✨[hadoop3.x]新一代的存储格式Apache Arrow(四)

@[toc]
前言
目前博客Hadoop文章大都停留在Hadoop2.x阶段,本系列将对2.x没有的新特性进行补充更新,一键三连加关注,下次不迷路!
历史文章
[hadoop3.x系列]HDFS REST HTTP API的使用(一)WebHDFS
[hadoop3.x系列]HDFS REST HTTP API的使用(二)HttpFS
[hadoop3.x系列]Hadoop常用文件存储格式及BigData File Viewer工具的使用(三)
✨[hadoop3.x]新一代的存储格式Apache Arrow(四)
🍑新一代的存储格式Apache Arrow

🐒Arrow简介
l Apache Arrow是一个跨语言平台,是一种列式内存数据结构,主要用于构建数据系统。Apache Arrow在2016年2月17日作为顶级Apache项目引入。
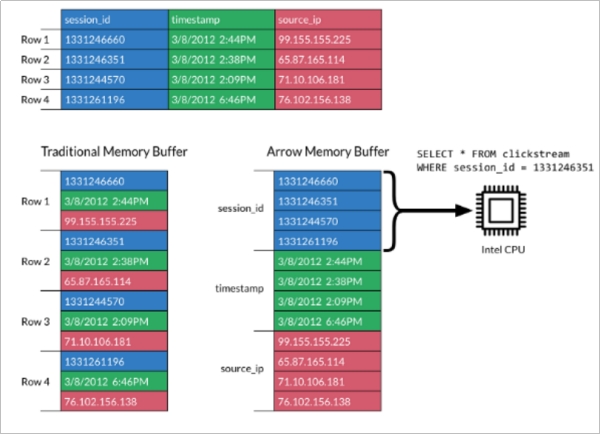
l Apache Arrow发展非常迅速,并且在未来会有更好的发展空间。 它可以在系统之间进行高效且快速的数据交换,而无需进行序列化,而这些成本已与其他系统(例如Thrift,Avro和Protocol Buffers)相关联。
l 每一个系统实现,它的方法(method)都有自己的内存存储格式,在开发中,70%-80%的时间浪费在了序列化和反序列化上。
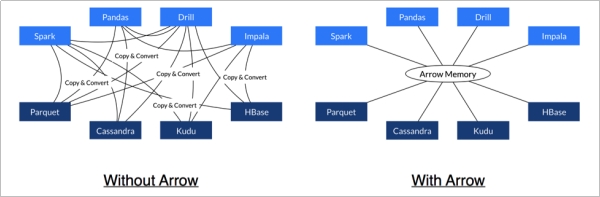
l Arrow促进了许多组件之间的通信。 例如,使用Python(pandas)读取复杂的文件并将其转换为Spark DataFrame。
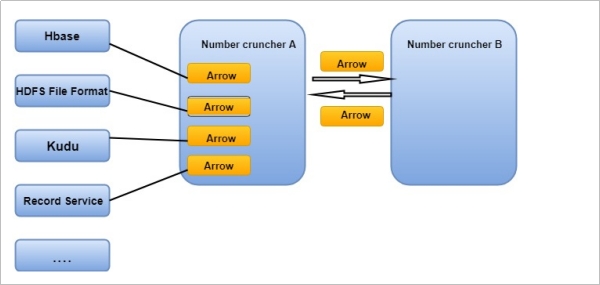
🐒Arrow是如何提升数据移动性能的
l 利用Arrow作为内存中数据表示的两个过程可以将数据从一种方法“重定向”到另一种方法,而无需序列化或反序列化。 例如,Spark可以使用Python进程发送Arrow数据来执行用户定义的函数。
l 无需进行反序列化,可以直接从启用了Arrow的数据存储系统中接收Arrow数据。 例如,Kudu可以将Arrow数据直接发送到Impala进行分析。
以将Arrow数据直接发送到Impala进行分析。
l Arrow的设计针对嵌套结构化数据(例如在Impala或Spark Data框架中)的分析性能进行了优化。
后记
📢博客主页:https://manor.blog.csdn.net
📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
📢本文由 manor 原创,首发于 CSDN博客🙉
📢Hadoop系列文章会每天更新!✨

- 点赞
- 收藏
- 关注作者
评论(0)