NVIDIA GPU SM和CUDA编程理解

SM硬件架构基础
不同架构的变化可以参考:
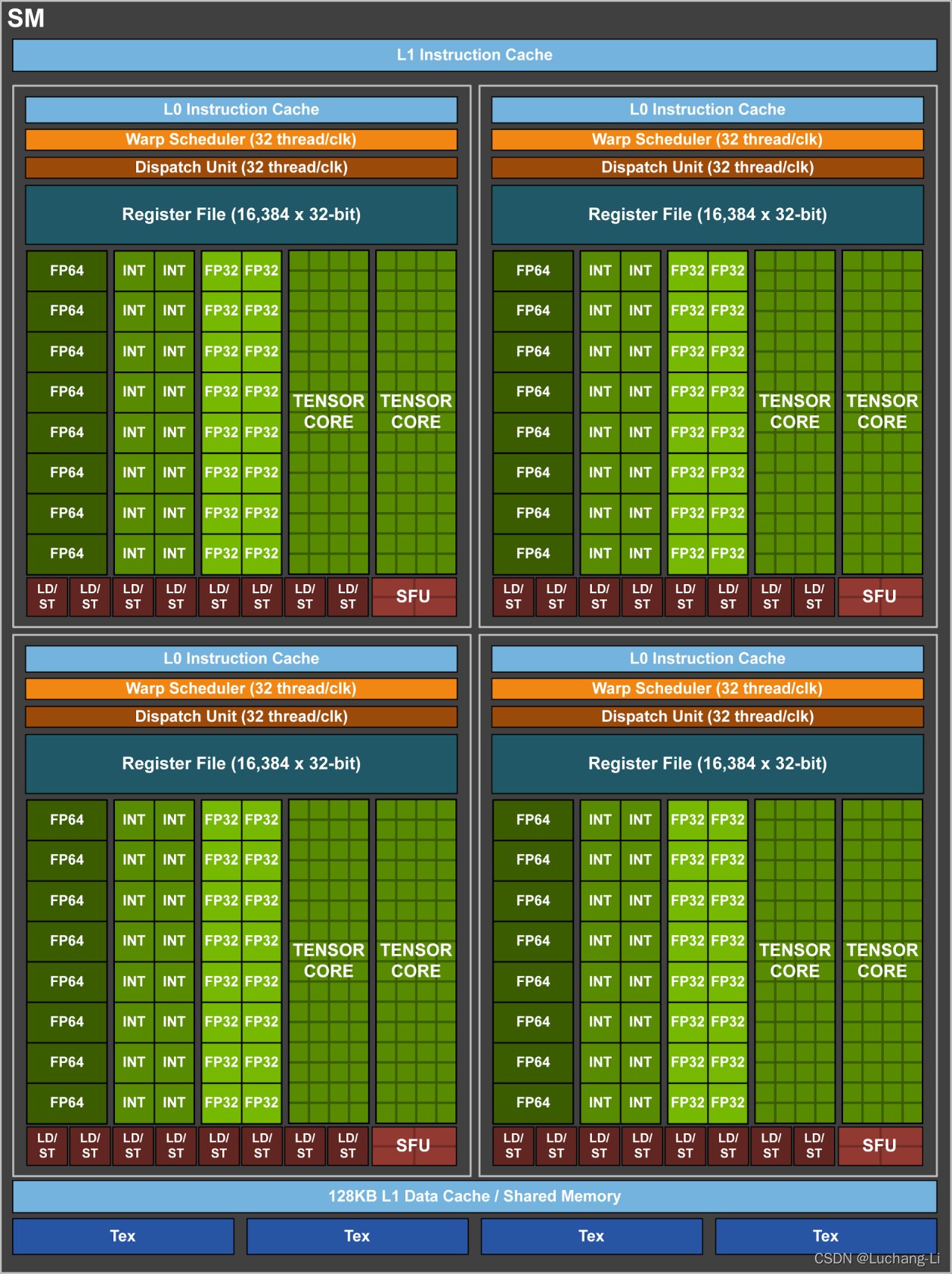
Volta GV100 Streaming Multiprocessor (SM)

![]() GA100 Streaming Multiprocessor (SM)
GA100 Streaming Multiprocessor (SM)
![]() GA102 Streaming Multiprocessor (SM)
GA102 Streaming Multiprocessor (SM)
上面展示了几个不同架构SM的区别,需要注意一些比较显著的异同点:
每个SM分成了4个子块,注意哪些部分是这4个子块共享的,哪些是这4个子块独立的。
比如shared mem和L1 cache是整个SM4个子块共享的,而register file, cuda core等是每个子块独立的。这些对CUDA编程实践和理解是有指导作用的。
注意每个子块的cuda core个数,比如GV100 GA100每个子块有16个INT32和FP32 cuda core,8个FP64 cuda core,4个SFU,而GA102没有FP64 cuda core。最新的hopper架构每个子块不是16个而是32个FP32 cuda core。
注意每个子块TensorCore的数量以及他们的具体参数规格。
CUDA SIMT编程模型基础
需要弄清的几个问题:
CUDA core的含义与线程的关系?
warp,线程块与SM的关系?
不同warp切换理解?
CPU编程写的程序一般是单线程串行执行的。在 SIMD(单指令多数据)中,一条指令同时适用于许多数据元素。而Nvidia GPU 采用SIMT(单指令多线程)模式进行并行计算。
我们首先需要写一个kernel函数,最后会创建出成千上万的线程,每个线程独立执行相同的kernel指令,但是处理不同的数据:


虽然每个线程执行相同的指令,但是所有的线程是按照block和grid两个层次进行管理的:
add<<<grid_size, block_size>>> (a, b, c);
每个线程块block包含几十数百个线程(一般应是32整数倍),而线程块内部的线程又是以32个线程组成为一个warp进行执行的。同时一个warp内部的32个线程是比较严格同步执行的(每个线程同一个时刻执行相同的指令)。最后多个block组成了一整个grid。
为什么这样组织是直接对应于硬件架构的:
对照前面的SM硬件架构,每个线程块所有线程是在同一个SM(包含4个子块执行的)执行的,而一个SM可以同时驻留和执行多个线程块。整个GPU一般有几十上百个SM可以执行,取决于具体硬件规格。
同时,每个warp 32个线程是在同一个SM子块内执行的,同一个线程块的多个warp可能分布在SM多个子块进行执行。
同一个子块内部的warp切换:GPU不同于CPU的一个特点是线程切换是极其迅速的。这是因为每个线程和线程块使用的资源是直接基于硬件资源保存的,而不是先把寄存器内存保存到内存,再从内存加载新线程的信息到寄存器然后再执行。这里会导致几注意点:1,SM会在当前warp处于某些等待时(比如当前warp内的线程在读取global mem,这需要数百个时钟),那这时会切换一个新的warp进行执行,从而可以显著提升硬件利用率和执行性能。2,因此虽然SM同时只能执行4个warp,但是应该有足够的warp驻留用于切换才能保证性能。每个线程块的线程数、每个SM能同时执行的线程块数量上限是可以通过CUDA提供接口进行查询的。但由于每个线程和线程块都是使用了实打实的寄存器和shared mem硬件资源,而硬件资源是有限的。因此每个线程和线程块的资源使用量决定了实际每个线程块包含的线程数和每个SM能同时执行的线程块数量。因此实际的程序要比较仔细规划每个线程块的线程数,每个线程和线程块使用的寄存器和shared mem资源,从而保证SM有足够的warp同时执行,一般应该有实际能够执行的4-8倍以上。
每个 warp 的执行上下文(程序计数器、寄存器等)在 warp 的整个生命周期内都在芯片上维护。寄存器文件、数据缓存和共享内存在线程块之间进行分区。因此,与其他上下文切换相比,在下一个时间步切换到另一个warp没有成本损失。但是可以驻留在 SM 中的预定义的最大线程块数和warp 数受到 GPU 容量的限制。This instruction can be selected from the same warp with no dependency on the last instruction, or more often an instruction of another warp. The execution time for many arithmetic instructions will take 2 clock cycles.
每个线程指令具体执行的逻辑:
CUDA程序SIMT这成千上万个线程执行跟CUDA core又是什么关系呢?
刚开始比较容易给人一种误解是好像是每个线程是在每个CUDA CORE执行的,实际并不是这样。
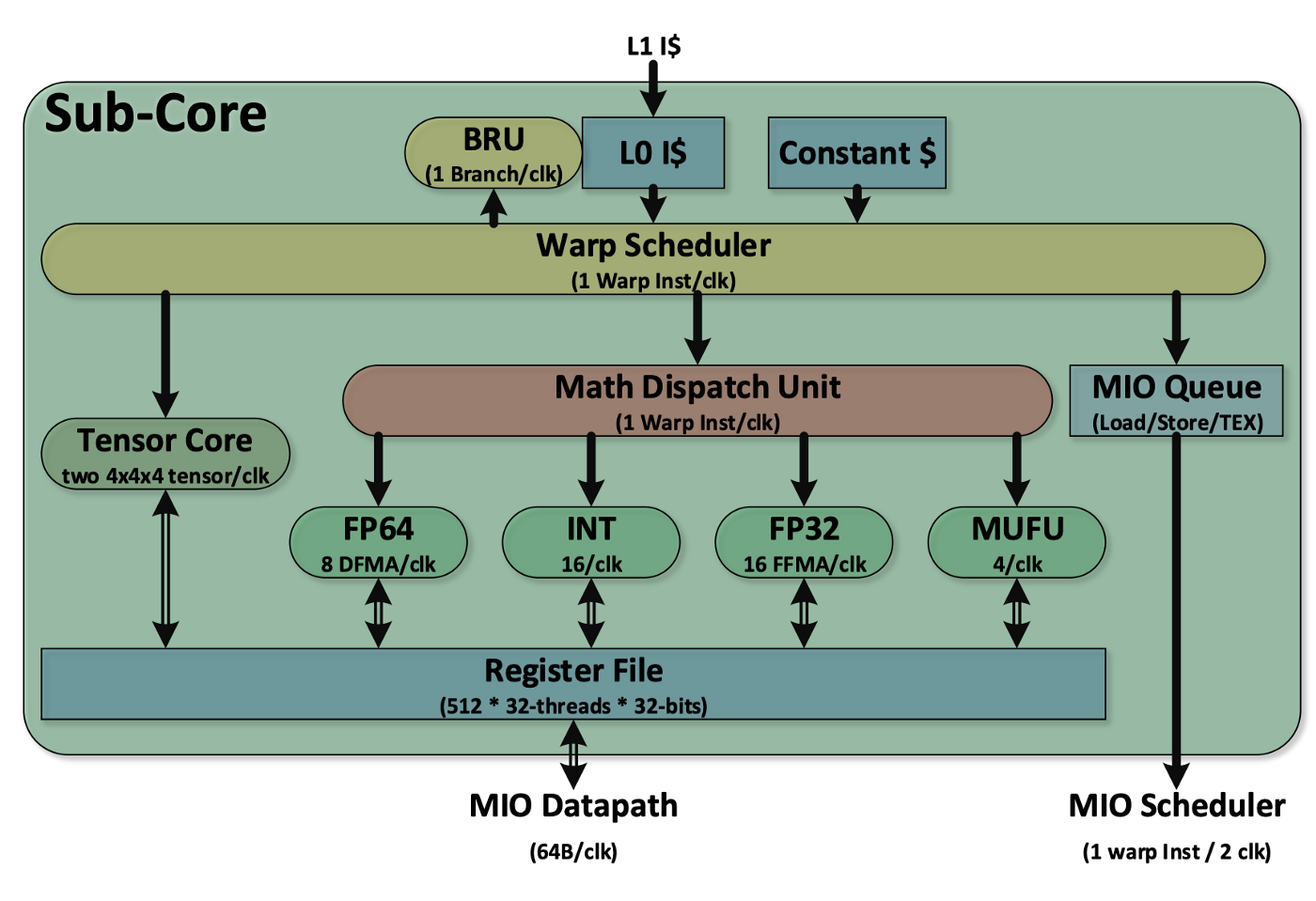
我们可以将kernel视为一系列指令。假设下一条指令是一个 INT32 操作。Nvidia GPU 将一个warp 32 个线程dispatch到 16 个 INT32 算术单元以同时执行指令(或分派到 16 个 FP32 单元以进行 FP32 操作)。
注意是把一个warp 32个线程的指令派遣到16个core,而不是32个,因为从前面SM图上可以看到每个SM子块只有16个FP32和INT32 cuda core,这也使得warp执行每条FP32/INT32指令实际需要2个时钟才能完成(hopper除外,因为它每个子块已经有32个CUDA CORE)。
同理,如果下一条指令是FP64,同一个warp 32个线程的指令需要dispatch到8个FP64 cuda core执行,因此需要更长的周期。
Fermi 中的 CUDA core同时提供 FP 和 INT 操作(时分复用),但 与 V100 和 Turing GPU 类似,Ampere 将它们分为独立的 INT32、FP32 和 FP64 单元。通过分离 FP32 和 INT32 内核,它允许并发执行 FP32 和 INT32 操作并增加指令发出吞吐量。许多应用程序的内循环都有执行指针算术(整数存储器地址计算)与浮点计算相结合的内循环,这些内循环受益于 FP32 和 INT32 指令的同时执行。流水线循环的每一次迭代都可以更新地址(INT32 指针算术),并为下一次迭代加载数据,同时在 FP32 中处理当前的迭代。
Here is another view of issuing instruction and execution in the Volta architecture in a processing block (sub-core).
CUDA程序的一些注意事项和优化点
基本原则是把GPU用满:一个SM能够同时执行多个线程块。同时一个grid应该有足够多的线程块。
一个SM能够同时执行多个线程块:
因为一个SM需要有足够多的warp才能够进行并发和切换warp保证性能。而每个SM能同时执行的warp数上限取决于这两者的最小值:
1.硬件限制和kernel参数设置(每个线程块和每个SM的线程和线程块数量是固定的可以通过接口查询的)。当资源充足大于线程和线程块使用的资源时,这时每个SM执行的warp数量受限于kernel设置的参数,比如每个线程块的线程数太少,那么由于SM同时执行的线程块数量有限,这就导致SM同时执行的线程数不够。一般一个线程块的线程数要达到128、256才能充分用满SM,这个参数可以进行调节从而找到一个最优值。
2.线程和线程块资源使用导致实际能够执行的数量限制。如果线程块的shared mem使用太多,比如一个线程块就用完了所有的shared mem的一半以上,这样一个SM最多只能执行1个线程块。为了保证一个SM能同时执行多个线程块,显然每个线程块只能用每个SM总的shared mem的几分之一。寄存器使用也是一样,寄存器使用合理时一个warp能够同时执行32个线程,同时一个子块的资源能满足同时驻留多个warp。而寄存器使用太多一个子块无法驻留多个warp,甚至极端情况一个warp的资源所有连32个线程都不够用。
一个grid应该有足够多的线程块
一个kenel是对应于一个grid,里面要有足够的线程块才能充分利用好整个GPU所有的SM。一方面一个SM本身就需要驻留多个线程块,那么整个GPU几十上百个SM用满的线程块数量应该要乘以一个比较大的倍数才够。
这里举一个深度学习中一个实际的reduce/layer_norm计算的例子,假如我们计算一个[200, 768] tensor最内部维度每一行的reduce mean,如果naive的想法每个线程计算一行那么总共的线程数才200。这样只能够生出一两个线程块,只能用上一两个SM,显然性能极差。而如果我们用一个warp来计算一行,那么就有200个warp,如果一个线程块4个warp则有50个线程块,能用上大部分SM。当然还可以使用一个线程块来计算一行,那么我们就有200个线程块,SM利用率更高。
当然这个reduce的例子存在一些其他的trade-off:因为reduce需要线程之间交换数据,使用warp计算一行时,前面提到过每个线程的寄存器是直接保存在硬件上,而同一个warp是在同一个SM子块运行的,这些子块共享寄存器文件,而不同子块共享数据最快只能通过shared mem。因此同一个warp之间不同线程交换数据可以通过warp shuffle (Warp-Level Primitives)直接交换寄存器数据,更加快速。而一个线程块计算一行需要先通过shared mem交换数据。如何平衡这个trade-off取决于任务量(每一行元素的数量)。
ampere架构的部分资源信息:
1.4.1.1. Occupancy
The maximum number of concurrent warps per SM remains the same as in Volta (i.e., 64), and other factors influencing warp occupancy are:
‣ The register file size is 64K 32-bit registers per SM.
‣ The maximum number of registers per thread is 255.
‣ The maximum number of thread blocks per SM is 32 for devices of compute capability 8.0 (i.e., A100 GPUs) and 16 for GPUs with compute capability 8.6 (GA102/104,如RTX3060等).
‣ For devices of compute capability 8.0 (i.e., A100 GPUs) shared memory capacity per SM is 164 KB, a 71% increase compared to V100's capacity of 96 KB. For GPUs with compute capability 8.6, shared memory capacity per SM is 100 KB.
‣ For devices of compute capability 8.0 (i.e., A100 GPUs) the maximum shared memory per thread block is 163 KB. For GPUs with compute capability 8.6 maximum shared memory per thread block is 99 KB.
CUDA储存层级和注意事项
寄存器
什么数据会被自动使用为寄存器?
shared memory的使用量通常是户明确定义可知的,而寄存器使用量如何确定?
每个线程有多少寄存器可用?如何避免寄存器使用过多?
不同于CPU,GPU对每个线程使用不同的硬件寄存器,切换线程时不会发生保存寄存器到内存和从内存加载寄存器内存的过程,因此线程切换十分高效。但SM总的寄存器资源和每个线程使用的寄存器数量决定了可以同时执行的线程数量。共享内存同样存在这个限制。
不同于CPU,GPU每个线程拥有不同的独立硬件寄存器,因此切换线程不需要保存和加载寄存器内存,线程切换代价低。
每个thread block的寄存器和共享内存使用量限制了每个SM能够同时执行的thread block数量,同时寄存器使用过多可能导致寄存器溢出导致数据存储到内存从而导致下降。
共享内存
bank conflict原理和如何避免?
bank conflict时不会切换warp降低延迟,因此对性能影响比较大。
常用的避免bank conflict方法是padding,即对原始矩阵的行长度进行加长,使得实际矩阵为shared mem保存矩阵的子矩阵。如下图展示了宽度为32的矩阵通过+1 padding可以避免不同线程访问同一列的bank冲突,d_id和b_id分别是数据和bank的id。实际上也可以+其他padding,比如+4或者+8还可以满足每一行数据的128/256字节对齐要求。图中的d_id是数据的id,而b_id是bank的id。

![]()
如何实现double buffer/prefetch?
double buffer是使用两个buffer,实现读取/写回与计算的pipe计算,保持计算单元一直处于忙碌状态。double buffer实现需要异步执行从而实现计算和数据拷贝的overlap。
从global mem加载到寄存器本身是异步的(不会阻塞后续指令除非后面用到了这个寄存器)。而ampere之前架构从global mem直接加载到shared需要经过寄存器中转,由于写shared mem依赖寄存器ready,导致需要等待global mem完成。ampere之前的架构为了实现global 到shared的异步,可以手动基于寄存器中转。也就是先手动把global读取到reg,然后执行其他无关计算指令,然后再把reg内存拷贝到shared,从而隐藏global mem读取等待。
apmere引入了新的不需要寄存器中转的异步拷贝LDGSTS指令从global mem读取到shared mem,减少了寄存器的压力和不必要的数据中转,进一步节省了功耗。并且因为这条指令的异步性,可以作为背景操作和前台的计算指令overlap执行,进一步提升整体计算效率。
double buffer的一个简单的演示代码:
全局内存
需要弄清楚的问题:
合并内存访问coalesce memory accesses的理解和实践?
内存合并访问:同一个warp 32个线程同时读取的内存地址是连续的n*128字节(每个线程读取4个字节,每个线程读取的地址id不一定要跟线程的id一致,但是整个warp视角读取的是一块连续的内存),并且需要内存对齐(这连续读取的内存首地址是128字节整数倍)。
一些注意点就是当处理int8 fp16等数据类型时,如果每个线程读取1个元素,那么一个warp是读取不到128字节的,这时可以用float2 float4等数据类型来读取然后在分发。
矩阵shape如果不是4、8、32等整数倍可以考虑进行padding,否则非0行的首地址不是128字节对齐的。
这个矩阵转置的例子很好的说明了如何利用shared mem来实现读取和写回两个矩阵的合并内容访问并且避免shared mem的bank conflict:CUDA学习(二)矩阵转置及优化(合并访问、共享内存、bank conflict) - 知乎
思路是每个warp读取32x32的数据块,每个warp的32线程依次读取32x32的每一行,这样输入读取是合并内存访问的。读取或者写入shared mem时基于索引idx变换可以轻松实现转置。然后再基于转置后的shared mem依次写回输出矩阵的每一行,实现输出的合并内存访问。由于32x32的shared mem读入或者写回时总存在32个线程同时访问同一行或者同一列的情况,因此如果只创建32x32的shared mem大小会在读取或者写回时出现bank conflict。但是如果创建一个[32,33]的shared mem数据块,读入时每次写入到shared mem[i,0:32],写回时读取shared mem[0:32,i]都不会出现bank冲突。
常量内存,纹理内存
一般特定应用场景才使用,AI里面是否有应用的空间?
CUDA Warp-Level Primitives
线程块以warp为单位由SM自动调度执行的,这一过程对程序员基本上不感知的,但也可以显示地在warp层面进行操作。例如Warp-level intra register exchange,因为同一个warp的线程执行和寄存器内容在同一个sm块,因此同一个warp线程存在便利的手段相互交换寄存器数据的可能(register-shuffle),而不同warp可能在不同sm块执行,只能通过shared memory交换数据。
CUDA 9 introduced three categories of new or updated warp-level primitives.
- Synchronized data exchange: exchange data between threads in warp.
__all_sync,__any_sync,__uni_sync,__ballot_sync__shfl_sync,__shfl_up_sync,__shfl_down_sync,__shfl_xor_sync__match_any_sync,__match_all_sync
- Active mask query: returns a 32-bit mask indicating which threads in a warp are active with the current executing thread.
__activemask
- Thread synchronization: synchronize threads in a warp and provide a memory fence.
__syncwarp
Please see the for detailed descriptions of these primitives.
这里展示基于warp shuffle使用每个warp来计算二维tensor每一行平均的例子:
__global__ void reduce_mean_row_warp(const float* __restrict__ A,
float* __restrict__ B,
int row, int col) {
int tid = blockDim.x * blockIdx.x + threadIdx.x;
int cur_row = tid / warpSize;
int start_col = tid % warpSize;
if (cur_row < row) {
float ratio = 1.0f / col;
int addr_offset = cur_row * col;
float mean_val = 0;
for (int i = start_col; i < col; i += warpSize) {
mean_val += ratio * A[addr_offset + i]; // method 1
}
// use warp shuffle to get correct mean for thread 0 from all threads in a warp
mean_val += __shfl_down_sync(0xFFFFFFFF, mean_val, 16);
mean_val += __shfl_down_sync(0xFFFFFFFF, mean_val, 8);
mean_val += __shfl_down_sync(0xFFFFFFFF, mean_val, 4);
mean_val += __shfl_down_sync(0xFFFFFFFF, mean_val, 2);
mean_val += __shfl_down_sync(0xFFFFFFFF, mean_val, 1);
if (start_col == 0) {
B[cur_row] = mean_val;
}
}
}
其他常见注意事项
分支导致的warp divergence应该尽量避免,比如让同一个warp尽量处理同一个分支。
__restrict__ 关键字可能带来一些优化效果,它具有与C99 restrict关键字基本相同的语义。
性能优化最重要的是知道瓶颈在哪里
1,整个模型的瓶颈在什么地方?是内存分配,数据拷贝?还是某些算子耗时?
2,单个算子里面,瓶颈又在哪里?数据计算?数据读写?偏置计算?
CUDA的一些新特性
异步内存分配
内存分配和重用是推理引擎极其重要的一块,因为每次重新内存分配和释放是很耗时的过程,通常需要实现一个内存池,提前分配好内存,然后基于内存池来进行内存重用,提高性能。而
而cuda11.2推出新功能底层自动实现了这样的功能,无需用户再自己实现复杂的内存重用算法。
ref
《CUDA并行程序设计 GPU编程指南》
《 PROFESSIONALCUDA C Programming》
Dissecting the NVIDIA Volta GPU Architecture via Microbenchmarking
声明:
本文部分内容使用了文中所引用文献和网页的内容。

- 点赞
- 收藏
- 关注作者
评论(0)