走进Java接口测试之从0到1搭建数据驱动框架(需求篇)

前言
一个 “好的” 数据驱动框架,需要从“时间”、“人力”、“收益”这三个方面出发,做好“取舍”。
不能由于被测业务系统发生一些变更,就导致花费了几个小时的脚本无法执行。同时,我们需要看到“收益”,不能为了总想看到100%的成功,而减少必须做的工作,这导致可能都需要进行大量的维护。
所以做好这三个方面的平衡并不容易,想要提高 ROI(投入产出比),我们必须从两方面入手:
- 减少开发成本。
- 增加使用便利度。
针对“减少开发成本”,我们需要做到:
- 减少持久层开发的成本。尽可能的减少开发、维护的时间,尽可能使用公司已有的,或是业界成熟的工具或组件;
- 减少用例录入成本。简化测试用例录入的方式,做到脚本和测试数据解耦,如果可以开发一些批量生成测试数据工具;
- 减少用例维护成本。减少用例维护成本,尽量只用在参数上做简单的变更即可完成维护动作,而不是进行大量的代码操作。
针对“增加使用便利度”,我们需要做到:
- 手工测试也能用,不需要进行接口用例逻辑开发,也可以准备测试数据;
- 在开发和调试阶段,可以帮助我们更快的定位问题;
- 在测试的运维过程中,可以帮助我们记录大部分的异常信息;
- 支持对数据库测试状态进行实时监控预警。
所以,我这边开发了一个数据驱动框架,来实现我对数据驱动想法的一些实践。
二、目前遇到的痛点
1、测试用例管理
这里不提倡把测试用例直接硬编码写在 Java 文件中,因为这样做会带来很多问题:
- 修改测试用例需要改动大量的代码;
- 代码也不便于交接给其他同学,因为每个人都有自己的编码风格和用例设计风格,这样交接,最后都会变成由下一个同学全部推翻重写一遍;
- 如果测试框架更换,无法做用例数据的迁移,只能手动介入,效率很低。
所以 “测试数据” 与 “脚本” 分离是非常有必要的。
网上很多的范例是使用的 Excel 进行的数据驱动,而我这里推荐使用关系型数据库 MySQL,为什么呢?
一般我们的脚本和代码都是提交至公司的 GitLab 仓库,如果使用 Excel 很显然不方便日常经常修改测试用例的情况,因为我们需要做到版本控制,集中式管理。使用 MySQL 就没有这样的烦恼了,由于数据与脚本的分离,只需对数据进行修改即可,脚本每次会在数据库中读取最新的用例数据进行测试。同时,还可以防止一些操作代码时的误操作。
多业务数据源
作为一个测试开发工程师,自动化接口测试经常要连 N个数据源。对于多数据源,网上提供了重写:
数据据库这边的配置:
mybatis.config-location=classpath:mybatis/mybatis-config.xml
spring.datasource.test1.jdbc-url=jdbc:mysql://localhost:3306/test1?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true
spring.datasource.test1.username=root
spring.datasource.test1.password=root
spring.datasource.test1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.test2.jdbc-url=jdbc:mysql://localhost:3306/test2?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true
spring.datasource.test2.username=root
spring.datasource.test2.password=root
spring.datasource.test2.driver-class-name=com.mysql.cj.jdbc.Driver
一个 test1 库和一个 test2 库,其中 test1 位主库,在使用的过程中必须指定主库,不然会报错:
@Configuration
@MapperScan(basePackages = "com.zuozewei.mapper.test1", sqlSessionTemplateRef = "test1SqlSessionTemplate")
public class DataSource1Config {
@Bean(name = "test1DataSource")
@ConfigurationProperties(prefix = "spring.datasource.test1")
@Primary
public DataSource testDataSource() {
return DataSourceBuilder.create().build();
}
@Bean(name = "test1SqlSessionFactory")
@Primary
public SqlSessionFactory testSqlSessionFactory(@Qualifier("test1DataSource") DataSource dataSource) throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(dataSource);
bean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath:mybatis/mapper/test1/*.xml"));
return bean.getObject();
}
@Bean(name = "test1TransactionManager")
@Primary
public DataSourceTransactionManager testTransactionManager(@Qualifier("test1DataSource") DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
@Bean(name = "test1SqlSessionTemplate")
@Primary
public SqlSessionTemplate testSqlSessionTemplate(@Qualifier("test1SqlSessionFactory") SqlSessionFactory sqlSessionFactory) throws Exception {
return new SqlSessionTemplate(sqlSessionFactory);
}
}
一层一层注入,首先创建 DataSource,然后创建 SqlSessionFactory 再创建事务,最后包装到 SqlSessionTemplate 中。其中需要指定分库的 mapper 文件地址,以及分库dao层代码:
@MapperScan(basePackages = "com.zuozewei.mapper.test1", sqlSessionTemplateRef = "test1SqlSessionTemplate")
这块的注解就是指明了扫描 dao 层,并且给 dao 层注入指定的 SqlSessionTemplate。所有 @Bean 都需要按照命名指定正确。dao 层和 xml 需要按照库来分在不同的目录,比如:test1 库 dao 层在 com.zuozewei.mapper.test1 包下,test2 库在com.zuozewei.mapper.test2。
这个方式,确实可用,不足在于,需要根据不同数据源建立不同的 package,一旦数据源发生变更,需要更改所在的 package。也看过了动态数据源,那也不是我们想要的。
持久层开发
在使用 Mybatis 的时候,Dao 接口,Entity 实体类,还有每个实体类对应的 xml 都得自己写,这其实也是工作量很大的事情,维护起来也很费劲。
日志管理
一个成熟的接口测试框架,日志管理这个是必不可少的。在开发和调试阶段,日志可以帮助我们更快的定位问题;而在测试的运维过程中,日志系统又可以帮助我们记录大部分的异常信息,通常很多测试框架会通过收集日志信息来对接口测试状态进行实时监控预警,比如慢SQL。
主流技术栈
主要考虑以下几个方面:
- 开发更简单;
- 测试更简单;
- 配置更简单;
- 部署更简单;
- 基于主流的框架;
- 具备市场竞争能力。
主要功能
所以,总结以上的需求,我画了一个图:
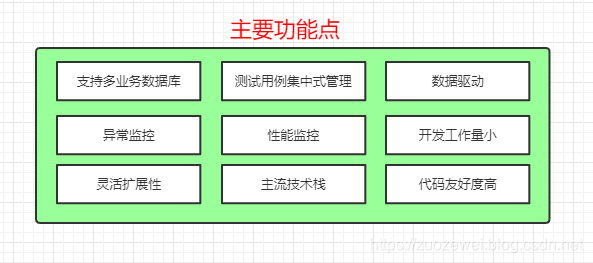
功能描述
- 灵活支持多业务数据源;
- 测试用例集中式管理,结构化数据;
- 数据驱动做到脚本与测试数据解耦;
- 丰富的日志管理功能,支持异常监控,便于开发调试;
- 支持性能监控,比如业务数据源的慢SQL;
- 开发的便利性,能节省重复工作,降低开发成本;
- 灵活的扩展性,满足自定义的数据类型;
- 主流的技术栈,能跟上互联网技术节奏,不易于快速被淘汰;
- 友好的代码结构及注释,便于阅读及二次开发。
小结
本文总结了数据驱动框架中一些常见的痛点和一些必备的功能,这决定后续我们的框架如何去设计,希望对你能有所启发。
参考资料:
- [1]:Lego-美团接口自动化测试实践
- [2]:在Mybatis-spring上基于注解的数据源实现方案

- 点赞
- 收藏
- 关注作者
评论(0)