医学知识图谱之关系预测模型

【摘要】 1. 知识图谱举例1.1 疾病知识图谱1.2 药物知识图谱2.常见知识图谱关系预测算法KGs能够以机器可读的方式对结构化、复杂的数据进行建模,因此它被广泛应用于各个领域如问答、信息检索、基于内容的推荐系统等。KG对于任何语义web项目都非常重要。但由于信息缺失导致的KG不完整,常常使得一些KG表现力较差。1.边预测目的:预测出一个三元组( h , r , t )缺失的头实体 h ,尾实体 t...
1. 知识图谱举例
1.1 疾病知识图谱

1.2 药物知识图谱
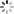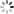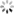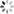

2.常见知识图谱关系预测算法

KGs能够以机器可读的方式对结构化、复杂的数据进行建模,因此它被广泛应用于各个领域如问答、信息检索、基于内容的推荐系统等。KG对于任何语义web项目都非常重要。但由于信息缺失导致的KG不完整,常常使得一些KG表现力较差。
1.边预测目的:预测出一个三元组( h , r , t )缺失的头实体 h ,尾实体 t 或者关系 r 。
2.边预测有助于更好地构建、表示、补全、应用知识图谱。
2.1 关系预测模型梳理

每个模型侧重点不一样,都有各自的缺陷,如:
①TransE:只适合处理一对一关系,一对多,多对一表现力差;
②TransR:同一关系下,头尾实体共享投影矩阵;
③DistMult:将关系表示为对角阵,只能处理对称关系;
2.2 预测算法公式

基于h, r, t简单组合的缺点
①实际的实体和关系更为复杂,简单的h、r、t之间的组合不能有效地表达知识。
②不同场景下适用的模型区别很大,无法有效率地得知当前场景下适用的模型,模型选取和调参过程费时费力;
3. DeepKG中关系预测模型的优势
过程
1.先将知识图谱特征化,把实体和关系通过embedding转化成向量作为模型的初始输入。
2.通过模型集成模块融合多个经典KGE模型作为基,将实体和关系分别输入各个基模型进行h,r,t的不同转化运算。
3.设置一组可学习的采样概率π,作为每个候选模型的采样概率,通过Gumbel-Softmax进行计算得到模型对应的权重。
4.将模型权重与其对应的候选模型的评分函数相乘,作为该候选模型的评分,而本次采样的评分则为所有候选模型评分之和。
5.对步骤3和4重复执行M次,并将多次采样得到的评分求均值,即可求得融合模型的最终评分。
特点
- 传统的知识图谱嵌入模型都是通过h、r、t之间关系的简单建模实现,单个模型应用场景有限;AutoTransX可融合多种经典知识图谱嵌入模型,集成了各模型在不同场景下的优势;
-
训练过程可微分,在训练参数的同时自动搜索模型结构,能针对不同数据动态调整,灵活选出适用于当前任务的最优模型结构,提升性能。
- 用Gumbel-Softmax替代传统的Softmax,多次Gumbel分布采样引入随机性和探索度,避免在训练过程中陷入局部最优解,结果更鲁棒
【版权声明】本文为华为云社区用户原创内容,转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息, 否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)