EfficientNet v2来了 更快、更小、更强

【摘要】
本文提出一种训练速度更快、参数量更少的卷积神经网络EfficientNetV2。我们采用了训练感知NAS与缩放技术对训练速度与参数量进行联合优化,NAS的搜索空间采用了新的op(比如Fused-MBConv)进行扩充。实验表明:相比其他SOTA方案,所提EfficientNetV2收敛速度更快,模型更小(6.8x)。
在训练过程中,我们可以通过逐步提升图像大...
本文提出一种训练速度更快、参数量更少的卷积神经网络EfficientNetV2。我们采用了训练感知NAS与缩放技术对训练速度与参数量进行联合优化,NAS的搜索空间采用了新的op(比如Fused-MBConv)进行扩充。实验表明:相比其他SOTA方案,所提EfficientNetV2收敛速度更快,模型更小(6.8x)。
在训练过程中,我们可以通过逐步提升图像大小得到加速,但通常会造成性能掉点。为补偿该性能损失,我们提出了一种改进版的渐进学习方式,它自适应的根据图像大小调整正则化因子,比如dropout、数据增广。
受益于渐进学习方式,所提EfficientNetV2在CIFAR/Cars/Flowers数据集上显著优于其他模型;通过在ImageNet21K数据集上预训练,所提模型在ImageNet上达到了87.3%的top1精度,以2.0%精度优于ViT,且训练速度更快(5x-11x)。
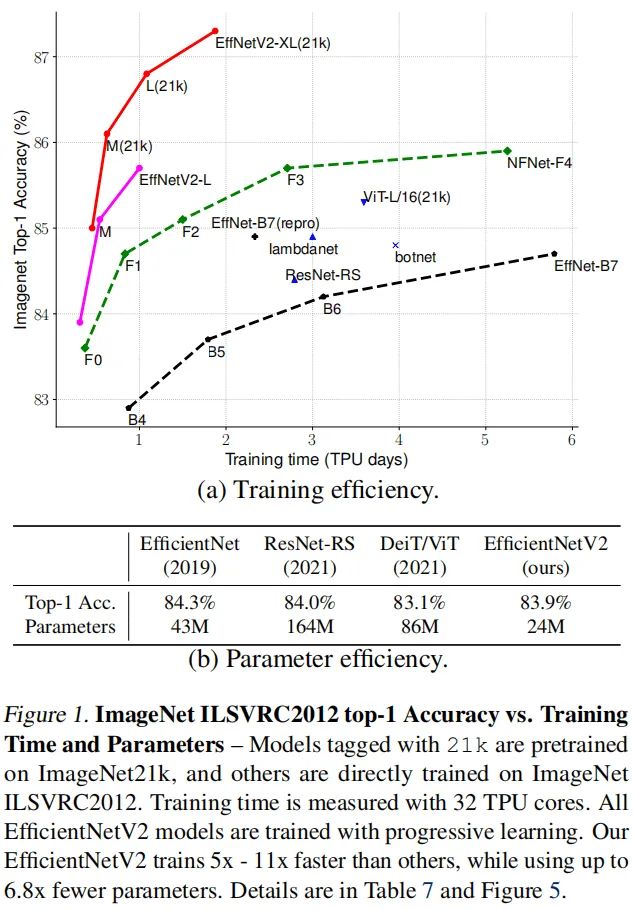
在正式介绍EfficientNetV2之前,我们先简单看一下EfficientNet;然后引出训练感知NAS与缩放,以及所提EfficientNetV2.
Understanding Training Efficiency
-
Training with very large image sizes is slow。已有研究表明:EfficientNet的大图像尺寸会导致显著的内存占用。由于GPU/TPU的总内存是固定的,我们
文章来源: blog.csdn.net,作者:网奇,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/jacke121/article/details/117000740
【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com

- 点赞
- 收藏
- 关注作者
评论(0)