数据湖(三):Hudi概念术语


大数据联盟地址:https://bbs.csdn.net/forums/lanson
文章目录
1、Copy On Write - COW
2、Merge On Read - MOR
Hudi概念术语
一、Timeline
Hudi数据湖可以维护很多张表,与Hive类似,数据存储在HDFS不同的目录结构中。Hudi维护了表在不同时刻执行的所有操作的Timeline,这有助于提供表的瞬时视图。
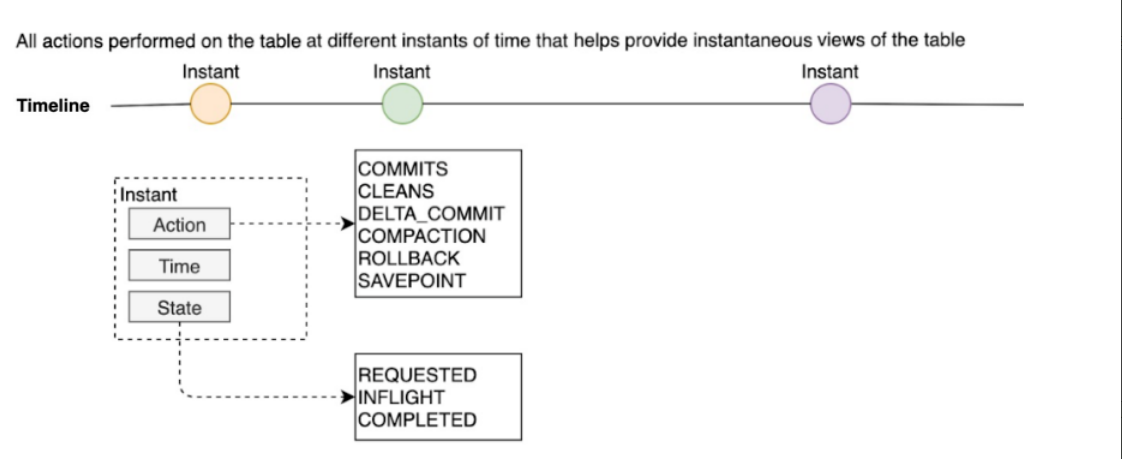
Timeline 是 HUDI 用来管理提交(commit)的抽象,每个 commit 都绑定一个固定时间戳,分散到时间线上。在Timeline上,每个commit被抽象为一个 HoodieInstant(Hoodie瞬时时刻),一个 instant 记录了一次提交(commit)的行为、时间戳、和状态,也就是说每个HoodieInstant 包含Action、Time、State三个部分,下面介绍每个HoodieInstant对应的这三个部分。
- Instant Action
Instant Action指的是对Hudi表执行的操作类型,目前包括COMMITS、CLEANS、DELTA_COMMIT、COMPACTION、ROLLBACK、SAVEPOINT这6种操作类型。
1)Commits:表示一批记录原子性的写入到一张表中。
2)Cleans:清除表中不再需要的旧版本文件。
3)Delta_commit:增量提交指的是将一批记录原子地写入MergeOnRead类型表,其中一些/所有数据都可以写入增量日志。
4)Compaction:将行式文件转化为列式文件。
5)Rollback:Commits或者Delta_commit执行不成功时回滚数据,删除期间产生的任意文件。
6)Savepoint:将文件组标记为“saved”,cleans执行时不会删除对应的数据。
- Instant Time
Instant Time表示一个时间戳,这个时间戳必须是按照Instant Action开始执行的时间顺序单调递增的。
- Instant State
Instant State表示在指定的时间点(Instant Time)对Hudi表执行操作(Instant Action)后,表所处的状态,目前包括REQUESTED(已调度但未初始化)、INFLIGHT(当前正在执行)、COMPLETED(操作执行完成)这3种状态。
HUDI的读写API通过Timeline的接口可以方便的在commits上进行条件筛选,对 history和on-going的commit应用各种策略,快速筛选出需要操作的目标commit。
下面结合官网中给出的例子理解下Timeline,例子场景是,在10:00~10:20之间,要对一个Hudi表执行Upsert操作,操作的频率大约是5分钟执行一次,每次操作执行完成,会看到对应这个Hudi表的Timeline上,有一系列的Commit元数据生成。当满足一定条件时,会在指定的时刻对这些COMMIT进行CLEANS和COMPACTION操作,这两个操作都是在后台完成,其中在10:05之后执行了一次CLEANS操作,10:10之后执行了一次COMPACTION操作。
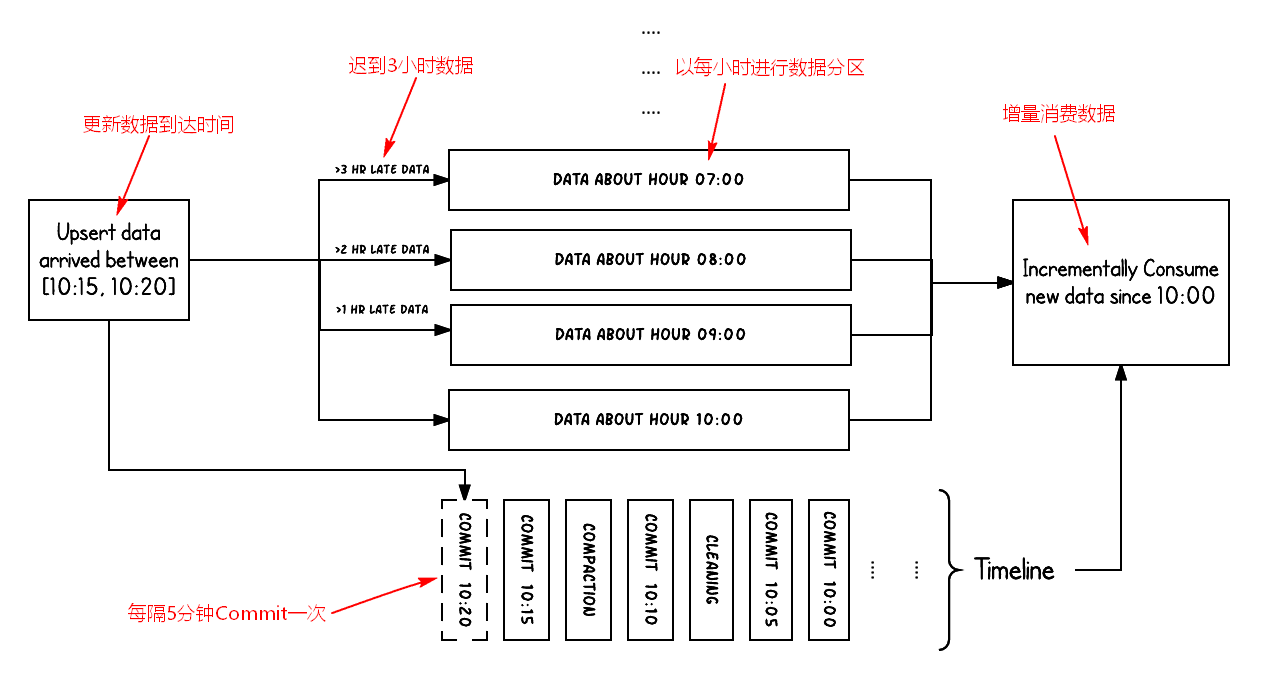 我们看到,从数据生成到最终到达Hudi系统,可能存在延迟,如上图数据大约在07:00、08:00、09:00时生成,数据到达大约延迟了分别3、2、1小时多,最终生成COMMIT的时间才是Upsert的时间。通过使用Timeline来管理,当增量查询10:00之后的最新数据时,可以非常高效的找到10:00之后发生过更新的文件,而不必根据延迟时间再去扫描更早时间的文件,比如这里,就不需要扫描7:00、8:00或9:00这些时刻对应的文件(Buckets)。
我们看到,从数据生成到最终到达Hudi系统,可能存在延迟,如上图数据大约在07:00、08:00、09:00时生成,数据到达大约延迟了分别3、2、1小时多,最终生成COMMIT的时间才是Upsert的时间。通过使用Timeline来管理,当增量查询10:00之后的最新数据时,可以非常高效的找到10:00之后发生过更新的文件,而不必根据延迟时间再去扫描更早时间的文件,比如这里,就不需要扫描7:00、8:00或9:00这些时刻对应的文件(Buckets)。
二、文件格式及索引
Hudi将表组织成HDFS上某个指定目录(basepath)下的目录结构,表被分成多个分区,分区是以目录的形式存在,每个目录下面会存在属于该分区的多个文件,类似Hive表,每个Hudi表分区通过一个分区路径(partitionpath)来唯一标识。
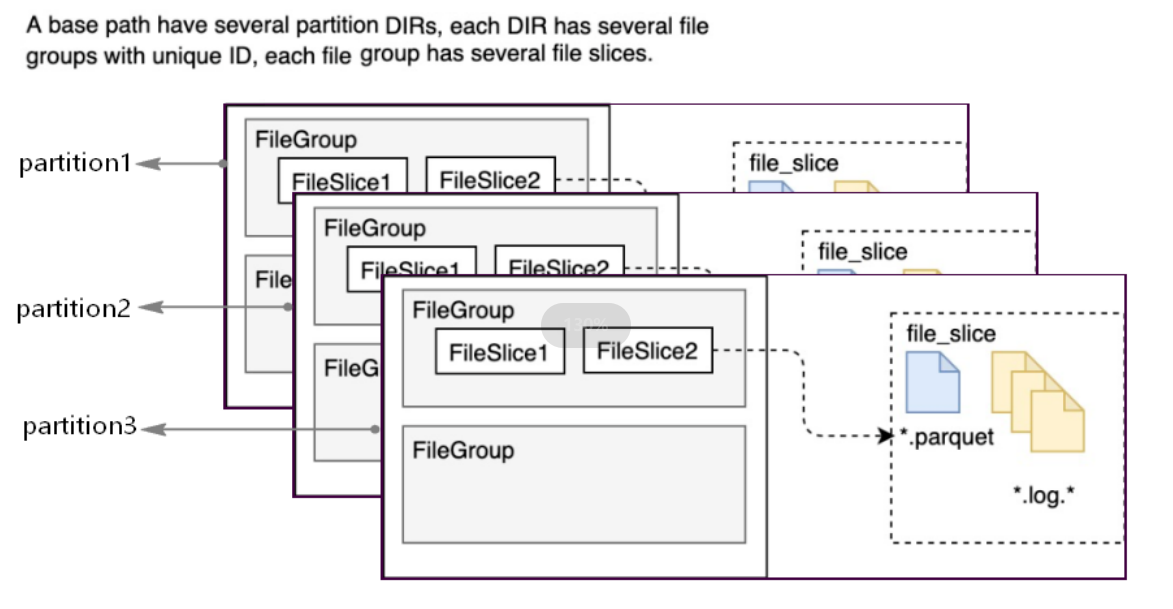
在每个分区下面,通过文件分组(file groups)的方式来组织,每个分组对应一个唯一的文件ID。每个文件分组中包含多个文件分片(file slices)(一个新的 base commit time 对应一个新的文件分片,实际就是一个新的数据版本),每个文件分片包含一个Base文件(*.parquet),这个文件是在执行COMMIT/COMPACTION操作的时候生成的,同时还生成了几个日志文件(*.log.*),日志文件中包含了从该Base文件生成以后执行的插入/更新操作。
Hudi采用MVCC设计,当执行COMPACTION操作时,会合并日志文件和Base文件,生成新的文件分片。CLEANS操作会清理掉不用的/旧的文件分片,释放存储空间。
Hudi会通过记录Key与分区Path组成Hoodie Key,即Record Key+Partition Path,通过将Hoodie Key映射到前面提到的文件ID,具体其实是映射到file_group/file_id,这就是Hudi的索引。一旦记录的第一个版本被写入文件中,对应的Hoodie Key就不会再改变了。
HUDI的Base file(parquet 文件)在根目录中的”.hoodie_partition_metadata”去记录了record key组成的 BloomFilter,用于在 file based index 的实现中实现高效率的key contains检测,决定数据是新增还是更新。
三、表类型
Hudi提供了两种表格式,Copy On Write Table (COW)和Merge On Read Table(MOR),他们会在数据的写入和查询性能上有所不同。
1、Copy On Write - COW
Copy On Write简称COW,在数据写入的时候,复制一份原来的拷贝,在其基础上添加新数据,生成一个新的持有base file (*.parquet,对应写入的instant time)的File Slice,数据存储格式为parquet列式存储格式。用户在读取数据时,会扫描所有最新的File Slice下的base file。
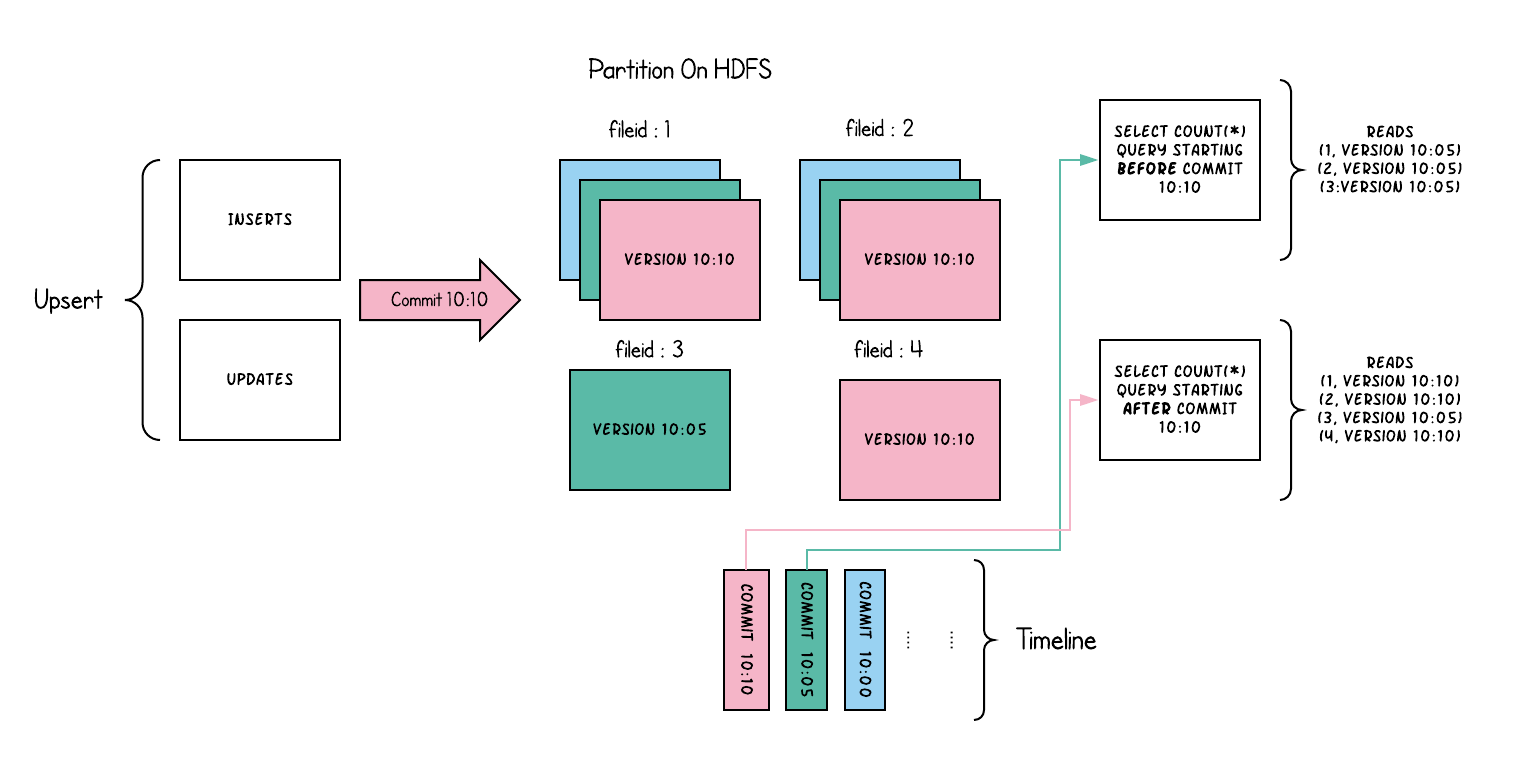
如上图,每一个颜色都包含了截至到其所在时间的所有数据。老的数据副本在超过一定的个数限制后,将被删除(hoodie.cleaner.commits.retained 参数配置,保留几个历史版本,不包含最后一个版本,默认10个)。这种类型的表,没有compact instant,因为写入时相当于已经compact了。
- 优点
读取时只需要读取对应分区的一个数据文件即可,比较高效。
- 缺点
数据写入的时候,需要复制一个先前的副本再在其基础上生成新的数据文件,这个过程比较耗时,且由于耗时,读请求读取到的数据相对就会滞后。
2、Merge On Read - MOR
Merge On Read简称MOR,使用列式存储(parquet)和行式存储(arvo)混合的方式来存储数据。更新时写入到增量(Delta)文件中,之后通过同步或异步的COMPACTION操作,生成新版本的列式格式文件。
Merge-On-Read表存在列式格式的Base文件,也存在行式格式的增量(Delta)文件,新到达的更新都会写到增量日志文件中(log文件),根据实际情况进行COMPACTION操作来将增量文件合并到Base文件上。
通过参数”hoodie.compact.inline”来开启是否一个事务完成后执行压缩操作,默认不开启。通过参数“hoodie.compact.inline.max.delta.commits”来设置提交多少次合并log文件到新的parquet文件,默认是5次。这里注意,以上两个参数都是针对每个File Slice而言。我们同样可以控制“hoodie.cleaner.commits.retained”来保存有多少parquet文件,即控制FileSlice文件个数。
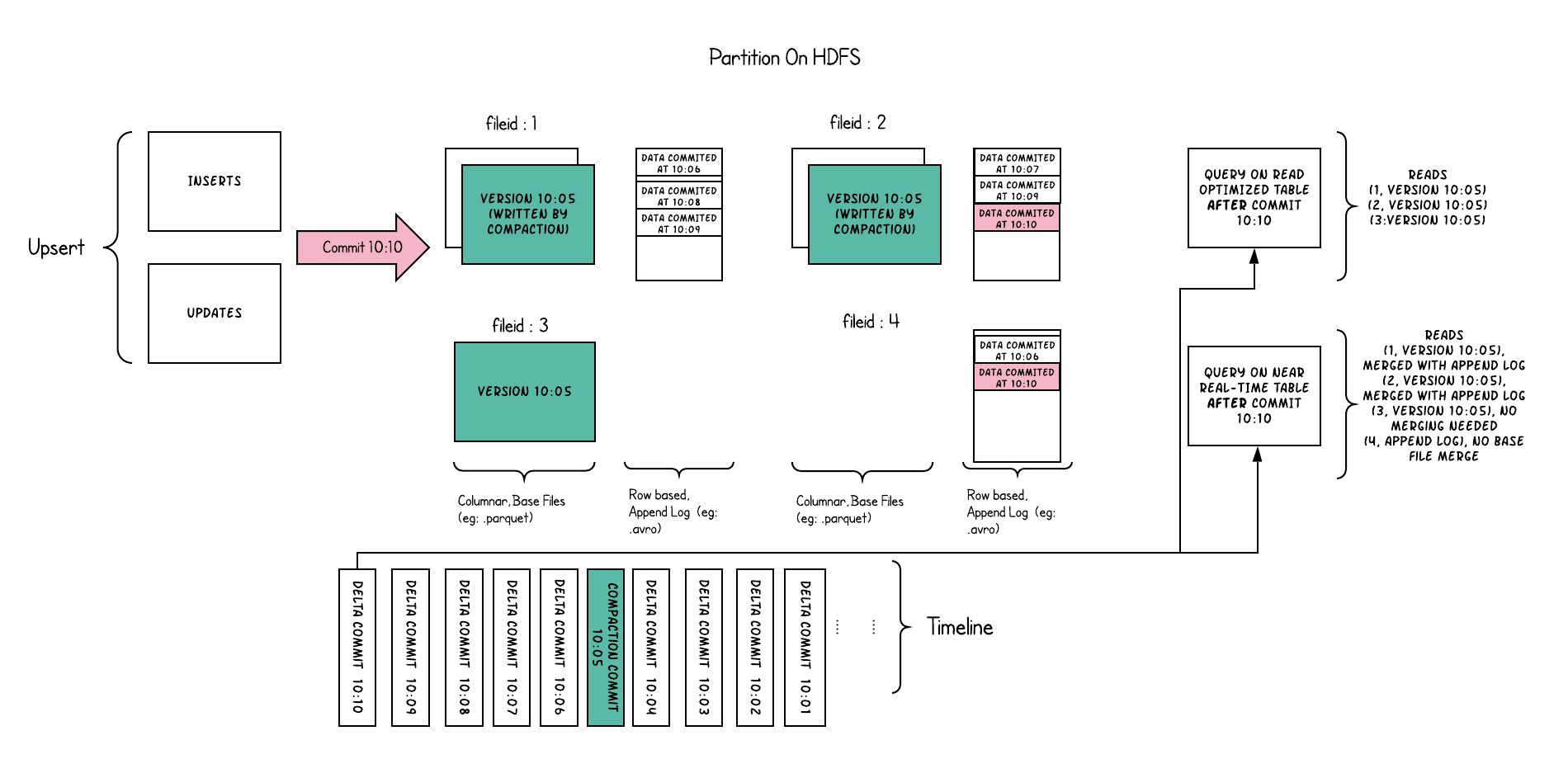
上图中,每个文件分组都对应一个增量日志文件(Delta Log File)。COMPACTION操作在后台定时执行。会把对应的增量日志文件合并到文件分组的Base文件中,生成新版本的Base文件。
对于查询10:10之后的数据的Read Optimized Query,只能查询到10:05及其之前的数据,看不到之后的数据,查询结果只包含版本为10:05、文件ID为1、2、3的文件;但是Snapshot Query是可以查询到10:05之后的数据的。
Read Optimized Query与Snapshot Query是两种不同的查询类型,后文会解释到。
- 优点
由于写入数据先写delta log,且delta log较小,所以写入成本较低。
- 缺点
需要定期合并整理compact,否则碎片文件较多。读取性能较差,因为需要将delta log 和 老数据文件合并。
3、COW&MOR对比
| 对比点 |
Copy On Write |
Merge On Read |
| 数据延迟 |
每次基于上次生成新的文件-高 |
直接写入Avro log文件-低 |
| 查询延迟 |
列式-低 |
列式+行式-高 |
| 更新IO |
每次基于上次生成新的文件-大 |
直接写入log文件-小 |
| 文件大小 |
单个全量使用parquet文件存储,占用空间小 |
单个全量存储使用parquet+avro格式存储,占用空间相对大 |
四、查询类型
Hudi数据查询对应三种查询类型,三种查询类型区别如下:
- Snapshot Query
读取所有Partition下每个FileGroup最新的FileSlice中的文件,Copy On Write表读Base(Parquet格式)文件,Merge On Read 表读Base(Parquet格式)文件+Log(Avro)格式文件,也就是说这种查询模式是将到当前时刻所有数据都读取出来,如果有更新数据,读取的也是更新后数据,例如:MOR模式下,读取对应的Base+Log文件就是读取当前所有数据更新后的结果数据。
- Incremantal Query
无论Hudi表模式是COW或者是MOR模式,这种模式可以查询指定时间戳后的增量数据,需要由用户指定一个时间戳。
- Read Optimized Query
这种模式只能查询列式格式Base文件中的最新数据。对于COW表模式,读取数据与Snapshot模式一样。对于MOR模式的数据,读取数据只会读取到Base文件列式数据,不会读取Log文件Avro格式数据。
- 点赞
- 收藏
- 关注作者
评论(0)