV1(512, 512, stride=1),
BottleneckV1(512, 512, stride=1),
BottleneckV1(512, 512, stride=1),
BottleneckV1(512, 512, stride=1),
BottleneckV1(512, 512, stride=1),
BottleneckV1(512, 1024, stride=2),
BottleneckV1(1024, 1024, stride=1),
)
self.avg_pool = nn.AvgPool2d(kernel_size=7,stride=1)
self.linear = nn.Linear(in_features=1024,out_features=num_classes)
self.dropout = nn.Dropout(p=0.2)
self.softmax = nn.Softmax(dim=1)
self.init_params()
def init_params(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
nn.init.constant_(m.bias,0)
elif isinstance(m, nn.Linear) or isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.first_conv(x)
x = self.bottleneck(x)
x = self.avg_pool(x)
x = x.view(x.size(0),-1)
x = self.dropout(x)
x = self.linear(x)
out = self.softmax(x)
return out
if __name__=='__main__':
model = MobileNetV1()
print(model)
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)

- 点赞
- 收藏
- 关注作者
评论(0)