深度学习和目标检测系列教程 22-300:关于人体姿态常见的估计方法

@Author:Runsen
姿态估计是计算机视觉中的一项流行任务,比如真实的场景如何进行人体跌倒检测,如何对手语进行交流。
作为人工智能(AI)的一个领域,计算机视觉使机器能够以模仿人类视觉为目的来执行图像处理任务。
在传统的物体检测中,人们只会被感知为一个边界框(一个正方形)。通过执行姿势检测和姿势跟踪,计算机可以理解人体语言。然而,传统的姿势跟踪方法既不够快,也不够稳健,无法实现遮挡。
高性能实时姿势检测和跟踪将推动计算机视觉领域的一些最大趋势。例如,实时跟踪人体姿势将使计算机能够对人类行为进行更细粒度、更自然的理解。
这将对各个领域产生重大影响,例如在自动驾驶领域,通过实时人体姿势检测和跟踪,计算机能够更好地理解和预测行人行为——从而实现更自然的驾驶。

人体姿态估计旨在预测图像或视频中人体部位和关节的姿态。由于姿势运动通常由某些特定的人类动作驱动,因此了解人类的身体姿势对于动作识别至关重要。
二维人体姿态估计用于从图像和视频等视觉对象中估计人体关键点的二维位置或空间位置。传统的 2D 人体姿态估计方法对各个身体部位使用不同的手工特征提取技术。
基于现代深度学习的方法通过显着提高单人和多人姿势估计的性能取得了重大突破。一些流行的 2D 人体姿态估计方法包括 OpenPose、CPN、AlphaPose 和 HRNet。

在人体姿势估计中,人体部位的位置用于根据视觉输入数据构建人体表示(例如身体骨架姿势)。因此,人体建模是人体姿态估计的一个重要方面。它用于表示从视觉输入数据中提取的特征和关键点。通常,基于模型的方法用于描述和推断人体姿势并渲染 2D 或 3D 姿势。
大多数方法使用 N 关节刚性运动学模型,其中人体被表示为具有关节和四肢的实体,包含身体运动学结构和身体形状信息。
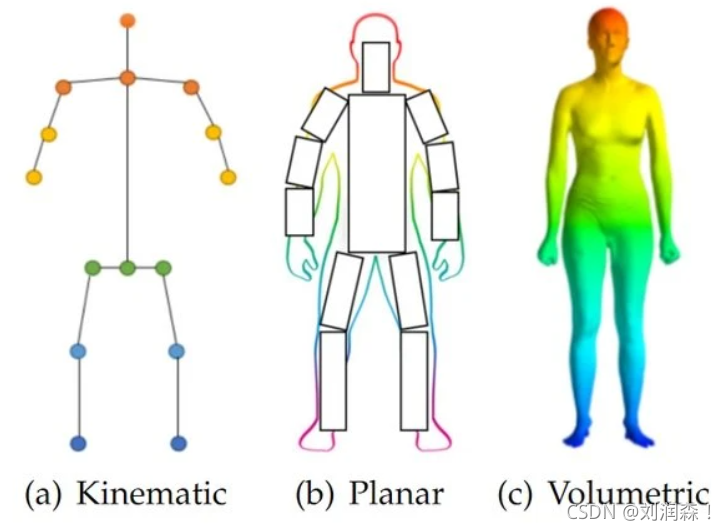
人体建模的模型分为三种:
-
Kinematic Model 运动学模型,也称为基于骨架的模型,用于 2D 姿态估计和 3D 姿态估计。这种灵活直观的人体模型包括一组关节位置和四肢方向来表示人体结构。因此,骨骼姿态估计模型用于捕捉不同身体部位之间的关系。然而,运动学模型在表示纹理或形状信息方面受到限制。
-
Planar Model 用于二维姿态估计的平面模型或基于轮廓的模型。平面模型用于表示人体的外观和形状。通常,身体部位由多个近似人体轮廓的矩形表示。一个流行的例子是活动形状模型(ASM),它使用主成分分析来捕获完整的人体图和轮廓变形。
-
Volumetric model 体积模型,用于 3D 姿态估计。存在多种流行的 3D 人体模型,用于基于深度学习的 3D 人体姿态估计以恢复 3D 人体网格。例如,著名的GHUM和 GHUML(ite) 是完全可训练的端到端深度学习管道,在超过 60,000 个人体配置的全身扫描高分辨率数据集上进行训练,以对统计的和铰接的 3D 人体形状进行建模和姿势。

姿势估计通过找到人或物体的关键点来操作。以一个人为例,关键点是肘部、膝盖、手腕等关节。姿势估计有两种类型:多姿势和单姿势。单姿态估计用于估计给定场景中单个物体的姿态,而多姿态估计用于检测多个物体的姿态。
流行的MS COCO 数据集上的人体姿态估计可以检测 17 个不同的关键点(类)。每个关键点都用三个数字 (x,y,v) 进行注释,其中 x 和 y 标记坐标,v 表示关键点是否可见。
"nose", "left_eye", "right_eye", "left_ear", "right_ear", "left_shoulder", "right_shoulder", "left_elbow", "right_elbow", "left_wrist", "right_wrist", "left_hip", "right_hip", "left_knee", "right_knee", "left_ankle", "right_ankle"
- 1

基于深度学习的姿态估计方法
由于姿态估计是一种易于应用的计算机视觉技术,我们可以使用现有架构实现自定义姿态估计器。帮助您开始开发自定义姿态估计器的现有架构包括:
-
HRNet:高分辨率网络 (HRNet)是一种用于人体姿态估计的神经网络。它是一种用于图像处理问题的体系结构,用于查找我们所知道的关于图像中特定对象或人的关键点(关节)。这种架构相对于其他架构的一个优点是,大多数现有方法将低分辨率表示中的姿势的高分辨率表示与使用高低分辨率网络相匹配。代替这种偏差,神经网络在估计姿势时保持高分辨率表示。例如,这种 HRNet 架构有助于检测电视体育赛事中的人体姿势。
-
OpenPose是最流行的自下而上的多人人体姿势估计方法之一。该架构具有实时、多人姿势估计的特点。OpenPose 是一个开源的实时多人检测,在检测身体、脚、手和面部关键点方面具有很高的准确性。OpenPose 的一个优点是它是一个 API,它使用户可以灵活地从摄像头字段、网络摄像头等中选择源图像,更重要的是对于嵌入式系统应用程序(例如,与 CCTV 摄像头和系统的集成)。它支持不同的硬件架构,例如 CUDA GPU、OpenCL GPU 或 CPU-only 设备。
-
DeepCut是另一种流行的自下而上的多人人体姿势估计方法。DeepCut 用于检测多人的姿势。该模型的工作原理是检测图像中的人数,然后预测每个图像的关节位置。DeepCut 可以应用于多人/物体的视频或图像,例如足球、篮球等区域多人姿势估计。
-
AlphaPose 是一种流行的自上而下的姿势估计方法。在存在不准确的人体边界框的情况下检测姿势很有用。也就是说,它是通过最佳检测边界框估计人体姿势的最佳架构。AlphaPose 架构适用于检测图像或视频领域中的单人和多人姿势。
-
DeepPose是一个利用深度神经网络的人体姿势估计器。DeepPose 的深度神经网络 (DNN) 捕获所有关节,铰接一个池化层、一个卷积层和一个全连接层以形成这些层的一部分。
-
PoseNet 是一种基于 tensorflow.js 的姿态估计器架构,可在浏览器或移动设备等轻量级设备上运行。因此,PoseNet可以被用来估计任何一个单个姿态或多个姿态。
-
DensePose是一种姿态估计技术,旨在将 RGB 图像的所有人体像素映射到人体的 3D 表面。DensePose 也可用于单个和多个姿态估计问题。
文章来源: maoli.blog.csdn.net,作者:刘润森!,版权归原作者所有,如需转载,请联系作者。
原文链接:maoli.blog.csdn.net/article/details/119970575

- 点赞
- 收藏
- 关注作者
评论(0)