什么是完整的AI视觉识别?

【摘要】 完整的AI视觉识别论文,这里的"完整"是指识别人类可以识别的一切,本文提出一种名为“learning-by-compression”的新型预训练任务,希望能够激发社区追求compression-recovery的权衡而不是精度-复杂度的权衡!
这里的"完整"是指识别人类可以识别的一切,本文提出一种名为“learning-by-compression”的新型预训练任务,希望能够激发社区追求compression-recovery的权衡而不是精度-复杂度的权衡!
论文标题:What Is Considered Complete for Visual Recognition?
论文链接:https://arxiv.org/abs/2105.13978
此论文的作者来自华为云EI团队:Lingxi Xie, Xiaopeng Zhang, Longhui Wei, Jianlong Chang, Qi Tian
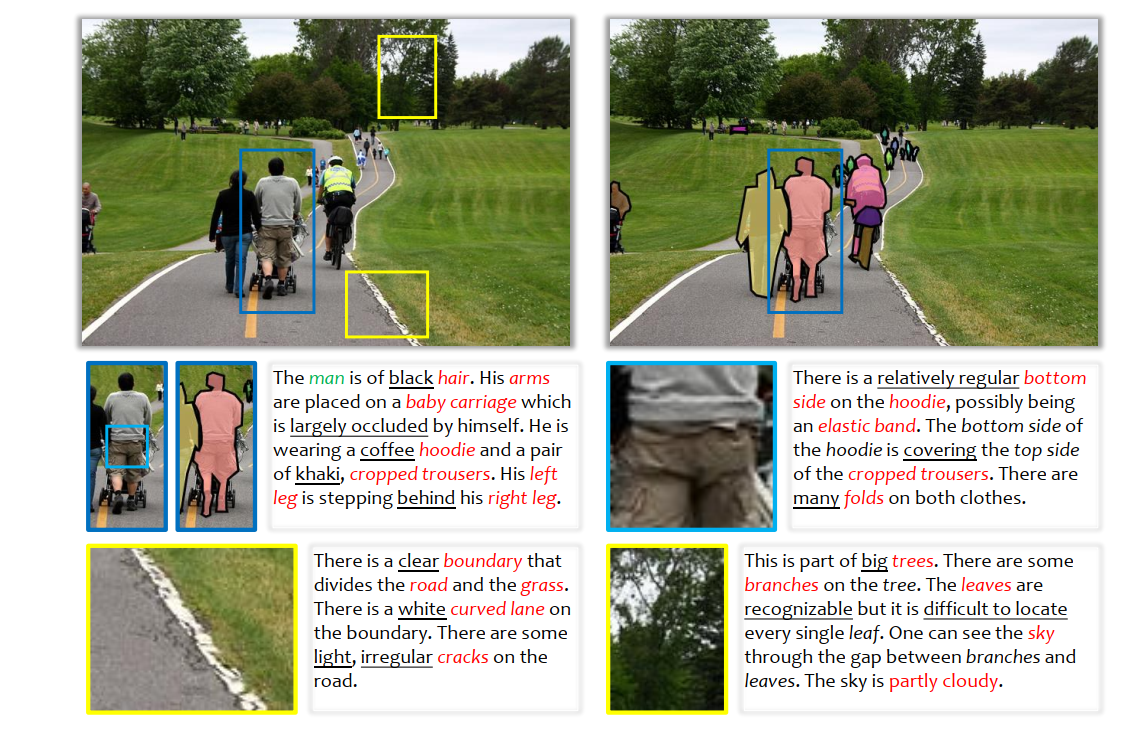
这是一篇意见书。我们希望传达一个关键信息,即当前的视觉识别系统远未完整,即识别人类可以识别的一切,而且通过不断增加人类注释来弥补差距的可能性很小。 基于观察,我们提出一种名为“learning-by-compression”的新型预训练任务。 计算模型(例如,深度网络)经过优化以使用紧凑特征来表示视觉数据,并且这些特征保留了恢复原始数据的能力。语义注释在可用时扮演弱监督的角色。一个重要但具有挑战性的问题是图像恢复的评估,我们提出了一些设计原则和未来的研究方向。 我们希望我们的建议能够激发社区追求compression-recovery的权衡而不是精度-复杂度的权衡。

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)