[论文阅读] (03) 清华张超老师 - Fuzzing漏洞挖掘详细总结 GreyOne

Discover Vulnerabilities with Flow Sensitive Fuzzing
Chao Zhang
清华大学
2nd International Workshop on Cyber Security and Data Privacy

《秀璋带你读论文》系列主要是督促自己阅读优秀论文及听取学术讲座,并分享给大家,希望您喜欢。由于作者的英文水平和学术能力不高,需要不断提升,所以还请大家批评指正,非常欢迎大家给我留言评论,学术路上期待与您前行,加油~
张超老师是我非常佩服的一位青年教师, 清华大学副教授(博导),蓝莲花战队教练,我也听了好几次他的讲座,受益匪浅。他主要研究软件和系统安全,尤其是智能攻防方向,在国际四大安全会议发表论文十余篇。在自动攻防研究方面,提出的漏洞挖掘方案发现300多个未知漏洞,多次参加DARPA CGC、微软BlueHat、Defcon CTF防夺旗赛等比赛并获奖。作者主要分享他的两次报告,第一篇是学术论文相关的“数据流敏感的漏洞挖掘方法”,第二篇是安全攻防实战相关的“智能软件漏洞攻防”。这些大佬是真的值得我们去学习,献上小弟的膝盖~fighting!
PS:顺便问一句,你们喜欢这种方式的分享吗?担心效果不好,如果不好我就不分享和总结类似的会议知识了,欢迎评论给我留言。
文章目录
前文赏析:
- [论文阅读] (01) 拿什么来拯救我的拖延症?初学者如何提升编程兴趣及LATEX入门详解
- [论文阅读] (02) SP2019-Neural Cleanse: 神经网络中的后门攻击识别与缓解
- [论文阅读] (03) 清华张超老师 - Fuzzing漏洞挖掘详细总结 GreyOne
演讲题目: 数据流敏感的漏洞挖掘方法
内容摘要: 模糊测试近年来成为安全研究人员的必备的漏洞挖掘工具,是近年来漏洞披露数量爆发的重要推手。然而,模糊测试工具在种子生成、选择、变异、测试、评估、反馈等多个环节都存在一定的盲目性和随机性,其漏洞挖掘效率存在较大提升空间。我们通过分析经典模糊测试工具AFL的实现原理,找到了若干个制约其效率的瓶颈所在,包括数据流不敏感等,并针对性地提出了改进方案GreyOne(USENIX Sec’20)。本次报告将与大家探讨这一方案。
漏洞大家都很熟悉了,是各大安全问题的根源。如下图所示的Stuxnet震网、WannaCry、心脏滴血等等。

我们在漏洞挖掘和攻防方面做了大量的研究,有人打的CTF,也有机器全自动的漏洞挖掘、攻击防御、二进制程序分析、CGC比赛等。下图是Blue-Lotus(清华蓝莲花)战队这些年的成绩。


我的研究主题是漏洞挖掘和攻击防御,今天的分享主要是我们在 漏洞挖掘(Vulnerability Discovery) 方面最近的工作,它是关于Fuzzing的一个工作,Fuzzing目前可能是漏洞挖掘最主流的方法。
漏洞挖掘发展几十年,前面有很多技术被提出来,大家最熟悉的应该是代码审计、逆向工程(无源码),它们仍然是企业发现漏洞的常用渠道;学术界提出的包括静态分析、动态分析、污点分析、符号执行等方法,这些技术或多或少都局限,没有最近流行的Fuzzing技术有效。
- Code Review(10%)
- Static Analysis
- Dynamic Analysis
- Taint Analysis
- Symbolic Execution
- Model Checking
- Fuzzing(80%)
Fuzzing也不是新技术,它是在90年的时候被提出来,已经有30年历史,但它真正大的发展是2013年以后,最近几年有个大的发展。它的基本思路如下图所示,它是一个动态测试的过程,需要想办法生成一大堆输入,扔给程序测试,如果测试过程中出现问题就可能有BUG,如果没有问题就接着测试,和软件工程中的测试流程类似。
- Goal:Finding PoC samples that prove vulnerabilities
- Solution:testing
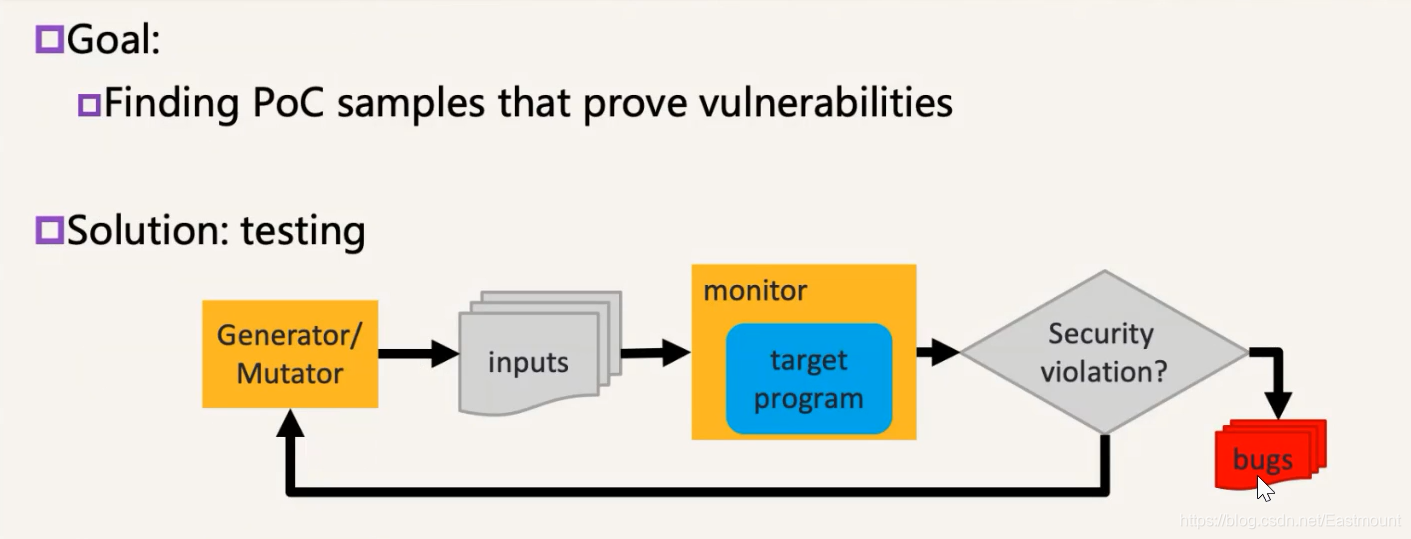
整个过程的核心是怎样有效地生成输入去触发Bugs,因为对于程序来说,它输入空间是个无限的空间,能够触发漏洞是非常少的。那么,怎样在无限空间中有效找到少量能触发漏洞的输入,这是它的核心问题。
90年左右提出Fuzzing的问题基本是偏随机输入的,后面又提出方法告诉输入的格式,然后基于格式去生成,但相对来说它挖漏洞的效率仍然很低,让人去写这个输入格式工程量也比较大。
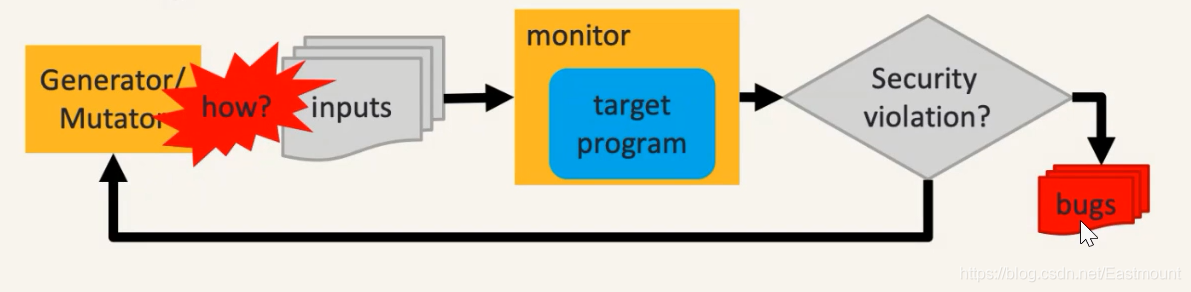
2013年以后,有一个叫AFL的重要方案被提出,这个方案有一个很重要的算法就是遗传算法,它把遗传算法放进来了。
- A better strategy: Genetic Algorithm
- Iterative testing,keep GOOD seeds, report bugs
我们刚才说到Fuzzing的核心是在无穷多个输入空间中去找有限的输入,去触发漏洞,那怎么在无穷空间中去有限探索呢?它用到了遗传算法。下图中间的核心循环,通过一轮一轮的迭代测试,测试过程中它会把上一轮测试比较好的测试用例留下来,作为种子进入下一轮,下一轮是在上一轮比较好的种子基础上进一步变异测试。它在无穷空间中探索时,不是盲目的去探索,而是在上一轮探索基础上去找比较好的方向,接着再这个方向上往下探索。该方法还是比较有效的。
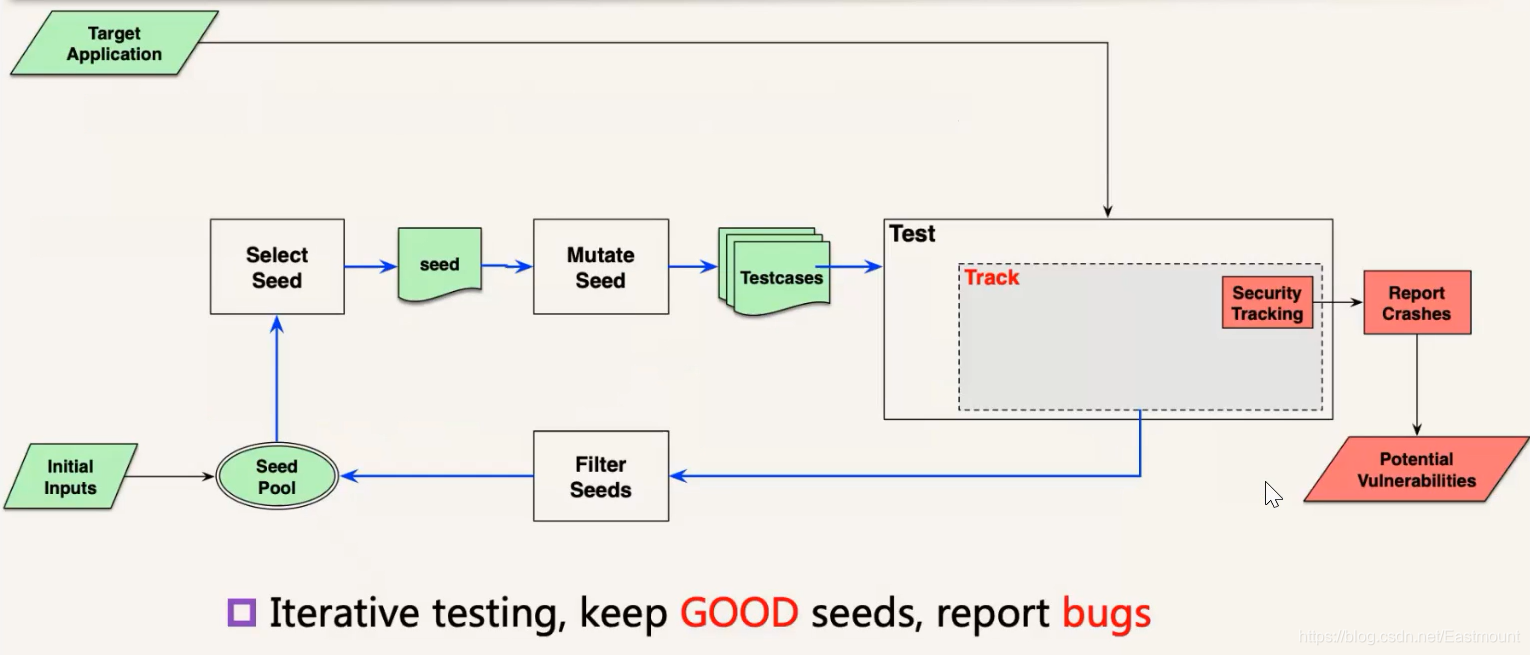
具体分析,每轮测试保留好的测试例。那么,什么是好的测试例呢?这里有一个进化指标,这个进化指标也非常重要。我们目标是挖漏洞,很自然就有一个指标是漏洞数量,但是用漏洞数量作为指标来进化的效果很差,因为漏洞是个非常稀疏的,你可能挖了几个小时都没挖到一个漏洞。这意味着没有进化的信号,整个算法效果就很差。
- 漏洞数量
2013年AFL工作使用的指标是代码覆盖率,测试工程中去监控程序的代码覆盖率情况,如果一个新的测试例提升了代码覆盖率,就认为它是好的种子就保留下来。通过这种方式就能不断提升代码覆盖率。
- GOOD:coverage increases
- Bug:sanitizers
代码覆盖率与漏洞有一定相关性,我们知道要触发漏洞的话肯定要走存在漏洞的那条路径,去触发代码,如果没走过那段代码,那个漏洞肯定不会触发。它们之间是有个关联性的,我们通过这种遗传算法不断提高代码覆盖率,它就有一定概率去发现代码中隐藏的漏洞,整体效果也不错。
为了支持做覆盖率跟踪以及在测试过程中发现代码漏洞是否被触发,通常会对程序进行插桩,做代码覆盖率收集和Security Sanitizers(安全检测工具),插桩完成之后在测试过程中,程序会自动收集Coverage信息以及检测是否触发安全问题。
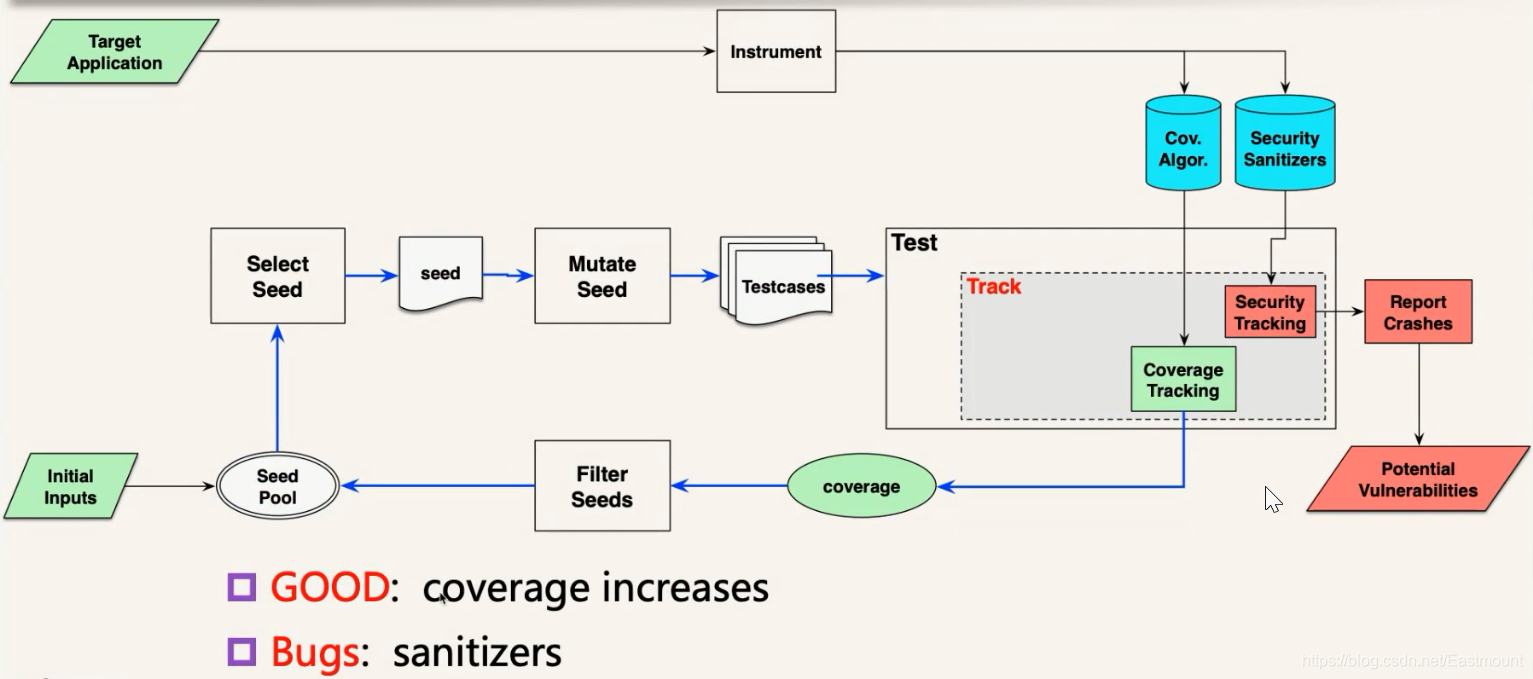
A pioneer:AFL
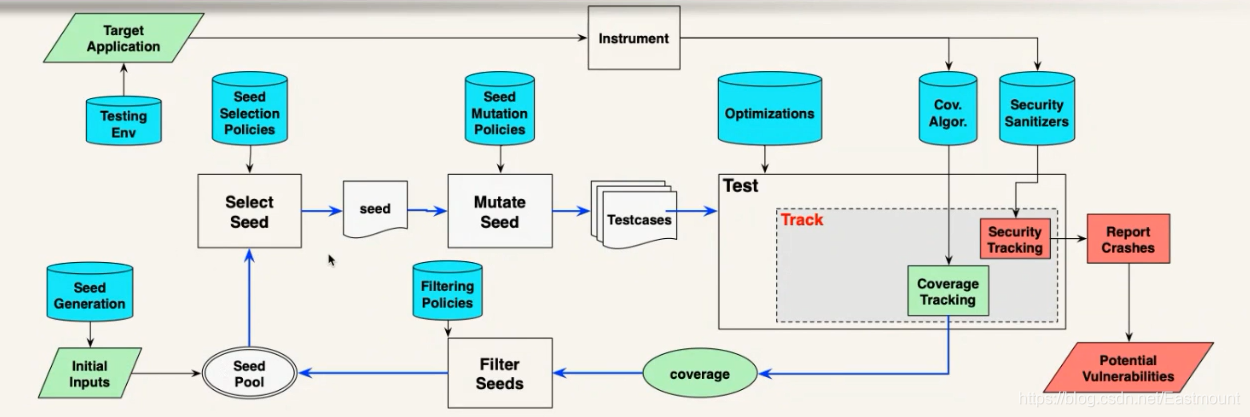
下图是真正AFL的框架,真正的AFL会在过程中每一步都有一些策略,比如怎么选种子(Select Seed)、怎么变异(Mutate Seed)、变异后怎么测试(Test)、测试过程中怎么跟踪覆盖率(Coverage Tracking)、覆盖率怎么过滤保留新的种子(Filter Seeds)等等。该算法提出来之后非常有效,改变了大家在这块的研究。AFL的重要特点如下:
- Evolving:filter out only GOOD samples contributing to code coverage
遗传算法是个进化的特征。 - Scalable:mutation-based, few knowledge required
方案是可量化的,不需要知道目标软件太多的知识,给它一个软件就能测。 - Fast:fork-server, persistent, parallel
测试过程非常快,一秒钟平均能测上千个测试用例。 - Sensitive: support different sanitizers to catch security violations
捕获漏洞能力比较强,可以支持不同的Sanitizers,也可以扩展,比较有名的是谷歌写的AddressSanitizer,常用安全防护和漏洞挖掘。这个非常重要,有时候在测试过程中触发漏洞但程序并不一定会让崩溃,一个好的Sanitizers能够在程序未崩溃的情况下发现漏洞。
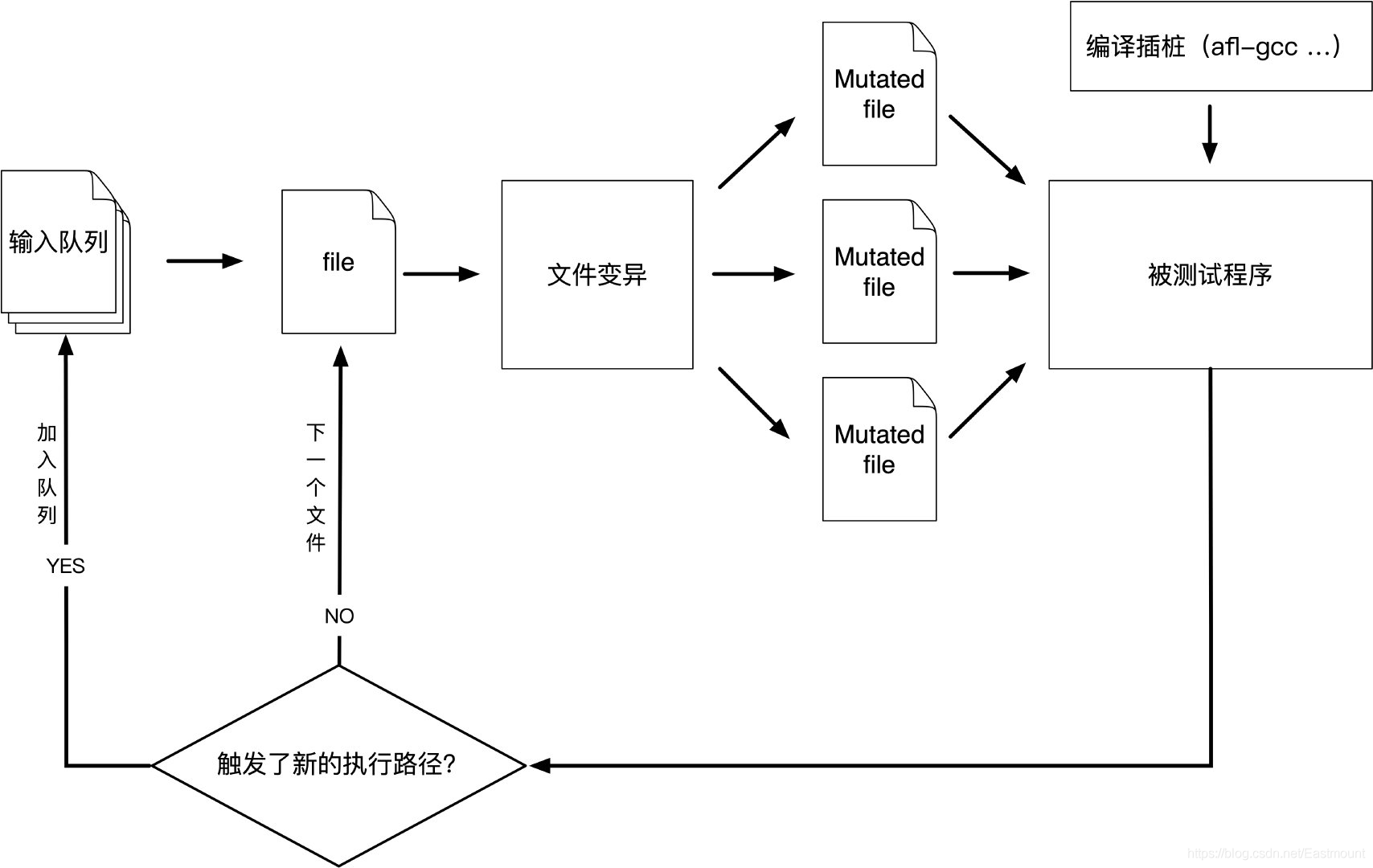
AFL(American Fuzzy Lop)是由安全研究员Michał Zalewski(@lcamtuf)开发的一款基于覆盖引导(Coverage-guided)的模糊测试工具,它通过记录输入样本的代码覆盖率,从而调整输入样本以提高覆盖率,增加发现漏洞的概率。其工作流程大致如下:
- ①从源码编译程序时进行插桩,以记录代码覆盖率(Code Coverage);
- ②选择一些输入文件,作为初始测试集加入输入队列(queue);
- ③将队列中的文件按一定的策略进行“突变”;
- ④如果经过变异文件更新了覆盖范围,则将其保留添加到队列中;
- ⑤上述过程会一直循环进行,期间触发了crash的文件会被记录下来。
参考alphalab文章:AFL漏洞挖掘技术漫谈(一):用AFL开始你的第一次Fuzzing
所以,在整个流程中这些环节都可以去改进。这些年四大安全会议关于Fuzzing的论文大概有60~70篇,数量非常大,我们简单介绍下。
安全四大顶会:
- CCS(ACM Conference on Computer and Communications Security)
网址:https://www.sigsac.org/ccs.html - NDSS(Network and Distributed System Security Symposium)
网址:https://www.ndss-symposium.org/ - Oakland S&P(IEEE Symposium on Security & Privacy)
网址:https://www.ieee-security.org/TC/SP-Index.html - USENIX Security(USENIX Security Symposium)
网址:https://www.usenix.org/
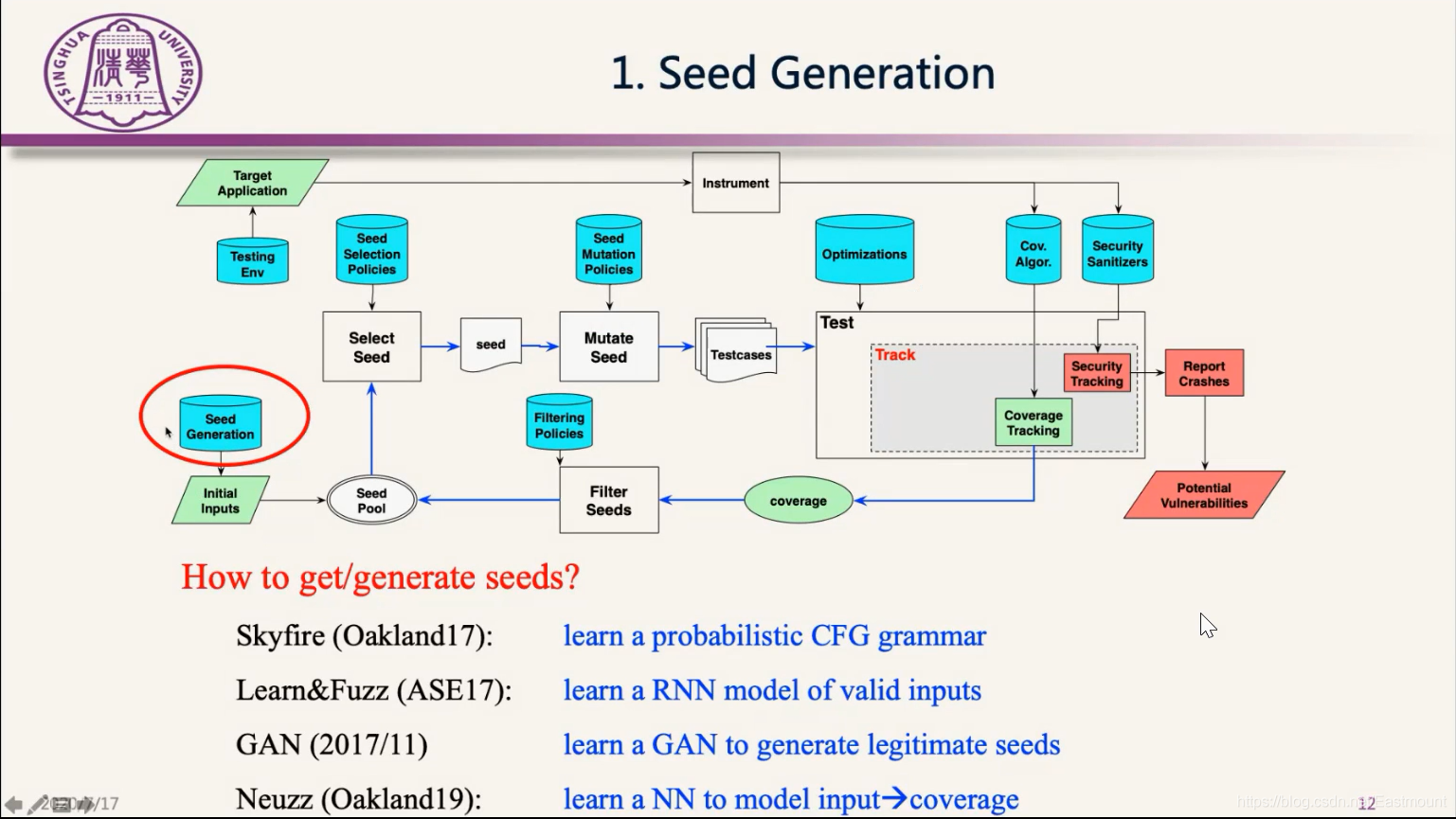
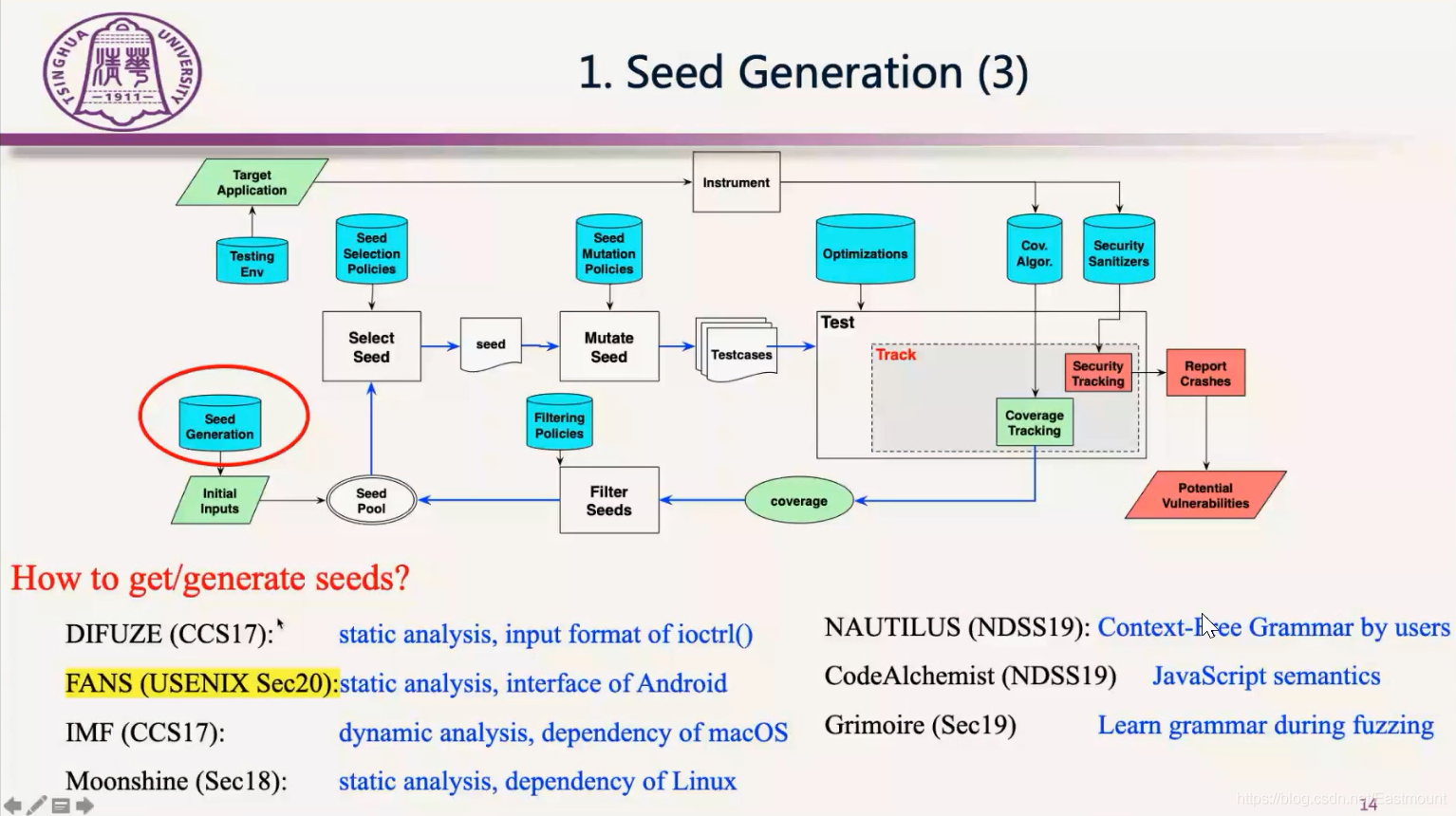
第一块是初始种子,它对Fuzzing的效率还是有很大影响的。如果你不给初始种子,它也会去测试,但是其效率比较低,很多学者去研究如何给一个好的初始种子,让Fuzzing更快地进入状态,更好地找到漏洞。
实践中怎么找到初始种子呢?可以从网上去爬取一些PDF文件作为初始种子,或者从网上找一些历史上的POC。而学术界的方法如下:
How to get/generate seeds?
- 第一种是借用AI的方法
基本思路是从程序的合法输入,网上爬取样本中学出一个模型,再用这个模型生成新的测试例,这样构造的初始种子相对来说更好。典型论文方法包括Skyfire、Learn&Fuzz、GAN、Neuzz等。
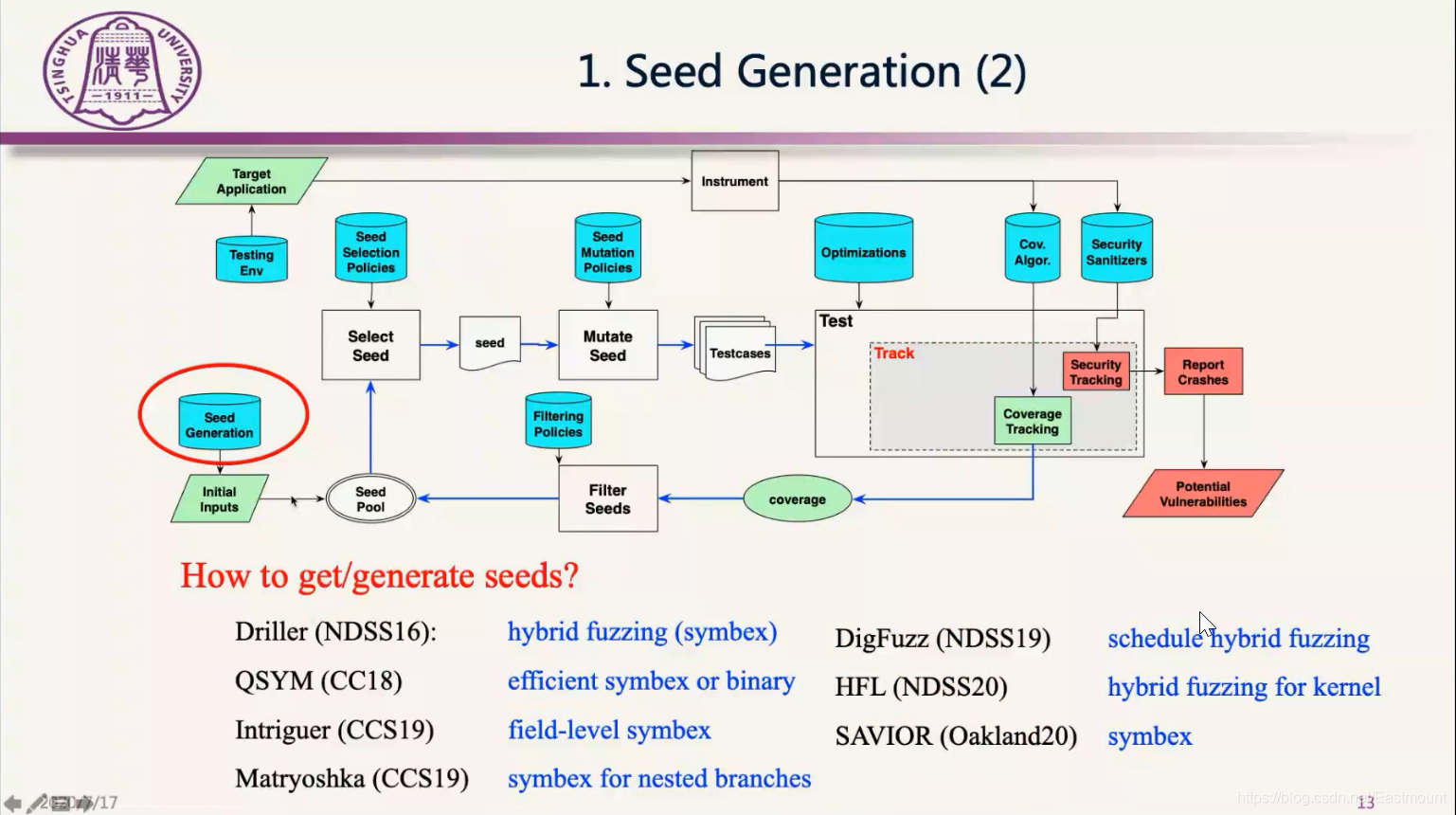
- 第二种是通过符号执行(Symbolic Execution)来辅助
这种辅助手段一般称为混合Fuzzing,其基本思路的核心还是Fuzzing来做,但Fuzzing有些代码过不去,比如一个复杂的数组检查,Fuzzing很难通过。对于这些过不去的分支,Drillers就提出用符号执行来辅助,遇到分支过不去的情况用符号执行来求解,并生成新的种子再丢给Fuzzing去通过分支,这是当时他们做CGC比赛的方案。符号执行和Fuzzing混合确实能提升过不去的分支。最近几年有进一步改进符号执行和Fuzzing的经典方法,比如QSYM、DigFuzz、HFL等。
- 第三种是基于静态分析和动态分析的
还有一些是基于静态分析、动态分析,以及去学习输入的规范,通过程序分析的技术手段去分析程序接受什么样的输入,再去指导测试例的生成。今年张老师他们有一篇针对Android服务的工作,也是这个思路,即FANS(USENIX Sec20)。
上面介绍的是采用不同角度,有AI、符号执行,传统静态分析、动态分析来辅助识别或者生成初始种子的。还有一部分是针对不同测试目标的工作,包括针对二进制程序的,针对内核程序的,针对JAVA、IoT、SDN的,还有虚拟机、手机驱动、文件系统、数据库、智能音响等等。
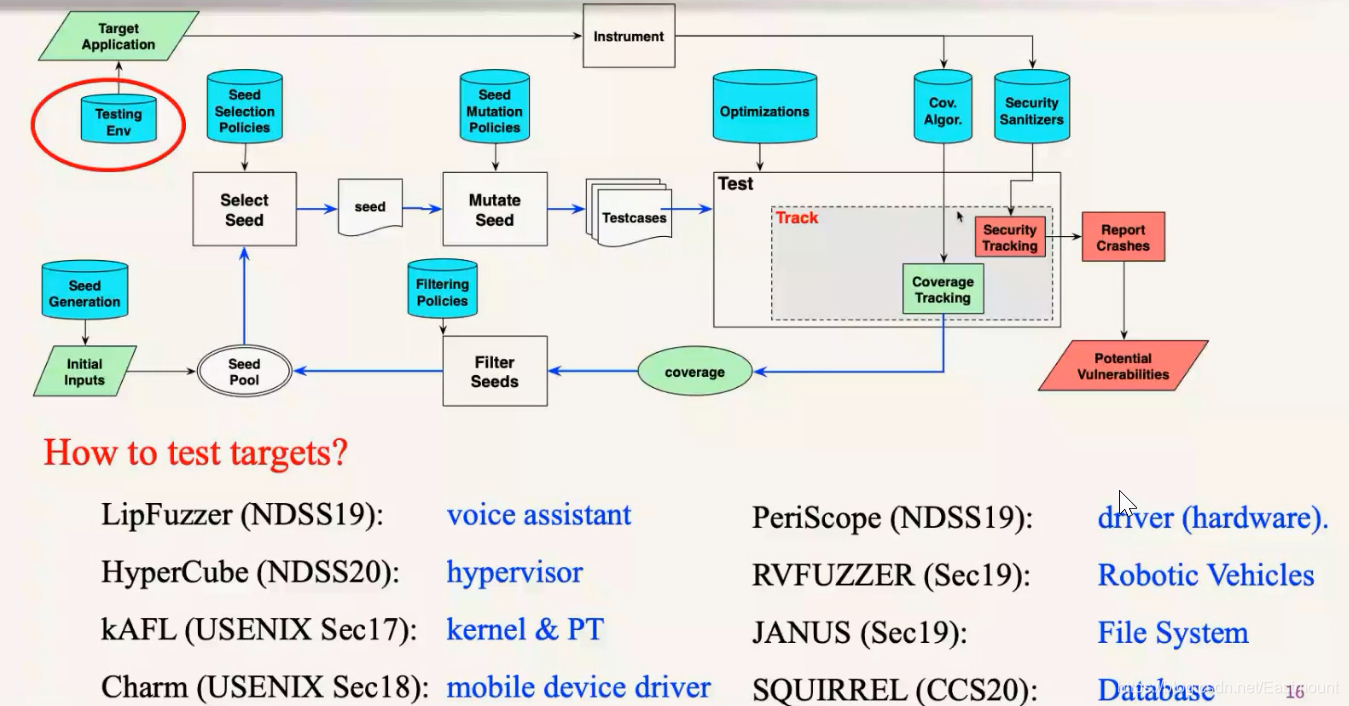
针对不同的目标做Fuzzing,它其实会存在很大的差异。一个重要原因是这些目标很难有个较好的动态测试环境,测试环境有个要求是尽量在测试过程中做一些跟踪,而很多目标可能不适合做跟踪,所以需要解决这个问题。针对不同测试目标也是有很多工作的。
How to test targets?
在遗传算法每轮的迭代中,它首先需要从现有的种子池(Seed Pool)中选择种子,该步骤也是有一些策略的。因为一个种子池中可能积累了很多种子,通过历史上不断测试留下来的,但每一轮可能只选择一个种子,而先选择哪一个的效率也是不一样的,虽然大家都是种子,但可能有些种子效率更好。
2016年发表在CCS上的AFLfast的策略是如果这个种子在之前测试中很少被选出来,就称为cold,这样的种子后面优先被选出来,或者这个种子搜索的路径在之前的测试中很少被测到,也会优先选择这个种子。还有其他的一些策略,比如VUzzer、AFLgo、QTEP等等,包括张老师他们2018年Oakland提出的CollAFL,这些策略其实没有哪一个是绝对的最好,各有千秋。
How to select seed from the pool?

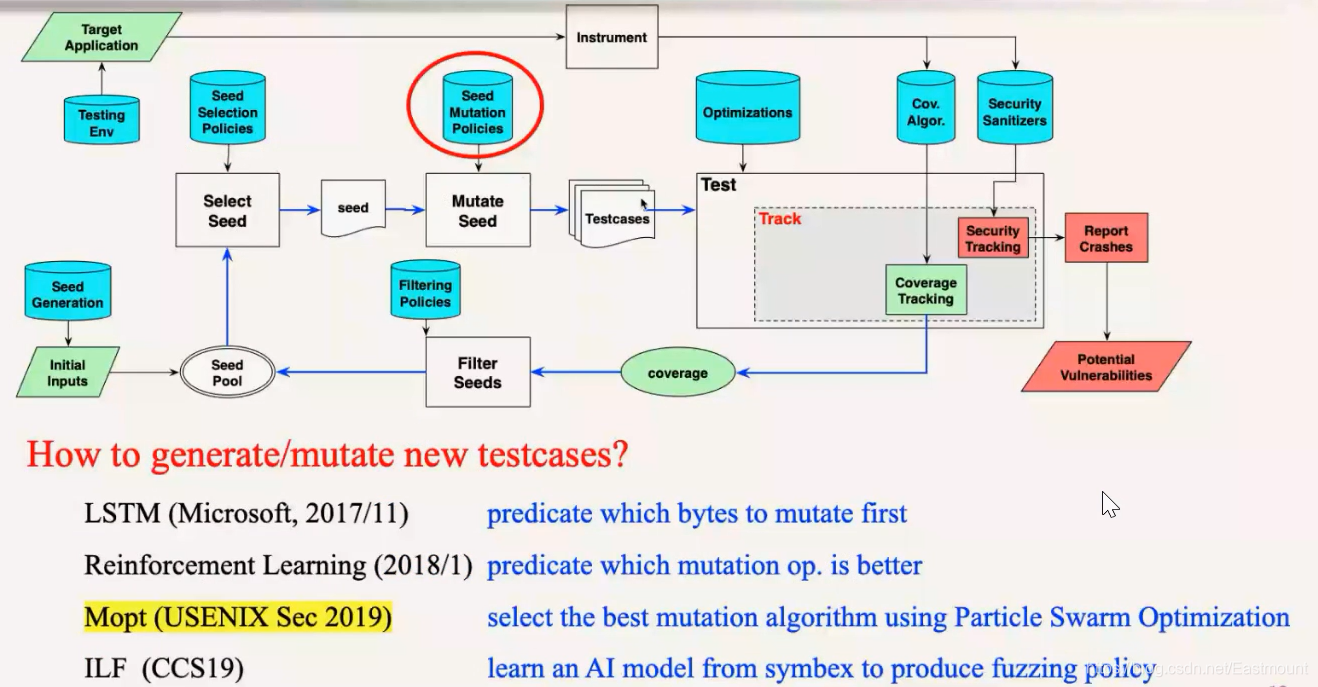
选好种子之后,接下来是做变异,在这个种子基础上变异生成一堆测试用例,AFL的做法是随机选择一些字节,对其进行增删改,做一些操作,但这个随机没法保证质量。这块就有一些工作尝试改进。
How to generate/mutate new testcases?
- 第一种是偏AI的方法
比如2017、2018年有尝试用AI来指导(LSTM、强化学习),去年张老师他们在USENIX Sec上有一篇Mopt,通过粒子群优化算法来选择最优的变异策略。同时CCS上有一篇ILF也是通过AI方法,先用符号执行去生成数据并作为训练数据,再通过AI模型来指导它变异,该工作适合于智能合约和区块链上。
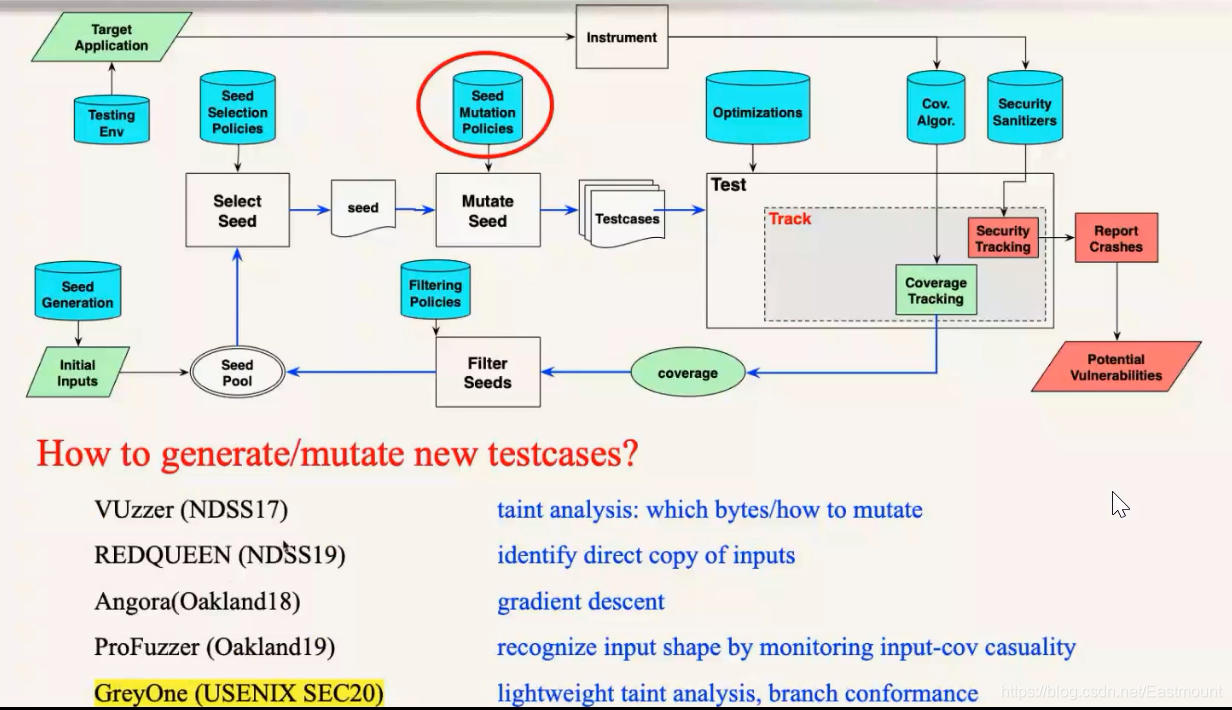
- 第二种偏程序分析的方法
这些方法是通过程序分析的方法,经典的是2017年发表在NDSS的VUzzer,它通过污点分析来判断应该对哪些字节进行变异,以及怎么变异。后面还有一些通过符号执行、梯度下降,2019年Oakland人大一位老师的做法也非常有意思,它通过测试去观测测试的表现,来推断输入字段的划分及类型,基于字段类型来指导怎么变异。我们今天要分享的是USENIX SeC20的GreyOne,也是关于变异的工作。
编译好之后,就是测试工作(Optimizations)。测试过程中,第一个很重要的问题是性能,测得非常快,漏洞挖掘工具也会很强。这里有一些并行化、硬件辅助的工作。
How to efficiently test target application?
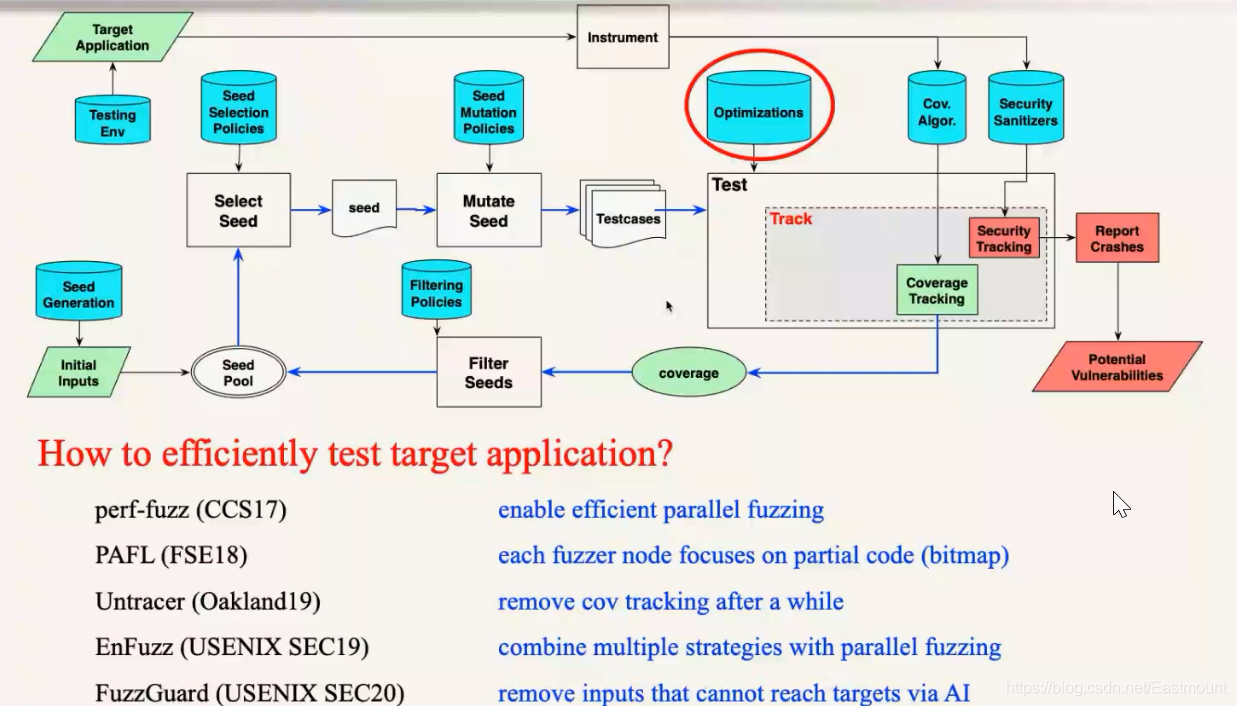
下面一类工作是测试过程中需要跟踪代码覆盖率、安全等属性,代码覆盖率相对来说工作比较少,我们2018年关注的是代码覆盖率中的碰撞问题,让它更精确。今年有很多团队尝试用别的、不同的Coverage来做指标,这个代表性工作是2020年Oakland的IJON工作,非常有意思,包括我们团队也在尝试各种想法,它实际上自定义了很多不同的Coverage指标,比方说在走迷宫程序时,迷宫所在的位置作为指标。如果大家搞Fuzzing,建议大家去看看。还有一些做定向Fuzzing的,不是探索所有代码,而是优先探索我们想探索的,比如某个点可能有漏洞,这类也是有个Coverage的,通常是距离,比如离目标有多远。
A better/alternative coverage algorithm?

还有一块是Sanitizer,刚才提到谷歌公司的AddressSanitizer是一个经典的工作。这部分和防护比较接近,去年也有Razar方法,引导它往race去发现特定的漏洞。
How to catch security violations during testing?

写到这里,我们就把这些年Fuzzing的一些方法介绍完毕了!可能不是很全,但大部分的方法都囊括了。
注意,这部分内容是结合张老师的分享以及作者的理解来叙述,所以和原文的框架有所差异。这里强烈推荐大家从下面的链接去下载原文进行学习,看看大佬们的前沿工作。
下面开始讲解我们的工作,第一个工作是USENIX Security 2020的一篇文章,叫做《GREYONE:Data Flow Sensitive Fuzzing》,是一个数据流敏感工作。

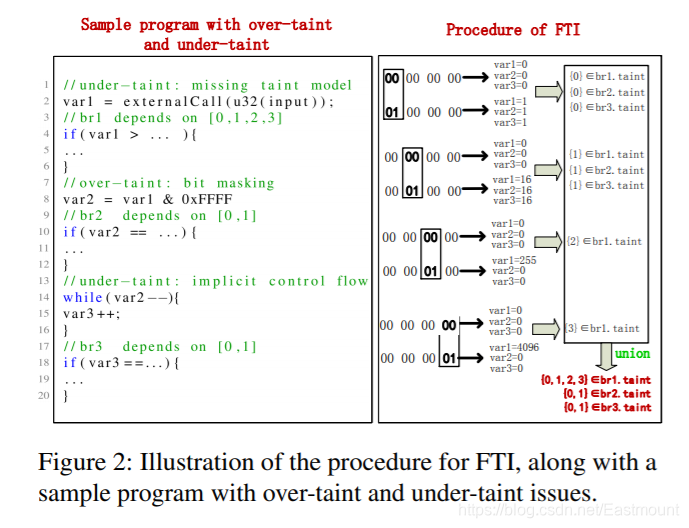
简单介绍下背景知识,我们先看下图所示的一个例子,这是经典的magic number检查。
- 第1个if:前面八个字节等于“MAGICHDR”
- 第2个if:后面八个字节必须等于算出来的校验和
- 第3个if:判断长度
- 第4个if:输入数据做个变形
- 第5个if:包含一些更复杂的是隐式依赖,比如第15行var1变量,它是跟第14行的控制相关
- 第6个if:bug5隐性依赖于Input的20到24个字节
我们人去看这些知识很容易理解,但是Fuzzing过程中,如果想触发bug1,我们在变异时,其实是有一些知识可以获取的。输入前8个字节与“MAGICHDR”进行比较,变异时是要对前8个字节进行变异,而不是随机变异,变异取什么值呢?我们应该取“MAGICHDR”。接着校验和(checksum)也类似,它会把输入中的8个字节(8-16)与算出来的值某个校验和进行对比,我们就要对input[8:16]进行变异,变异所取的值是计算出来的值。
- Where to mutate? input[0:8]
- How to mutate?MAGICHDR
- Seed prioritization:1 byte match vs 7 byte match
还有一点,比如“MAGICHDR”例子,只有全匹配上才能出发bug1,全部匹配上的概率还是比较低的,64个bit(2的64次方)。现在假设我们有两个用例,它们分别与“MAGICHDR”有1个byte和7个byte匹配,但从代码覆盖率上来说,它们都是一样的,都不满足这个检查,都会走这个flase的分支,但它们的测试效果或者对Fuzzing的作用一样吗?显然不是,明显7个byte匹配的测试例效果更好,因为下一次在7个byte基础上可能再变异一个byte就匹配上了“MAGICHDR”。

所以说这两个测试例得代码覆盖率是一样的,但是它的测试效果不一样。这个例子说明:Data flow information is useful for fuzzing。因此张老师他们提出了一种新的数据流敏感模糊解Greyone。
首先,data-flow features的类型是什么呢?
- Taint attributes(污点属性)
输入和变量之间的依赖性 - Branch value conformance(分支匹配度)
转移条件操作数间的距离,提出了一个分支匹配度的计算公式。一致性越高,距离越近,我们就认为它的匹配度越好。

基于上述观测,我们提出了如下图所示的模型,关注的是Taint部分,我们需要做数据流跟踪来识别刚才提出的两个特性。
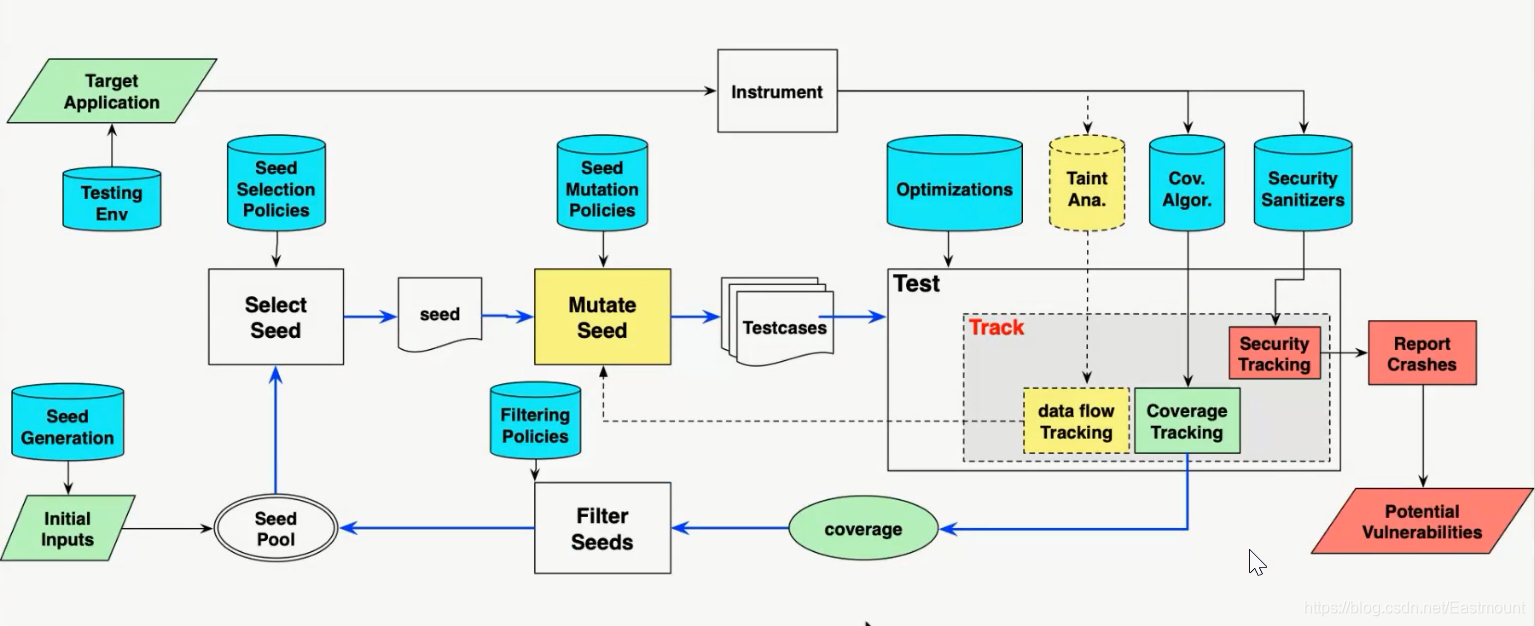
此时遇到3个问题:
- 怎么去获取数据流特性呢?
How to efficiently get data-flow features?——Traint attributes、branch value conformance - 如何利用数据流特性来指导变异?
How to utilize data-flow features to guide mutation? - 怎么去进一步调整fuzzing进化的方向?
How to utilize data-flow features to tune fuzzing direction?
接着我们先来回答这部分的问题。
(1) RQ1-1:Taint Attributes
Taint是非常经典的技术,很多地方都有,比如Libdft、DFSan等。基本思路是逐条解释指令,因为指令是有语义的,比如MOV移动EAX到EDX中去,它就会把EAX的污点属性转义到EDX污点属性中去,所以当它逐条解释语义它就可以分析这个输入的污点是怎么传播到程序中的各个变量上去的,一条条指令来解释。
但是这种做法很笨重,需要人去逐条写这个语义,非常麻烦,这些工具一般都需要人来写这个规则,很容易写错、写漏。那么去年NDSS有一篇做自动的,去推演Taint inst的工作,自动推演Taint的规则。
Traditional dynamic taint analysis
- Libdft/DFScan…
- Propagate taint inst. by inst.
- Taint rules manually/automatically
- Under-taint and over-taint issues
但所有这些工作都有一个问题,存在严重的Under-taint和over-taint的问题。这两类问题都很多,就会漏掉一些taint信息,或者造成错误地把一些不应该是taint而识别为taint。时间关系不展开讲解,不论是人工或机器来做都会遇到的问题,而且还比较严重。

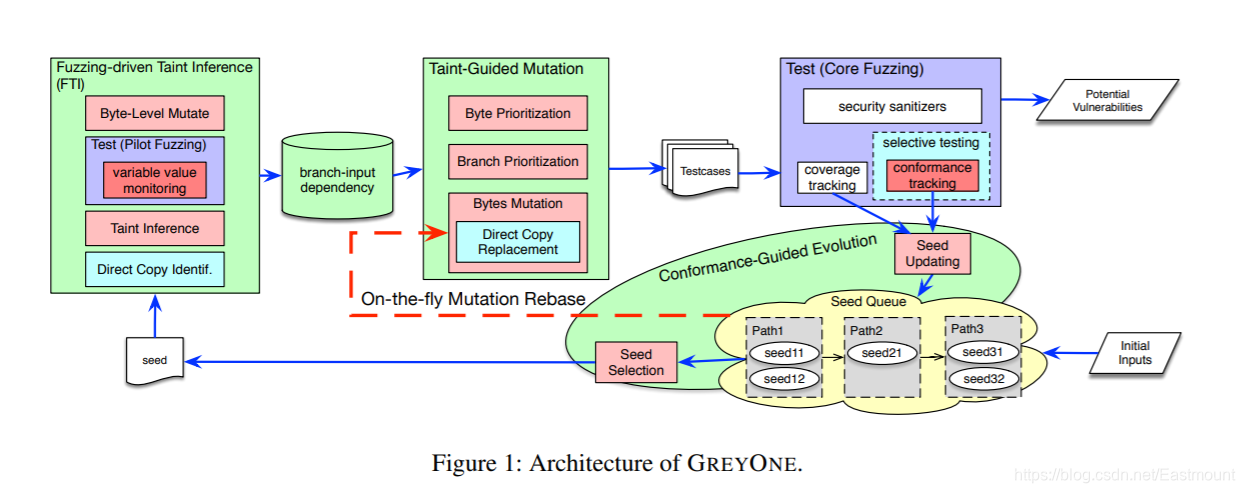
我们提出了一个新的方案,叫fuzzing驱动污点推断(Fuzzing-driven Taint Inference,FTI)。基本想法很简单,我们要关注的不是一条条指令的传播,我们关注的是宏观的效果,比如输入的哪几个字节会影响我的某一个分支,分支这边涉及到变量,我想关心的就是变量与输入的哪个字节相关。通过做一个变化,观察变量var的值是否保持不变,如果它的值发生了变化,我们就知道,这个var和变量S[i](第i个字节)是相关的,换句话说,如果变量的值在输入字节发生变化时发生变化,我们可以推断前者受到了污染,并依赖于后者。所以,我们只需要对fuzzing做动态测试,调整输入的某些字节,然后看程序中哪些变量发生了变化,发生变化的值就认为它与输入字节有关。
- Interference rule
v(var, S) ≠ v(var, S[i]) - Taint inference
Byte-level mutation:逐个字节变异
Branch variable monitoring:监控变量是否发生变化
Deterministic fuzzing stage
由于AFL是可以逐个字节变异的,我们只需要在Fuzzing过程中增加个变量监控即可。它的优点包括:速度非常快,不需要人工写传播规则,没有Over-taint问题,可能有少量的Under-taint问题,出现没测试到的情况。

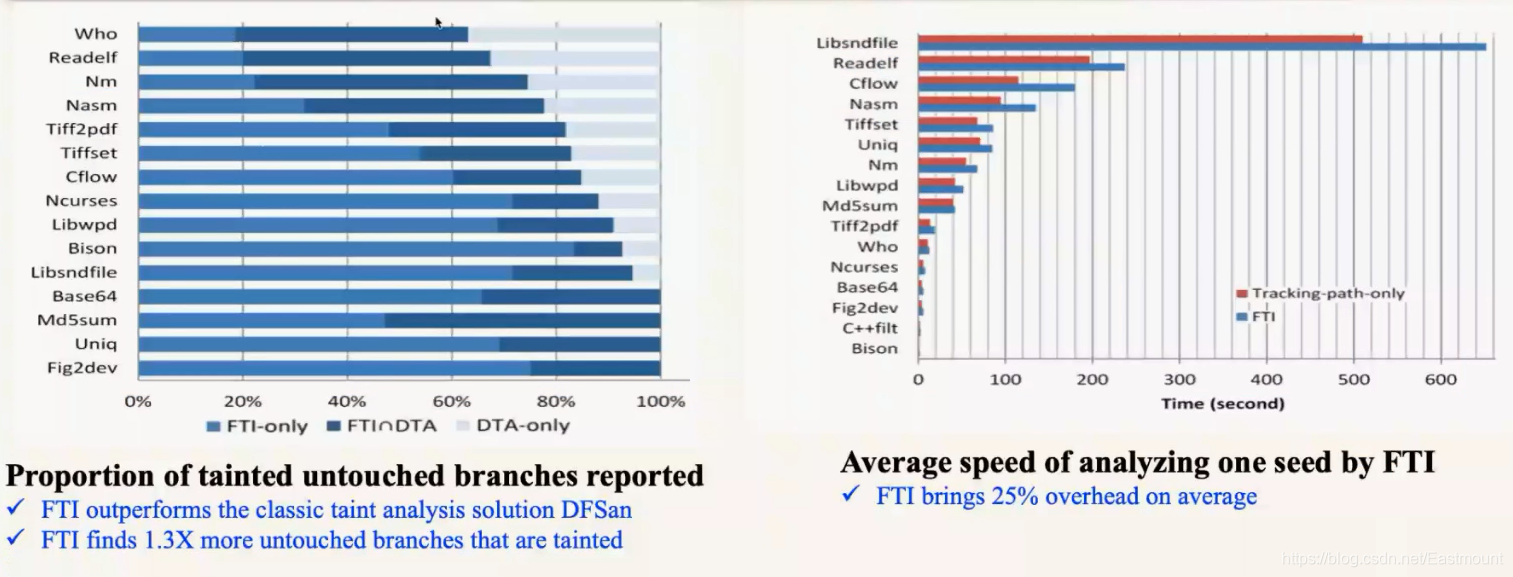
下图发现我们的漏报其实很少,左边这张图蓝色(最左边)是我们发现的污点,深蓝色(中间)是两者都发现的污点,浅蓝色(最右边)是IBM提供的污点。我们是没有误报的,它们可能会有Over-Taint的问题。所以我们的识别效果更准确,速度影响也非常小,只有25%的会overhead,对整体Fuzzing速度没有影响。
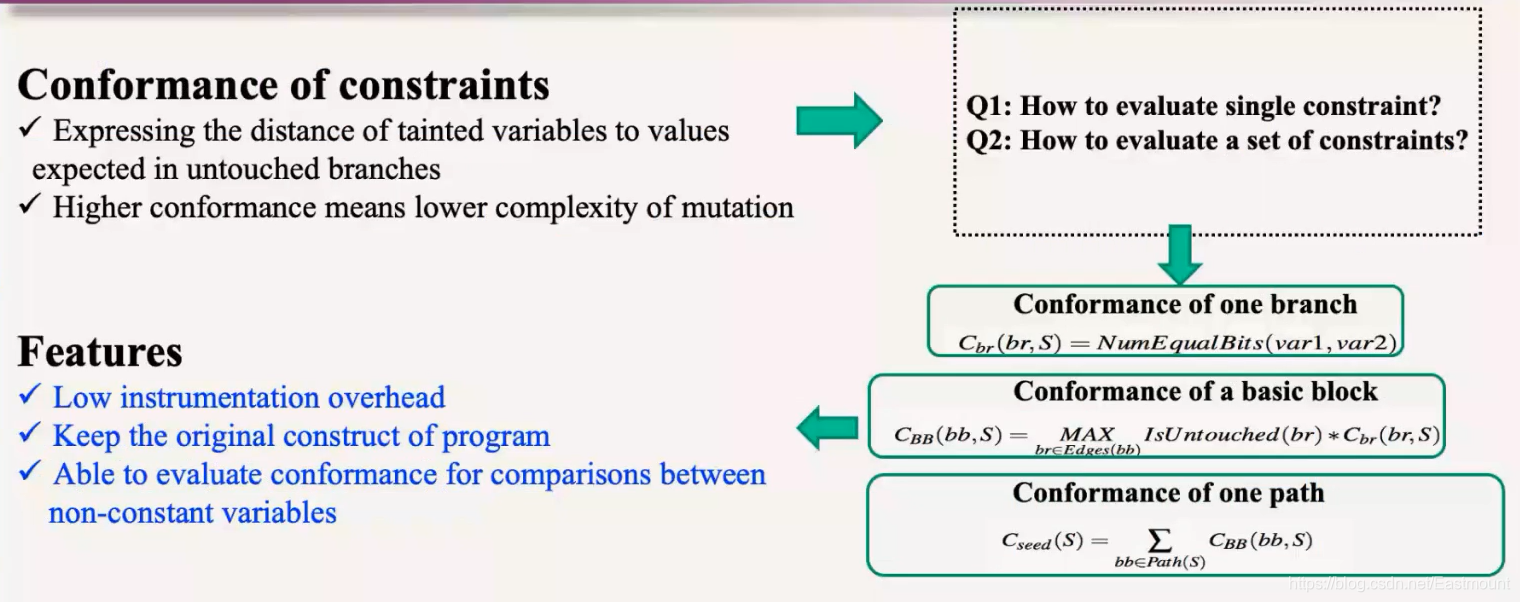
(2) RQ1-2:Constraint Conformance
第二个是识别数据流特征——分支匹配度。分支的地方两个变量有多少个匹配,通过程序插桩,就看分支在哪、有多少个bit相等,我们除了定义分支匹配度外,还进一步扩展了基本块的匹配度,扩展到路径的匹配度。
(3) RQ2:taint-guided mutation
① 识别完Taint信息和分支匹配度信息之后,怎么去进一步指导我们的mutation,怎么做变异呢?
前面其实已经提到了怎么做编译,比如Magic number、Checksum这些,直接拷贝这种。该编译很简单,通过Taint信息就知道要对哪里进行变异,然后获取的值是Magic number、Checksum,填进去就好了。
How to mutate direct copies of input
- Direct copies
Magic number、Checksum… - Execute twice
First round:FTI taint analysis input offsets, expected value
Second round:Mutate and test
还有一些是间接拷贝,输入的字节是通过一些运算之后来做检测,这种在变异的时候不能确定它准确的值,采用偏随机的方法,通过变量相关的字节进行随机的变异。
How to mutate indirect copies of input
- Random bit flipping and arithmetic operations on each dependent byte
- Multiple dependent bytes could be mutated together
然后taint有个问题,可能会有少量的under-taint问题,所以在变异过程中也不完全依赖于指导,可能也对那些我们认为不相关的字节也做一定小概率的编译。
Mitigate the under-taint issue
- Randomly mutate their adjacent bytes with a small probability
② 接着我们需要确定对哪些字节变异?
我们有一个排序,目标是探索更多的代码,首先对没有探索的分支做一个排序;然后这些分支与某些输入字节相关,再对输入字节做一个排序,然后优先选某个字节。
- Explore the untouched neighbor branches along this path one by one
In descending order of branch weight - For specific untouched neighbor branch
Mutating its dependent input bytes one by one
In descending order of byte weight
③ 这些排序怎么计算呢?
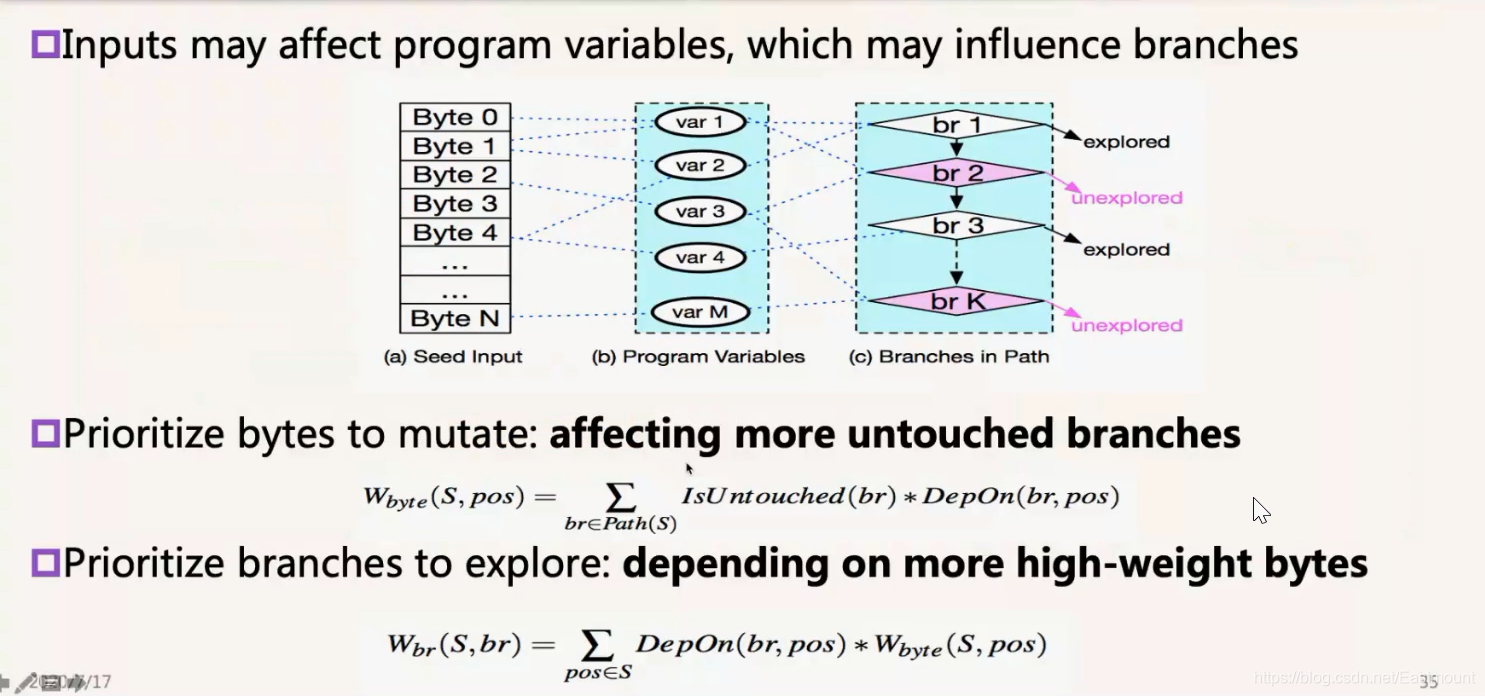
我们有公式来计算,其实就是看输入字节与这个分支之间的依赖关系,输入字节会影响某些变量,有些变量会应用到不同分支中去,有些分支被探索过(Explored),有些分支没有(Unexplored)。所以先定义字节的权重,看这个直接会影响多少个没有测试的分支,图中所示,数量越高它的权重越大。
- Input -> Variables -> Branches
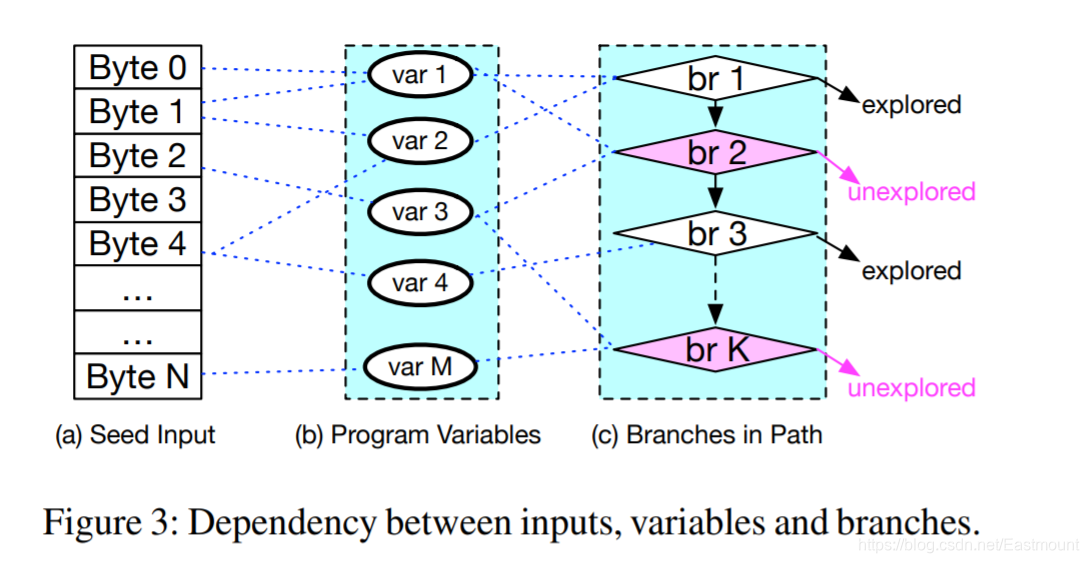
那么,分支怎么做排序呢?都是没有探索过的分支。也是从这个图上说,反过来,一个分支(Branch)会依赖若干个字节,这若干个字节权重加起来越高,这个Branch的权重也就越高。
(4) RQ3:Conformance-guided evolution
最后一部分是去调整进化方向,通过分支匹配度,一个字节匹配和七个字节匹配的效果是完全不一样的。

① 那么,怎么把这个增加进去呢?
我们在原来代码覆盖率基础上增加了一个新的指标,即分支匹配度。原来大家是把这个分支,有好的代码覆盖率,就把它放到种子池中去,种子池是一个线性列表,现在把种子池修改,它还是个列表,但是每个节点不再是一个种子了,它每个节点可能是多个种子。
- Updating seed queues
the higher conformance, the better
together with AFL’s policy: converage-guided
② 怎么做的呢?
- 如果有新的代码覆盖率(New coverage),即有新的测试例(每个小圆圈就是测试例),就会在种子池中新建一组节点,里面就是新的测试例。如下图右边黄色部分,种子编号41。
- 如果没有新的代码覆盖率(Same coverage,higher path conformance),它的代码覆盖率与之前某组测试例是一样的,但是它的路径匹配度更好,那我就取代了刚才的两个测试例。如下图左下角部分,种子编号21。
- 如果没有新的代码覆盖率或更高的路径匹配度(Same coverage, same path conformance, different branch conformance),路径匹配度是由基本块匹配度构成的,但是基本块匹配度或分支匹配度组合不太一样,我们就往里面添加一个。如下图所示的右下角部分,种子编号23。
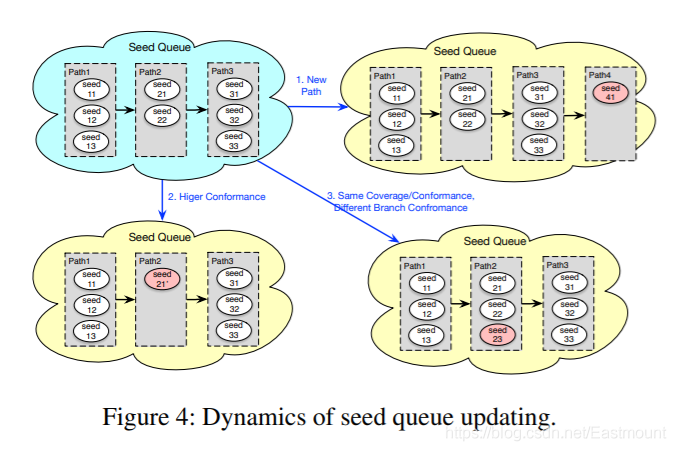
最后我们的种子池就修改成如下图所示,变成了二维的,后面取种子变异就从这个种子池中完成。该方法有很多好处,这里不详细讲解,具体如下图所示:

接着我们看看实验结果,我们和AFL、CollAFL、Angora进行了对比,我们比它们中最好的代码覆盖率也提升了20%左右。
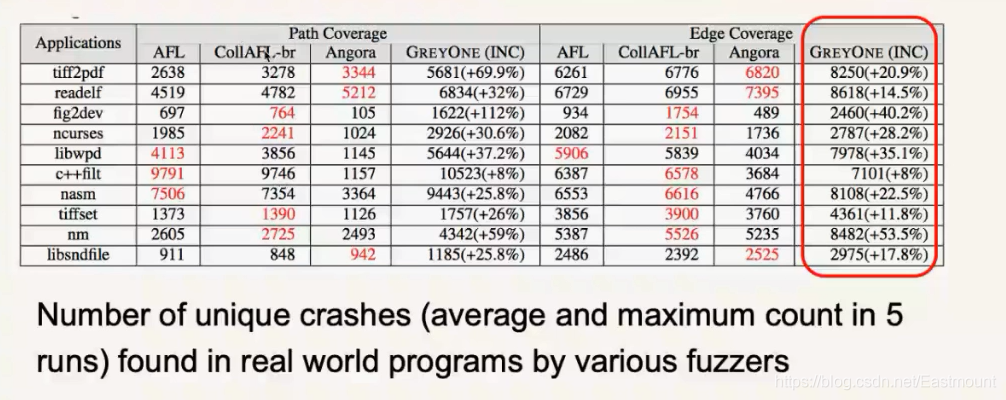
下图是进化曲线,代码覆盖率增长的曲线。
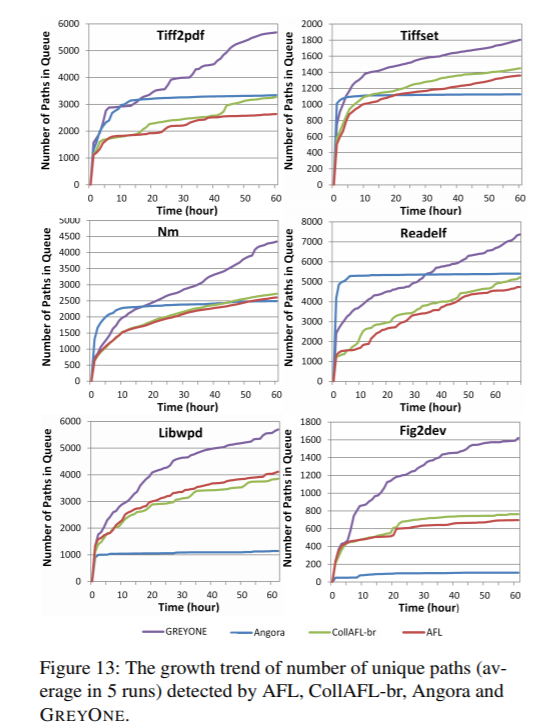
在挖漏洞这边,我们评价有两个指标——Crashes和漏洞。Crashes和之前三个中最好的相比,提升了5倍,增长曲线也非常快。
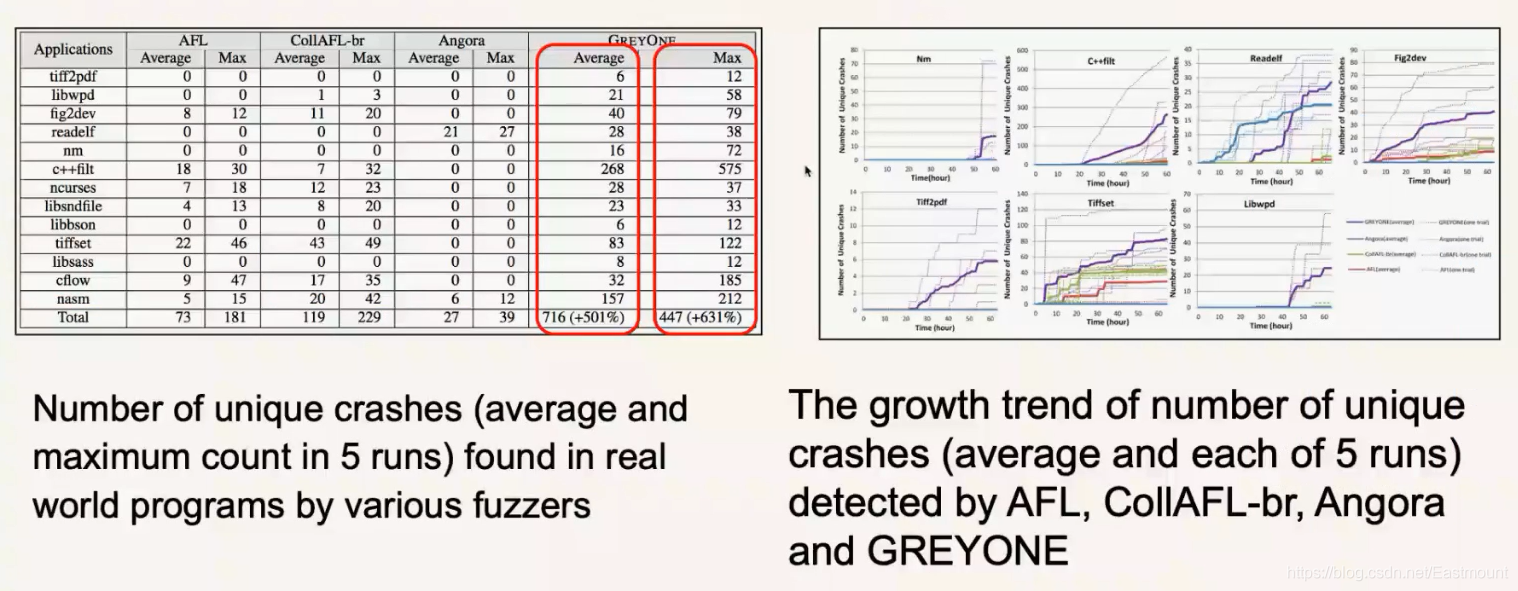
挖漏洞方面(Vulnerabilities),我们比之前的方案都要多,多2倍的效果,最后申请了41个CVE。

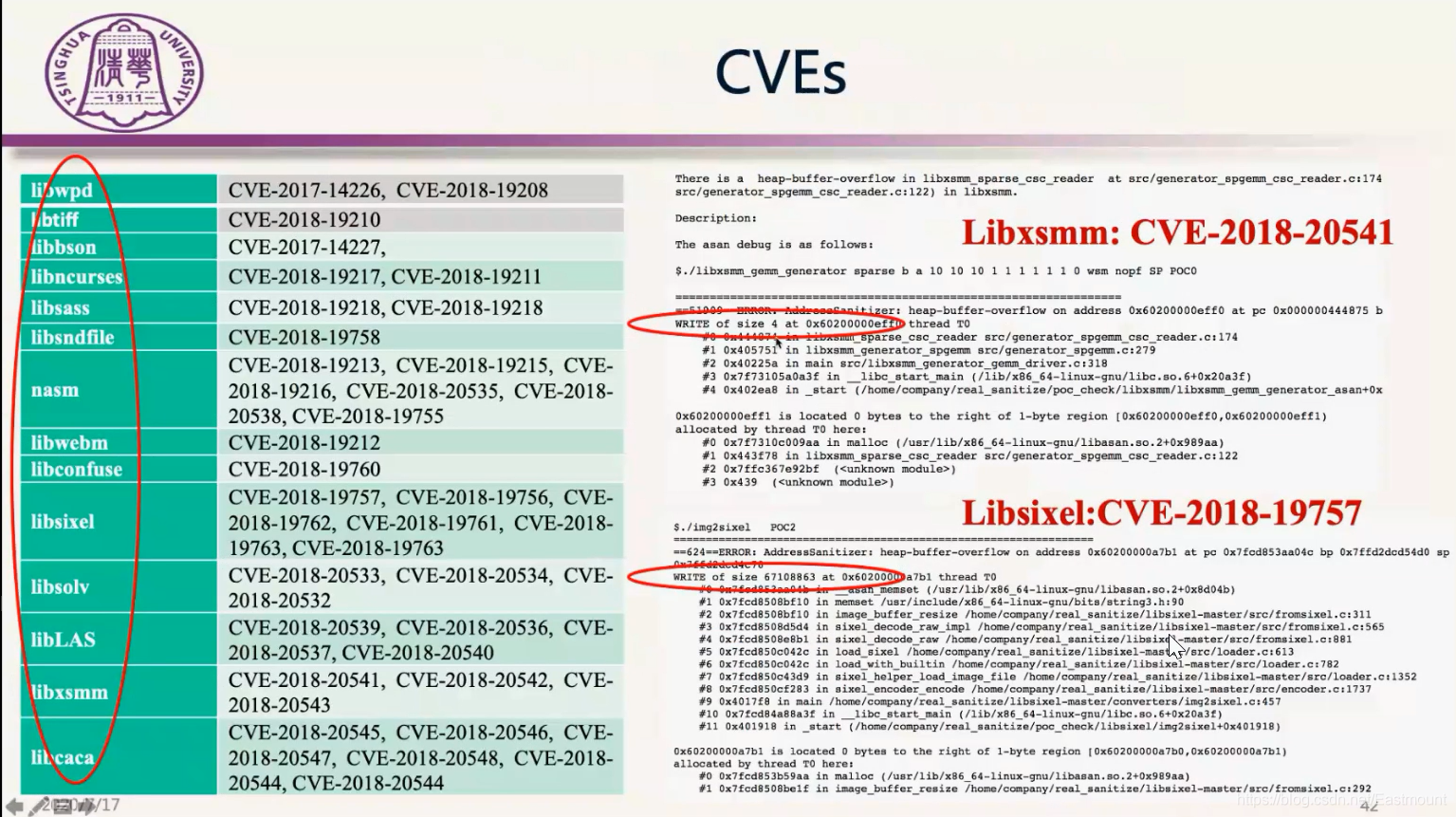
这次分享基本把GreyOne介绍了一遍,其实我们在Fuzzing方面还有以下这几个方面的工作,前面也提到过,推荐大家去阅读这些文章。
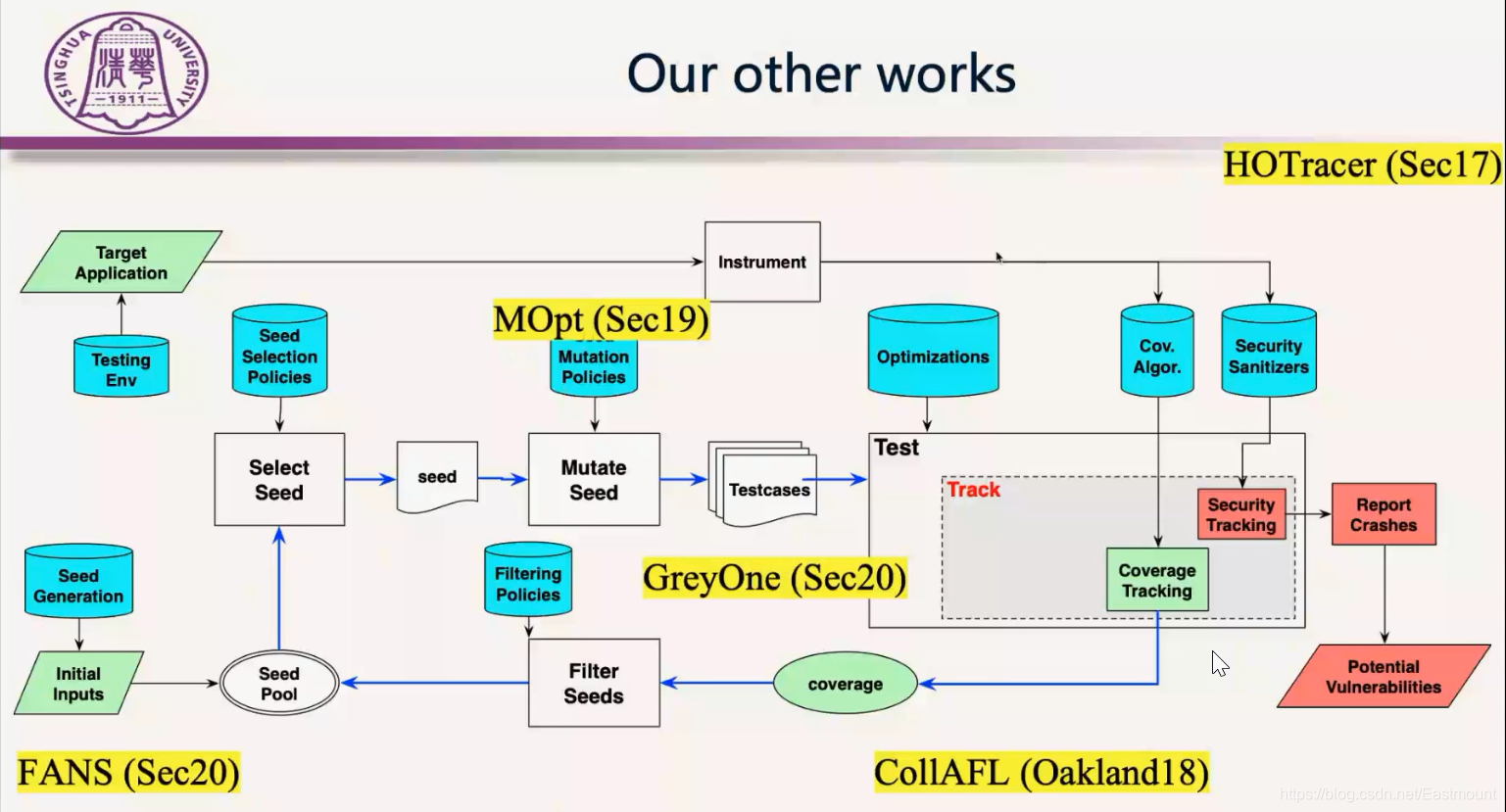
简单做个总结,Fuzzing目前是最流行的漏洞挖掘方法,有很多的工作在研究。我们讲解的GreyOne方法是根据数据流敏感的思路来做的,在Fuzzing中更精确地通过很多的数据检查,该方法的亮点在于用了一个清亮的污点跟踪机制,用污点信息来指导进化,同时用分支匹配度来调整进化方向。当然,fuzzing这块还有很多工作可以去做的。
- Fuzzing is the most popular vulnerability discovery solution
Coverage-guided fuzzing is popular - Data-flow sensitive solution Greyone
Infers taint attributes during fuzzing
Performs taint-guided mutation
Performs conformance-guided evolution - Many more topics to explore in fuzzing
问题:这里主要针对有源码的挖掘吗?这套方案和源码有什么关联呢?
回答: 有源码的时候效果会更好,因为需要做污点分析、监控变量的取值,然后来做程序插桩。当然这些工作在二进制中也可以做,其实反汇编都很难做种,更何况需要做插桩或其他的,可以做,但是效果会差一些,准确性、包括提取的分支会少一些,我们的方案可以移植过去,但是目前没有数据会说移植过去的效果会怎样,相比其他二进制方案会有提升,但效果不会很高。
问题:漏洞挖掘方案它挖掘的漏洞类型会不会偏向哪一类呢?比如哪一类较多或哪一类没有效果。
回答: 现在Fuzzing方案基本挖的内存破坏漏洞比较多,还有一些定制的适用于算法复杂度的漏洞,有一小部分是其他漏洞。它能挖什么类型漏洞,主要能力在于Sanitizer这部分,写什么样的检测工具,如果不写检测工具,只能看程序是否崩溃。很多时候漏洞触发后,它也不一定崩溃,所以大家会定制Sanitizer,比如BufferFlow监控,定义规则出来,比如谷歌的AddressSanitizer,它的漏洞类型和我们检测器有关。
问题:您挖出来的这些未知漏洞,怎么去验证它是不是真实的漏洞呢?是通过手动的方式呢?还是自动化方式呢?
回答: 这是个很好的问题,目前我们Paper中基本是人工来做,AFL提供了一些过滤功能,把显然是重复的这些Crashes去重了,剩下的还有一定数量,几十个、上百个,通常会人工写一些脚本工具来判断和验证。学术界现在也是有Paper在研究这些,怎么做自动的Crashes分析和归类。
问题:论文假设分支匹配度越高,输入的种子越优,这个假设怎么处理函数变化,如Hash变化再input呢?一个好的Hash函数它的输出应该是均匀的,这时的假设感觉就不太需要了,请问下这是怎么处理的。
回答: 我们现在没有处理这种特殊情况,其实遇到这种情况现在的方案可能大家都做得不好,这是一个很经典的例子。比如前面说的间接数据拷贝,做了一个变换再来判断,我们的方案效果也不好。我们的方法识别出来它和18到20字节相关,重点变异这几个字节,此时分支匹配度策略可能就不是很有效,比如foo可能是Hash变换函数后均匀分布了,确实是存在问题的。

作者感受:学术或许是需要天赋的,这些大佬真值得我们学习,同时自己会继续努力的,争取靠后天努力来弥补这些鸿沟,更重要的是享受这种奋斗的过程,加油!
最近又认识了很多朋友和博友,非常荣幸。有问问题的,有考研交流的,有一起读博鼓励的,也有想考博去大学教书的,还有技术交流以及交朋友的。虽未谋面,共同前行。尽管自己非常忙碌,但还是很愿意去解答博友的问题,去帮助更多的陌生人。有时候你的一句鼓励,一个回答,可能就是别人前行的动力,何乐而不为。虽然自己的技术和科研都很菜,安全也非常难,但还是得苦心智,劳筋骨,饿体肤。感恩亲人的支持,也享受这个奋斗的过程。月是故乡圆,佳节倍思亲,加油,晚安娜
希望能与大家一起在华为云社区共同成长。原文地址:https://blog.csdn.net/Eastmount/article/details/107825286
(By:Eastmount 2021-09-22 晚上12点写于武汉 )

- 点赞
- 收藏
- 关注作者
评论(0)