多模态信息抽取系列--预训练模型 Layout LM v1

【摘要】 模型结构介绍主模型结构:使用BERT作为backbone,加入2-D绝对位置信息,图像信息,分别捕获token在文档中的相对位置以及字体、文字方向、颜色等视觉信息。Layout系列模型(LayoutLM,LayoutLMv2,LayoutXLM)2D位置嵌入:文档页面视为坐标系统(左上为原点), 使用2张embedding table构造4种位置嵌入,横纵轴各使用1张嵌入表;图像嵌入:将文档...
模型结构介绍
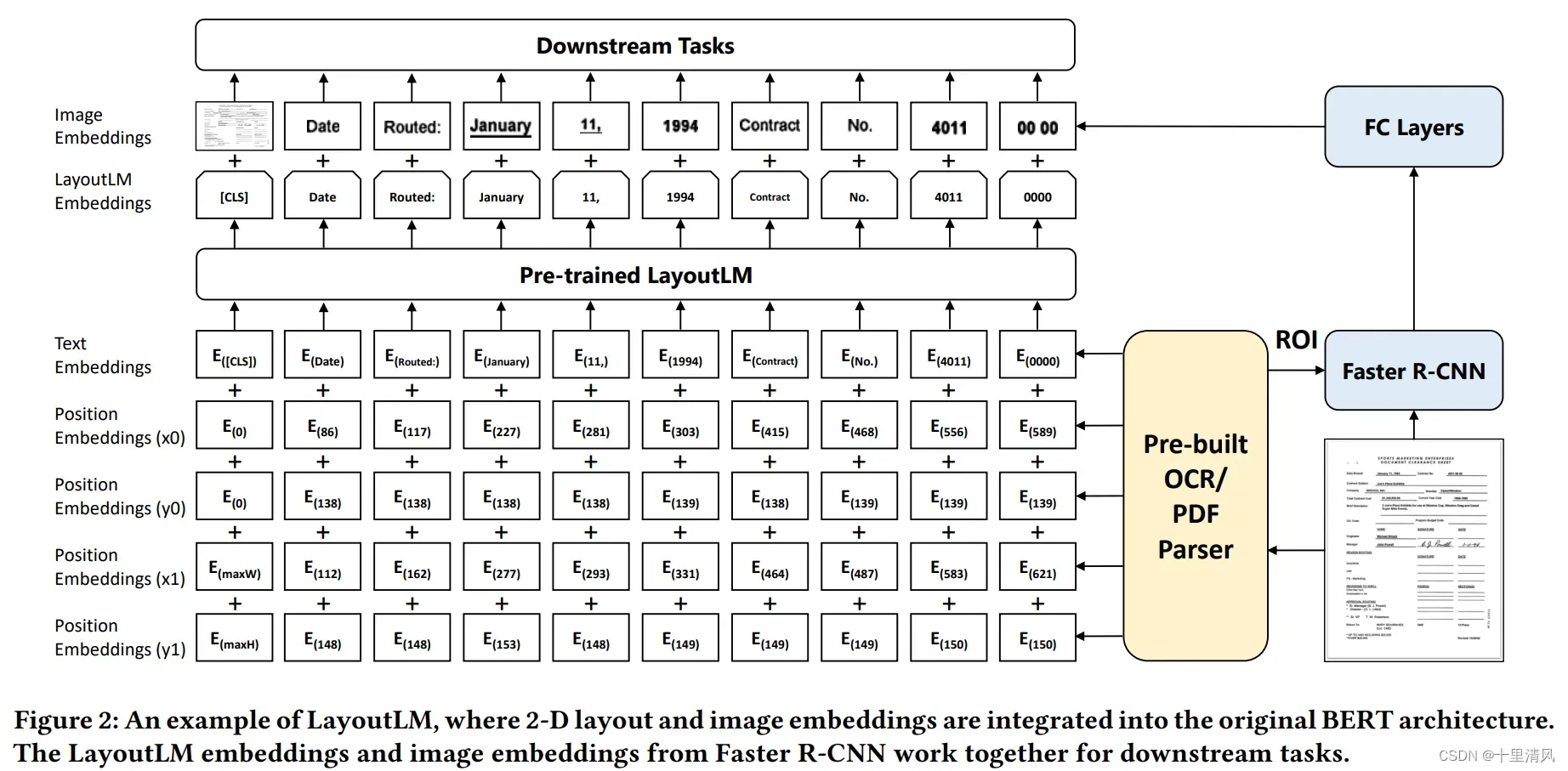
- 主模型结构:使用BERT作为backbone,加入2-D绝对位置信息,图像信息,分别捕获token在文档中的相对位置以及字体、文字方向、颜色等视觉信息。
Layout系列模型(LayoutLM,LayoutLMv2,LayoutXLM) - 2D位置嵌入:文档页面视为坐标系统(左上为原点), 使用2张embedding table构造4种位置嵌入,横纵轴各使用1张嵌入表;
- 图像嵌入:将文档页面图像分割成小图片序列,基于Faster R-CNN建模整张图片特征丰富[CLS]token表征;
预训练数据集介绍:
预训练集 IIT-CDIP Test Collection 1.0(600万扫描件,含1200万扫描图片,含信件、邮件、表单、发票等)。
- MVLM, Masker Visual-Language Model: 随机掩盖输入tokens,保留2-D信息,预测被掩盖token分布;
- MDC, Multi-label Document Classification: 监督预训练多标签文档分类,促使模型聚类不同文档特征,增强文档级特征表示;


预训练模型设置&任务:
Layout LM 设置
- 除2-D positional embeddings之外,其余参数使用bert base初始化;
- 标准化所有坐标点为0~1000;
- 使用ResNet-101作为Fatser R-CNN的backbone;
预训练任务:
- MVLM:预测15%的token,选其中80%替换为[MASK],10%随机替换,余下10%不变;
- 文档分类任务
下游Fine-tuning任务效果:
将预训练模型分别在Form Understanding、Receipt Understanding、 Document Image Classification三项任务上验证,较存BERT模型均有较大提升,具体如下:


【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)