RTOS中如何确定使用栈的大小

@TOC
前言
本篇文章将带大家学习在FreeRTOS中怎么样去确认栈的大小,在确认栈的大小后就可以根据实际情况来分配栈空间,防止栈空间被浪费。
一、生成反汇编文件
首先我们来看一下什么是汇编文件,什么是反汇编文件:
汇编文件 (.s 文件):
定义:在嵌入式系统中,汇编文件通常是指包含汇编语言代码的文本文件,其中的指令和数据使用特定的汇编语法表示。这些文件以 .s 作为文件扩展名。
作用:汇编文件用于编写底层的系统级代码,通常包括中断服务程序、启动代码、设备驱动程序等。它们直接与硬件交互,并对系统资源进行管理。
例如,一个嵌入式系统的汇编文件可能包含了与硬件设备通信的指令,如对寄存器的读写、对外设的控制等。
反汇编文件 (.dis 文件):
定义:反汇编文件是从已编译的二进制文件(如可执行文件、固件文件等)生成的汇编语言代码文件。这些文件以 .dis 作为文件扩展名。
作用:反汇编文件用于分析已编译程序的底层运行机制,通常用于调试、优化和逆向工程等任务。
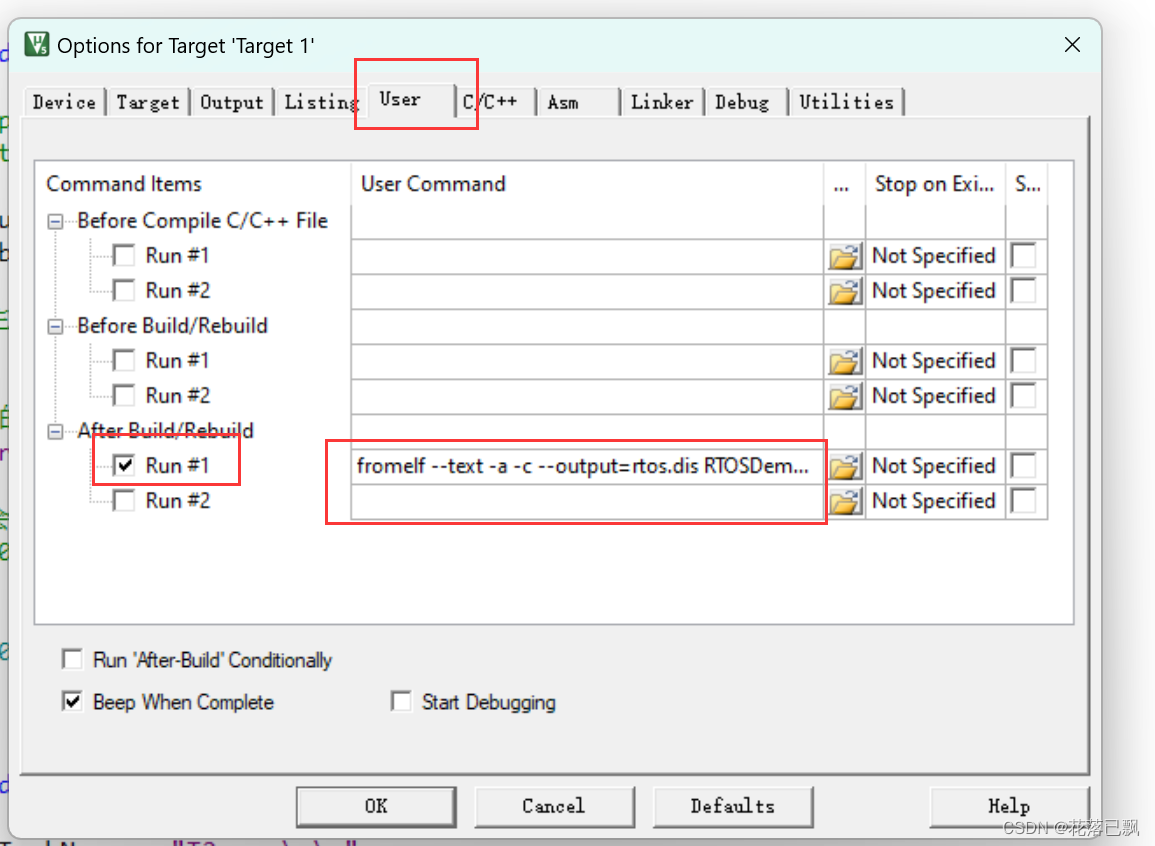
我们会通过keil5来生成反汇编文件来查看如何估算栈的大小:
使用下面这句话可以将.axf文件生成.dis文件:
fromelf --text -a -c --output=xxx.dis xxx.axf
让我们逐步解释每个参数的含义:
–text:这个选项告诉 fromelf 工具将输出的内容以文本形式显示。这意味着输出将以可读的文本格式呈现,而不是二进制格式。
-a:这个选项告诉 fromelf 工具生成汇编伪指令(assembly pseudo-instructions)。这样生成的反汇编文件将包含一些更易读的汇编指令,而不是完全的机器码。
-c:这个选项告诉 fromelf 工具在输出时显示注释。注释通常包含有关代码和数据的信息,有助于理解反汇编输出。
–output=xxx.dis:这个选项指定了输出文件的名称,其中 xxx.dis 是你希望生成的反汇编文件的文件名。反汇编文件将被写入到这个文件中。
xxx.axf:这是输入的 ARM 可执行文件(.axf 文件)的名称。fromelf 将会对这个文件执行反汇编操作,并根据指定的参数生成相应的输出文件。
二、粗略估计栈大小
首先在任务中使用一个数组,任务相当于就是一个函数,那么在任务中定义出来的数组就是保存在栈中的。
void vTask1( void *pvParameters )
{
volatile int buff[100];//定义出数组
strcpy((char*)buff, "Hello");
/* 任务函数的主体一般都是无限循环 */
for( ;; )
{
/* 打印任务1的信息 */
printf( "T1 run\r\n" );
vTaskDelay(10);
}
}
编译生成反汇编文件查看对应的函数:
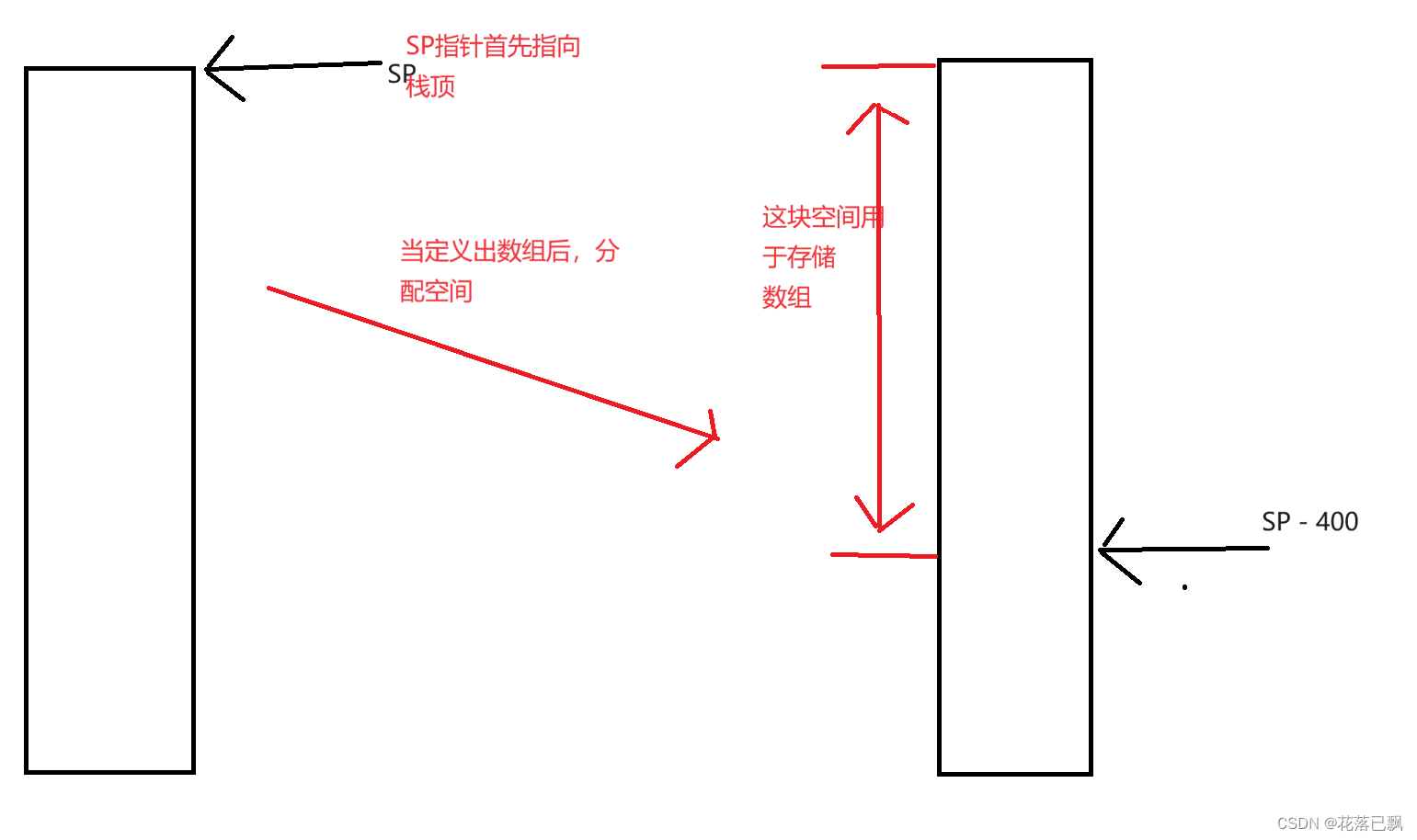
进入函数一开始就可以看到SUB sp,sp,#0x190这段汇编指令。
这段指令的含义如下:
将当前栈指针的值减去 400,并将结果存储回栈指针寄存器中。

定义出局部的数组后SP指针会向下移动。
这里可以知道定义的局部变量越多那么所需要的栈空间也是越大的。
根据函数调用链来判断所需要栈的大小:
分析函数调用:
从主函数开始,沿着函数调用链分析程序的执行路径。
记录每个函数调用时,当前函数的局部变量、参数、返回地址等需要存储在栈上的数据。
计算局部变量大小:
对于每个函数,计算所有局部变量所需的总大小。
局部变量的大小是其数据类型大小的总和。
考虑函数调用的深度:
对于递归函数或者多层嵌套的函数调用,需要考虑函数调用的深度。
每次函数调用都会在栈上增加一层新的栈帧,包含函数的局部变量、参数、返回地址等。
计算其他需要存储的信息:
除了局部变量,还需要考虑参数、返回地址、临时寄存器等信息。
一些编译器可能会为函数调用保存一些额外的状态信息,如寄存器的保存。
计算总的栈大小:
将以上计算得到的每个函数所需的栈大小累加起来,得到整个函数调用链所需的栈大小。
现在在vTask1任务中调用了stack函数,stack函数中也会使用到局部数组,那么这个时候就需要把所stack函数中使用到的栈和vTask1中定义的栈都计算出来。
void stack(void)
{
char stack_buff[100];
strcpy(stack_buff, "Hello");
}
void vTask1( void *pvParameters )
{
volatile int buff[100];//定义出数组
strcpy((char*)buff, "Hello");
/* 任务函数的主体一般都是无限循环 */
for( ;; )
{
/* 打印任务1的信息 */
printf( "T1 run\r\n" );
vTaskDelay(10);
}
}
三、在任务中调用多个函数这些函数的栈是怎么样的?
在vTask1中调用了stack1和stack两个函数,下面我们来分析一下他们的栈分布。
void stack(void)
{
char stack_buff[100];
strcpy(stack_buff, "Hello");
}
void stack1(void)
{
char stack_buff[100];
strcpy(stack_buff, "Hello");
}
void vTask1( void *pvParameters )
{
volatile int buff[100];//定义出数组
strcpy((char*)buff, "Hello");
stack();
stack1();
/* 任务函数的主体一般都是无限循环 */
for( ;; )
{
/* 打印任务1的信息 */
printf( "T1 run\r\n" );
vTaskDelay(10);
}
}
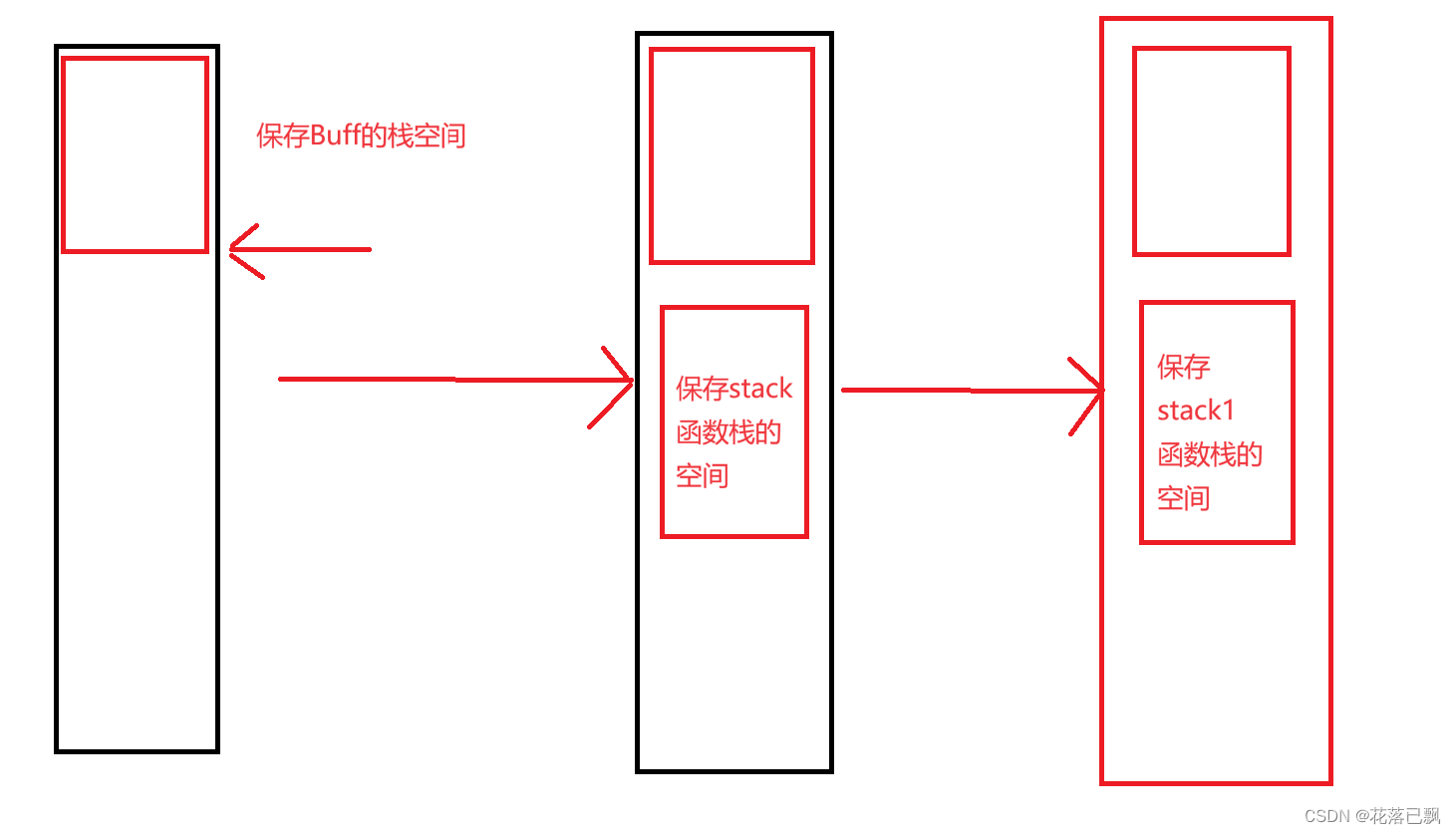
很多同学会认为这三个数组会保存在同一个栈中的,但是结果确是下面这样的。
那么下面来讲解一下这个原理:
函数调用过程:
当一个函数被调用时,系统会执行一系列操作来为该函数创建一个新的执行环境,这个执行环境被称为栈帧(stack frame)或活动记录(activation record)。
这个栈帧用于存储函数调用时所需的各种信息,如参数、局部变量、返回地址等。
栈的创建:
当函数被调用时,系统会在当前栈顶分配一块新的内存空间作为新的栈帧。
这个新的栈帧将用于存储函数的局部变量、参数和其他必要的信息。
函数的参数会被复制到栈帧中的指定位置,局部变量也会在栈帧中分配空间。
函数执行:
在函数执行过程中,系统可以通过栈帧来访问函数的参数和局部变量。
函数执行期间,栈帧中的数据可以被读取、修改和使用。
函数调用的完成:
当函数执行完成时,系统会销毁该函数的栈帧。
这意味着栈顶会恢复到调用该函数之前的状态,原来的栈帧将被释放。
释放栈帧时,系统会回收该栈帧所占用的内存空间,以便后续的函数调用可以重用该空间。
返回值传递:
在函数调用完成时,系统会将函数的返回值(如果有的话)传递给调用者。
返回值通常会存储在调用者的栈帧中的指定位置,以便调用者可以访问和使用它。
四、栈大小的准确计算
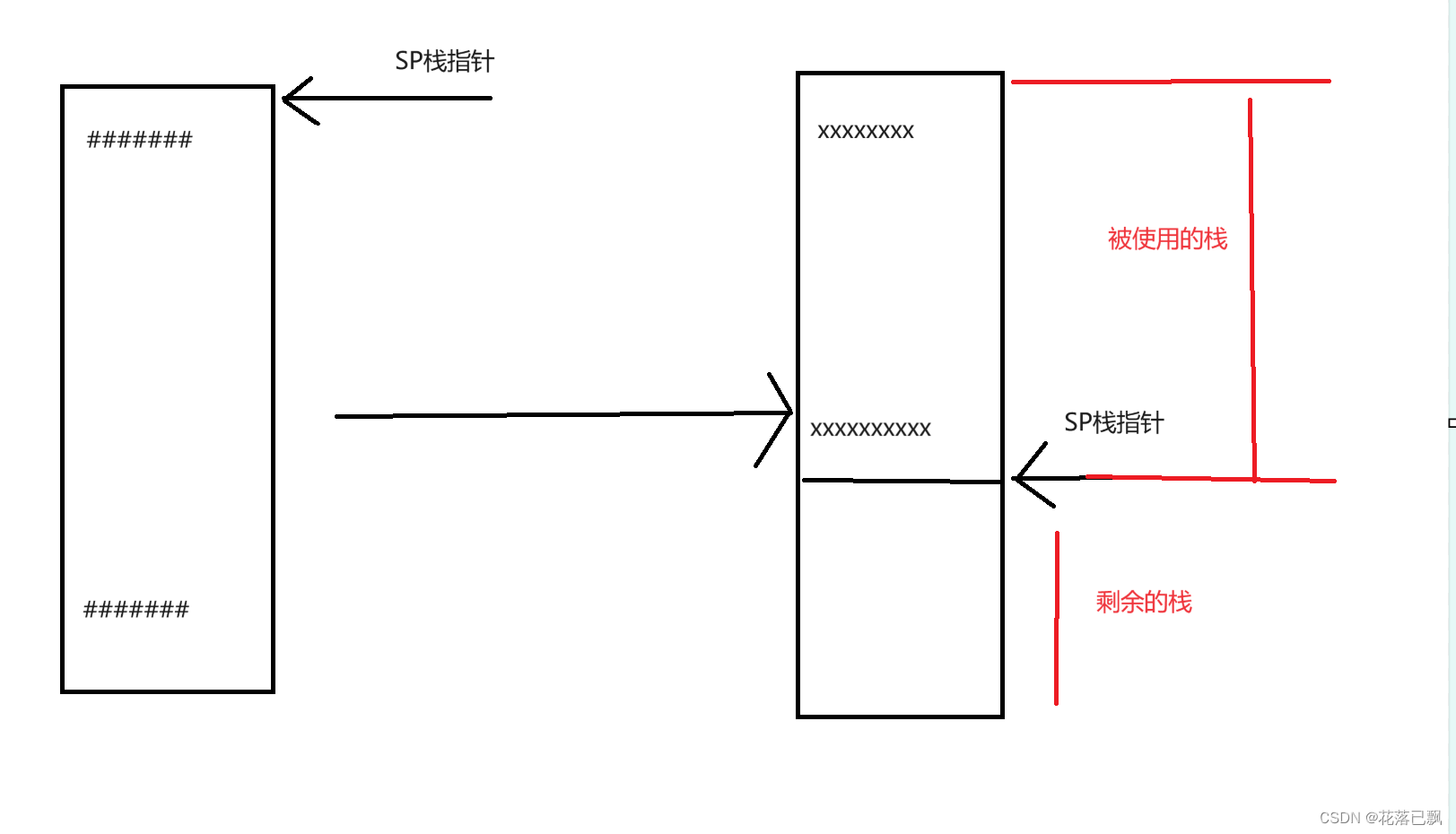
在使用rthread创建任务的时候首先会将栈里面的数据全部设置成#。
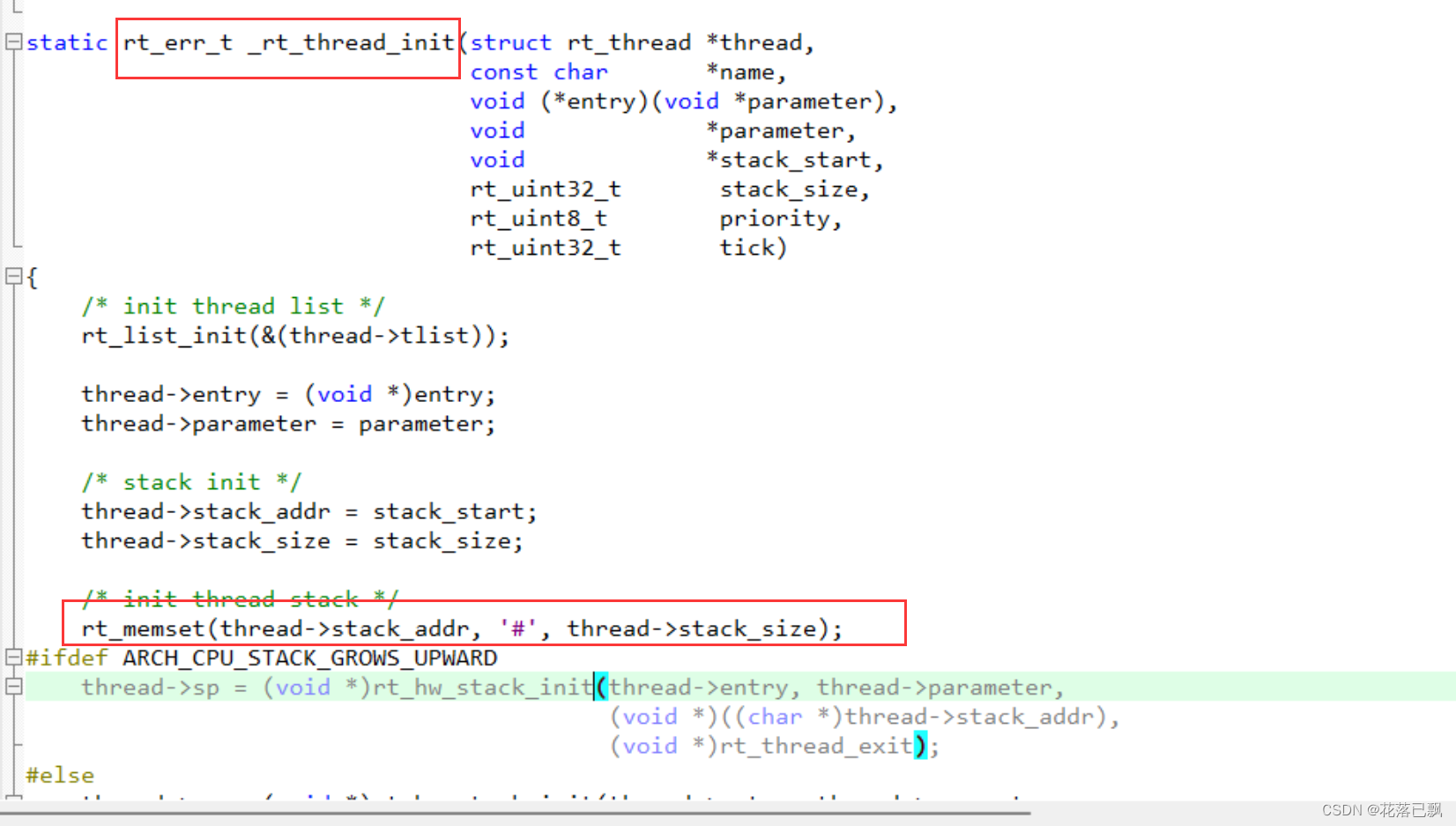
当使用了栈后#就会被设置为其他的内容,此时就可以根据#的位置来判断栈使用了多少。
总结
本篇文章主要讲解了如何确定栈的大小,大家也可以尝试去查看一下栈有什么作用,以及如何计算栈的大小。

- 点赞
- 收藏
- 关注作者
评论(0)