走进Java接口测试之从0到1搭建数据驱动框架(完结篇)

前言
在前面的几篇文章中,我们介绍了从需求到设计,再到部分功能实现,本篇作为完结篇,我们一起来完成剩下的功能实现,主要为日志管理和性能监控以及有同学提出测试用例多参数的问题。
- 走进Java接口测试之从0到1搭建数据驱动框架(需求篇)
- 走进Java接口测试之从0到1搭建数据驱动框架(设计篇)
- 走进Java接口测试之从0到1搭建数据驱动框架(用例管理)
- 走进Java接口测试之从0到1搭建数据驱动框架(多数据源和业务持久层)
日志管理
一个成熟的数据驱动框架,日志管理这个是必不可少的。在开发和调试阶段,日志可以帮助我们更快的定位问题;
SpringBoot 在所有内部日志中使用 Commons Logging,但是默认配置也提供了对常用日志的支持,如:Java Util Logging,Log4J, Log4J2 和 Logback。每种 Logger 都可以通过配置使用控制台或者文件输出日志内容。
LogBack 和 Log4j 都是开源日记工具库,而 LogBack 是 Log4j 的改良版本,比 Log4j 拥有更多的特性,同时也带来很大性能提升,同时天然支持SLF4J。
LogBack 官方建议配合 Slf4j 使用,这样可以灵活地替换底层日志框架。所以在此处我们选择了LogBack。
默认日志框架Logback
默认情况下,SpringBoot 会用 Logback 来记录日志,并用 INFO 级别输出到控制台。在运行应用程序和其他例子时,我们可以看到很多 INFO 级别的日志了。
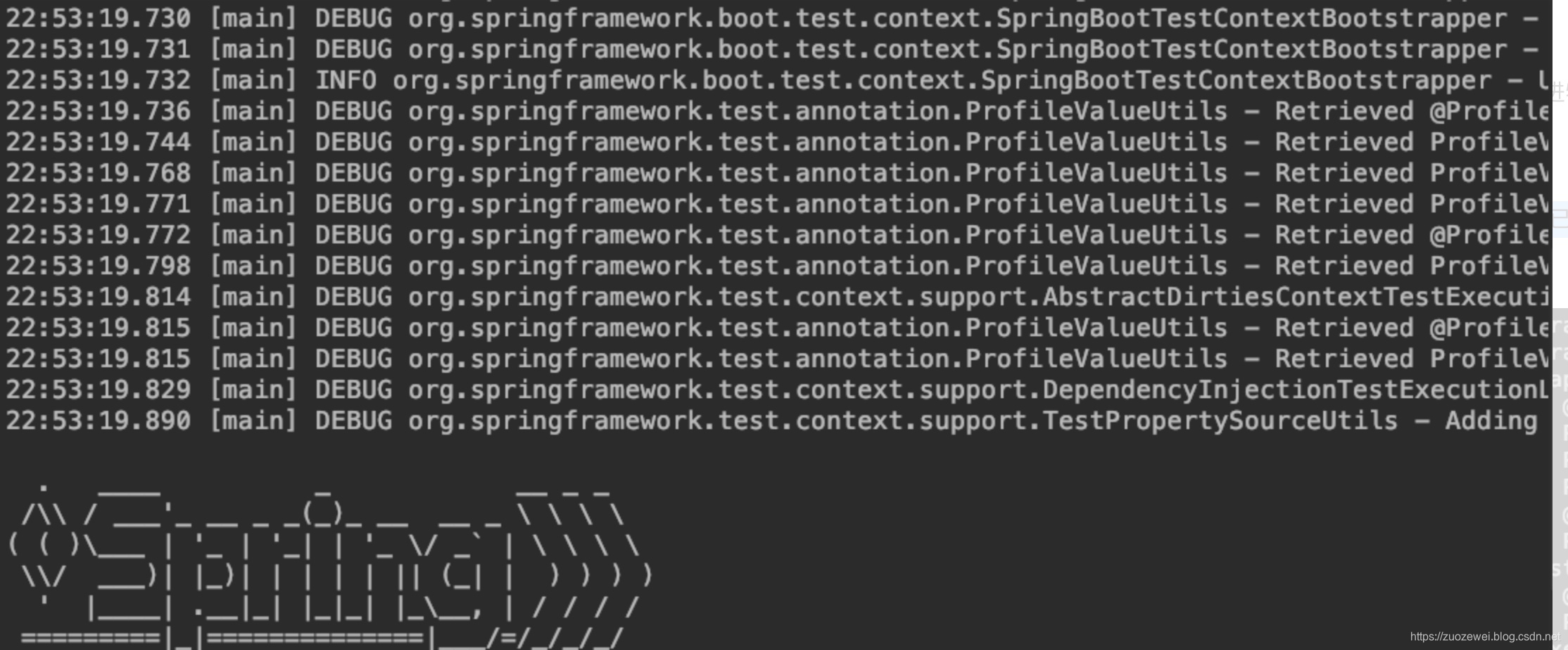
从上图可以看到,日志输出内容元素具体如下:
- 时间日期:精确到毫秒
- 日志级别:ERROR, WARN, INFO, DEBUG or TRACE
- Logger名:通常使用源代码的类名
- 分隔符:— 标识实际日志的开始
- 进程 ID
- 线程名:方括号括起来(可能会截断控制台输出)
- 日志内容
实际开发中我们不需要直接添加 Logback 依赖,因为 spring-boot-starter 其中包含了 spring-boot-starter-logging,该依赖内容就是 SpringBoot 默认的日志框架 logback。
<!--MyBatis、数据库驱动、数据库连接池、logback-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.1</version>
</dependency>
SpringBoot 官方推荐优先使用带有 -spring 的文件名作为你的日志配置(如使用logback-spring.xml,而不是 logback.xml ),命名为 logback-spring.xml 的日志配置文件,springboot 可以为它添加一些 springboot 特有的配置项(下面会提到)。并且放在 src/main/resources 下面即可。
添加配置文件 logback-spring.xml:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- 日志根目录-->
<springProperty scope="context" name="LOG_HOME" source="logging.path" defaultValue="./logs/spring-boot-logback"/>
<!-- 日志级别 -->
<springProperty scope="context" name="LOG_ROOT_LEVEL" source="logging.level.root" defaultValue="INFO"/>
<!-- 标识这个"STDOUT" 将会添加到这个logger -->
<springProperty scope="context" name="STDOUT" source="log.stdout" defaultValue="STDOUT"/>
<!-- 日志文件名称-->
<property name="LOG_PREFIX" value="api-test-logback" />
<!-- 日志文件编码-->
<property name="LOG_CHARSET" value="UTF-8" />
<!-- 日志文件路径+日期-->
<property name="LOG_DIR" value="${LOG_HOME}/%d{yyyyMMdd}" />
<!--对日志进行格式化-->
<property name="LOG_MSG" value="- | [%d{yyyyMMdd HH:mm:ss.SSS}] | [%level] | [${HOSTNAME}] | [%thread] | [%logger{36}] | --> %msg|%n "/>
<!--文件大小,默认10MB-->
<property name="MAX_FILE_SIZE" value="50MB" />
<!-- 配置日志的滚动时间 ,表示只保留最近 10 天的日志-->
<property name="MAX_HISTORY" value="10"/>
<!--输出到控制台-->
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<!-- 输出的日志内容格式化-->
<layout class="ch.qos.logback.classic.PatternLayout">
<pattern>${LOG_MSG}</pattern>
</layout>
</appender>
<!--输出到文件-->
<appender name="0" class="ch.qos.logback.core.rolling.RollingFileAppender">
</appender>
<!-- 定义 ALL 日志的输出方式:-->
<appender name="FILE_ALL" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!--日志文件路径,日志文件名称-->
<File>${LOG_HOME}/all_${LOG_PREFIX}.log</File>
<!-- 设置滚动策略,当天的日志大小超过 ${MAX_FILE_SIZE} 文件大小时候,新的内容写入新的文件, 默认10MB -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!--日志文件路径,新的 ALL 日志文件名称,“ i ” 是个变量 -->
<FileNamePattern>${LOG_DIR}/all_${LOG_PREFIX}%i.log</FileNamePattern>
<!-- 配置日志的滚动时间 ,表示只保留最近 10 天的日志-->
<MaxHistory>${MAX_HISTORY}</MaxHistory>
<!--当天的日志大小超过 ${MAX_FILE_SIZE} 文件大小时候,新的内容写入新的文件, 默认10MB-->
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>${MAX_FILE_SIZE}</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
</rollingPolicy>
<!-- 输出的日志内容格式化-->
<layout class="ch.qos.logback.classic.PatternLayout">
<pattern>${LOG_MSG}</pattern>
</layout>
</appender>
<!-- 定义 ERROR 日志的输出方式:-->
<appender name="FILE_ERROR" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 下面为配置只输出error级别的日志 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>ERROR</level>
<OnMismatch>DENY</OnMismatch>
<OnMatch>ACCEPT</OnMatch>
</filter>
<!--日志文件路径,日志文件名称-->
<File>${LOG_HOME}/err_${LOG_PREFIX}.log</File>
<!-- 设置滚动策略,当天的日志大小超过 ${MAX_FILE_SIZE} 文件大小时候,新的内容写入新的文件, 默认10MB -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!--日志文件路径,新的 ERR 日志文件名称,“ i ” 是个变量 -->
<FileNamePattern>${LOG_DIR}/err_${LOG_PREFIX}%i.log</FileNamePattern>
<!-- 配置日志的滚动时间 ,表示只保留最近 10 天的日志-->
<MaxHistory>${MAX_HISTORY}</MaxHistory>
<!--当天的日志大小超过 ${MAX_FILE_SIZE} 文件大小时候,新的内容写入新的文件, 默认10MB-->
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>${MAX_FILE_SIZE}</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
</rollingPolicy>
<!-- 输出的日志内容格式化-->
<layout class="ch.qos.logback.classic.PatternLayout">
<Pattern>${LOG_MSG}</Pattern>
</layout>
</appender>
<!-- additivity 设为false,则logger内容不附加至root ,配置以配置包下的所有类的日志的打印,级别是 ERROR-->
<logger name="org.springframework" level="ERROR" />
<logger name="org.apache.commons" level="ERROR" />
<logger name="org.apache.zookeeper" level="ERROR" />
<logger name="com.alibaba.dubbo.monitor" level="ERROR"/>
<logger name="com.alibaba.dubbo.remoting" level="ERROR" />
<!-- ${LOG_ROOT_LEVEL} 日志级别 -->
<root level="${LOG_ROOT_LEVEL}">
<!-- 标识这个"${STDOUT}"将会添加到这个logger -->
<appender-ref ref="${STDOUT}"/>
<!-- FILE_ALL 日志输出添加到 logger -->
<appender-ref ref="FILE_ALL"/>
<!-- FILE_ERROR 日志输出添加到 logger -->
<appender-ref ref="FILE_ERROR"/>
</root>
</configuration>
配置文件 application.yml:
logging:
file:
path: ./logs # 日志文件路径
日志会每天新建一个文件夹,日文文件配置的每 50 M,一个文本文件,超过新写入一个:
文件夹:20191130
文件夹内容:all_api-test-logback0.log
文件夹内容:all_api-test-logback1.log
文件夹内容:all_api-test-logback2.log
文件夹内容:err_api-test-logback0.log
多环境日志输出
根据不同环境(prod:生产环境,test:测试环境,dev:开发环境)来定义不同的日志输出,在 logback-spring.xml中使用 springProfile 节点来定义,方法如下:
文件名称不是 logback.xml,想使用 spring 扩展 profile 支持,要以 logback-spring.xml 命名
<!-- 生产环境生效 -->
<springProfile name="prod">
<root level="error">
<appender-ref ref="STDOUT" />
<appender-ref ref="FILE" />
</root>
</springProfile>
<!-- 测试和开发环境日志级别为INFO/并且记录日志文件 -->
<springProfile name="dev,test">
<!-- 日志输出级别 -->
<root level="INFO">
<appender-ref ref="STDOUT" />
<appender-ref ref="FILE" />
</root>
</springProfile>
然后跑测时,maven 命令加入参数 -P 命令即可指定相应的环境资源,比如: -Ptest,则会替换 test 环境下的参数值。
mvn clean install -DskipTests -Ptest
到此为止终于介绍完集成 Logback 日志框架了,平时使用的时候推荐用自定义 logback-spring.xml 来配置,代码中使用日志也很简单,可以使用 lombok 效率插件配合 @Slf4j注解快捷使用。
性能监控
而在测试的运维过程中,日志系统又可以帮助我们记录大部分的异常信息。通常很多测试框架会通过收集日志信息来对接口测试状态进行实时监控预警,比如慢SQL。所以我们选择了一款强大的连接池Druid和小巧的工具 p6spy。
Druid
Druid 是一个关系型数据库连接池,它是阿里巴巴的一个开源项目。Druid 支持所有 JDBC 兼容数据库,包括了Oracle、MySQL、PostgreSQL、SQL Server、H2等。
Druid 在监控、可扩展性、稳定性和性能方面具有明显的优势。通过 Druid 提供的监控功能,可以实时观察数据库连接池和SQL查询的工作情况。使用 Druid 连接池在一定程度上可以提高数据访问效率。
首先需要引入依赖包:
<!-- 数据库连接池druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
application.yml 启用配置:
spring:
datasource:
dynamic:
primary: mysql # 设置默认的数据源或者数据源组,默认值即为 master
strict: false # 设置严格模式,默认 false 不启动. 启动后在未匹配到指定数据源时候回抛出异常,不启动会使用默认数据源.
druid:
filters: config,stat,slf4j # 配置监控统计拦截的filter,注意这个值和 druid 原生不一致,默认启动了stat,wall
stat:
enabled: true
log-slow-sql: true # 开启慢sql日志
slow-sql-millis: 100 # 慢sql时间
max-wait: 3 # 最大连接等待时间
max-active: 5 # 最大连接池数量
min-idle: 2 # 最小连接池数量
validationQuery: SELECT 1
testWhileIdle: true # 申请连接的时候检测,如果空闲时间大于 timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效
testOnBorrow: true # 申请连接时执行validationQuery检测连接是否有效
testOnReturn: true # 归还连接时执行validationQuery检测连接是否有效
poolPreparedStatements: false
maxPoolPreparedStatementPerConnectionSize: 200
# druid: # 以下是全局默认值,可以全局更改
# initial-size:
# max-active:
# min-idle:
# max-wait:
# time-between-eviction-runs-millis:
# time-between-log-stats-millis:
# stat-sqlmax-size:
# min-evictable-idle-time-millis:
# max-evictable-idle-time-millis:
# test-while-idle:
# test-on-borrow:
# test-on-return:
# validation-query:
# validation-query-timeout:
# use-global-datasource-stat:
# async-init:
# clear-filters-enable:
# reset-stat-enable:
# not-full-timeout-retry-count:
# max-wait-thread-count:
# fail-fast:
# phyTimeout-millis:
# keep-alive:
# pool-prepared-statements:
# init-variants:
# init-global-variants:
# use-unfair-lock:
# kill-when-socket-read-timeout:
# connection-properties:
# max-pool-prepared-statement-per-connection-size:
# init-connection-sqls:
# share-prepared-statements:
# connection-errorretry-attempts:
# break-after-acquire-failure:
# filters: stat,wall
logging:
level:
com.baomidou: debug
org.springframework.jdbc.datasource.init: debug
此处只是简单演示如何使用,详细介绍可以参考官方资料。
P6Spy
p6spy 是一个开源项目,通常使用它来跟踪数据库操作,查看程序运行过程中执行的sql语句。
p6sy大部分人最常用的功能就是格式化你的sql语句。
# 如在使用 mybatis 的过程中,原生输出的语句是带?号的。在需要复制到其他地方执行看效果的时候很不方便。
select * from user where age>?
# 在使用了 p6sy 后,其会帮你格式化成真正的执行语句。
select * from user where age>6
引入依赖包:
<!--p6spy-->
<dependency>
<artifactId>p6spy</artifactId>
<groupId>p6spy</groupId>
<version>3.8.0</version>
</dependency>
启用配置:
spring:
datasource:
dynamic:
p6spy: true # 默认false,建议线上关闭。
引入相关配置文件。
在 classPath 下创建 spy.properties:
# 一个最简单配置,定义slf4j日志输出。 更多参数请自行了解。
appender=com.p6spy.engine.spy.appender.Slf4JLogger
# 日期格式
dateformat=yyyy-MM-dd HH:mm:ss
编写测试用例
在此一并解决之前某个同学提出如何解决测试用例多个参数的问题,即在测试用例表中存放json map 格式的参数。
多参数据构造
这里还是演示一个参数,
{"Parameters":"latte"}
如果有多个参考,再添加一个键值对即可:
{"Parameters1":"latte1","Parameters2":"latte2"}
解析参数
即然参数是 json 格式,那么我在取参数的时候需要解析。此处我们使用阿里开源的 fastjson 解析库。
首先需要引包:
<!--引入 fastjson 序列化库-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
编写一个解析FastJson工具类,FastJsonUtils:
/***
* 解析为字符串
*
* @param jsonString json字符串
* @param key 关键字
* @return 返回值
*/
public static String fromString(String jsonString, String key) {
try {
if (jsonString != null && jsonString.length() > 0) {
JSONObject jsonObject = JSONObject.parseObject(jsonString);
return jsonObject.getString(key);
} else {
return null;
}
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
这时候我们的测试用例逻辑如下:
@Test(dataProvider = "testData",description = "测试demo")
public void testSelect(Map<String, String> data) throws InterruptedException {
// 参数取值
String parameters = FastJsonUtils.fromString(data.get("Parameters"),"Parameters");
// 封装查询条件
CoffeeExample example = new CoffeeExample();
//创建一个 Criteria,来拼装查询条件
example.createCriteria().andNameEqualTo(parameters);
// 查询数据
List<Coffee> list = coffeeService.selectCoffeeFromDs(example);
// 循环打印
list.forEach(e -> log.info("selectByExample: {}", e));
// 筛选指定属性
List<Money> moneys = list.stream().map(Coffee::getPrice).collect(Collectors.toList());
log.info( moneys.get(0).toString() );
// 断言结果
Assert.assertEquals(data.get("expected"),moneys.get(0).toString());
}
注意这里需要了解 mybatis Example条件查询。
mybatis 的逆向工程中会生成实例及实例对应的 example,example 用于添加条件,相当where 后面的部分
xxxExample example = new xxxExample();
Criteria criteria = new Example().createCriteria();
criteria.andXxxEqualTo(value),表示添加 xxx 字段等于 value 条件。
执行 jdbcAPI-TestSuite.xml ,我们可以查看测试结果。

- | [20191210 22:19:59.328] | [DEBUG] | [DESKTOP-MLD0KTS] | [main] | [c.b.d.d.DynamicRoutingDataSource] | --> dynamic-datasource switch to the datasource named [h2]|
- | [20191210 22:19:59.338] | [INFO] | [DESKTOP-MLD0KTS] | [main] | [p6spy] | --> 2019-12-10 22:19:59|0|statement|connection 1|url |select ID, NAME, PRICE, CREATE_TIME, UPDATE_TIME from T_COFFEE WHERE ( NAME = ? )|select ID, NAME, PRICE, CREATE_TIME, UPDATE_TIME from T_COFFEE WHERE ( NAME = 'latte' )|
- | [20191210 22:19:59.356] | [INFO] | [DESKTOP-MLD0KTS] | [main] | [c.z.s.demo.TestMapperService] | --> selectByExample: Coffee [Hash = 1963590892, id=2, name=latte, price=CNY 25.00, createTime=Tue Dec 10 22:19:58 CST 2019, updateTime=Tue Dec 10 22:19:58 CST 2019]|
- | [20191210 22:19:59.356] | [INFO] | [DESKTOP-MLD0KTS] | [main] | [c.z.s.demo.TestMapperService] | --> CNY 25.00|
注意日志中的 [p6spy] 行会打印程序执行的 sql 语句。
慢SQL测试
环境准备
- 操作系统:window/linux
- 数据库: MySQL 5.7
数据准备
在 mysql_2 数据库创建一个测试表:
CREATE TABLE emp
(empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '编号',
ename VARCHAR(20) NOT NULL DEFAULT "" COMMENT '名字',
job VARCHAR(9) NOT NULL DEFAULT "" COMMENT '工作',
mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '上级编号',
hiredate DATE NOT NULL COMMENT '入职时间',
sal DECIMAL(7,2) NOT NULL COMMENT '薪水',
comm DECIMAL(7,2) NOT NULL COMMENT '红利',
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '部门编号'
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
构建一个存储函数,这个存储函数会返回一个长度为参数 n 的随机字符串
delimiter $$
create function rand_string(n INT)
returns varchar(255) #该函数会返回一个字符串
begin
declare chars_str varchar(100) default 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
while i < n do
set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i = i + 1;
end while;
return return_str;
end $$
delimiter ;
接下来我们再创建一个存储函数,该存储函数会返回一个随机 int 值
delimiter $$
create function rand_num( )
returns int(5)
begin
declare i int default 0;
set i = floor(10+rand()*500);
return i;
end $$
delimiter ;
然后我们利用刚刚创建的两个存储函数创建一个存储过程,该存储过程包含一个参数,该参数表示插入数据表 emp 的数据条数
delimiter $$
create procedure insert_emp(in max_num int(10))
begin
declare i int default 0;
set autocommit = 0;
repeat
set i = i + 1;
insert into emp values (i ,rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand_num());
until i = max_num
end repeat;
commit;
end $$
delimiter ;
我们调用创建的存储过程,对 emp 表插入 1000w 条数据
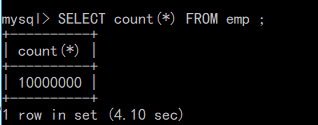
call insert_emp(10000000);
统计表数据:
现在我们运行一个查询时间超过 1s 的查询语句:

慢查询测试
在 TestDataMapper.xml 中新增:
<!-- 自定义SQL语句2 -->
<select id="selectBySlowsql" parameterType="String" resultType="java.util.LinkedHashMap">
${value};
</select>
编辑 TestDataMapper 新增 Dao 接口:
// 自定义sql查询2
List<LinkedHashMap<String, Object>> selectBySlowsql(String sql);
编辑 TestDataService,新建 Service 接口:
// 自定义查询2
List<LinkedHashMap<String, Object>> selectBySlowsql(String sql);
编辑 TestDataServiceImpl类,实现 Service 接口,并指定数据源:
@DS("mysql_2")
@Override
public List<LinkedHashMap<String, Object>> selectBySlowsql(String sql) {
return testDataMapper.selectBySlowsql(sql);
}
编写测试方法:
@Test
public void testTestData() {
String sqlString = "SELECT * FROM emp WHERE empno = 403345;";
//调用
List<LinkedHashMap<String, Object>> names = testDataService.selectBySlowsql(sqlString);
names.forEach(name -> log.info("selectBySlowsql: {}", name));
执行测试如下:

- | [20191210 22:19:59.360] | [DEBUG] | [DESKTOP-MLD0KTS] | [main] | [c.b.d.d.DynamicRoutingDataSource] | --> dynamic-datasource switch to the datasource named [mysql_2]|
- | [20191210 22:20:05.058] | [ERROR] | [DESKTOP-MLD0KTS] | [main] | [c.a.druid.filter.stat.StatFilter] | --> slow sql 5684 millis. SELECT * FROM emp WHERE empno = 403345;;[]|
- | [20191210 22:20:05.059] | [INFO] | [DESKTOP-MLD0KTS] | [main] | [p6spy] | --> 2019-12-10 22:20:05|5685|statement|connection 2|url |SELECT * FROM emp WHERE empno = 403345;;|SELECT * FROM emp WHERE empno = 403345;;|
- | [20191210 22:20:05.062] | [INFO] | [DESKTOP-MLD0KTS] | [main] | [c.z.s.demo.TestMapperService] | --> selectBySlowsql: {empno=403345, ename=RbJamf, job=SALESMAN, mgr=1, hiredate=2018-09-13, sal=2000.00, comm=400.00, deptno=428}|
注意 [ERROR] 行已经打印出慢sql记录,执行时间:5685毫秒
slow sql 5684 millis. SELECT * FROM emp WHERE empno = 403345;;[]|
全部代码骨架结构
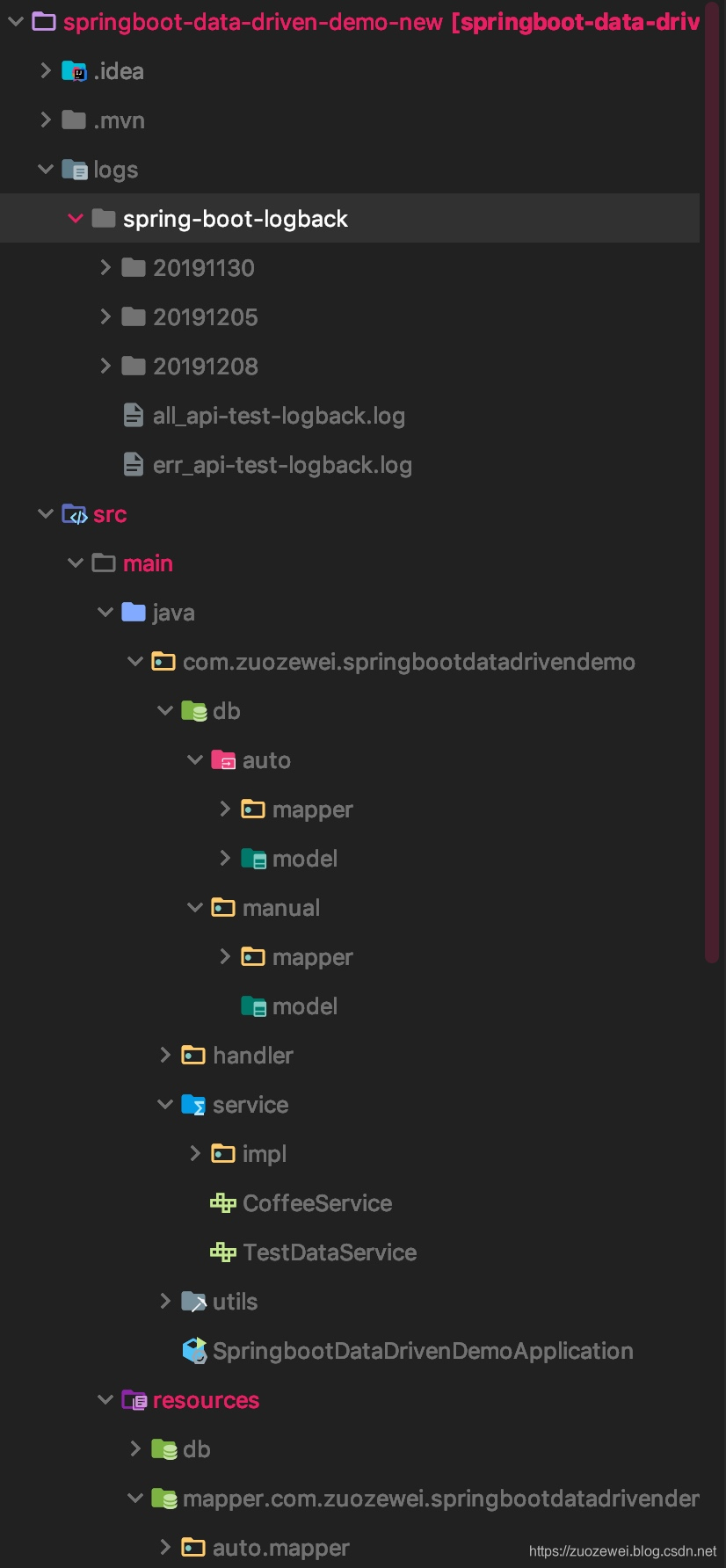
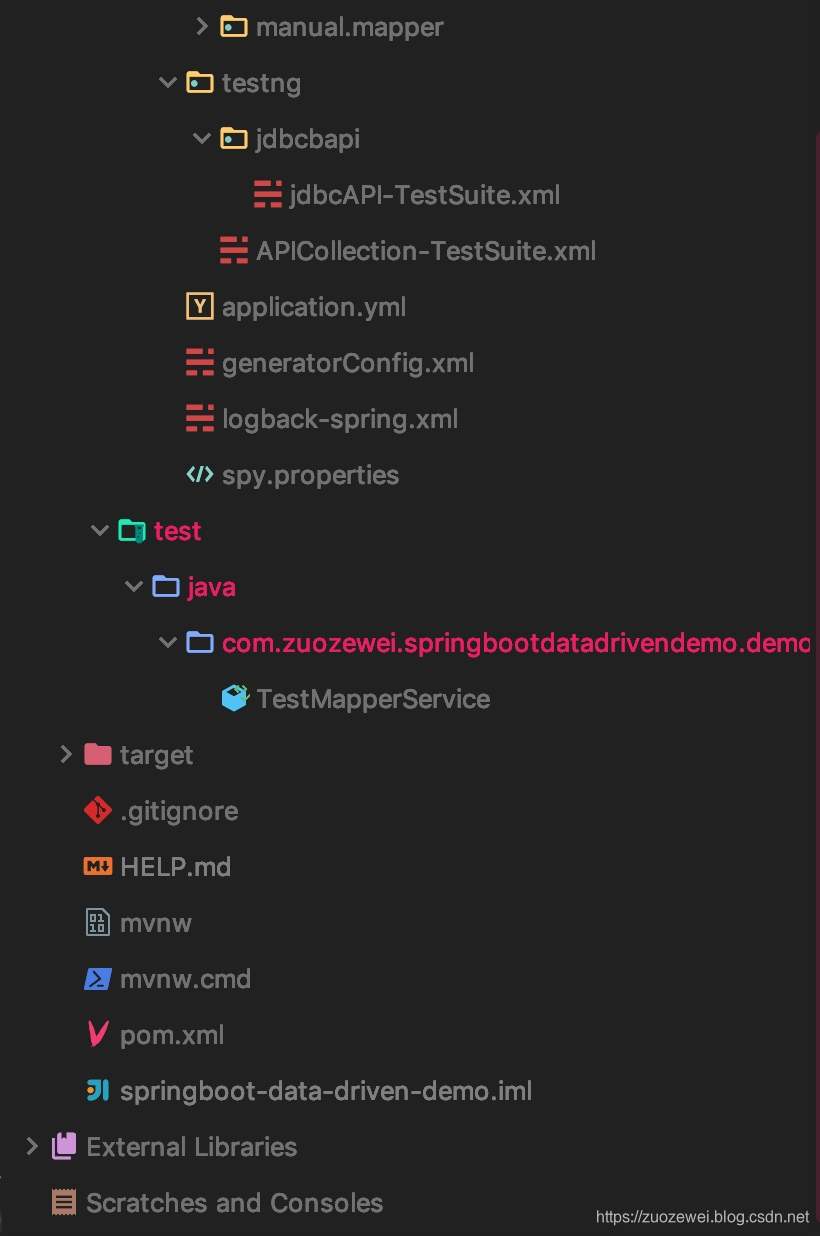
├─logs
│ └─spring-boot-logback # 日志文件
│ all_api-test-logback.log # 所有日志
│ err_api-test-logback.log # 错误日志
├─src
│ ├─main
│ │ ├─java
│ │ │ └─com
│ │ │ └─zuozewei
│ │ │ └─springbootdatadrivendemo
│ │ │ │ SpringbootDataDrivenDemoApplication.java # 启动类
│ │ │ │
│ │ │ ├─db
│ │ │ │ ├─auto # 存放MyBatis Generator生成器生成的数据层代码,可以随时删除再生成
│ │ │ │ │ ├─mapper # DAO 接口
│ │ │ │ │ └─model # Entity 实体
│ │ │ │ └─manual # 存放自定义的数据层代码,包括对MyBatis Generator自动生成代码的扩展
│ │ │ │ ├─mapper # DAO 接口
│ │ │ │ └─model # Entity 实体
│ │ │ ├─handler # 数据转换
│ │ │ └─service # 业务逻辑
│ │ │ └─impl # 实现类
│ │ │ └─utils # 工具类
│ │ │
│ │ └─resources
│ │ │ application.yml # 全局配置文件
│ │ │ generatorConfig.xml # Mybatis Generator 配置文件
│ │ │ logback-spring.xml # logback 配置文件
│ │ │ spy.properties # P6Spy 配置文件
│ │ │
│ │ ├─db
│ │ ├─mapper
│ │ │ └─com
│ │ │ └─zuozewei
│ │ │ └─springbootdatadrivendemo
│ │ │ └─db
│ │ │ ├─auto # 存放MyBatis Generator生成器生成的数据层代码,可以随时删除再生成
│ │ │ │ └─mapper # 数据库 Mapping 文件
│ │ │ │
│ │ │ └─manual # 存放自定义的数据层代码,包括对MyBatis Generator自动生成代码的扩展
│ │ │ └─mapper # 数据库 Mapping 文件
│ │ └─testng
│ │ │ APICollection-TestSuite.xml # 所用测试用例集
│ │ └─jdbcbapi
│ │ jdbcAPI-TestSuite.xml # 某API测试用例集
│ │
│ └─test
│ └─java
│ └─com
│ └─zuozewei
│ └─springbootdatadrivendemo
│ └─demo # 接口测试用例
├─pom.xml
小结
在今天这篇文章中,主要和大家分享了实现日志管理和性能监控的过程,另外也回复之前某同学提出的用例多参数的问题。在实现过程中,你最需要关注的几部分内容是:
- 基于
Druid和P6spy跟踪sql语句和打印慢sql; - 使用
logback搭建日志框架; - 实现用例 json 多参数取值。
希望对你能有所启发。
框架源码:

- 点赞
- 收藏
- 关注作者
评论(0)