SQL思维快速上手使用Pandas

大多数数据工作者都学过SQL,却没有学过Pandas,本文的目标是让熟悉SQL语法的朋友能够快速在pandas上使用同样思维的等价方法。
下面测试的过程中,数据库中存在下面三张表,数据库版本为MySQL 8.0.19:
(上面使用的数据库可视化工具为SQLyog)
本文涉及的库,可以使用pip安装:
pip install sqlalchemy
pip install pandas -U
pip install pandasql
- 1
- 2
- 3
数据来源:
tips.csv:https://raw.github.com/pandas-dev/pandas/master/pandas/tests/io/data/csv/tips.csv
meat.csv和births.csv:
from pandasql import load_meat, load_births
load_meat().to_csv("meat.csv", index=False)
load_births().to_csv("births.csv", index=False)
- 1
- 2
- 3
- 4
想把数据拿到pandas中处理,最直接的办法就是,直连数据库,直接用现成的sql语句从数据库取数,这样Pandas拿到的数据本身就已经是在MySQL中处理好的。
Pandas直接读写MySQL
获取数据库连接(根据数据库实际情况修改):
from sqlalchemy import create_engine
import pandas as pd
host = 'localhost'
database = 'pandas'
user_name = 'root'
password = '123456'
port = 3306
engine = create_engine(
f'mysql+pymysql://{user_name}:{password}@{host}:{port}/{database}')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
读取数据:
query = "SELECT total_bill, tip, smoker, time FROM tips limit 5"
df = pd.read_sql(query, engine)
df
- 1
- 2
- 3
| total_bill | tip | smoker | time | |
|---|---|---|---|---|
| 0 | 16.99 | 1.01 | No | Dinner |
| 1 | 10.34 | 1.66 | No | Dinner |
| 2 | 21.01 | 3.50 | No | Dinner |
| 3 | 23.68 | 3.31 | No | Dinner |
| 4 | 24.59 | 3.61 | No | Dinner |
对于被pandas处理过的数据,我们还可以回写到MySQL数据库指定的表中:
df.to_sql(name='test', con=engine, if_exists='append', index=False)
- 1
name参数表示表名,if_exists表示表已经存在时的处理策略,包括’fail’, ‘replace’, 'append’三个参数:
- fail:存在则报错,写入失败。
- replace:删除原表再插入数据。
- append:向源表追加数据。
使用replace参数时需要注意,pandas创建的表,数据类型可能不符合预期。append则会按照原有数据类型追加。
对于上表,我们需要pandas能创建指定类型的表时,可以从sqlalchemy.types导入相应的类型:
from sqlalchemy.types import CHAR
df.to_sql(name='test', con=engine, if_exists='replace',
index=False, dtype={"smoker": CHAR(3), "time": CHAR(6)})
- 1
- 2
- 3
这样对于这两列,pandas创建的表将不再是text长文本类型。
有时我们写入多个表时,需要开启数据库事务,可以使用engine.begin()开启一个带事务的连接,关闭连接事务将自动提交:
with engine.begin() as conn:
df.to_sql(name='test', con=engine, if_exists='append', index=False)
- 1
- 2
SQL思维对比Pandas思维
下面我们再继续看假如我们的数据不在MySQL数据库上,而是直接在本地文件时该如何处理呢?
标准的SQL查询语法如下:
select (distinct) [字段]
from [表1] join [表2] on [匹配字段]
where [过滤条件]
group by [字段]
having [过滤条件]
order by [字段] desc
limit [个数] offset [个数]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
下面将给出每种语法对应的pandas语法。
首先,让Pandas读取数据:
import pandas as pd
tips = pd.read_csv("tips.csv")
meat = pd.read_csv("meat.csv")
births = pd.read_csv("births.csv")
- 1
- 2
- 3
- 4
- 5
SELECT查询
比如在MySQL中查询指定的列:
SELECT total_bill, tip, smoker, time
FROM tips
LIMIT 5;
- 1
- 2
- 3

对于这种与sqlite相兼容的sql语法,我们完全可以直接使用pandassql做到无缝对接。
首先我们对pandasql提供的sqldf进行柯里化(currying),将需要反复传入的globals()封装起来。
from pandasql import sqldf
def pysqldf(q): return sqldf(q, globals())
- 1
- 2
- 3
这样我们就得到一个传入sql语句直接获取结果的pysqldf函数,由于我们封装了globals()全局变量空间,所有Datafream类型的变量名都可以被注册为sqlite内存表的表名被查询。
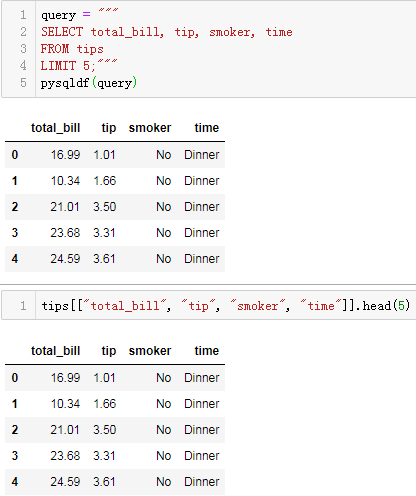
这样我们就可以直接对Pandas对象使用sql操作:
query = """
SELECT total_bill, tip, smoker, time
FROM tips
LIMIT 5;"""
pysqldf(query)
- 1
- 2
- 3
- 4
- 5
但pandasql的核心原理是通过sqlalchemy创建sqlite的内存表,查询时先将对应的数据写入到sqlite的内存表中,再调用sql语句查询。多少有点浪费性能,我们还是也顺便学点基本的Pandas操作更佳。
Pandas的操作为:
tips[["total_bill", "tip", "smoker", "time"]].head(5)
- 1
假如存在新列创建时:
SELECT *, tip/total_bill as tip_rate
FROM tips
LIMIT 5;
- 1
- 2
- 3

pandas基本API操作为:
tips.assign(tip_rate=tips["tip"] / tips["total_bill"]).head(5)
- 1
对于基本的四则运算产生的新列还可以使用eval函数来创建:
tips.eval("tip_rate=tip/total_bill").head(5)
- 1
结果都与上面相同。
DISTINCT去重
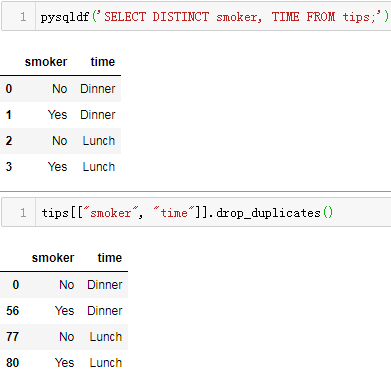
假设我们想查询指定列去重后的结果:
SELECT DISTINCT smoker, TIME FROM tips;
- 1
对应pandas操作为:
tips[["smoker", "time"]].drop_duplicates()
- 1
WHERE过滤
对于sql语句:
SELECT *
FROM tips
WHERE time = 'Dinner' AND tip > 5.00;
- 1
- 2
- 3
对应pandas操作为:
tips[(tips["time"] == "Dinner") & (tips["tip"] > 5.00)]
- 1
这种全列查询的where过滤,使用query函数会更简单:
tips.query("time=='Dinner' & tip>5")
- 1
结果为:

对于sql语句:
SELECT *
FROM tips
WHERE size >= 5 OR total_bill > 45;
- 1
- 2
- 3
对应pandas基础API操作为:
tips[(tips["size"] >= 5) | (tips["total_bill"] > 45)]
- 1
query函数:
tips.query("size>=5 | total_bill>45")
- 1
结果均为:
如果我们在过滤同时还需筛选指定列时,比如对于sql语句:
SELECT DAY, tip, sex
FROM tips
WHERE TIME = 'Dinner'
LIMIT 5;
- 1
- 2
- 3
- 4
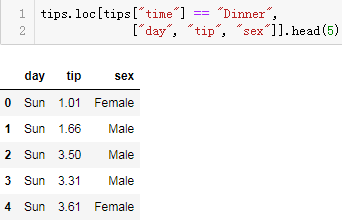
直接使用loc函数会简单很多:
tips.loc[tips["time"] == "Dinner", ["day", "tip", "sex"]].head(5)
- 1
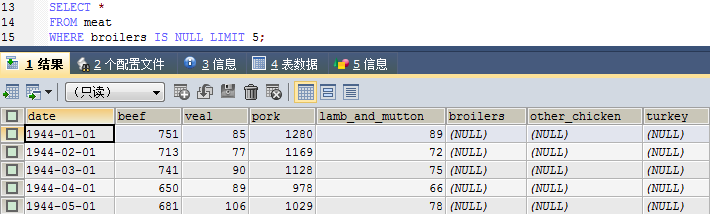
假如我们要查询某列为空的行:
SELECT *
FROM meat
WHERE broilers IS NULL LIMIT 5;
- 1
- 2
- 3
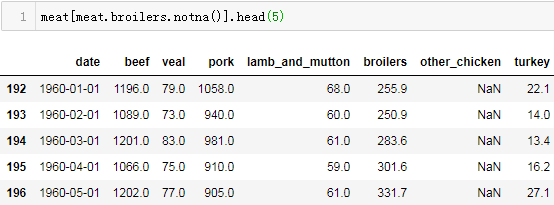
对应pandas操作为:
meat[meat.broilers.isna()].head(5)
- 1
假如要查询某列不为空的行:
SELECT *
FROM meat
WHERE broilers IS NOT NULL LIMIT 5;
- 1
- 2
- 3
对应pandas操作为:
meat[meat.broilers.notna()].head(5)
- 1
GROUP BY分组
SELECT sex, count(*)
FROM tips
GROUP BY sex;
- 1
- 2
- 3
对应pandas操作:
tips.groupby("sex").size()
- 1

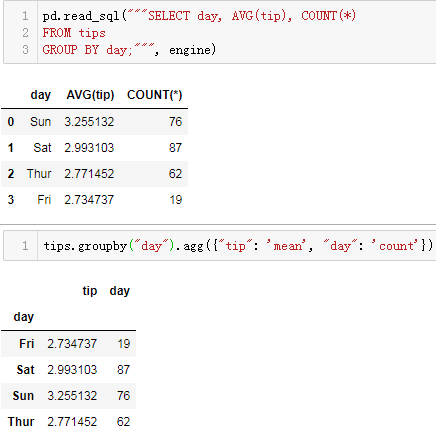
SELECT day, AVG(tip), COUNT(*)
FROM tips
GROUP BY day;
- 1
- 2
- 3
对应pandas操作:
tips.groupby("day").agg({"tip": 'mean', "day": 'count'})
- 1
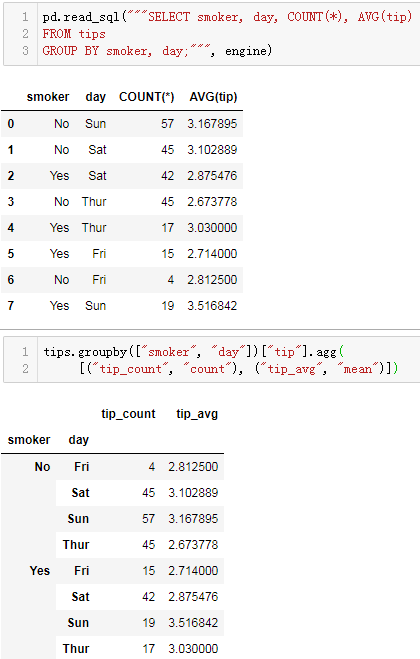
SELECT smoker, day, COUNT(*), AVG(tip)
FROM tips
GROUP BY smoker, day;
- 1
- 2
- 3
对应pandas操作:
tips.groupby(["smoker", "day"])["tip"].agg(
[("tip_count", "count"), ("tip_avg", "mean")])
- 1
- 2
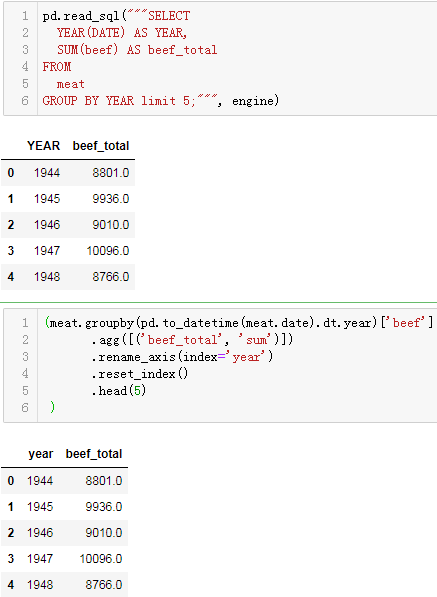
按计算过的字段分组:
SELECT
YEAR(DATE) AS YEAR,
SUM(beef) AS beef_total
FROM
meat
GROUP BY YEAR ;
- 1
- 2
- 3
- 4
- 5
- 6
对应pandas操作:
(meat.groupby(pd.to_datetime(meat.date).dt.year)['beef']
.agg([('beef_total', 'sum')])
.rename_axis(index='year')
.reset_index()
.head(5)
)
- 1
- 2
- 3
- 4
- 5
- 6
HAVING
分组过过滤出平均小费小于3的数据:
SELECT DAY, AVG(tip) avg_tip, COUNT(*)
FROM tips
GROUP BY DAY
HAVING avg_tip<3;
- 1
- 2
- 3
- 4
只需对分组过的查询结果继续进行query过滤即可:
tips.groupby("day").agg({"tip": [('avg_tip', 'mean')], "day": 'count'}).droplevel(0, axis=1).query("avg_tip<3")
- 1

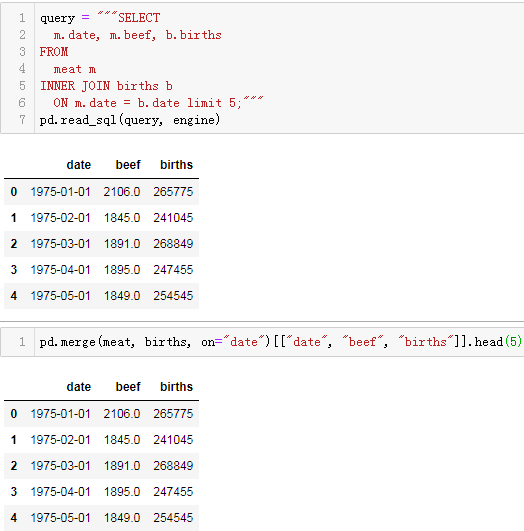
JOIN
sql:
SELECT
m.date, m.beef, b.births
FROM
meat m
INNER JOIN births b
ON m.date = b.date ;
- 1
- 2
- 3
- 4
- 5
- 6
对应Pandas操作:
pd.merge(meat, births, on="date")[["date", "beef", "births"]]
- 1
当然还有左连接和右连接:
SELECT
m.date, m.beef, b.births
FROM
meat m
LEFT JOIN births b
ON m.date = b.date ;
SELECT
m.date, m.beef, b.births
FROM
meat m
RIGHT JOIN births b
ON m.date = b.date ;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
对应Pandas操作:
pd.merge(meat, births, how="left", on="date")[["date", "beef", "births"]]
pd.merge(meat, births, how="right", on="date")[["date", "beef", "births"]]
- 1
- 2
UNION与UNION ALL
sql:
SELECT DISTINCT TIME, size FROM tips WHERE smoker = 'No'
UNION ALL
SELECT DISTINCT TIME, size FROM tips WHERE smoker = 'Yes' ;
- 1
- 2
- 3
在Pandas对应操作:
df1 = tips.loc[tips.smoker == 'No', ["time", "size"]].drop_duplicates()
df2 = tips.loc[tips.smoker == 'Yes', ["time", "size"]].drop_duplicates()
pd.concat([df1, df2])
- 1
- 2
- 3
如果是UNION:
SELECT DISTINCT TIME, size FROM tips WHERE smoker = 'No'
UNION
SELECT DISTINCT TIME, size FROM tips WHERE smoker = 'Yes' ;
- 1
- 2
- 3
sql语句对合并的结果还会进行去重操作,在pandas中也只需要合并再去重即可:
pd.concat([df1, df2]).drop_duplicates()
- 1
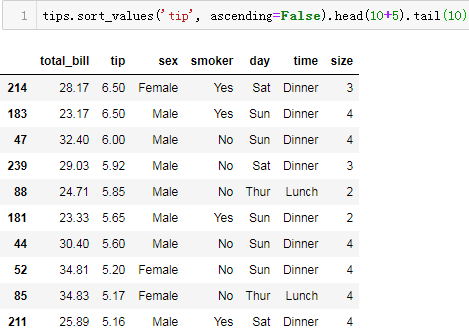
order by与limit offset
对于sql:
SELECT * FROM tips
ORDER BY tip DESC
LIMIT 10 OFFSET 5;
- 1
- 2
- 3
或:
SELECT * FROM tips
ORDER BY tip DESC
LIMIT 5,10;
- 1
- 2
- 3
表示按小费tip倒序排序,从第6条记录开始取10条记录。
Pandas操作对应操作
方法1:
tips.sort_values('tip', ascending=False).head(10+5).tail(10)
- 1
方法2:
tips.nlargest(5+10, 'tip').tail(10)
- 1

方法3:
tips.sort_values('tip', ascending=False, ignore_index=True).loc[5:5+10-1]
- 1

参考资料:
https://pypi.org/project/pandasql/
https://pandas.pydata.org/pandas-docs/stable/getting_started/comparison/comparison_with_sql.html
文章来源: xxmdmst.blog.csdn.net,作者:小小明-代码实体,版权归原作者所有,如需转载,请联系作者。
原文链接:xxmdmst.blog.csdn.net/article/details/114542458

- 点赞
- 收藏
- 关注作者
评论(0)