如何使用Ascend的ATB加速库?

1 前言
Ascend Transformer Boost加速库(下文简称为ATB加速库)是一款高效、可靠的加速库,基于华为Ascend AI处理器,专门为Transformer类模型的训练和推理而设计。具体请阅读:ATB是什么?
那么程序猿小白如何实现一个ATB算子呢?
2 具体实现一个ATB算子
以下内容参考:
算子使用指导-加速库使用指导-Ascend Transformer Boost加速库-领域加速库开发-CANN商用版8.0.RC2.2开发文档-昇腾社区
实现一个ATB算子大概要有以下10个步骤,如下图所示。

step 1: 包含ACL与加速库接口头文件
#include <acl/acl.h>
#include <atb/atb_infer.h>
#include <atb/types.h>
#include <atb/utils.h>
#include "atb/infer_op_params.h"
这里要注意:
- 首先要安装atb相关的so文件,才能获取到相关头文件,保证程序链接不出错。
- 不同的算子,可能包含的头文件并不相同。
- 其它头文件,自定义添加
参考:
安装部署-Ascend Transformer Boost加速库-领域加速库开发-CANN商用版8.0.RC2.2开发文档-昇腾社区
step 2: 配置deviceId
uint32_t deviceId = 0;
aclError status = aclrtSetDevice(deviceId);
根据需求设置deviceId,如单机多卡,asecnd可用的deviceId为0-7(总共8张卡)。
step 3: 创建算子对象实例
从前文ATB是什么? ATB总共有3种算子实现,下文分别进行说明。
1、基础Operation(原生算子)
第一步:构造Operation参数
根据要创建的算子,实例化参数结构体,参数结构体的接口定义参考atb/infer_op_params.h和atb/train_op_params.h。
以Mul算子为例,Mul算子归属于Elewise,可通过以下方式构造对应参数:
atb::infer::ElewiseParam mulParam;
mulParam.elewiseType = atb::infer::ElewiseParam::ElewiseType::ELEWISE_MUL;
第二步:创建算子对象实例
atb::Operation *op = nullptr;
atb::Status st = atb::CreateOperation(mulParam, &op);
2、插件(Plugin)机制(插件算子)
插件算子需要是使用Ascend c或者其它方式实现kernel。
建议直接本文3.2章节。
参考:
第一步:开发算子
以使用Ascend C创建Add算子为例,用户可根据实际需求选择其他方式实现自定义算子。
参考如下:kernel_add.cpp
plugin_op_demo/kernel/kernel_add.cpp · Si1verBul1et623548/atb-op-demo - 码云 - 开源中国 (gitee.com)
第二步:创建算子对象实例
CustomOperation*op = new CustomOperation("CustomOperation");
3、Graph Frame(图算子)
图算子有配置TensorId和配置TensorName组图两种创建和使用方式。
根据如下图算子结构图:
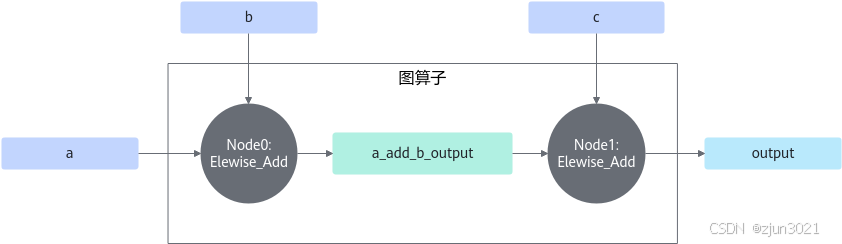
可以明确出,TensorId与TensorName对应关系配置如下:
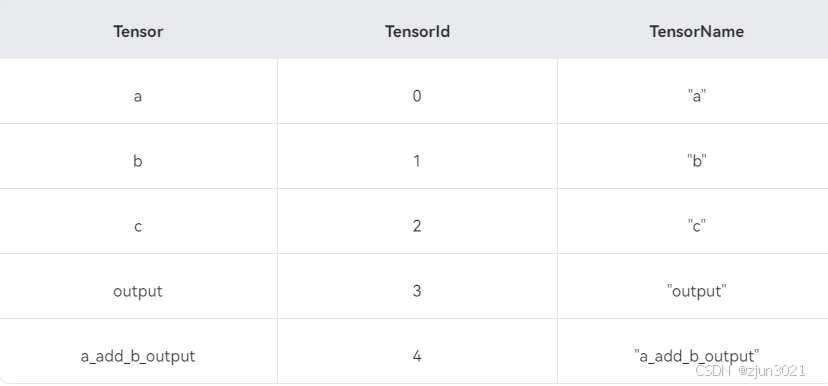
表1 TensorId与TensorName对应关系配置
组图方式1:配置TensorId
第一步:构造Operation参数
与单算子的参数不同,图算子的参数包含图节点、输入Tensor数、输出Tensor数、中间Tensor数等图相关的信息。
首先,根据设计的图算子结构,分别计算出图输入Tensor(假设为x个),图输出Tensor(假设为y个)以及图中间Tensor(假设为z个)的个数。 图输入Tensor的Id取值为[0, x - 1],图输出Tensor的Id取值为[x, x + y - 1],图中间Tensor的Id取值为[x + y, x + y + z - 1]。示例对应关系见表1Tensor与TensorId列。
然后,配置每一个节点的相关信息,包括创建好的单算子对象实例、输入Tensor和输出Tensor。该节点的输入和输出Tensor在图里可能是图的输入Tensor、输出Tensor或中间Tensor,用户需根据其所属的图Tensor类型,在合适的范围内取值。
实例中的op0和op1创建过程可参考单算子的创建。
atb::GraphParam graphParam;
graphParam.inTensorNum = 3; // 指定该图的输入Tensor数量
graphParam.outTensorNum = 1; // 指定该图的输出Tensor数量
graphParam.internalTensorNum = 1; // 指定该图的中间Tensor数量
graphParam.nodes.resize(2); // 指定该图中的节点数量,即包含的单算子数量
graphParam.nodes[0].operation = op0; // 指定该图中的节点0的单算子对象实例
graphParam.nodes[0].inTensorIds = {0, 1}; // 指定该图中的节点0需要的输入Tensor所对应的id
graphParam.nodes[0].outTensorIds = {4}; // 指定该图中的节点0输出的输出Tensor所对应的id
graphParam.nodes[1].operation = op1; // 指定该图中的节点1的单算子对象实例
graphParam.nodes[1].inTensorIds = {4, 2}; // 指定该图中的节点1需要的输入Tensor所对应的id
graphParam.nodes[1].outTensorIds = {3}; // 指定该图中的节点1输出的输出Tensor所对应的id
第二步:创建算子对象实例
atb::Operation *op = nullptr;
atb::Status st = atb::CreateOperation(graphParam, &op);
组图方式2:配置TensorId
使用TensorId组图需要提前定义,操作过程繁琐。该组图通过字符串定义每个Tensor,可行性更高。示例对应关系见上表1种Tensor与TensorName。
第一步:创建图算子构造器
atb::GraphOpBuilder* graphOpBuilder;
CreateGraphOpBuilder(&graphOpBuilder);
第二步:初始化图算子构造器
// lambda函数,通过图算子的输入TensorDesc推导输出TensorDesc,包括DataType、Format、Shape等
atb::InferShapeFunc inferShapeFunc = [=](const atb::SVector<atb::TensorDesc> &inTensorDescs, atb::SVector<atb::TensorDesc> &outTensorDescs) {
outTensorDescs.at(0) = inTensorDescs.at(0);
return atb::NO_ERROR;
};
graphOpBuilder->Init("DemoGraphOperation", inferShapeFunc, {"a", "b", "c"}, {"output"});
第三步:用图算子构造器构图
构图时可通过定义lambda函数对Tensor进行reshape,需保证reshape前后的shape大小一致。
op0等单算子的创建过程可参考上述单算子的创建。
graphOpBuilder->AddOperation(op0, {"a", "b"}, {"a_add_b_output"});
graphOpBuilder->AddOperation(op1, {"a_add_b_output", "c"}, {"output"});
第四步:用图算子构造器构图
atb::Operation *op = graphOpBuilder->Build(); // 使用时需判断op是否为空指针
DestroyGraphOpBuilder(graphOpBuilder); // 销毁图算子构造器
step 4: 创建输入输出tensor,并存入VariantPack
VariantPack中包含输入和输出Tensor列表。VariantPack中传入的每个输入Tensor要求大于0且不超过256GB。
// 设置各个intensor的属性
void CreateInTensorDescs(atb::SVector<atb::TensorDesc> &intensorDescs)
{
for (size_t i = 0; i < intensorDescs.size(); i++) {
intensorDescs.at(i).dtype = ACL_FLOAT16;
intensorDescs.at(i).format = ACL_FORMAT_ND;
intensorDescs.at(i).shape.dimNum = 2;
intensorDescs.at(i).shape.dims[0] = 2;
intensorDescs.at(i).shape.dims[1] = 2;
}
}
// 设置各个intensor并且为各个intensor分配内存空间,此处的intensor为手动设置,工程实现上可以使用torchTensor转换或者其他简单数据结构转换的方式
void CreateInTensors(atb::SVector<atb::Tensor> &inTensors, atb::SVector<atb::TensorDesc> &intensorDescs)
{
std::vector<char> zeroData(8, 0); // 一段全0的hostBuffer
for (size_t i = 0; i < inTensors.size(); i++) {
inTensors.at(i).desc = intensorDescs.at(i);
inTensors.at(i).dataSize = atb::Utils::GetTensorSize(inTensors.at(i));
int ret = aclrtMalloc(&inTensors.at(i).deviceData, inTensors.at(i).dataSize, ACL_MEM_MALLOC_HUGE_FIRST); // 分配NPU内存
if (ret != 0) {
std::cout << "alloc error!";
exit(0);
}
ret = aclrtMemcpy(inTensors.at(i).deviceData, inTensors.at(i).dataSize, zeroData.data(), zeroData.size(), ACL_MEMCPY_HOST_TO_DEVICE); //拷贝CPU内存到NPU侧
}
}
// 设置各个outtensor并且为outtensor分配内存空间,同intensor设置
void CreateOutTensors(atb::SVector<atb::Tensor> &outTensors, atb::SVector<atb::TensorDesc> &outtensorDescs)
{
for (size_t i = 0; i < outTensors.size(); i++) {
outTensors.at(i).desc = outtensorDescs.at(i);
outTensors.at(i).dataSize = atb::Utils::GetTensorSize(outTensors.at(i));
int ret = aclrtMalloc(&outTensors.at(i).deviceData, outTensors.at(i).dataSize, ACL_MEM_MALLOC_HUGE_FIRST);
if (ret != 0) {
std::cout << "alloc error!";
exit(0);
}
}
}
// 按上述方法构造所有输入和输出tensor,存入VariantPack
atb::VariantPack pack;
atb::SVector<atb::TensorDesc> intensorDescs;
atb::SVector<atb::TensorDesc> outtensorDescs;
uint32_t inTensorNum = op->GetInputNum();
uint32_t outTensorNum = op->GetOutputNum();
pack.inTensors.resize(inTensorNum);
intensorDescs.resize(inTensorNum);
CreateInTensorDescs(intensorDescs);
CreateInTensors(pack.inTensors, intensorDescs);
outtensorDescs.resize(outTensorNum);
pack.outTensors.resize(outTensorNum);
op->InferShape(intensorDescs, outtensorDescs);
CreateOutTensors(pack.outTensors, outtensorDescs);
step 5: 创建context,配置stream
Context主要负责对NPU中使用的Stream进行管理。
atb::Context *context = nullptr;
st = atb::CreateContext(&context);
aclrtStream stream = nullptr;
status = aclrtCreateStream(&stream);
context->SetExecuteStream(stream);
step 6: 调用Setup接口,计算workspace大小
uint64_t workspaceSize = 0;
st = op->Setup(pack, workspaceSize, context);
step 7: 根据workspace大小申请NPU内存
void *workspace = nullptr;
if (workspaceSize != 0) {
status = aclrtMalloc(&workspace, workspaceSize, ACL_MEM_MALLOC_HUGE_FIRST);
if (status != 0) {
std::cout << "alloc error!";
exit(0);
}
}
当workspace大小为0时,无需执行该步骤,否则会报错。
step 8: 调用Execute接口,执行算子
st = op->Execute(pack, (uint8_t *)workspace, workspaceSize, context);
step 9: 销毁创建的对象,释放内存
// 流同步,作用是等待device侧任务计算完成
auto ret = aclrtSynchronizeStream(stream);
if (ret != 0) {
std::cout << "sync error!";
exit(0);
}
status = aclrtDestroyStream(stream); // 销毁stream
st = atb::DestroyOperation(op); // 销毁op对象
st = atb::DestroyContext(context); // 销毁context
// 销毁输入tensor
for (size_t i = 0; i < pack.inTensors.size(); i++) {
aclrtFree(pack.inTensors.at(i).deviceData);
}
// 销毁输出tensor
for (size_t i = 0; i < pack.outTensors.size(); i++) {
aclrtFree(pack.outTensors.at(i).deviceData);
}
aclrtFree(pack.outTensors.at(0).deviceData); // 销毁输出tensor
status = aclrtFree(workspace); // 销毁workspace
aclrtResetDevice(deviceId); // 重置deviceId
step 10: demo运行
编译源文件:
# g++编译demo工程,demo.cpp为demo对应的源码文件
g++ -I "${ATB_HOME_PATH}/include" -I "${ASCEND_HOME_PATH}/include" -L "${ATB_HOME_PATH}/lib" -L "${ASCEND_HOME_PATH}/lib64" demo.cpp -l atb -l ascendcl -o demo
这里:
ATB_HOME_PATH:指的是atb库文件的安装路径。
执行:
./demo # 运行可执行文件
3 完整代码文件
由于博客字数限制,请参照
ATB 完整代码文件

- 点赞
- 收藏
- 关注作者
评论(0)