[论文阅读] (01) 拿什么来拯救我的拖延症?初学者如何提升编程兴趣及LATEX入门详解

又是在凌晨三点赶作业,又是在Deadline前去熬夜,一次次无眠,一次次抱怨。为什么三年前、两年前、一年前,甚至是昨天,我都下定决心“从现在开始读顶会论文”,却又悄悄选择逃避;为什么我的收藏夹存了很多学习资料和视频,然而却没有再次翻起;为什么无数次告诫自己一定要卸载游戏和社交APP,开始好好学习,但明天又会继续下载去放纵自己。我们忙碌,我们孤独,我们在一遍遍地逃避和自我安慰中变得惴惴不安,拖延和等待终将击垮我们的斗志。人生几何,去日良多,不要再让拖延彻底吞噬了你我!
为了改变,为了前行。因此就有了这样一篇文章,也有了《秀璋带你看论文》新的系列,同时也解答了一些初学编程博友的疑惑。本文将分享作者这些年学习、编程和科研的经历,也将详细介绍LATEX工具的用法,就当是开启我们科研之门的钥匙。注意,本文欢迎大家对号入座,闭上眼睛、扪心自问,你有拖延症吗?你是不是也准备开始学习一门新的编程技术,却又立刻放弃;你是不是无数次在截止日期前通宵达旦、痛心不已?你是不是立下很多flag却没有付诸以行动而更改计划呢?如果这篇文章能唤起你去学习,去奋斗,去拼搏,足矣。如果你能坚持一个月、半年、一年,甚至几年,去做自己想做的事情,去追逐心中的乌托邦。那么,我希望你再回过头来找到这篇文章,告诉你的好友秀璋,我们曾一起拼搏前行,这种素未谋面却相互鼓励的感觉真好!

更重要的是,希望大家督促我,我在此立下每个星期至少分享一篇学术论文的flag,也期待您的加入,多多与我评论、交流、探讨,同时欢迎大家推荐我好的论文和创新。该系列文章主要包括:
- 空间安全方向: 作者目前正在学习系统安全、网络安全、恶意代码溯源等知识,该方向的论文主要来自顶会、期刊,也有部分较好的中文核心。同时,会结合实际项目及作者的理解进行分享。
- 人工智能方向: 作者一直从事人工智能相关研究,但没有系统地阅读过AI论文,后续也想尝试安全与AI的融合,所以这里想阅读一些前沿的人工智能论文。
- 知识图谱方向: 知识图谱和自然语言处理我是2014年开始接触,硕士毕业论文也是实体对齐和属性对齐。后续工作一直从事知识图谱与贵州文化、舆情等融合的研究,这些论文将从实战讲解,包括命名实体识别、关系提取、事件提取等。
- 图情情报方向: 图书情报方向是在传统计量分析、文献情报分析基础上,融合大数据、人工智能、NLP等知识进行讲解,涉及情感分析、舆情分析、大数据分析、可视化分析等知识。该部分论文主要源自C刊核心内容,实战以作者的编程博客为主。
- 计算机视觉方向: 作者曾研究过数字图像处理技术,随着算法发展,传统的先验计算如何融合到深度神经网络中,更好地实现人脸识别、模式识别、指纹识别等。同时,恶意代码用图像表示从而进行恶意代码识别,计算机视觉如何抢救古文物、民族文字,对抗样本都是新关注点,作者也将努力去学习。
最后,感恩一路有你,感谢一路同行,希望通过编程分享帮助到更多人,也希望学成之后回贵州教更多学生。因为喜欢,所以分享,且看且珍惜,加油!等我四年学成归来~
文章目录
对我而言,我自认为自制力还可以。高中三年每天学到凌晨2点;大学期间在CSDN分享博客八年从未间断;上班之后又挤周末、上下班赶公交的时间考了博士;2019年下半年初入安全,《网络安全自学篇》系列记录了这大半年的点点滴滴,82篇文章,50万访问量,每一篇都是我的血肉,都包含了我的汗与泪。那么,我为何还有这么严重的拖延症呢?我又该如何督促自己高效的学习呢?

很多博友和初入编程世界的朋友都问过我,我应该怎么学习呢?我应该去选择哪一门编程语言呢?我又应该怎么提升自己的编程兴趣呢?
时光回到十年前,我刚入大学。
从未接触电脑的我也是一个懵懂的小屁孩,高考被莫名其妙调剂到了一个陌生的专业——软件工程。调剂可能也是很多同学都会面临的,一个“毫无兴趣”的专业会让你我迷失。到了大学,我们就像脱缰的野马脱离了父母老师的约束,我也一样。大一刚接触电脑不久的我就学会了dota,开始看小说。每天重复着下午打球,晚上打游戏到熄灯,看小说到深夜的日子,难道是我的控制能力不强吗?不是的,高中的我也每天学到2点!是我们还没有接触到这些诱惑,还不知道它们的魅力有多大。所以,在大学一定不要沉迷于游戏和小说,切记,切记,切记。

如果你是依然沉迷其中的大一学子,醒醒吧!少年~
幸运的是,我还是一个比较会反思自己的人。寒窗苦读十二年,父母心血何止千,难道就是为了让我们来大学享受的?况且这算得上享受吗?毕业之后难道我真的只会修电脑、做PPT吗?欧,NO,我连电脑都不会修。所以,接下来我开始改变,怎么做呢?
-
跟着好学生一起编程,如果没有,从自己做起
这之后我开始改变,跟着优秀的同学一起学习,一起编程。无数个中午都跑到实验楼和图书馆敲打代码,从C语言的“Hello World”到HTML的“< html>< /html>”,一点点成长。这过程痛苦吗?其实痛苦,但也夹杂着欢笑,尤其是当屏幕出现我们想要的结果,那种欣喜若狂至今回味无穷。 -
远离寝室,扎根图书馆或实验室
幸运的是我们寝室学习氛围还算好,但我们仍然远离寝室,去图书馆或教学楼学习。在我遇到的很多网友中,可能有学习氛围不是很好的。没关系,少年,不要在意别人的眼光,想想自己的父母,出去学习、敲代码吧!我看到了太多的学生通过自己的努力找到让我羡慕的工作,专科也好、本科也罢、硕士博士亦然,只有不断地去奋斗,去吸取,才能体味到人生各个阶段的魅力。 -
不耻下问,坚持不懈
编程道路上是孤独的,我们会遇到各种各样的问题,这种独立搜索解决问题的能力也至关重要。记住一句话,不要总觉得自己的问题简单,就害怕而不去询问,更可怕的是逃避。我也一样,从最早的VC环境搭建,到回文递归、图形打印、列表文件等,都一点点摸索着前行,况且现在网络这么发达,社交论坛这么多。同样,坚持也非常重要,当我无助沮丧时,就会想起小石匠精神,“有个小石匠在不停的敲打石头,似乎敲打了上百次也没能在石头上留下任何裂痕,但就在他敲第一百零一下的时候,石头突然裂成了两半”,我知道,不是最后那一下击碎了石头,而是前面不懈努力的结果。 -
多敲代码,多去实践
编程中最忌讳的就是拿着书本、看着视频、喝着奶茶,就是一天。作为一个计算机学生,不去敲代码,不去实践怎么能行。同时,很多基础课程都非常重要,有的课程可能枯燥,比如《数据结构》《软件工程》《操作系统》《算法分析》等等。但换个角度,你能否将枯燥书本中的内容用代码去实现呢?能不能编写一些小程序呢?算法能不能编个音乐推荐系统呢?能不能做出一个小型DOS系统呢? -
争当小组核心,尝试参加竞赛,这种短期压迫自己和追逐学习的能力才是你的珍宝
大学中很多课程会分小组,我建议你尝试当组长或作为核心成员。回过头来,大学四年,真正让我成长的课程都是我作为组长或核心的时候,可能你的组会有打酱油的人,但这何尝不是对你的一种提升和锻炼呢?同时,大学中的竞赛有很多,比如ACM、CTF、软件设计大赛、阿里竞赛等。个人建议你可以尝试参加一些竞赛,这种短时间内让你参与到团队中去做项目,会让你不断成长,也是你一生的珍宝。我大二就参加了游戏协会、ACM,博士最近又参加了CTF,每次都能从实战中学到了很多前沿技术。 -
网络自学提升,撰写博客分享
随着网络学习资源和课程越来越多,我们能通过网络自学很多知识,后面我会进行详细推荐。同时,为了更好地逼迫自己去学习,养成独立编程的习惯,我从2013年3月开始撰写博客,最早的一些都是课程作业或编程实战,到后面系统的博客,我伴随着CSDN成长。虽然写博客会占用一些时间,但这种在线笔记会记录你学习的点滴,而且当你再次遇到问题时能快速解决,如果博客写得好对你找工作未尝也不是一种优势。尤其是缺乏独立学习能力的同学,当我们在网上看实战课程时,非常建议一边编写代码一边用博客记录,最开始可能会很艰难,但慢慢你会发现自己的技术在不断成长,人有的时候是需要PUSH、PUSH、PUSH的。

我是调剂生,我不想学习编程。
回到之前的问题,很多初学者都是调剂生,对编程不感兴趣,怎么办呢?刚开始我来到这个专业的时候,也觉得它不适合我,我的一些同学也因为一些课程后觉得不适合这个专业。难道真的不适合吗?很多时候是在为自己找一个借口罢了,因为你根本没用心去学。如果你不知道你是否适合,那你需要的是付出、努力去学习,况且又有多少人能够再次调专业呢?
当我付出后,我才知道其实这个专业是适合我的,因为其他的我想不出第二个更适合的专业,而且更加热爱这个专业。计算机专业本身还是非常有意思的,我们能通过编程做很多有趣的东西,也可以私下去学习一些技术或完成一些软件。
如何让自己对编程感兴趣呢?
兴趣是最好的老师,刚开始接触编程C语言、C++、数据结构时,我们会觉得枯燥而丢失兴趣。这里我非常建议大家课后去做一些自己感兴趣、并且可见的程序,我就是在大二开始学做游戏慢慢提升编程兴趣的,下图正是我最终做的音乐游戏《坠梦》。如果你是一名初学者或大一新生,你可以去做哪些事情呢?
- C#能够迅速完成Windows应用程序,比如聊天室、对话框等,也可以实现.NET网站
- Python简洁的特点非常适合初学者,建议学习路线为语法、爬虫、网站、可视化、数据分析、CV、AI等
- C++/MFC能够让你完成一些应用程序,可以结合图像处理或小型系统来学习
- JAVA推荐大家结合网站开发来学习,包括传统的SSH、Spring Cloud、Android移动端开发等
- 游戏开发其实挺有意思的,包括Unit3D软件、gamemaker、OpenGL等都不错
- 网络安全也非常有意思,但提醒大家要合理合法去完成实验
- 参加学校的编程社团或组队比赛,大家一起去学习或完成一个东西
我自认为不是很聪明的学生,但是只要我用心去学了肯定能入门,至于精通还需要很长的磨练。如果你能有打 lol 的那种激情,编程其实也很轻松,只有付出才会有所收获;如果你编程有holy shit(超神)那种欣喜若狂,你还做不出来吗?其实当你独立完成一个项目后,它的感觉不亚于一次暴走的杀戮、一次超神!!!

这句话我不知道出自何处,只知道是我们的学长鼓励我们编程时说的,而我们的学长又是上上届学长传承下来的。如果你还是学生,一定要好好珍惜寒暑假,在那段时间我们能学到很多东西,可以做一个自己感兴趣的软件或项目,学习一些技术算法都是非常有用的。我就利用寒暑假学习了MFC编程知识、C#网络编程知识、Python技术等。你是否也应该去尝试一下,何乐而不为呢?YQ期间,你是否仍在坚持学习新技术呢?又为什么不是从今天开始制定计划补充能量呢?
当我到了大三的时候,专业课变得越来越多,也是最繁忙的一年。其中需要学习的就包括:计算机网络、操作系统、数据库、项目实践、编译原理、汇编等,还有很多自选的专业知识课程。在这当中你需要扎实的学习,提升自己的专业技能后,才能更好的找工作或为研究生出国打基础。所以,寒暑假还是要利用起来啊,上课期间哪还有时间搞其他的!下面是我这些年寒暑假的学习经历,看了之后,你就会知道为什么我说“真正的大牛都是在寒暑假练成的”了!
- 大一寒假: 参加学院ACM集训队,3周的编程实践,第一次了解算法竞赛
- 大一暑假: 学院组织去东软学习锻炼,MFC完成汽车地图解析系统,当时就是个拖油瓶

- 大二寒假: 与两位好友花了半年时间共同开发了音乐游戏《坠梦》《采蘑菇小矮人》
- 大二暑假: 小学期实践完成DOS操作系统开发,学习了Object-C移动端开发,改编游戏《仙剑一》

- 大三寒假: 独立学习了C#编程语言,完成了网络编程应用开发,这为后面本科毕设打下基础
- 大三暑假: 小学期编程实践,准备考研,同时提升英语等能力
- 大四寒假: 完成了毕业设计Eastmount安全卫士,当时360还没有相关功能,做了一款集成痕迹清除的安全软件
- 大四暑假: 回贵州支教半个月,第一次站上讲台授课,同时由于研究生方向为NLP和Web数据挖掘,开始接触Python编程,学习爬虫分析

- 研一寒假: 进一步研究知识图谱,参加CCF会议并分享相关博客
- 研一暑假: 结合课程进一步学习JAVA网站和Android开发,进一步提升编程实践,完成LeetCode题目及找工作
- 研二寒假: 系统学习搜索引擎、知识图谱相关知识,并完成毕业论文实体对齐算法研究
- 研二暑假: 反复奔波北京和贵州找教师工作,最后到贵州财经大学成为一名教师

如果你还是一个大学生,你也应该去享受一下自己独立编程实现一个感兴趣东西的过程。在这期间,你需要自己查阅资料、调动自己的积极性,尽自己的最大努力去完成它。下一个寒暑假你是否也应该珍惜起来,不,应该是从现在开始去做点什么了吧!短暂的激情是不值钱的,只有长久的激情才是值钱的。不论未来如何变化,我都希望大家能始终坚持自己为人处世的原则,怀抱一颗学习、感恩的心,坚持着去追逐心中的梦想,人生路上期待你的陪伴与前行,共勉~
你或许也听过TED关于拖延症的讲座,我们制定好了理想的计划,最终却只能在Deadline前熬夜去完成。在生命的日历上,我们涂掉了一格又一格,不要再让拖延吞噬了你我的成长。
让我们沮丧的不是我们没有实现梦想,而是我们甚至还没有开始追寻梦想
The frustration is not that we could’t achieve their dreams, it’s that we weren’t even able to start chasing them
那么,如何改掉编程或学习中的拖延症呢?下面是我的个人意见,如果存在不足或错误的地方,还请批评指正。
- 编程不要想太多,先开始写代码再说,做最重要
- 如果自觉性不强的,可以结伴而行,找到努力的小伙伴,一起前行
- 如果是编程不感兴趣造成的,尝试让自己爱上编程,做好玩的,完成一件后又适当奖励自己
- 编程实践和撰写博客能够让你付诸以行动,分享会让你重拾兴趣
- 编程路上需要鼓励,去感染你身边的人,看到自己喜欢的文章,不要吝啬评论和点赞
- 制定计划并定期打卡,让自己忙碌起来之后会忘记游戏、小说等诱惑
- 如果有导师督促,每周的汇报会让你紧张起来,酸爽
- 现在、立刻、马上,别再等待
同时,我自认为还是努力的,朋友圈也比较励志,这也影响了很多周围的好友一起奋斗,如果您想加我微信一起前行,私聊我就好。为了逼迫自己开源,我的Github从二月份开始每日打卡,这或许也是另一种远离拖延的方法吧!你也可以试试~

当然,写这篇文章的初心有两个,一方面是帮助初入编程又困惑的同学,另一方面是督促自己赶紧去看学术论文,别再拖延了。所以接下来《秀璋带你读论文》系列文章就是我摆脱科研拖延症的尝试,半年或一年后我们再来看看结果吧!

首先,怎么去学习呢?
(1) 课程知识
关于课堂知识,我的建议是基础理论课程要学扎实(适当划水),而编程实践课程一定要学好(切勿划水),实战编程就是我们今后的饭碗啊!包括C语言、Python、程序设计、Web网站开发、大数据分析、数据库等等,能当组长的可以尝试当组长,编程实战作业一定要独立完成。同时,当我们学习了网页开发、数据库、后台编程语言如JAVA之后,你是否有考虑过独自将它们串联起来,开发一个动态网站呢?你又是否考虑过学习最新的框架如Spring Cloud \ Spring Boot再去结合这些知识点呢?这种拓展学习的能力很多时候是课堂上没有的,这也是为什么大家学同样的课程,别人家的孩子技术就很强。
(2) 网络学习
随着网络学习资料越来越多,通过网络学习是我非常推荐的方法之一,这里我给出了一些比较好的资源网站。同时,个人不建议大家私下去购买那些非常贵的课程,B站、MOOC等这么多免费视频,它们难道不香吗?还不够你学习吗?
- MOOC: https://www.icourse163.org/
中国大学MOOC提供了很多高校的公开视频课程,非常值得大家去学习,跟着老师的进度去完成。比如下图中,我母校BIT的Python语言程序设计就不错,哈哈~等我毕业回去之后,我也会尝试在MOOC上分享几门Python编程课程的,加油!

- B站: https://www.bilibili.com/
B站不仅是二次元的世界,里面还有非常多的学习资源,这里非常、非常推荐大家去搜索学习。比如安全、深度学习的一些课程都非常好,而且还没有广告,下图是我收藏的部分资源。

- CSDN: https://blog.csdn.net/Eastmount
如果是想通过博客学习,我非常推荐CSDN。作为全国最大的编程论坛,不仅仅因为我在这里分享知识,更多的是我在这里学到了很多技术,它让我不断成长。从最早的July大神到Android的郭神、罗神,再到吴老师、许老师这些前辈,金老师、贺老师这些高校教师,以及涛哥、雷神、二哥,还有太多太多大佬和博友,感谢在CSDN遇到的每一位朋友,感谢每一位为CSDN付出和分享的人,有你真好!这里厚着脸皮推荐下我的一篇文章:我与CSDN的这十年——笔耕不辍,青春热血

- 网易云课程: https://study.163.com/
网易云课程也有很多学习资料供大家学习,包括之前我学习的TensorFlow、Python、软件安全等视频,下图是我的学习资源,推荐“莫烦”老师。

-
Github: https://github.com/
GitHub是一个面向开源及私有软件项目的托管平台,因为只支持Git作为唯一的版本库格式进行托管,故名GitHub。这里能找到非常多的开源代码,这些源码和框架都值得我们学习。 -
coursera: https://www.coursera.org/
Coursera是大型公开在线课程项目,由美国斯坦福大学两名计算机科学教授创办。旨在同世界顶尖大学合作,在线提供网络公开课程。Coursera的首批合作院校包括斯坦福大学、密歇根大学、普林斯顿大学、宾夕法尼亚大学等美国名校。尤其是机器学习、深度学习等课程非常推荐大家去学习,比如吴恩达老师的。 -
Stack Overflow: https://stackoverflow.com/
Stack Overflow是一个与程序相关的IT技术问答网站。用户可以在网站免费提交问题,浏览问题,索引相关内容,在创建主页的时候使用简单的HTML。当我们遇到很多编程问题时,这个网站会提供非常多且准确的解决方案。 -
微信公众号
个人感觉,微信公众号也是学习的好地方,越来越多的大牛都有自己的公众号,里面包括非常多的高质量文章,它更方便大家用手机浏览。毕业之后,我也弄个公众号玩玩吧!这几年真的很忙。 - 华为云社区
当然,还有很多学习的网站,比如博客园、开源中国、看雪、阿里云栖社区等等,这里作者不再赘述。
那么,如果是一名初学者,我需要学什么呢?
下面作者结合自己这些年躺过的浑水,给初学者一些学习建议。这十年,感觉自己确实学得太杂,作为高校老师这是好事;但如果是做研究,这还远远不够,所以接下来的博士生涯希望能更深入的学习,加油~
(1) Python学习系列
共计6个系列,近200篇文章。2014年作者攻读硕士研究生,跟着导师从事Web数据挖掘和知识图谱的研究,从零开始系统地学习Python系列知识;2016年作者回到家乡贵州财经大学教书,陆续完成了Python数据挖掘、大数据分析等课程,本系列文章就此而成。它非常适合对Python感兴趣的读者学习,不要担心你的基础,一步一个脚印学就是了。个人建议的学习路线为:先学习Python基础语法,接着深入学习Python爬虫、Python数据分析、Python图像处理、Python人工智能,一定要结合实例编写代码。加油,让我们一起走进Python的世界吧!
- Python基础知识系列:Python基础知识学习与提升
- Python网络爬虫系列:Python爬虫之Selenium+BeautifulSoup+Requests
- Python数据分析系列:知识图谱、web数据挖掘及NLP
- Python图像识别系列:Python图像处理及图像识别
- Python人工智能系列:Python人工智能及知识图谱实战
- TensorFlow+Keras:Python+TensorFlow+Keras人工智能实战

(2) 安全学习系列
共计100篇文章,目前仅1个系列。2019年博士方向又恰好为网络空间安全,故撰写了该专栏的一系列文章,后续会继续深入。涉及包括Web渗透、网站攻防、AI安全、系统安全等。希望对网络安全的读者有所帮助~
(3) 人工智能学习系列
目前约30篇文章,该专栏涉及人工智能基础知识、实战项目,包括Learning to Rank、TensorFlow、Keras、Theano和Word2vec等,后续希望能深入研究人工智能算法,并带着大家由浅入深分享代码和总结文章。希望该专栏对知识图谱和人工智能感兴趣的读者有帮助~
- TensorFlow+Keras:Python+TensorFlow+Keras人工智能实战
- Python+Theano:Python+Theano人工智能实战
- Learning to Rank:Learning to Rank学习排序编程实战
- LDA+WordVec:知识图谱、web数据挖掘及NLP

(4)知识图谱学习系列
共计20余篇文章,作者硕士研究方向为知识图谱和人工智能,第一篇知识图谱文章是2015年总结的相关会议。该专栏涉及知识图谱的基础知识、实战项目,希望对您有帮助~下面给出文章中含目录的最新博客,希望对您有所帮助。

(5) NLP和舆情分析系列
共计20余篇文章,主要围绕NLP和舆情分析进行讲解,涉及内容包括NLP常用工具、实体识别、中文分词、舆情分析、情感分析、YQ舆情分析等。下面给出典型的文章供读者学习:

(6) Android开发系列
共计19篇文章,作者2012年就计划学习IOS和Android开发,但由于当时的海尔笔记本无法满足环境要求,后来又准备学习Unit 3D游戏开发,也因为电脑问题,最终改为学习C#入门到Python数据挖掘,说来也是有趣。本系列文章是作者硕士研究生的一个项目,如下图所示的类似于微信的随手拍程序。那期间更换了电脑并系统学习了Android开发,五年前的文章希望对你有所帮助。
- Android实例开发与学习系列:https://blog.csdn.net/eastmount/category_9263408.html

(7) C#学习系列
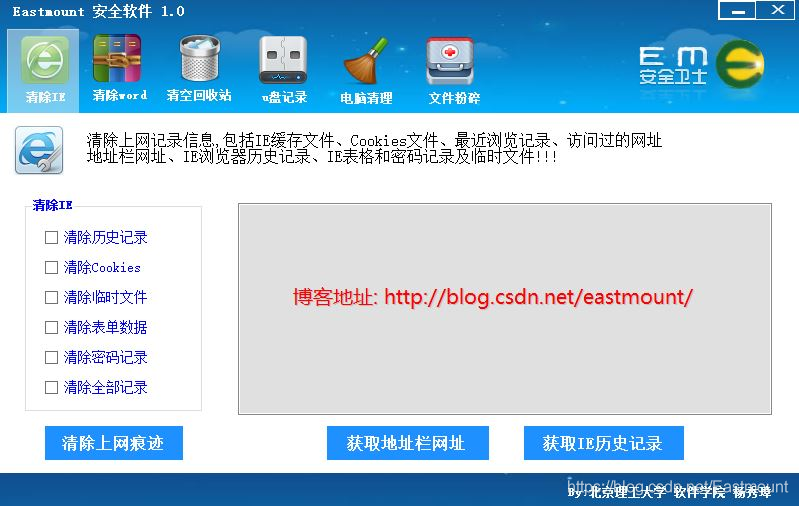
共计40余篇,共4个专栏。C#非常适合初学者入门。曾记否,在CSDN创建的最早两个专栏是《C#系统应用》和《C#网络编程》,作者的毕业设计也是采用C#设计,如下图所示的一个类似于360杀毒软件的程序,当时还是挺自豪的。C#编写窗体控件确实有它的优势,推荐初学者学习,它既能提升你的编程兴趣,又能做一些实践的项目,希望这个系列专栏对你有所帮助~
(8) C++和MFC图像处理系列
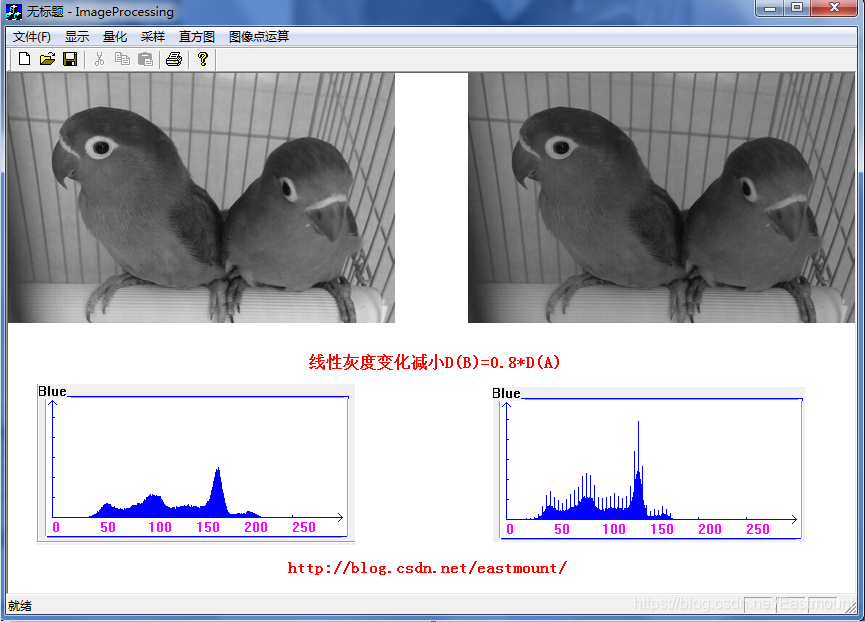
共计20余篇文章,该专栏主要是由于作者《数字图形处理》课程需要完成一个C++的图像处理软件而总结,里面的图像处理系列还是较为完整且底层的,推荐低年级的同学学习;后续又结合几个MFC项目进行了补充,最后是自己在《计算机图形学》课程中的实验,带着学生们完成。MFC是计算机相关专业学生入门的工具,同时给出Python图像处理系列最为对比,还是挺有意思的,建议一定结合实例去做,希望这些文章对你有所帮助。

(9) 网站开发系列
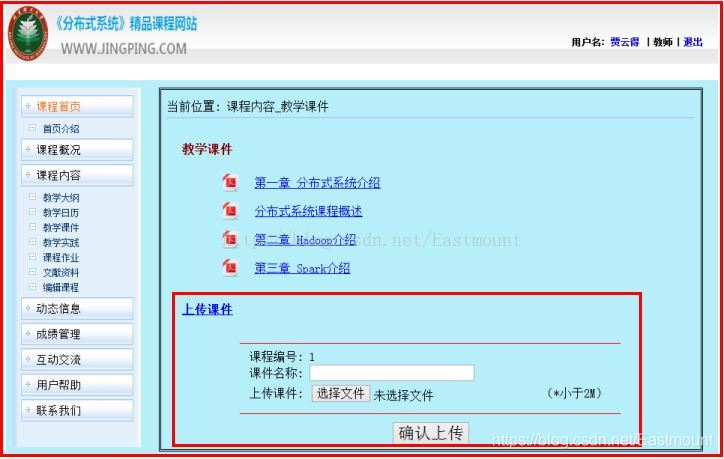
该专栏主要是作者读书和教书期间的课程作业,包括HTML基础、JAVA网站开发、PHP网站开发、Python网站开发、数据库知识等,由此可见作者确实学得很杂,更建议同学们深入学习一门语言,学精学通,并结合现在热门的框架学习,比如Spring Cloud等。希望这些基础知识对初学者有所帮助。
讲完了第一部分,接下来进入第二部分。这篇文章既然是我科研之路的开启,那么我们就从LATEX入门开始讲解。这一部分对需要撰写论文,正在学习LATEX工具的人比较适用,感兴趣的也可以简单了解下。
LaTeX是一种基于ΤΕΧ的排版系统,由美国计算机学家莱斯利·兰伯特在20世纪80年代初期开发,利用这种格式,即使使用者没有排版和程序设计的知识也可以充分发挥由TeX所提供的强大功能,能在几天、甚至几小时内生成很多具有书籍质量的印刷品。对于生成复杂表格和数学公式,这一点表现得尤为突出。因此它非常适用于生成高印刷质量的科技和数学类文档。
LaTeX的工作方式类似网页,它们都是由源文件(.tex or .html)经由引擎(TeX or browser)渲染产生最终效果,从而得到PDF文件或生成页面。两者极其神似,包括语法规则与工作方式。

安装过程推荐读者阅读TechArtisan6师傅的这篇文章:
官方下载地址如下:
- Tex Live下载地址:http://www.tug.org/texlive/
- 清华大学镜像地址:https://mirrors.tuna.tsinghua.edu.cn/CTAN/systems/texlive/Images/
- Tex studio下载地址:http://www.texstudio.org/
强烈推荐大家直接下载LaTex模块进行修改,这篇文章更多是告诉大家基本语法,安装过程请大家下来去尝试,希望对您有所帮助!

设置行号如下图所示:

LaTeX文档分为导言区和正文区(文稿区),在导言区我们可以使用documentclass命令引入一个文档类,也可以有book类、report类、letter类,其中百分号表示注释,不参与文档编译且不作为输出。在正文区用begin和end输入一个环境,如下图所示:

接着将环境的名称设置为document,一个LaTeX文件有且只能有一个document文件,添加正文内容再编译文档。

(1) 设置标题
导言区主要用于全局设置,比如文档标题、作者、日期,再通过maketitle显示标题。
% 导言区
\documentclass{article}
\title{My First Document}
\author{Eastmount}
\date{\today}
% 正文区
\begin{document}
\maketitle
Hello World!
\end{document}
显示如下图所示:

(2) 正文插入公式
如果需要在正文中插入公式,则使用美元符号,表示数学模式,如下所示:
% 导言区
\documentclass{article}
\title{My First Document}
\author{Eastmount}
\date{\today}
% 正文区
\begin{document}
\maketitle
Hello World!
Let $f(x)$ be defined by the formula $f(x)=3x^2+x-1$.
This feature is usually extracted by calling the sequence $X=\left\{ {api_1,api_2,...,api_n} \right\}$ ,
where $i \in L \bigcup U $ represents the i sample and n is the number of API functions.
\end{document}
显示如下图所示,公式后面会详细介绍,这里仅作部分说明。
- 符号^:表示上标
- 符号_:表示下标
- 符号\left{:表示左大括号
- 符号\right}:表示右大括号
- 符号\bigcup:表示并集
- 符号\in:表示属于

(3) 顶格和换行
如果我们想让它换行或定格,怎么解决呢?Latex 换行顶格、不缩进,使用的命令为:
\noindent
在顶格的段落前面加上,此命令,就可以。而“\” 表示换行,$$表示公式换行,比如:

在LaTeX中字体属性包括字体编码、字体族、字体系列、字体形状、字体大小,如下图所示。

(1) 字体族设置
罗马字体、无衬线字体、打字机字体的两种设置方式如下:
- \textrm{Roman Family} \textsf{Sans Serif Family} \texttt{Typerwriter Family}
- \rmfamily Roman Family {\sffamily Sans Serif Family} {\ttfamily Typerwriter Family}
显示结果如下图所示,括号可以限定字体的范围:
% 导言区
\documentclass{article}
\title{My First Document}
\author{Eastmount}
\date{\today}
% 正文区
\begin{document}
\maketitle
% 字体族设置(罗马字体、无衬线字体、打字机字体)
\textrm{Roman Family} \textsf{Sans Serif Family} \texttt{Typerwriter Family}
\rmfamily Roman Family {\sffamily Sans Serif Family} {\ttfamily Typerwriter Family}\\
Hello World!
% here is my big formula
\sffamily
Let $f(x)$ be defined by the formula $$f(x)=3x^2+x-1$$ which is a polynomial of degree 2.
{\ttfamily
This feature is usually extracted by calling the sequence $X=\left\{ {api_1,api_2,...,api_n} \right\}$.}
My name is Eastmount!
\end{document}
显示如下图所示:

(2) 字体系列设置
主要包括粗细、宽度。
- \textmd{Medium Series} \textbf{Boldface Series}
- {\mdseries Medium Series} {\bfseries Boldface Series}
(3) 字体形状设置
主要包括粗体、斜体、伪斜体、小型大写。
- \textup{Upright Shape} \textit{Italic Shape} \textsl{Slanted Shape} \textsc{Small Caps Shape}
- {\upshape Upright Shape} {\itshape Italic Shape} {\slshape Slanted Shape} {\scshape Small Caps Shape}

(4) 中文字体设置
需要使用ctex包才能调用,在进行相关字体设置。
% 导言区
\documentclass{article}
\usepackage{ctex}
\title{My First Document}
\author{Eastmount}
\date{\today}
% 正文区
\begin{document}
\maketitle
% 字体族设置(罗马字体、无衬线字体、打字机字体)
\textrm{Roman Family} \textsf{Sans Serif Family} \texttt{Typerwriter Family}
\rmfamily Roman Family {\sffamily Sans Serif Family} {\ttfamily Typerwriter Family}\\
% 字体系列设置(粗细、宽度)
\textmd{Medium Series} \textbf{Boldface Series}
{\mdseries Medium Series} {\bfseries Boldface Series}\\
% 字体形状设置
\textup{Upright Shape} \textit{Italic Shape}
\textsl{Slanted Shape} \textsc{Small Caps Shape}
{\upshape Upright Shape} {\itshape Italic Shape}
{\slshape Slanted Shape} {\scshape Small Caps Shape}
% 中文字体
{\songti 宋体} \quad {\heiti 黑体} \quad {\fangsong 仿宋} \quad {\kaishu 楷书}\\
中文字体的\textbf{粗体}与\textit{斜体}、\underline{下换线}\\
Hello World!
% here is my big formula
\sffamily
Let $f(x)$ be defined by the formula $$f(x)=3x^2+x-1$$ which is a polynomial of degree 2.
{\ttfamily
This feature is usually extracted by calling the sequence $X=\left\{ {api_1,api_2,...,api_n} \right\}$.}
My name is Eastmount!
\end{document}
显示如下图所示:

注意,如果你的中文显示是乱码,则需要进行下面的设置,并且调用\usepackage{ctex}包即可。
设置默认编辑器为xelatex,编辑器默认字体为UTF-8。

(5) 字体大小设置
推荐大家阅读官方帮助文档,查看具体细节。
% 字体大小设置 相对大小
{\tiny Hello}\\
{\scriptsize Hello}\\
{\footnotesize Hello}\\
{\small Hello}\\
{\normalsize Hello}\\
{\large Hello}\\
{\Large Hello}\\
{\LARGE Hello}\\
{\huge Hello}\\
{\Huge Hello}\\
%文档大小
\documentclass[12pt]{article}
% 中文字体大小
\zihao{3} 你好!
需要注意的是,LaTeX建议大家使用newcommand命令定义一个新的命令,以执行字体设置操作,比如:
- \newcommand{\myfont}{\textit{\textbf{\textsf{Font Text}}}}

学术论文通常包括两种结构,如下图所示,左边表示理论型,右边表示实验型。

在LaTeX中我们可以通过section定义小结,也可以用subsection定义子小结。同时更推荐大家下载IEEE结构进行修改,后面我也会讲到。
- \section{Section title}
- \label{sec:mysection}
- \subsection{title}
- \subsubsection{title}
- \section*{} unnumbered section
- \appendix
举个示例:
% 导言区
\documentclass{article}
\usepackage{ctex}
\title{My First Document}
\author{Eastmount}
\date{\today}
% 正文区
\begin{document}
\maketitle
% 构建文章小结
\section{Introduction}
\section{Related Work}
\section{System Model}
\section{Mathematics and algorithms}
\section{Experiments}
\subsection{Datasets}
\subsubsection{实验条件}
\subsubsection{评价指标}
\subsection{Results}
\section{Acknowledgment}
\end{document}

我们还可以使用ctexset命令定义不同标题的格式,如下图所示,具体详情推荐大家阅读官方文档。

在LaTeX中插入图片的基本语法如下:
- 导言区插入:\usepackage{graphicx}
- 语法:\includegraphics[ < 选项 > ] { < 文件名 > }
- 格式:EPS、PDF、PNG、JPEG、BMP

下面举例说明:
% 导言区
\documentclass{article}
\usepackage{ctex}
\usepackage{graphicx}
% 指定图片在当前目录下figures目录下
\graphicspath{{figures/}}
% 正文区
\begin{document}
% 插入图片
\includegraphics{fig1}
% 缩放比例
\includegraphics[scale=0.5]{fig1}
% 固定图像高度
\includegraphics[height=2cm]{fig1.png}
% 固定图像宽度
\includegraphics[width=2cm]{fig1.png}
% 图像高度和宽度基于
\includegraphics[height=0.2\textheight]{fig1.png}
\includegraphics[width=0.2\textwidth]{fig1.png}
% 指定多个参数
\includegraphics[angle=-45,width=0.5\textwidth]{fig1.png}
\end{document}
显示结果如下图所示,scale=0.5是将图片大小缩小为真实大小的一半,[width=0.2\textwidth] 将图形缩放到文本的0.2倍。

横跨两栏
注意,在论文中通常会遇到要横跨两栏的应用场景,此时我们需要这样设置:
- \begin{figure*}
- \end{figure*}
\usepackage{stfloats}
\begin{figure*}[ht]
\centering
\includegraphics[width=0.80\textwidth]{fig4.png}
\caption{Framework of traceability of malicious code attack based on knowledge graph.}
\label{fig4}
\end{figure*}
上面代码中,figure* 表示跨双栏,htbp表示的意思是latex会尽量满足排在前面的浮动格式,就是h-t-b-p这个顺序,让排版的效果尽量好。其中,h-here,表示在此处;t-top,表示在顶部,b-bottom,表示底部,p-page,表示在本页。为了防止跨页图片跑到最后一页,我们需要在导言区加入stfloats包,然后设置\begin{figure*}[ht] 即可。

(2) 双图显示
其核心代码如下:
\usepackage{caption}
\usepackage{subfigure}
\begin{figure}[htbp]
\centering %居中
\subfigure[name of the first figure] %第一张子图
{
\begin{minipage}[t]{0.4\textwidth}
\centering
\includegraphics[scale=0.15]{fig2}
\end{minipage}
}
\subfigure[name of the second figure] %第二张子图
{
\begin{minipage}[t]{0.4\textwidth}
\centering
\includegraphics[scale=0.2]{fig3}
\end{minipage}
}
\caption{name of the figure} %大图名称
\label{fig-1} %图片引用标记
\end{figure}
显示如下图所示:

在LaTeX中使用tabular生成表格,插入时需要设置对齐方式(l-左对齐、c-居中对齐、r-右对齐),然后插入数据,其中&用于分割每列,\\用于换行。
% 导言区
\documentclass{article}
\usepackage{ctex}
% 正文区
\begin{document}
\begin{tabular}{l c c c r} % 左 居中 右对齐
A & B & C & D & E \\
11 & 12 & 13 & 14 & 15 \\
21 & 22 & 23 & 24 & 25 \\
\end{tabular}
\end{document}
显示结果如下图所示:
 )
)
然后通过 | 插入表格竖线,通过 \hline命令插入表格横线,也可以插入双线。如下图所示:
 )
)
(1) 三线表
下面的代码展示常见的三线表。
\begin{table}
\caption{Symbol Table}
\centering
\begin{tabular}{lll}
\hline
Symbol & Definition & Unitis\\
\noalign{\global\arrayrulewidth1pt}\hline\noalign{\global\arrayrulewidth0.4pt}
\multicolumn{3}{c}{\textbf{Constants}}\\
$\lambda$ & Mean of Poisson distribution & unitless\\
$p_{slow}$ & Probability that a vehicle slows down randomly & unitless\\
\hline
\end{tabular}
\end{table}
显示如下图所示:

(2) 跨栏显示表格
在双栏论文中,只需要多加一个星号即可设置跨栏显示,代码如下:
\begin{table*}[htbp]
\caption{The evolution and influence of PC Malware}
\centering
\begin{center}
\begin{tabular}{lllll}
\hline
Period & Malware & Type & Damage & Characteristics\\
\hline
1971 & Creeper & Normal software & experiment & can move between computers\\
1971 & Creeper & Normal software & experiment & can move between computers\\
\hline
\end{tabular}
\label{tab1}
\end{center}
\end{table*}
显示如下图所示:

(3) 表格内容自动换行及首行居中
当我们指定表格宽度时,它就会产生自动换行的效果,如使用p{3cm}参数,指的是当该单元格超出3cm的时候自动换行。辅助命令 \makebox[4cm][c]{Traceability Method} 用于设置居中。
\begin{table*}[htbp]
\caption{Common Malicious Code Tracing Method in Industry}
\centering
\begin{center}
\begin{tabular}{cp{10cm}}
\hline
\makebox[4cm][c]{Traceability Method} & \makebox[10cm][c]{Traceability Target}\\
\hline
Domain Name/IP & Analyze the domain name and IP address used by the attacker, and tap the source of the attack\\
Intrusion Log & Analysis of a large number of behavioral operation logs left after an attacker invades the host, can extract relevant attacker information.\\
Attack Model & This method of tracing is mainly found in individuals or organizations with a relatively high degree of specialization. They have their own routines for attacking, and they have long focused on attacks in a field.\\
Sample Analysis & Extract sample features through static or dynamic methods, and then analyze attacker-related information.\\
\hline
\end{tabular}
\label{tab1}
\end{center}
\end{table*}
显示如下图所示:

(1) 无序序列
\begin{itemize}
\item Every sentence should make sense.
\item There is a lot to be said.
\item Eschew the highfalutin.
\end{itemize}

(2) 有序序列
\begin{enumerate}
\item Every sentence should make sense.
\item There is a lot to be said.
\item Eschew the highfalutin.
\end{enumerate}

(3) 自定义序列
\begin{description}
\item[Rule 1.] Every sentence should make sense.
\item[Rule 2.] There is a lot to be said.
\item[Rule 3.] Eschew the highfalutin.
\end{description}

序列同样可以嵌套,代码如下所示:

LaTeX中的数学模式有两种形式:inline 和 display。前者是指在正文插入行间数学公式,后者独立排列,可以有或没有编号。推荐这篇文章:试试LaTeX插入数学公式 - Nautilus_sailing
- 行内公式(inline): 用 $…$将公式括起来进行排版,也可以使用小括号和\begin{math}排版。
- 行间公式(displayed): 用 $ $…$ $ 将公式括起来是无编号的形式,还有 \ [ … \ ]的无编号独立公式形式,块间元素默认是居中显示的。
- 上标使用^符号,下表使用_符号。
- 常见数学函数包括 \log、\sin、\cos、\arcsin、\arccos、\ln、\sqrt等。
- 分数建议使用\frac{3}{4}表示3/4。
- 如果需要对公式进行自动编号,要在equation环境下进行排版,同时调用\ref直接引用。
- 各类希腊字母编辑表,常见符号如下图所示。

下面给出一个常见的公式插入案例。
% 导言区
\documentclass{article}
\usepackage{ctex}
% 正文区
\begin{document}
\section{Introduction}
At present, the popular similarity calculation methods mainly focus on the processing of set, sequence, vector, graph and other features.
Qiao [20] calculates the similarity based on sets, and uses the Jaccard coefficient method in the similarity comparison of API sets of different malicious samples.
The ratio of the intersection of the two sets of A and B in the union set is used as the similarity.
If the ratio value is larger, the proof is more similar, as shown in the formula (1).
\begin{equation}
J(A,B) = \frac{|A \bigcap B|}{|A \bigcup B|} \label{eq}
\end{equation}
\begin{equation}
a+b=\sqrt{\frac{a}{b}}\label{eq}
\end{equation}
\end{document}
显示如下图所示:

如果您正在编写包含许多复杂公式的科学文档,则amsmath包引入了几个新命令,这些命令比基本LaTeX提供的命令更强大,更灵活。
- \usepackage {amsmath}
- \usepackage {mathtools}
Stone_Stan4d老师的文章“Latex的公式输入”归纳总结了常见的符号,如下图所示:

接着给出一些示例:

注意,如果不需要编号公式,使用equation*环境。公式的编号与交叉引用是自动实现的,大家在排版中要习惯于采用自动化的方式处理诸如图、表、公式、参考文献的编号与交叉引用。
如果公式太长,怎么办呢?下面给出公式对齐的例子。其中aligned就是用来公式对齐的,在中间公式中,\ 表示换行, & 表示对齐。在公式中等号之前加&,等号介绍要换行的地方加\就可以了。
\begin{equation}
\begin{aligned}
Similarity &= \cos \theta\\
&= \frac{A·B}{||A|| ||B||}\\
&= \frac{\sum_{i=1}^{n}A_i \times B_i}{\sqrt{\sum_{i=1}^{n}A_i^2} \times \sqrt{\sum_{i=1}^{n}B_i^2}}
\end{aligned}
\label{eq}
\end{equation}
输出结果如下图所示:

接着补充矩阵输出方式,首先输\usepackage {amsmath}导入包,矩阵环境中通过&分隔列,用\\分隔行。
% 导言区
\documentclass{article}
\usepackage{ctex}
\usepackage {amsmath}
% 正文区
\begin{document}
\[
\begin{matrix}
a & b & c \\
d & e & f \\
g & h & i
\end{matrix} \qquad
% 小括号
\begin{pmatrix}
a & b & c \\
d & e & f \\
g & h & i
\end{pmatrix} \qquad
% 中括号
\begin{bmatrix}
a & b & c \\
d & e & f \\
g & h & i
\end{bmatrix} \qquad
% 大括号
\begin{Bmatrix}
a & b & c \\
d & e & f \\
g & h & i
\end{Bmatrix} \qquad
% 单竖线
\begin{vmatrix}
a & b & c \\
d & e & f \\
g & h & i
\end{vmatrix} \qquad
% 双竖线
\begin{Vmatrix}
a & b & c \\
d & e & f \\
g & h & i
\end{Vmatrix} \qquad
\]
\end{document}
显示结果如下图所示:

其他示例如下所示:
$$
A_{m,n} =
\begin{pmatrix}
a_{1,1} & a_{1,2} & \cdots & a_{1,n} \\
a_{2,1} & a_{2,2} & \cdots & a_{2,n} \\
\vdots & \vdots & \ddots & \vdots \\
a_{m,1} & a_{m,2} & \cdots & a_{m,n}
\end{pmatrix}
$$
$$
M = \begin{bmatrix}
\frac{5}{6} & \frac{1}{6} & 0 \\[0.3em]
\frac{5}{6} & 0 & \frac{1}{6} \\[0.3em]
0 & \frac{5}{6} & \frac{1}{6}
\end{bmatrix}
$$
$$
M = \bordermatrix{~ & x & y \cr
A & 1 & 0 \cr
B & 0 & 1 \cr}
$$
输出如下图所示:

在矩阵中,常用省略号包括 \dots、\vdots、\ddots。用cases插入分段函数,array实现方程组,最后补充一个梯度下降公式。
$$
A = \begin{bmatrix}
a_{11} & \dots & a_{1n} \\
& \ddots & \vdots \\
0 & & a_{nn}
\end{bmatrix}_{n \times n}
$$
$$
f(n) =
\begin{cases}
n/2, & \text{if $n$ is even} \\
3n+1, & \text{if $n$ is odd}
\end{cases}
$$
$$
\left\{
\begin{array}{c}
a_1x+b_1y+c_1z=d_1 \\
a_2x+b_2y+c_2z=d_2 \\
a_3x+b_3y+c_3z=d_3
\end{array}
\right.
$$
$$
\frac{\partial J(\theta)}{\partial\theta_j}=-\frac1m\sum_{i=0}^m(y^i-h_\theta(x^i))x^i_j
$$
显示结果如下图所示:

如果需要将多个公式写在一起,则使用gather关键字。
\begin{gather}
a + b = b + a \\
a + b + c = 0 \\
a^2 + b^2 = 1
\end{gather}
显示如下图所示:
LaTeX插入参考文献,可以使用BibTex,也可以不使用BibTex。参考文章:Latex技巧
\begin{thebibliography}{99}
\bibitem{ref1}Zheng L, Wang S, Tian L, et al., Query-adaptive late fusion for image search and person re-identification, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015: 1741-1750.
\bibitem{ref2}Arandjelović R, Zisserman A, Three things everyone should know to improve object retrieval, Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on, IEEE, 2012: 2911-2918.
\bibitem{ref3}Lowe D G. Distinctive image features from scale-invariant keypoints, International journal of computer vision, 2004, 60(2): 91-110.
\bibitem{ref4}Philbin J, Chum O, Isard M, et al. Lost in quantization: Improving particular object retrieval in large scale image databases, Computer Vision and Pattern Recognition, 2008. CVPR 2008, IEEE Conference on, IEEE, 2008: 1-8.
\end{thebibliography}
上面列出了5个参考文献,{thebibliography}的选项99指的是参考文献的个数最大为99,可以设置为别的数。在正文中引用参考文献的方法是:\cite{ref1}、\cite{ref1, ref5}。

BibTeX 是一种格式和一个程序,用于协调LaTeX的参考文献处理。

LaTex写论文非常推荐大家去下载模板来进行修改,常见的IEEE模块如下:
\documentclass[conference]{IEEEtran}
\IEEEoverridecommandlockouts
% The preceding line is only needed to identify funding in the first footnote. If that is unneeded, please comment it out.
\usepackage{cite}
\usepackage{amsmath,amssymb,amsfonts}
\usepackage{algorithmic}
\usepackage{graphicx}
\usepackage{stfloats}
\usepackage{textcomp}
\usepackage{xcolor}
\def\BibTeX{{\rm B\kern-.05em{\sc i\kern-.025em b}\kern-.08em
T\kern-.1667em\lower.7ex\hbox{E}\kern-.125emX}}
\begin{document}
% 指定图片在当前目录下figures目录下
\graphicspath{{figures/}}
\title{A Network Attack Method Based on Knowledge Graph\\}
\author{\IEEEauthorblockN{Eastmount}
\IEEEauthorblockA{\textit{School of Network} \\
\textit{CDSN University}\\
Guiyang, China \\
20200622@xxx.edu.cn}
}
\maketitle
\begin{abstract}
The security situation in cyberspace is becoming more and more complex, and the traceability of malicious code attacks has become an important technical challenge facing the security protection system....
\end{abstract}
\begin{IEEEkeywords}
knowledge graph; network attack; CNN
\end{IEEEkeywords}
\section{Introduction}
In recent years, there have been more and more cyber security incidents and malicious code attacks, which have brought serious harm to the country....
\section{Related Work}
\subsection{Research on Attack Tracing of Malicious Code}
Malicious code traceability refers to the discovery of the source of malicious code based on the characteristics of the target malicious code, as shown in Table I.
\begin{table}[htbp]
\caption{The evolution and influence of PC Malware}
\centering
\begin{center}
\begin{tabular}{cllp{6cm}}
\hline
Period & Malware & Type\\
\hline
1971 & Creeper & normal software \\
1974 & Wabbit & normal software \\
\hline
\end{tabular}
\label{tab1}
\end{center}
\end{table}
The evolution of malware is divided into three stages, which are as follows:
\begin{itemize}
\item The first stage is from 1971 to 1999...
\item The second stage is from 2000 to 2008....
\end{itemize}
\subsection{Malicious Code Detection in Academia}
The process relationship between each stage is shown in Fig.1.
\begin{figure}[htbp]
\centering
\includegraphics[width=0.40\textwidth]{fig1.png}
\caption{The system model of Malicious code traceability.}
\label{fig1}
\end{figure}
\noindent
\textbf{Feature Extraction.} Feature extraction is the basis of the traceability analysis process...
\noindent
\textbf{Feature Preprocessing.} If the ratio value is larger, the proof is more similar, as shown in the formula (1).
\begin{equation}
J(A,B) = \frac{|A \bigcap B|}{|A \bigcup B|} \label{eq}
\end{equation}
The feature extraction process will encounter unrepresentative and non-quantifiable original features.
\section{System Model}
To make up for the shortcomings of traditional malicious code attack source tracing based on single organization and attack chain...
\subsection{Research Framework}\label{RF}
The purpose of this paper is to trace the hacker organization and the author behind the malicious code..
\subsection{Feature Extraction}
\section{Experiments}
\subsection{Datasets and evaluation indicators}
\subsection{Attack Traceability Simulation Experiment}
\section{Results}
\section*{Acknowledgment}
\begin{thebibliography}{3}
\bibitem{b1} Jiang JG, Wang JZ and Kong B, ``A summary of research on traceability of network attack source'', Journal of Information Security, vol.3, no.1, pp.111--131, 2018.
\bibitem{b2} Liu J, Su PR and Yang M, ``Overview of Software and Network Security Research'', Journal of Software, vol.29, no.1, pp.42--68, 2018.
\bibitem{b3} He R, ChenZG and Pu S, ``Research on Multi-Source Network Attack Tracing and Tracing Technology'', Communication Technology, vol.46, no.12, pp.77--81, 2013.
\end{thebibliography}
\end{document}
运行结果如下图所示:

人生路上,不应该只有编程,陪伴心爱之人、做喜欢的事也是非常有意义的。
如今梦醒已三年。
回廊清风抚白发,
一笑弥新已三年。
愿我等即使须发皆白,仍是少年!

最后,真诚地感谢很多读者和CSDN与我携手走过了这八年,陪伴着我成长。也让我认识到无数优秀的人都值得我去学习和请教,程序员更应该知道天外有天,人外有人,希望未来能继续分享文章,静下心来写点博客和论文,做点项目和实践。每当看到文章对你有帮助,就是对秀璋最好的回报,科研论文也希望您的督促。且看且珍惜,共勉~

希望能与大家一起在华为云社区共同成长。原文地址:https://blog.csdn.net/Eastmount/article/details/106886194
(By:Eastmount 2021-09-22 晚上12点写于武汉 )

- 点赞
- 收藏
- 关注作者
评论(0)