CUDA专业小贴士:通过 Warp-聚合的原子操作来优化过滤

注:这篇文章已经(于 2017年11月)更新为 CUDA 9 和最新的 GPU。NVCC编译器现在可以在许多情况下自动为原子操作执行 warp-聚合,因此无需额外的工作就可以获得更高的性能。事实上,编译器生成的代码比手工编写的 warp 聚合代码更快。这篇文章主要是为那些想了解它是如何工作的,并将类似的技术应用于其他问题的人准备的。
在本文中,我将介绍 warp-聚合的原子操作,这是一种可以在多个线程原子地累加到单个计数器时提高性能的有用技术。在 warp-聚合中,warp 的线程首先计算它们之间的总增量,然后选择单个线程将增量原子地添加到全局计数器中。这种聚合减少了原子操作的数量【最多可以是一个 warp 中的线程数量(当前gpu上最多可以减少 32x )】,并且可以显著提高性能。此外,在许多典型情况下,可以将标准原子操作顺便替换为 warp-聚合实现,因此它可以作为提高复杂应用程序性能的一种简单方法。
问题: 通过断定过滤
考虑如下过滤问题:我有一个源数组 src,包含 n 个元素和一个断定,我需要将满足断定的 src 的所有元素复制到目标数组 dst 中。为了简单起见,假设 dst 的长度至少为 n,并且 dst 数组中元素的顺序无关紧要。对于这个例子,我假设数组元素是整数,并且只有当元素为正时判定才为真。下面是过滤的 CPU 实现示例。
-
int filter(int *dst, const int *src, int n) {
-
int nres = 0;
-
for (int i = 0; i < n; i++)
-
if (src[i] > 0)
-
dst[nres++] = src[i];
-
// return the number of elements copied
-
return nres;
-
}
过滤(也称为流压缩)是一种常见的操作,它是许多编程语言的标准库的一部分,可以使用多种名称,包括 grep、copy_if、select、FindAll 等等。它也经常被简单地实现为一个循环,因为它可能与周围的代码紧密集成。
结合全局和共享内存的解决方案
现在,如果我想在 GPU 上实现过滤,且并行处理数组 src 的元素,该怎么办? 一种直接的方法是使用一个全局计数器,并对 dst 数组中写入的每个新元素原子地递增它。这个的 GPU 实现可能如下所示。
-
__global__
-
void filter_k(int *dst, int *nres, const int *src, int n) {
-
int i = threadIdx.x + blockIdx.x * blockDim.x;
-
if(i < n && src[i] > 0)
-
dst[atomicAdd(nres, 1)] = src[i];
-
}
这个实现的主要问题是,从 src 读取正元素的(网格中的)所有线程都会累加一个计数器 nres 。根据正元素的数量,这可能是非常多的线程。因此,atomicAdd() 的冲突程度很高,这限制了性能。您可以在 图1 中看到这一点,它绘制了 Kepler K80 GPU在处理1亿个(100*2^20)元素时获得的内核带宽(包括读和写,但不包括原子操作)。
 图1. 开普勒 K80 GPU 上的全局原子操作滤波的性能 (CUDA 8.0.61) 。
图1. 开普勒 K80 GPU 上的全局原子操作滤波的性能 (CUDA 8.0.61) 。
带宽与执行的原子操作数或数组中正元素的比例成反比。对于5%的部分(fraction),性能是可以接受的(大约55 GiB/s),但是当更多的元素通过过滤器时,性能会急剧下降,对于 50% 的部分 (fraction),性能仅为 8 GiB/s左右。原子操作显然是一个瓶颈,需要删除或减少原子操作以提高应用程序性能。
提高过滤性能的一种方法是使用共享内存执行原子操作。这提高了每个操作的速度,并减少了冲突的程度,因为计数器只在单个块中的线程之间共享。使用这种方法,每个线程块只需要一个全局 atomicAdd()。下面是用这种方法实现的内核。
-
__global__
-
void filter_shared_k(int *dst, int *nres, const int* src, int n) {
-
__shared__ int l_n;
-
int i = blockIdx.x * (NPER_THREAD * BS) + threadIdx.x;
-
-
for (int iter = 0; iter < NPER_THREAD; iter++) { // 迭代 NPER_THREAD 次
-
// zero the counter
-
if (threadIdx.x == 0)
-
l_n = 0;
-
__syncthreads();
-
-
// get the value, evaluate the predicate, and
-
// increment the counter if needed
-
int d, pos;
-
-
if(i < n) {
-
d = src[i];
-
if(d > 0)
-
pos = atomicAdd(&l_n, 1); // 在共享内存上进行原子加(l_n 不会超过 BS)
-
}
-
__syncthreads();
-
-
// leader increments the global counter
-
if(threadIdx.x == 0)
-
l_n = atomicAdd(nres, l_n); // 注意,这边是用 nres 的旧值来覆盖 l_n
-
__syncthreads();
-
-
// threads with true predicates write their elements
-
if(i < n && d > 0) {
-
pos += l_n; // increment local pos by global counter 下一块(块内)各个线程的位置
-
dst[pos] = d;
-
}
-
__syncthreads();
-
-
i += BS; // 一次迭代跳过 BS 个 src (一个线程块有 BS 个线程)
-
}
-
}
另一种方法是首先使用一个并行前缀和来计算每个元素的输出索引。Thrust 库的 copy_if() 函数使用了这种方法的优化版本。图2展示了开普勒 K80 的两种方法的性能。尽管共享内存原子技术提高了过滤性能,但其性能仍然保持在原始方法的1.5倍以内。原子操作仍然是一个瓶颈,因为操作的数量没有改变。Thurst 比两种方法都适用于高过滤部分 (fraction),但前期成本较大,不能用于小过滤部分的摊销。
需要注意的是,与 Thrust 的比较不是严格的同类比较,因为 Thrust 实现了一个稳定的过滤器:它保留了输出中输入元素的相对顺序。这是使用前缀和来实现它的结果,但其代价更高。如果我们不需要一个稳定的过滤器,那么纯原子方法更简单,执行的工作也更少。
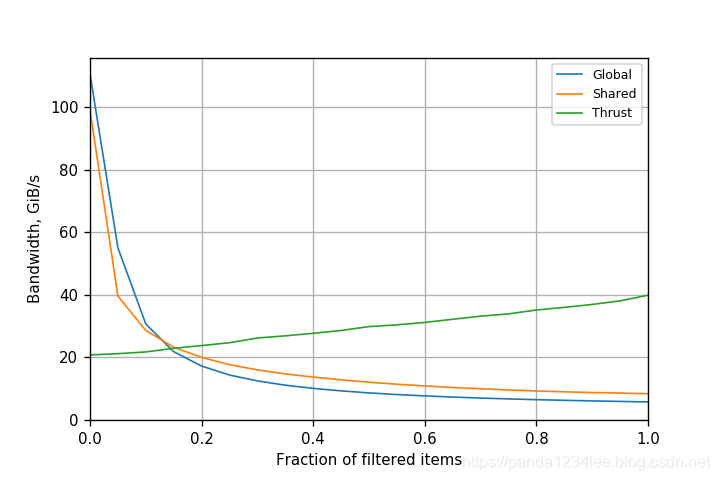 图2. 基于Kepler K80 GPU 的共享内存原子操作滤波的性能(CUDA 8.0.61)。
图2. 基于Kepler K80 GPU 的共享内存原子操作滤波的性能(CUDA 8.0.61)。
Warp-聚合的原子操作
warp-聚合是将来自一个 warp 中的多个线程的原子操作组合成一个原子操作的过程。这种方法与使用共享内存是正交的(完全不同的):原子的类型保持不变,但是我们使用的原子操作更少。使用 warp-聚合,我们使用以下步骤替换原子操作。
- 从 warp 中的线程中选择一个领导线程。
- warp 中的所有线程都计算 warp 的总原子增量。
- 领导线程执行一次原子加法来计算 warp 的偏移量。
- 领导线程将偏移量广播给 warp 中的所有其他线程。
- 每个线程都将自己在 warp 中的索引加上 warp 偏移量,以获得其在输出数组中的位置。
从 CUDA 9.0 开始,有两个 api 可用来实现这一点:
- 协作组,一种用于管理协作线程组的 CUDA 编程模型的扩展;
- warp 同步原语函数。
在执行一个 warp-聚合的原子操作之后,每个线程按照原始代码的方式继续,并将其值写入 dst 数组中对应的位置。现在让我们详细考虑每个步骤。
步骤1:领导线程的选择
在过滤中,可以重新组织代码,使所有线程都处于活跃状态。然而,在其他一些情况下,原子操作可能发生在嵌套条件中,其中一些线程可能处于非活跃状态。通常,这种方法应该假设只有某些线程是活跃的,所以我需要一个由所有活跃线程组成的组。
要使用协作组,请包含头文件并使用 cooperative_groups 命名空间。
-
#include <cooperative_groups.h>
-
using namespace cooperative_groups;
将当前所有合并访问的线程创建为一组。
auto g = coalesced_threads();
使用协作组能够很容易获得线程级别:调用 g.thread_rank() 。级别为 0 的线程将成为 leader。
如果您喜欢使用原语函数,可以从 _activemask() 开始。
unsigned int active = __activemask();
(一种较老的方法是使用 _ballot(1) 。这在 CUDA 8 上是可行的,但从 CUDA 9 开始就废弃了。)
然后选出一个 leader 。warp 内的线程叫做 lane ;选择 leader 最简单的方法是使用数字最小的活跃 lane 。__ffs() 原语返回集合位(set bit)的基于 1 的最低索引,因此减去 1 得到基于 0 的索引。
int leader = __ffs(active) - 1;
步骤2: 计算总增量
对于过滤的示例,每个具有判定为真的线程将计数器递增 1 。warp 的总增量等于活跃 lane 的数量(这里我不考虑不同 lane 增量不同的情况)。这对于协作组来说很简单: g.size() 返回组中的线程数。
如果您喜欢使用原语函数,您可以将由 _activemask() 返回的掩码中 bits set 的个数作为总增量。为此,使用内置函数 _popc(int v) ,它返回整数 v 的二进制表示的 bits set 的个数。
int change = __popc(active);
步骤3:执行原子添加
只有领导线程(lane 0)执行原子操作。对于协作组,只需检查 thread_rank() 是否返回0,就像这样。
-
int warp_res;
-
if(g.thread_rank() == 0)
-
warp_res = atomicAdd(ctr, g.size());
如果喜欢使用原语函数,则必须使用 _lanemask_lt() 计算每个 lane 的 rank,该函数返回 ID小于当前 lane 的所有 lane (包括非活跃 lane)的掩码。然后,您可以通过将这个掩码与活跃的 lane 的掩码进行与运算来计算 rank,并统计 bits set 的个数。
-
unsigned int rank = __popc(active & __lanemask_lt());
-
int warp_old;
-
if(rank == 0)
-
warp_old = atomicAdd(ctr, change); // ctr is the pointer to the counter
步骤4:广播结果
在此步骤中,领导线程将 atomicAdd() 的结果广播到 warp 中的其他 lane。我们可以通过在活跃 lane 上使用 shuffle 操作来实现这一点。
使用协作组,您可以使用 g.shfl(warp_res, 0) 广播结果。 0 是领导线程的索引,它仅仅在活跃线程是组的一部分时才奏效(因为它是使用 coalesced_threads() 创建的)。
如果您喜欢使用原语函数,可以调用 _shfl_sync(),它具有以下签名,其中 T 是32位或64位整数或浮点类型。
T __shfl_sync(unsigned int mask, T var, int srcLane, int width=warpSize);
shfl_sync() 返回由 srcLane 提供 ID 的线程所持有的值 var。mask 是参与调用的线程的掩码。掩码位为 1 的所有非退出线程(non-exited)必须使用相同的掩码执行相同的内置函数,否则结果将是未定义的。 width 必须是 2 的幂次,且小于或等于 warp 尺寸。 warp 会按照该尺寸分成相同大小的组,srcLane 指的是组内的 lane 号。如果 srcLane 超出范围[0:width-1](包括两端),则 srcLane 对 width 取模给出 lane 号。
下面的代码使用了 _shfl_sync() 来广播结果。
warp_res = __shfl_sync(active, warp_res, leader);
CUDA 8 和更早的实现使用了_shfl(),从 CUDA 9 开始就不提倡使用它 (已废弃) 。
步骤5:计算每个 lane 的结果
最后一步计算每个 lane 的输出位置,方法是将 warp 的广播计数器的值添加到(活跃的 lanes 中的) lane 的 rank 上。
协作组的形式:
return g.shfl(warp_res, 0) + g.thread_rank();
原语函数的形式:
return warp_res + rank;
现在,我们可以将步骤 1-5 的代码片连接起来,以获得完整的 warp-聚合版本的增量函数。
对于协作组,代码简洁明了。
-
__device__ int atomicAggInc(int *ctr) {
-
auto g = coalesced_threads();
-
int warp_res;
-
if(g.thread_rank() == 0)
-
warp_res = atomicAdd(ctr, g.size());
-
return g.shfl(warp_res, 0) + g.thread_rank();
-
}
对于原语函数,代码则更加复杂。
-
__device__ int atomicAggInc(int *ctr) {
-
unsigned int active = __activemask();
-
int leader = __ffs(active) - 1;
-
int change = __popc(active);
-
unsigned int rank = __popc(active & __lanemask_lt());
-
int warp_res;
-
if(rank == 0)
-
warp_res = atomicAdd(ctr, change);
-
warp_res = __shfl_sync(active, warp_res, leader);
-
return warp_res + rank;
-
}
性能对比
warp-聚合的原子增量函数是 atomicAdd(ctr, 1) 的一个替代,其中所有 warp 线程的 ctr 都是相同的。因此,我们可以使用atomicAggInc() 重写 GPU 过滤,如下所示。
-
__global__ void filter_k(int *dst, const int *src, int n) {
-
int i = threadIdx.x + blockIdx.x * blockDim.x;
-
if(i >= n)
-
return;
-
if(src[i] > 0)
-
dst[atomicAggInc(nres)] = src[i];
-
}
注意,尽管我们在定义 warp-聚合时考虑了全局原子,但是没有什么可以阻止对共享内存原子做同样的事情。事实上,如果 ctr 是指向共享内存的指针,那么上面定义的 atomicAggInc(int *ctr) 函数就可以工作。因此,Warp-聚合还可以用于加速共享内存的过滤。图3 显示了有和没有warp-聚合的不同类型的滤波在 开普勒 GPU 上性能的比较。
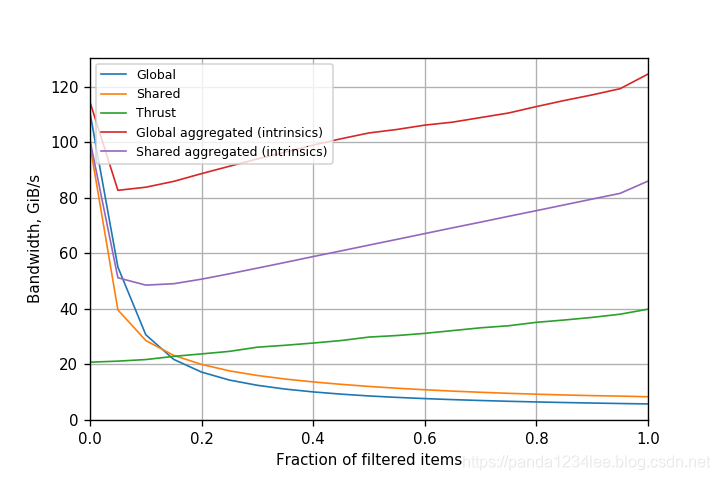 图3. 在Tesla K80(开普勒架构)GPU (CUDA 8.0.61)上不同过滤的性能。
图3. 在Tesla K80(开普勒架构)GPU (CUDA 8.0.61)上不同过滤的性能。
对于开普勒 GPU 来说,带有 warp-聚合的全局原子的版本显然是赢家。它总是提供超过 80GiB /s的带宽,并且带宽实际上随着成功通过过滤器的元素的比例的升高而增加。这也表明原子不再是一个重要的瓶颈。与 全局原子 相比,性能提高了21倍。在同一个 GPU 上,一个简单的复制操作的性能大约是190 GiB /s。因此,我们可以说,使用 warp-聚合原子进行过滤的性能与简单的复制操作相当。这也意味着过滤现在可以用于代码的性能关键部分。还要注意,共享内存原子(带有 warp-聚合)实际上比 warp-聚合原子慢。这表明 warp-聚合已经做得很好了,在开普勒上使用共享内存没有带来任何好处,只会带来额外的开销。
由于在某些情况下,可以使用 warp-聚合的 atomics 作为常规 atomics 的替代,所以编译器现在在许多情况下自动执行这种优化就不足为奇了。事实上,编译器从CUDA 7.5开始为后开普勒 GPU 做优化,而在CUDA 9中,它也为开普勒 GPU 做优化。因此,早期的比较是与开普勒上的 CUDA 8 进行的,在那里 warp 聚集的原子尚未自动插入。
图4、图5 和 图6 显示了开普勒、帕斯卡和伏特在 CUDA 9 上的性能比较,简单 atomicAdd() 的性能类似于 warp-聚合的 atomics。
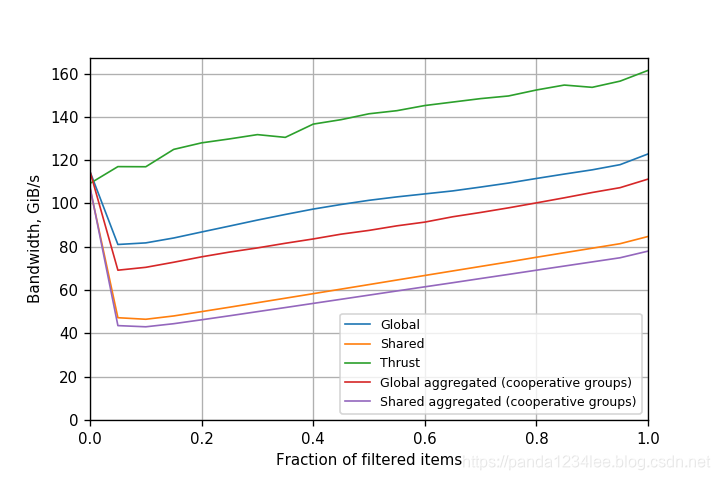 题图4. 在 Tesla K80(Kepler) GPU 上不同过滤的性能(CUDA 9.0.176)
题图4. 在 Tesla K80(Kepler) GPU 上不同过滤的性能(CUDA 9.0.176)
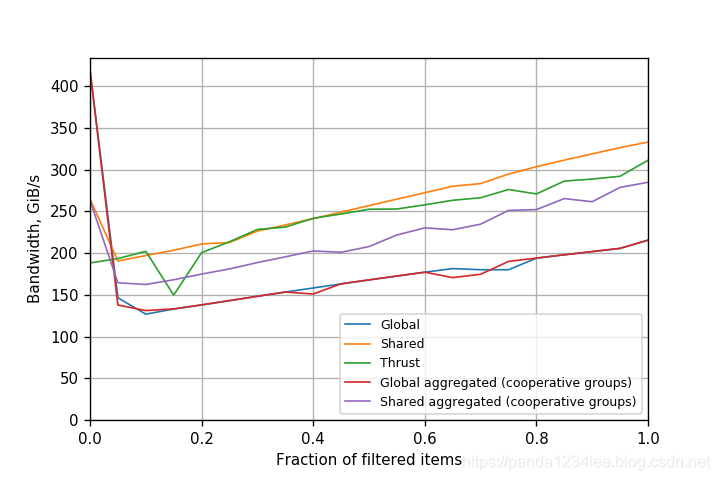 图5. 在 Tesla P100 (Pascal) GPU (CUDA 9.0.176)上不同过滤的性能。
图5. 在 Tesla P100 (Pascal) GPU (CUDA 9.0.176)上不同过滤的性能。
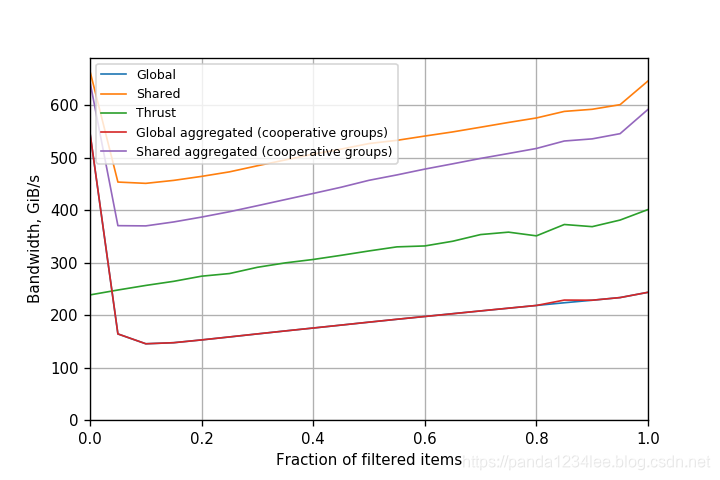 图6. 在 Tesla V100 (Volta) GPU (CUDA 9.0.176)上不同过滤的性能。
图6. 在 Tesla V100 (Volta) GPU (CUDA 9.0.176)上不同过滤的性能。
总结
原子的 warp-聚合是一种有用的技术,可以提高在少量计数器上执行许多操作的应用程序的性能。在这篇文章中,我们将 warp-聚合应用于滤波,并在开普勒+CUDA 8 上获得了一个量级以上的性能改进。事实上,这项技术非常有用,现在已经在 NVCC 编译器中实现了,在很多情况下,默认情况下无需额外的工作就可以获得 warp-聚合。
warp-聚合原子并不局限于过滤;您可以将它用于许多其他使用原子操作的应用程序中。
文章来源: panda1234lee.blog.csdn.net,作者:panda1234lee,版权归原作者所有,如需转载,请联系作者。
原文链接:panda1234lee.blog.csdn.net/article/details/88721966
- 点赞
- 收藏
- 关注作者
评论(0)