8:Java Conllections FrameWork-Java API 实战

1. 原生数组带来的问题,抛出问题
- 原生数组容易造成超出边界,如果非要使用传统的数组,增删改查,就要用到数据结构,非常复杂
- CRUD是指在做计算处理时的增加(Create)、读取查询(Retrieve)、更新(Update)和删除(Delete)几个单词的首字母简写
由此引出Java Conllections FrameWork即Java集合框架,也可称为函数库

2. Conllections家族
- Java集合框架是一个包含一系列实作可重复使用集合的数据结构的类别和界面集合
- Java集合大致可以分为两大体系,一个是
Collection,另一个是Map
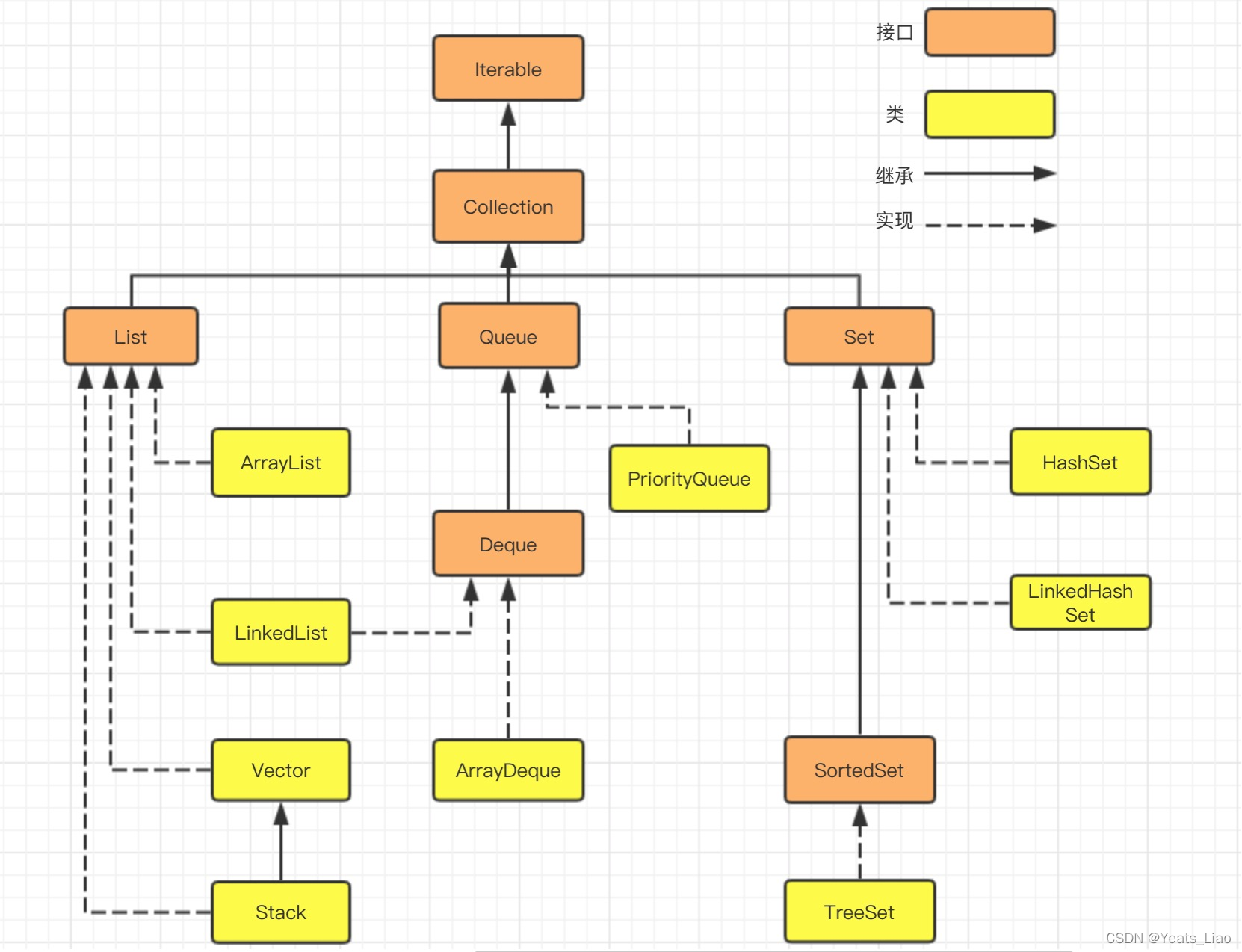
这里是引用java.util.Collection下的接口和继承类关系简易结构图:
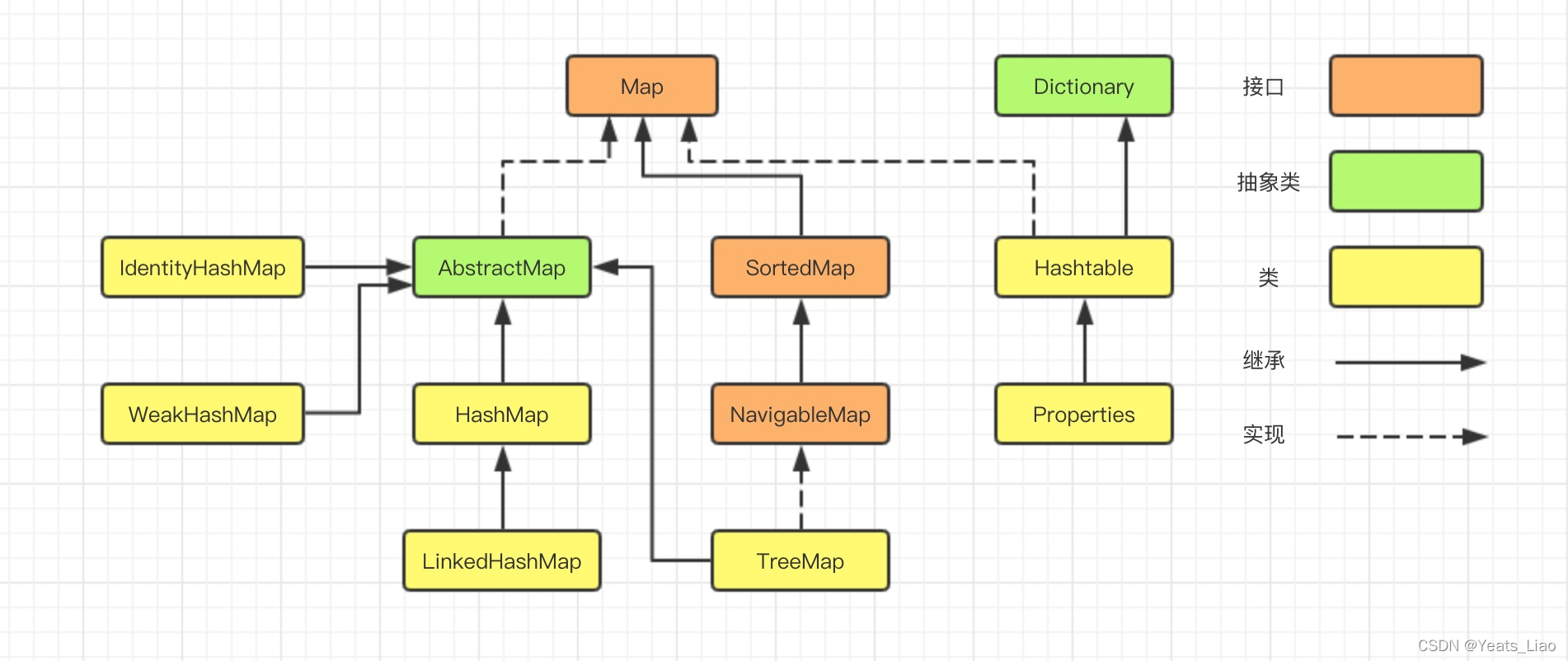
java.util.Map下的接口和继承类关系简易结构图:
3. 黑帮的帮规
lterables集合层次结构中的根接口,可以理解成帮派老大- 当我们要帮派帮忙时,一般请它下面的小弟来办事,所以用的时候找类来实现
- 所有类和接口都自身相关的规定,也必须遵守总集合的规定

4. ArrayList第一讲
ArrayList 类是一个可以动态修改的数组,与普通数组的区别就是它是没有固定大小的限制,我们可以添加或删除元素。
ArrayList 继承了 AbstractList ,并实现了 List 接口可以自动扩容

泛型限定是指将类型做限定,可设置成只能存放String类型

如果要进行CRUD,可以创建一个Student类
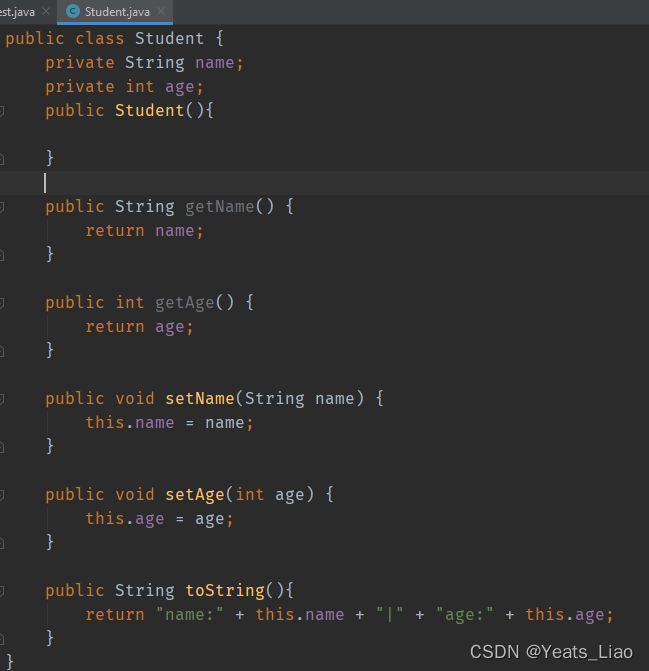
正常来说Student并不是以数组的形式输出的,而是toSring,如果要再添加一个对象扩容的话,又要getter setter一遍

如果换成集合形式输出, 效果会大不同
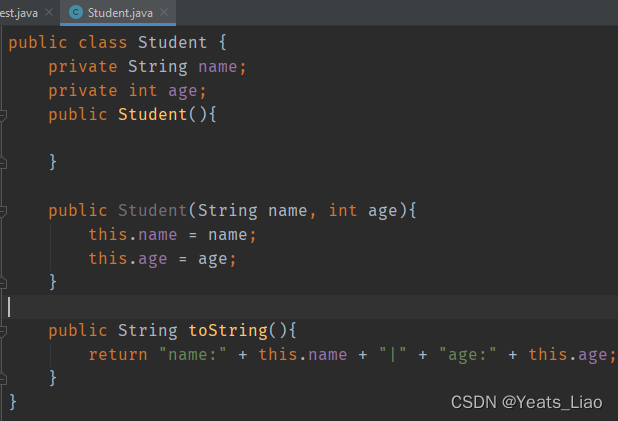
这下扩容就方便多了,只需.add()即可,也不用担心数组下标,不用像传统输出写一个for循环了
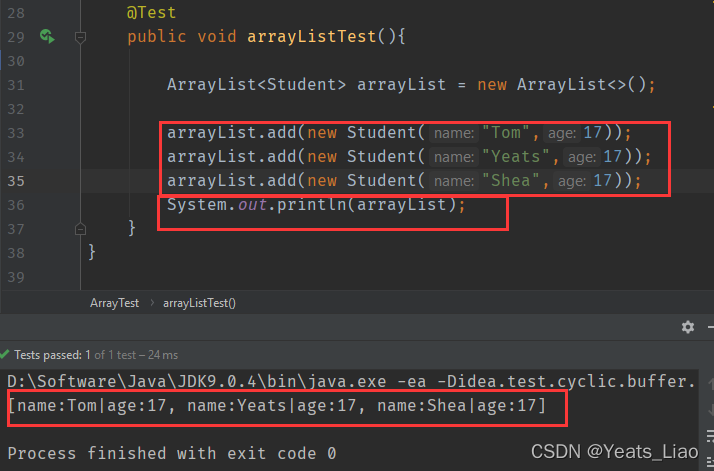
5. ArrayList第二讲
.add()方法可以添加元素和替换元素
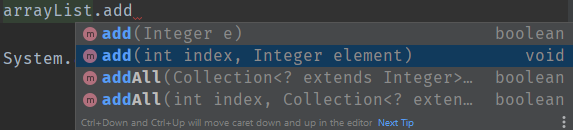
.add(0, 4)表示在第0个下标处插入元素4

.addAll()表示合并元素,讲arrayList_2合并到arrayList_1之后

查看源代码中,集合是先转换为数组,再拷贝到一份新数组返回

.toarray()方法表示返回集合的数组形式

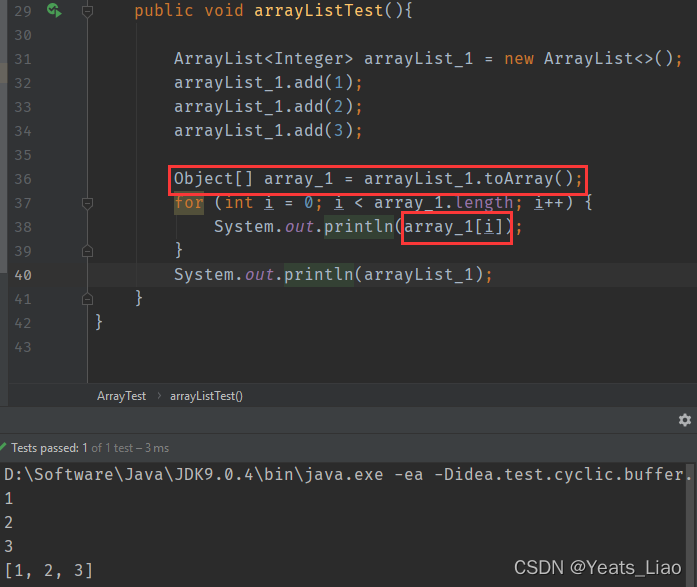
.clear()方法表示清楚数据

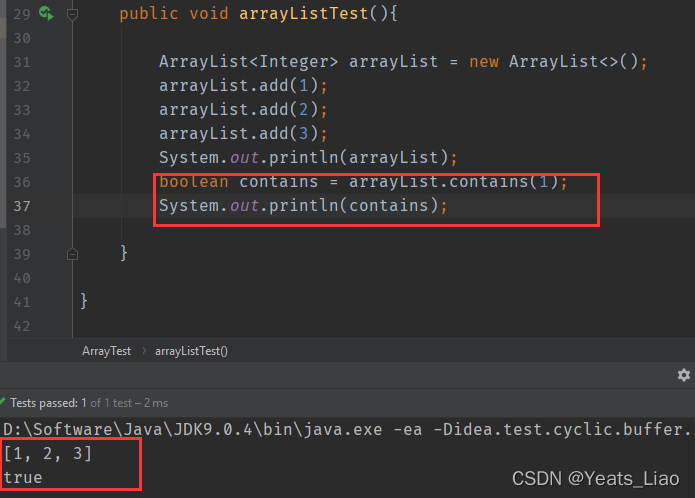
.contaions()方法用于判断字符串中是否包含指定的字符或字符串
.get()方法获得集合里的元素,for循环遍历具有操作性,集合的长度要用.size(),数组的长度用.length()
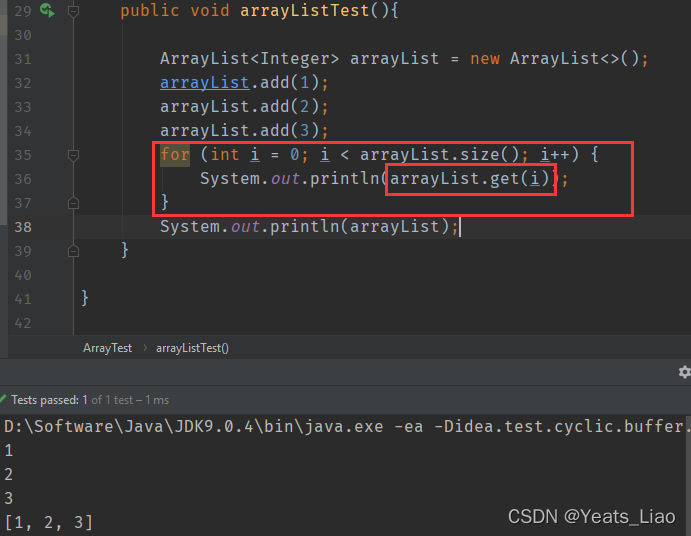
.get()的源代码中,是先检查指是否存在,在返回元素值
如何对集合中每个元素操作呢?增强for循环 for each ,可以实现对每个元素值都加1

6. ArrayList第三讲
索引(下标)是从0开始的
.indexOf()方法用于查找元素首个下标
.lastIndexOf()方法用于查找元素最后一个下标
.isEmpty()方法用于检查集合是否为空

.remove()方法用于删除元素,默认根据下标删除,可以根据object和index删除
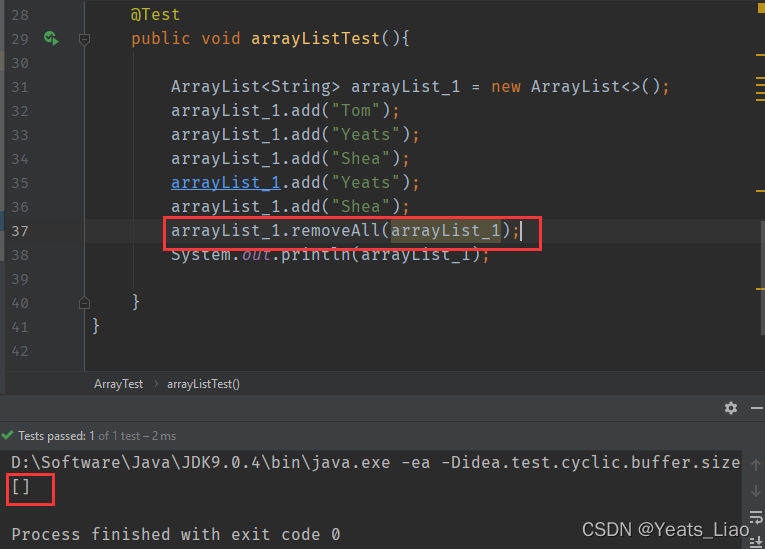
.removeAll()方法用于移除所有元素
.replaceAll()方法用于替换所有元素
.toLowerCase()用于转换成小写
.toUpperCase()用于转换成大写

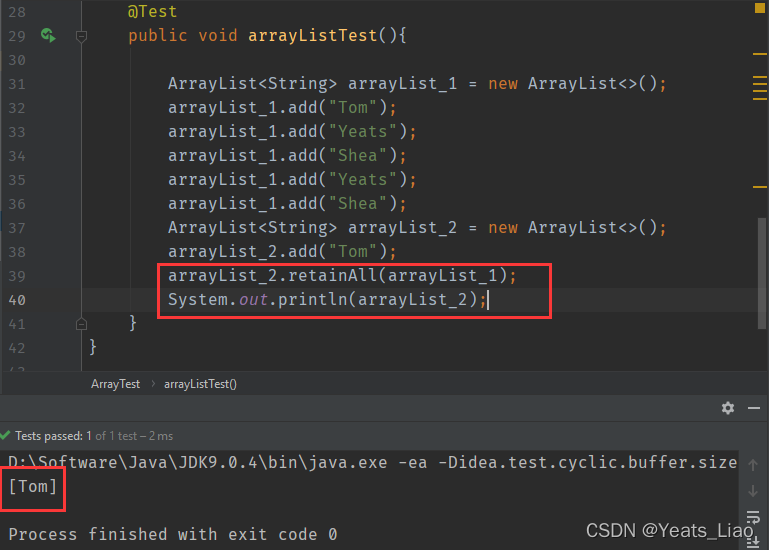
.retainAll()方法用于取交集
.set()方法用于给指定的下标元素设置值

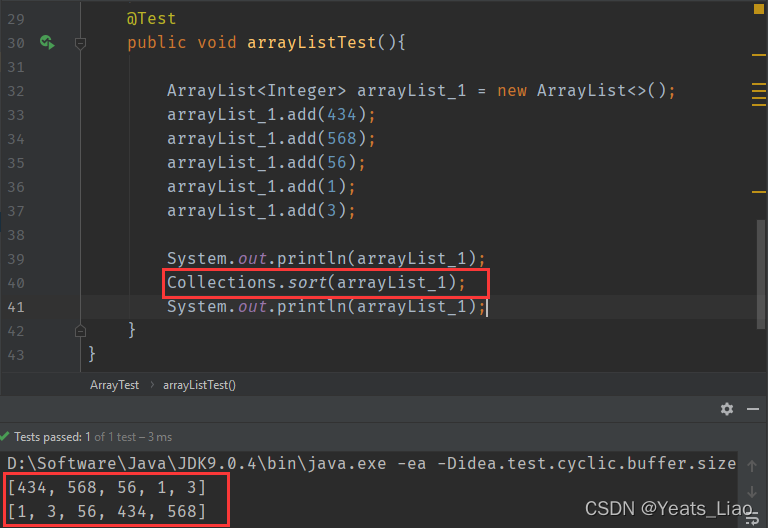
.sort()方法用于排序,默认从小到大
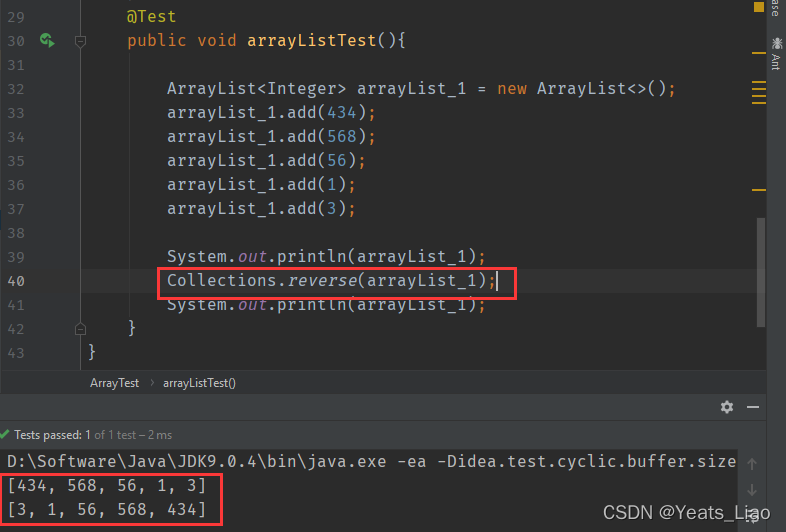
.reverse()方法用于置反集合
.subList()方法用于切割容器,需要注意截止于前一个元素

7. Linked链表
ArrayList数组集合,增删慢,查询快LinkedList链表集合,增删快,查询慢
8. LinkedList一带而过
- 链表是数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的地址
- 链表可分为单向链表和双向链表
- Java
LinkedList类似于ArrayList,是一种常用的数据容器

9. 提醒
- 多看JDK文档,多练习,把基础打好
10. iterator 迭代器初试
- 迭代是重复反馈过程的活动,其目的通常是为了接近并到达所需目标或结果
- 每一次对过程的重复被称为一次“迭代”,而每一次迭代的结果会被用来作为下一次迭代的初始值
迭代器Iterator,不管用于ArrayList还是LinkedList都可以迭代输出

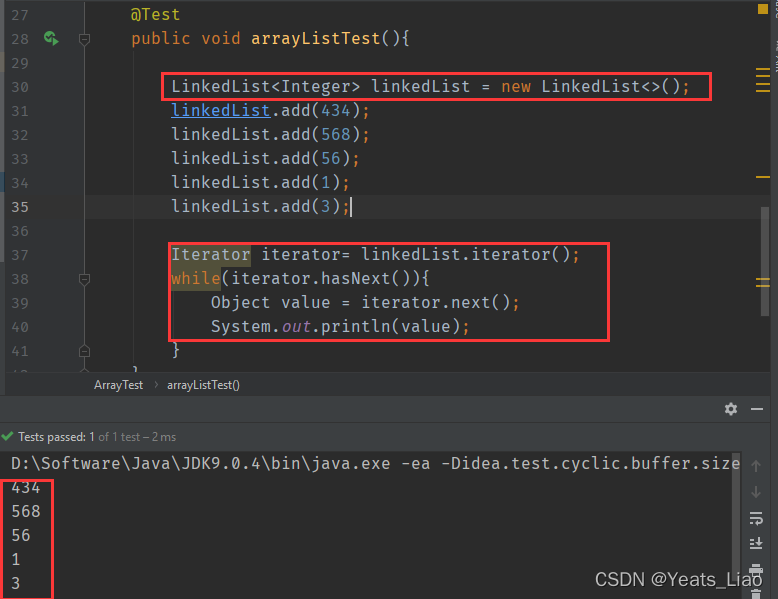
迭代器类似用链表的形式去迭代,也可以指定泛型

11. fori、增强for、迭代器的区别、注意事项和分别用途
fori适合数据的读取与修改for each适合数据的读取Iterator不要使用嵌套,适合数据的读取与修改
for each绝对不能与.remove()方法一起使用,危险会导致所有数据删除

for each已经是一个小型的迭代器了,如果一定要修改集合的话可以使用迭代器,但不建议在for each中使用对象引用去修改元素
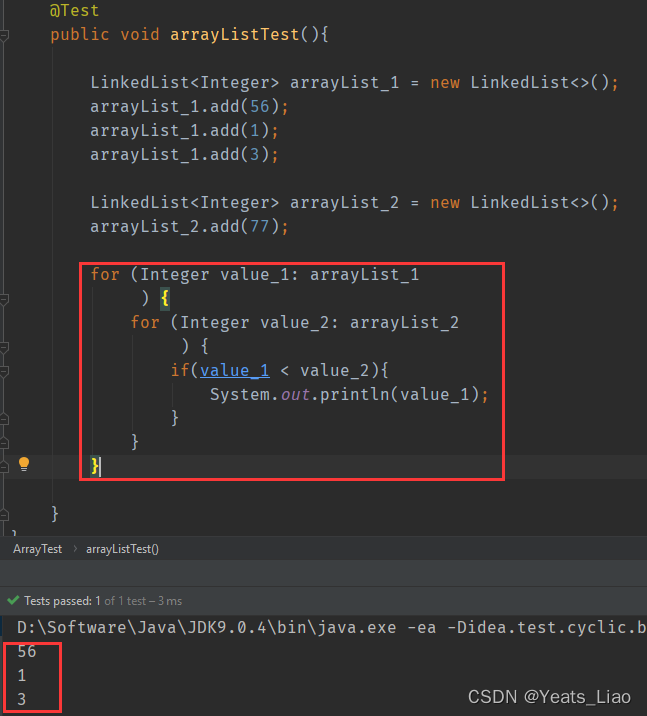
12. 谈谈三者性能
比较时间复杂度,foreach和迭代器谁更快呢?
- 如果是
ArrayList,用三种方式遍历的速度是for>Iterator>foreach,速度级别基本一致,一般都会用for或者for each,因为Iterator写法相对复杂一些 - 如果是
LinkedList,则三种方式遍历的差距很大了,数据量大时越明显,Iterator>foreach>>>for,推荐使用foreach或者Iterator
13. Set和HashSet
HashSet基于HashMap来实现的,是一个不允许有重复元素的集合,允许有 null 值,是无序的,即不会记录插入的顺序HashSet不是线程安全的, 如果多个线程尝试同时修改HashSet,则最终结果是不确定的,必须在多线程访问时显式同步对HashSet的并发访问
HashSet 实现了 Set 接口
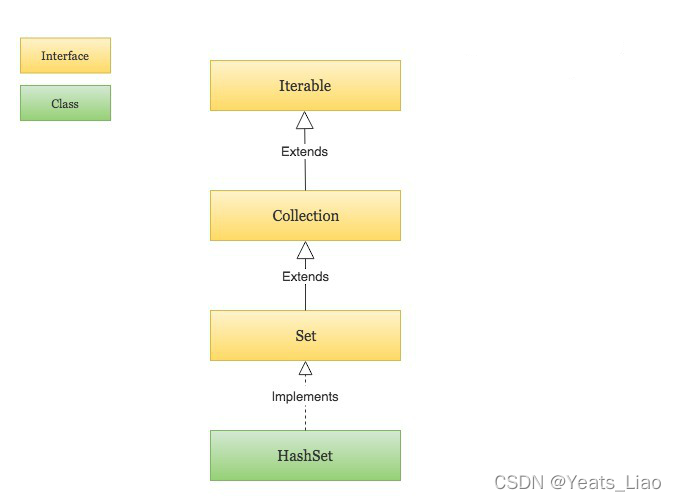
使用Hash函数实现HashSet,元素无序,且不重复

14. LinkedHashSet
如果要创建有序集合呢?LinkedHashSet便是有序的

15. Map、HashMap、Entry
java.util.Map下的接口和继承类关系简易结构图:

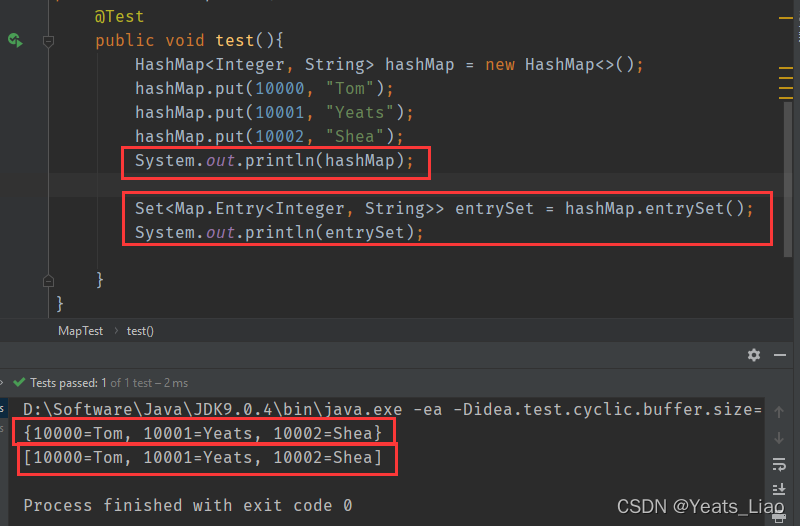
HashMap是映射关系,即键Key值Value对
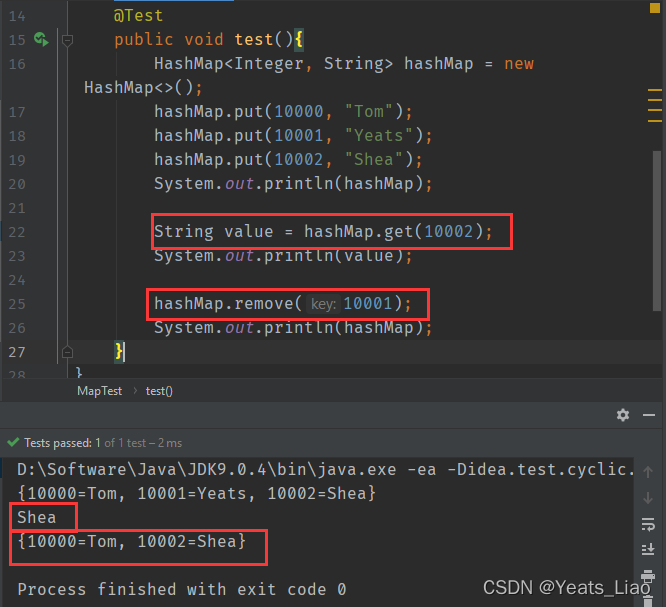
HashMap不能使用迭代器Iterator

.replace()方法可以替换键Key对应的值Value

让Key以集合形式输出,.keySet()方法返回值是HashMap中Key值的集合
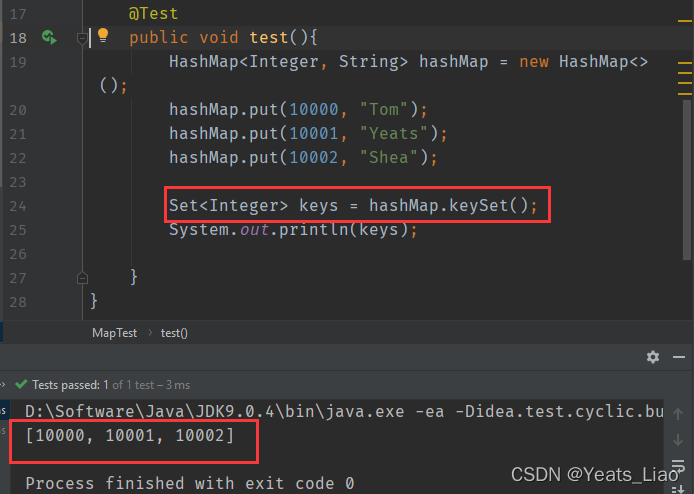
让HashMap以集合形式输出, .entrySet()方法的返回值也是Set集合
16. Map注意点
已经存在的键值对,再次.put()会替换原来的,.get()不存在的值会返回null

17. Entry与Map转换Set之后遍历: Iterator<Entry<Integer,Integer>> iterator = entrySet.iterator(); (什么?看不懂这行?)
Entry就是用来管理键值对对象的,将对象包裹起来,提供遍历的方式Entry可以使用迭代器,筛选值,但只适合在内存中使用,不适用于JDBC

18. 提及 LinkedHashMap以及课后作业
HashMap是无序的,可以自定义泛型,而LinkedHashMap相当于有序的HashMap,可以自己写一个包括增删改查的学生管理系统了

19. 集合框架部分结束
剩下的类需要自己去学习了!了解各类是怎么实现的,以及其之间的区别,JDK的新特性暂时用不到,还没学习到框架

- 点赞
- 收藏
- 关注作者
评论(0)