NEON 指令集并行技术优化矩阵旋转【Android】

【摘要】
参考链接: 利用neon技术对矩阵旋转进行加速
目标:将输入矩阵顺时针旋转90度,如下图所示:
输入矩阵  ...
参考链接: 利用neon技术对矩阵旋转进行加速
目标:将输入矩阵顺时针旋转90度,如下图所示:
输入矩阵 输出矩阵


以 8x8x8bit 的矩阵(更大的矩阵可以分块为 8x8x8bit)为例,基本的思路就是,逐渐扩大粒度(8bit 到 32bit)的 2x2 矩阵旋转
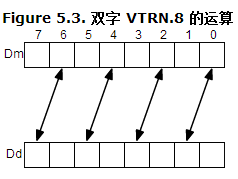
vtrn 示意图,可以看作是 2x2 矩阵的转置
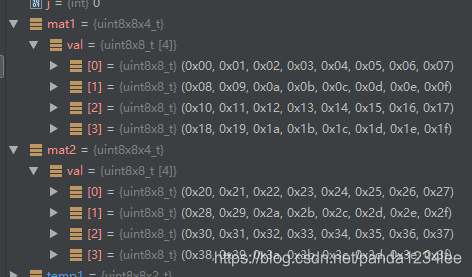
原始的数据的字节表示形式
以 8 bit 为单位进行旋转:
-
temp1 = vtrn_u8(mat1.val[1], mat1.val[0]);
-
temp2 = vtrn_u8(mat1.val[3], mat1.val[2]);
-
temp3 = vtrn_u8(mat2.val[1], mat2.val[0]);
-
temp4 = vtrn_u8(mat2.val[3], mat2.val[2]);

结果以 16 bit 看作一个数(小端存储)

再次进行旋转得到
-
temp9 = vtrn_u16(temp6.val[0], temp5.val[0]);
-
temp10 = vtrn_u16(temp6.val[1], temp5.val[1]);
-
temp11 = vtrn_u16(temp8.val[0], temp7.val[0]);
-
temp12 = vtrn_u16(temp8.val[1], temp7.val[1]);
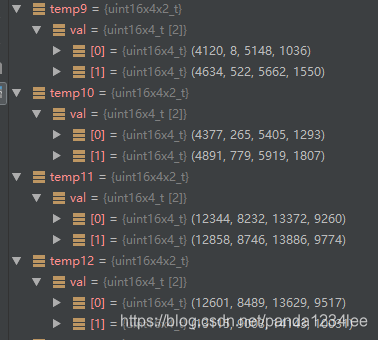
旋转的结果对应的字节表示形式为(小端存储)
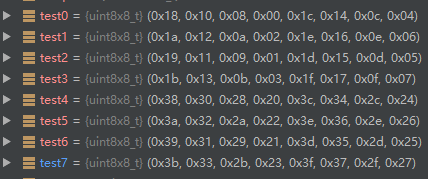
接着,把 32bit 当做一个数来旋转

-
temp17=vtrn_u32(temp15.val[0],temp13.val[0]);
-
temp18=vtrn_u32(temp15.val[1],temp13.val[1]);
-
temp19=vtrn_u32(temp16.val[0],temp14.val[0]);
-
temp20=vtrn_u32(temp16.val[1],temp14.val[1]);
旋转的结果为

对应的字节表示形式为

即最初矩阵的顺时针 90 ° 旋转的结果
代码如下:
-
uint8x8x4_t mat1, mat2;
-
mat1.val[0] = vld1_u8(srcImg + i * width + j); // vec8,每个元素 8 bit
-
mat1.val[1] = vld1_u8(srcImg + (i + 1) * width + j);
-
mat1.val[2] = vld1_u8(srcImg + (i + 2) * width + j);
-
mat1.val[3] = vld1_u8(srcImg + (i + 3) * width + j);// 4*vec8
-
mat2.val[0] = vld1_u8(srcImg + (i + 4) * width + j);
-
mat2.val[1] = vld1_u8(srcImg + (i + 5) * width + j);
-
mat2.val[2] = vld1_u8(srcImg + (i + 6) * width + j);
-
mat2.val[3] = vld1_u8(srcImg + (i + 7) * width + j);
-
-
uint8x8x2_t temp1, temp2, temp3, temp4;
-
temp1 = vtrn_u8(mat1.val[1], mat1.val[0]);
-
temp2 = vtrn_u8(mat1.val[3], mat1.val[2]);
-
temp3 = vtrn_u8(mat2.val[1], mat2.val[0]);
-
temp4 = vtrn_u8(mat2.val[3], mat2.val[2]);
-
-
// ==============================================
-
-
uint16x4x2_t temp5, temp6, temp7, temp8;
-
temp5.val[0] = vreinterpret_u16_u8(temp1.val[0]);
-
temp5.val[1] = vreinterpret_u16_u8(temp1.val[1]);
-
temp6.val[0] = vreinterpret_u16_u8(temp2.val[0]);
-
temp6.val[1] = vreinterpret_u16_u8(temp2.val[1]);
-
temp7.val[0] = vreinterpret_u16_u8(temp3.val[0]);
-
temp7.val[1] = vreinterpret_u16_u8(temp3.val[1]);
-
temp8.val[0] = vreinterpret_u16_u8(temp4.val[0]);
-
temp8.val[1] = vreinterpret_u16_u8(temp4.val[1]);
-
-
uint16x4x2_t temp9, temp10, temp11, temp12;
-
temp9 = vtrn_u16(temp6.val[0], temp5.val[0]);
-
temp10 = vtrn_u16(temp6.val[1], temp5.val[1]);
-
temp11 = vtrn_u16(temp8.val[0], temp7.val[0]);
-
temp12 = vtrn_u16(temp8.val[1], temp7.val[1]);
-
-
// ==============================================
-
-
uint32x2x2_t temp13, temp14, temp15, temp16;
-
temp13.val[0]= vreinterpret_u32_u16(temp9.val[0]);
-
temp13.val[1]= vreinterpret_u32_u16(temp9.val[1]);
-
temp14.val[0]= vreinterpret_u32_u16(temp10.val[0]);
-
temp14.val[1]= vreinterpret_u32_u16(temp10.val[1]);
-
temp15.val[0]= vreinterpret_u32_u16(temp11.val[0]);
-
temp15.val[1]= vreinterpret_u32_u16(temp11.val[1]);
-
temp16.val[0]= vreinterpret_u32_u16(temp12.val[0]);
-
temp16.val[1]= vreinterpret_u32_u16(temp12.val[1]);
-
-
uint32x2x2_t temp17, temp18, temp19, temp20;
-
temp17=vtrn_u32(temp15.val[0],temp13.val[0]);
-
temp18=vtrn_u32(temp15.val[1],temp13.val[1]);
-
temp19=vtrn_u32(temp16.val[0],temp14.val[0]);
-
temp20=vtrn_u32(temp16.val[1],temp14.val[1]);
-
-
// ==============================================
-
-
temp1.val[0]= vreinterpret_u8_u32(temp17.val[0]);
-
temp1.val[1]= vreinterpret_u8_u32(temp19.val[0]);
-
temp2.val[0]= vreinterpret_u8_u32(temp18.val[0]);
-
temp2.val[1]= vreinterpret_u8_u32(temp20.val[0]);
-
temp3.val[0]= vreinterpret_u8_u32(temp17.val[1]);
-
temp3.val[1]= vreinterpret_u8_u32(temp19.val[1]);
-
temp4.val[0]= vreinterpret_u8_u32(temp18.val[1]);
-
temp4.val[1]= vreinterpret_u8_u32(temp20.val[1]);
-
-
vst1_u8 (dstImg + j * height + i, temp1.val[0]);
-
vst1_u8 (dstImg+ (j+1) * height + i, temp1.val[1]);
-
vst1_u8 (dstImg+ (j+2) * height + i, temp2.val[0]);
-
vst1_u8 (dstImg+ (j+3) * height + i, temp2.val[1]);
-
vst1_u8 (dstImg+ (j+4) * height + i, temp3.val[0]);
-
vst1_u8 (dstImg+ (j+5) * height + i, temp3.val[1]);
-
vst1_u8 (dstImg+ (j+6) * height + i, temp4.val[0]);
-
vst1_u8 (dstImg+ (j+7) * height + i, temp4.val[1]);
以 256*256的矩阵为例(矩阵太小的话,neon 版本还不如 cpu 编译器自动优化的版本),得到以下测试结果

可见,性能优化了 40.9% 左右
文章来源: panda1234lee.blog.csdn.net,作者:panda1234lee,版权归原作者所有,如需转载,请联系作者。
原文链接:panda1234lee.blog.csdn.net/article/details/85228038
【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)