Python实现动态规划Labeling算法求解SPPRC问题

本文中的课件来自清华大学深圳国际研究生院,物流与交通学部戚铭尧教授《物流地理信息系统》课程。
SPPRC问题
带资源约束的最短路径问题(shortest path problem with resource constraints)是一个众所周知的NP-Hard问题。 除了作为网络问题直接应用外,SPPRC还用作列生成解决方案方法的基础,用于解决车辆路径规划问题和人员排班问题等。
考虑一个有向图 G = ( N , A ) G = (N,A) G=(N,A), N = { v 1 , v 2 , . . . , v i , . . . , v n } N=\{v_1,v_2,...,v_i,...,v_n\} N={v1,v2,...,vi,...,vn}表示节点的集合,并且 A = { ( i , j ) ∣ v i ∈ N , v j ∈ N , i ≠ j } A=\{(i,j)|v_i \in N,v_j \in N ,i \ne j\} A={(i,j)∣vi∈N,vj∈N,i=j}表示弧的集合。对于每一段弧 ( i , j ) ∈ A (i,j)\in A (i,j)∈A都有一个非负的权重(vrptw问题中可能为负,需要作特殊处理), c i j c_{ij} cij和 t i j t_{ij} tij,表示通过这段弧的成本和资源消耗。
SPPRC问题包括找到从起始节点 v s ∈ N v_s \in N vs∈N到结束节点 v t ∈ N v_t \in N vt∈N的一条路径 P P P,使该路径的总成本最小化,但不超过最大资源消耗 T T T。即使只存在一种资源,SPPRC也是一个NP-Hard。
Labeling算法
直接求解SPPRC问题是比较困难的,故通常采用一种动态规划的方法: l a b e l c o r r e c t i o n a l g o r i t h m label \ correction \ algorithm label correction algorithm算法。
通常我们考虑有 L L L种资源,可能包括时间、最大装载重量、最大装载体积等。
对于每一条从起始节点 v s v_s vs扩展到点 v i v_i vi的路径 X p i X_{pi} Xpi都有一个标签 ( R i , C i ) (R_i,C_i) (Ri,Ci)与之相关联。 R i ≡ ( T i 1 , T i 2 , . . . , T i L ) R_i \equiv (T_i^1,T_i^2,...,T_i^ L) Ri≡(Ti1,Ti2,...,TiL)是路径使用的每L个资源的数量; C i C_i Ci是 c o s t cost cost。
此外,我们还需要设置一些优超规则,称为 d o m i n a n c e r u l e dominance\ rule dominance rule,以帮助减少不必要的扩展。令 X p i X_{pi} Xpi和 X p i ∗ X_{pi}^* Xpi∗是从 v s v_s vs扩展到 v i v_i vi的两条不同的路径,与之关联的标签分别为 ( R i , C i ) (R_i,C_i) (Ri,Ci)和 ( R i ∗ , C i ∗ ) (R_i^*,C_i^*) (Ri∗,Ci∗)。路径 X p i X_{pi} Xpi可以 d o m i n a t e s dominates dominates路径 X p i ∗ X_{pi}^* Xpi∗当且仅当:
C i ≤ C i ∗ , T i l ≤ T i l ∗ , ∀ l ∈ ( 1 , . . . , L ) , ( R i , C i ) ≠ ( R i ∗ , C i ∗ ) C_i \le C_i^*,T_i^l\le T_i^{l*} ,\forall \ l \in (1,...,L), (R_i,C_i) \ne (R_i^*,C_i^*) Ci≤Ci∗,Til≤Til∗,∀ l∈(1,...,L),(Ri,Ci)=(Ri∗,Ci∗)
下面介绍一个简单的小例子:
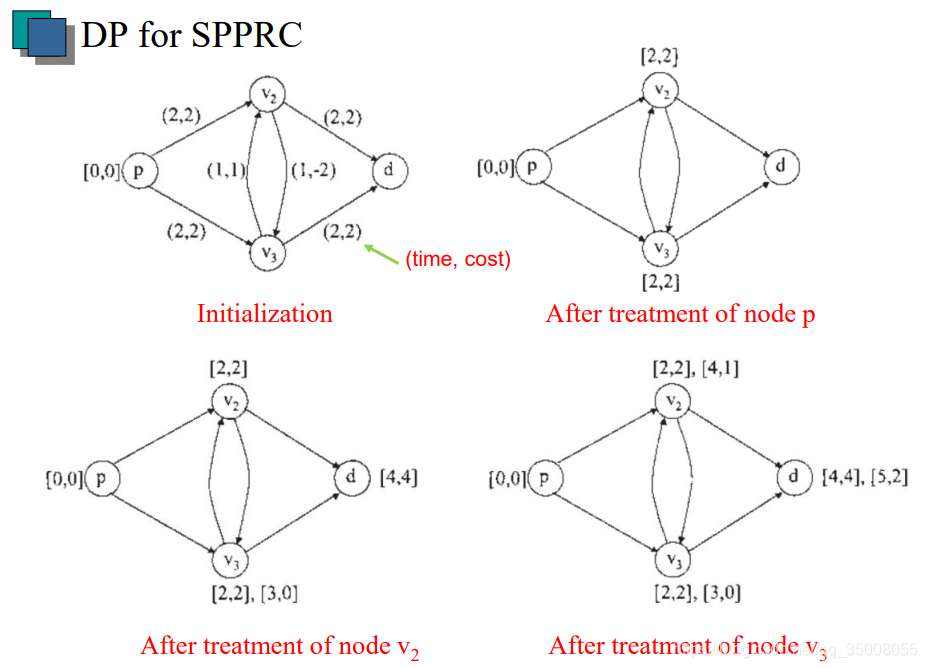
一个有向图如上图所示,我们可以看到每一段弧上都有一个非负的权重,分别表示通过该弧的 t i m e time time与 c o s t cost cost。首先初始化出发节点 p p p的标签,设置为 [ 0 , 0 ] [0,0] [0,0],随后令其向可达节点 v 2 v_2 v2和 v 3 v_3 v3进行扩展,则分别设置一个新的标签 [ 2 , 2 ] [2,2] [2,2]。再由 v 2 v_2 v2向 v 3 v_3 v3和 d d d进行扩展,则 v 3 v_3 v3得到一个新的标签 [ 3 , 0 ] [3,0] [3,0], d d d得到一个新的标签 [ 4 , 4 ] [4,4] [4,4],同理继续扩展到 d d d,生成一个新的标签 [ 5 , 2 ] [5,2] [5,2]。然后回过头由 v 3 v_3 v3扩展到 v 2 v_2 v2, v 2 v_2 v2得到一个新的标签 [ 4 , 1 ] [4,1] [4,1]。我们可以发现没有继续向 d d d扩展了,因为其生成的标签为 [ 6 , 2 ] [6,2] [6,2],与 d d d已有的标签 [ 5 , 2 ] [5,2] [5,2]相比满足了 d o m i n a n c e r u l e dominance\ rule dominance rule的要求,不必再扩展。
Python编程实现

考虑这样一个有向图。
首先在python中对该图进行定义:
import numpy as np
import networkx as nx
from time import *
# 点中包含时间窗属性
Nodes = {'s': (0, 0) , '1': (6, 14) , '2': (9, 12) , '3': (8, 12) , 't': (9, 15) }
# 弧的属性包括travel_time与distance
Arcs = {('s','1'): (8, 3) ,('s','2'): (5, 5) ,('s','3'): (12, 2) ,('1','t'): (4, 7) ,('2','t'): (2, 6) ,('3','t'): (4, 3) }
# create the directed Graph
Graph = nx.DiGraph()
cnt = 0
# add nodes into the graph
for name in Nodes.keys(): cnt += 1 Graph.add_node(name , time_window = (Nodes[name][0], Nodes[name][1]) , min_dis = 0 )
# add edges into the graph
for key in Arcs.keys(): Graph.add_edge(key[0], key[1] , travel_time = Arcs[key][0] , length = Arcs[key][1] )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
创建Label类
class Label: path = [] travel_time = 0 distance = 0
# dominance rule
def dominate(Q, Path_set): QCopy = copy.deepcopy(Q) PathsCopy = copy.deepcopy(Path_set) # dominate Q for label in QCopy: for another_label in Q: if (label.path[-1] == another_label.path[ -1] and label.time < another_label.time and label.dis < another_label.dis): Q.remove(another_label) print('dominated path (Q) : ', another_label.path) # dominate Paths for key_1 in PathsCopy.keys(): for key_2 in PathsCopy.keys(): if (PathsCopy[key_1].path[-1] == PathsCopy[key_2].path[-1] and PathsCopy[key_1].travel_time < PathsCopy[key_2].travel_time and PathsCopy[key_1].length < PathsCopy[key_2].length and (key_2 in Path_set.keys())): Path_set.pop(key_2) print('dominated path (P) : ', PathsCopy[key_1].path) return Q, Path_set # labeling algorithm
def Labeling_SPPRC(Graph, org, des): # initial Q Q = [] Path_set = {} # creat initial label label = Label() label.path = [org] label.travel_time = 0 label.distance = 0 Q.append(label) count = 0 while(len(Q) > 0): count += 1 current_path = Q.pop() # extend the current label last_node = current_path.path[-1] for child in Graph.successors(last_node): extended_path = copy.deepcopy(current_path) arc = (last_node, child) # check the feasibility arrive_time = current_path.travel_time + Graph.edges[arc]['travel_time'] time_window = Graph.nodes[child]['time_window'] if(arrive_time >= time_window[0] and arrive_time <= time_window[1] and last_node != des): extended_path.path.append(child) extended_path.travel_time += Graph.edges[arc]['travel_time'] extended_path.distance += Graph.edges[arc]['length'] Q.append(extended_path) Path_set[count] = current_path # 调用dominance rule Q, Path_set = dominance(Q, Path_set) # filtering Paths, only keep feasible solutions Path_set_copy = copy.deepcopy(Path_set) for key in Path_set_copy.keys(): if(Path_set[key].path[-1] != des): Path_set.pop(key) # choose optimal solution opt_path = {} min_dis = 1e6 for key in Path_set.keys(): if(Path_set[key].distance < min_dis): min_dis = Path_set[key].distance opt_path[1] = Path_set[key] return Graph, Q, Path_set, opt_path
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
调用labeling算法计算
org = 's'
des = 't'
begin_time = time()
Graph, Q, Path_set, opt_path = Labeling_SPPRC(Graph, org, des)
end_time = time()
print("计算时间: ", end_time - begin_time)
print('optimal path : ', opt_path[1].path )
print('optimal path (distance): ', opt_path[1].distance)
print('optimal path (time): ', opt_path[1].travel_time)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
最终运行结果如图所示:

我们也可以尝试计算更多的点,并且加入 l o a d c a p a c i t y load \ capacity load capacity的约束,对 S o l o m o n c 101. t x t Solomon \ c101.txt Solomon c101.txt算例的计算结果为:

对 S o l o m o n c 1 _ 10 _ 1. T X T Solomon \ c1\_10\_1.TXT Solomon c1_10_1.TXT算例取300个客户点的计算结果为:

至于500个点往上,我的电脑就跑不出来啦。。。
感谢大家的阅读。
作者:夏旸,清华大学,工业工程系/深圳国际研究生院 (硕士在读)
刘兴禄,清华大学,清华伯克利深圳学院(博士在读)
欢迎大家关注公众号运小筹。

文章来源: blog.csdn.net,作者:旸1111,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq_35008055/article/details/110574314

- 点赞
- 收藏
- 关注作者
评论(0)