DNAscope白皮书: 基于机器学习的高精度胚系变异检测流程

DNAscope模块,是Sentieon软件的一个精准高效的胚系变异检测模块。其在GATK基础上优化了核心算法,在继承GATK成熟且完整的BAM预处理流程的同时,引入机器学习基因分型模型。相比于GATK金标准而言,在大幅降低计算成本的情况下,DNAscope流程能够大幅度提升SNP和Indel的检测准确度和稳定性。

GATK HaplotypeCaller由于其准确性高已成为胚系短变异检测的行业标准,在公开发表的第三方基准测试中都取得了最佳性能。然而,包括HaplotypeCaller在内的基于短读长序列技术的变异检测流程所检测出来的变异位点与高置信度真集并不能完美匹配,尤其是在基因组的复杂区域,如单碱基多聚体和其他重复位点。这些复杂区域很多都是与临床相关的,随着NGS在临床分析中的使用越发频繁,提高这些区域变异识别的准确度将变得越来越重要。
GATK在复杂区域的限制

GATK在reads比对排列复杂区域无法进行局部重头组装;
GATK在基因组的特定区域无法进行组装,产生了特定的盲点;
GATK可能会丢失单倍型之前的联系,无法生成最准确的单倍型序列。
此前,大多数变异检测工具使用的是构建统计模型进行变异位点基因分型,并通过设置手动调节过滤参数来消除变异识别的假阳性。虽然这些过滤器在大多数情况下运行良好,但基于机器学习的假阳性位点过滤及基因分型则可通过学习变异特征之间更复杂的关系来提高准确性,因此相较于传统的显式统计模型,机器学习模型在改进变异过滤及基因分型中的应用越来越广泛,并逐渐成为主流的解决方案。
DNAscope将基于单倍型拼接的变异检测与机器学习模型结合,从而实现更高的准确性。DNAscope在GATK HaplotypeCaller类似的逻辑体系结构基础上,对活性区域检测和局部组装等模块进行了优化,尤其是在高复杂度区域,可有效提高灵敏度和鲁棒性。当应用机器学习模型时,DNAscope会输出带有额外注释信息的候选变异列表,然后将这些被注释的候选变异传递到机器学习模型中进行基因分型,从而提高了变异检测和基因分型的准确性。
DNAscope方法概述
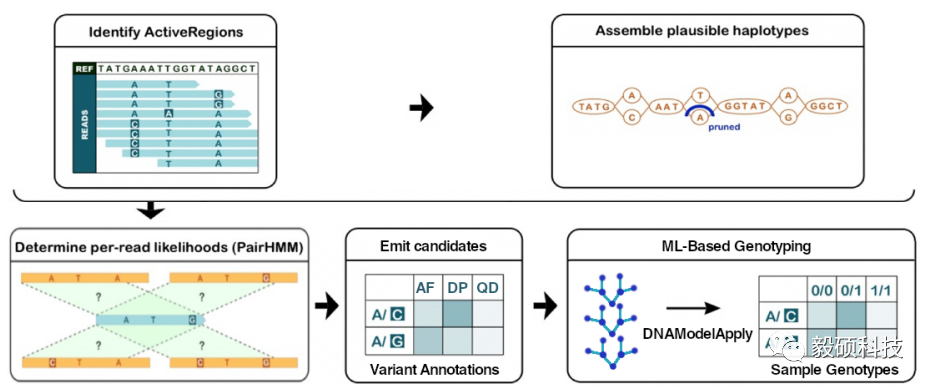
DNAscope遵循与GATK HaplotypeCaller类似的算法流。首先将可能存在遗传变异的位点确定为活跃区域,然后使用de Bruijn图对跨活动区域比对的序列reads进行局部组装,并通过PairHMM计算 read-haplotype的可能性,从而输出带有额外注释信息的候选变异列表,并传递到基于机器学习的基因分型模型中进行处理,以确定最终正确的变异基因型。
DNAscope评测
为了评估DNAscope 的变异检测准确度,我们将3个测序深度约为36x的GIAB样本(HG002,HG003和HG004)分别进行降采样得到5个覆盖深度15x-36x的数据集作为测试集,并采用Sentieon的DNAscope和DNAseq(匹配GATK结果)标准流程进行测试。DNAscope的性能评测参考的是美国国家标准与技术研究所 (NIST) 于2021年下半年发布更新的GIAB high-confidence calls v4.2.1,该版本的真集涵盖了对二代测序来说较为困难的区域,所以准确率等指标不能和旧版真集的评测数据进行直接对比。此外,这里我们还省略了会导致F1-scores下降的变异位点质量值重新校正(VQSR)的步骤。
评测结果显示,对于SNP和INDEL,DNAscope在所有测试集中的灵敏度(recalls)和特异性(precisions) 都显著高于DNAseq。例如在30x的HG002数据集中,DNAscope 的 SNP 和 INDEL 的 F1-score分别高达99.57% 和 99.46%。此外,相较于DNAseq,DNAscope的错误变异检测结果降低了1倍以上(87607到34634);同时在多个数据集的测试结果中表明,DNAscope没有出现模型过拟合的情况。另外值得一提的是,模型文件和测序平台可以特异性适配,这在已发表的华大测序仪模型的性能评测文章中有印证,说明了DNAscope可以适配新的测序技术。
DNAscope VS DNAseq灵敏度曲线
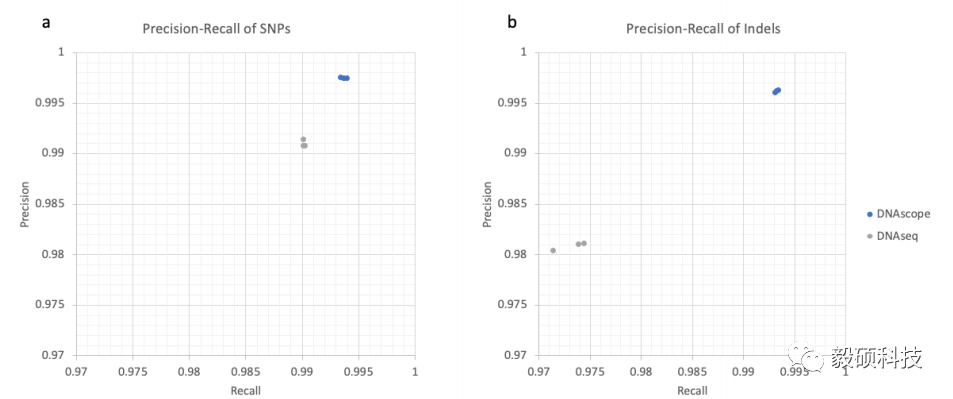
图a-b分别为30x HG002、HG003和HG004样本的SNPs 及 Indels评测结果。DNAscope结果准确度总体高于DNAseq。
对全基因组进行多层次的分区分析能够更好地体现分析工具的准确性和稳健度,特别是在低可比对区域等的复杂区域,这些区域的变异检测准确性评估能够更加全面地展示分析工具的检测性能。因此,我们采用了全球基因组学与健康联盟(Global Alliance for Genomics and Health,GA4GH)的标准对基因复杂区域进行多层次分区分析,以评估DNAscope和DNAseq的准确度。下图显示DNAscope的综合分析性能较DNAseq更为出色,尤其在复杂区域的分析精确度较DNAseq有较大幅度的提升。
30x HG002的GA4GH分区评估
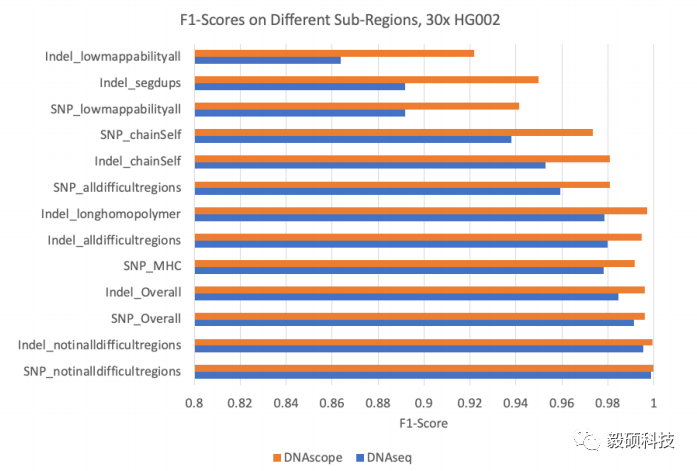
图a-b分别为30x HG002、HG003和HG004样本的SNPs 及 Indels评测结果。DNAscope结果准确度总体高于DNAseq。
我们同样使用HG002、HG003和HG004三个样本分别进行降采样得到的5个不同测序深度的数据集来评估两个分析流程变异检测精确度随测序深度的变化波动情况。测试结果符合预期,两个流程在低深度的精确度相较于高深度都有一定程度的下降。而DNAscope由于对算法架构进行了整体优化,同时引入了机器学习模型,以至于DNAscope下降的幅度相对较低,值得一提的是,DNAscope在20x的准确度表现已经优于与DNAseq流程在36x的表现。
HG002、HG003、HG004多测序深度分析
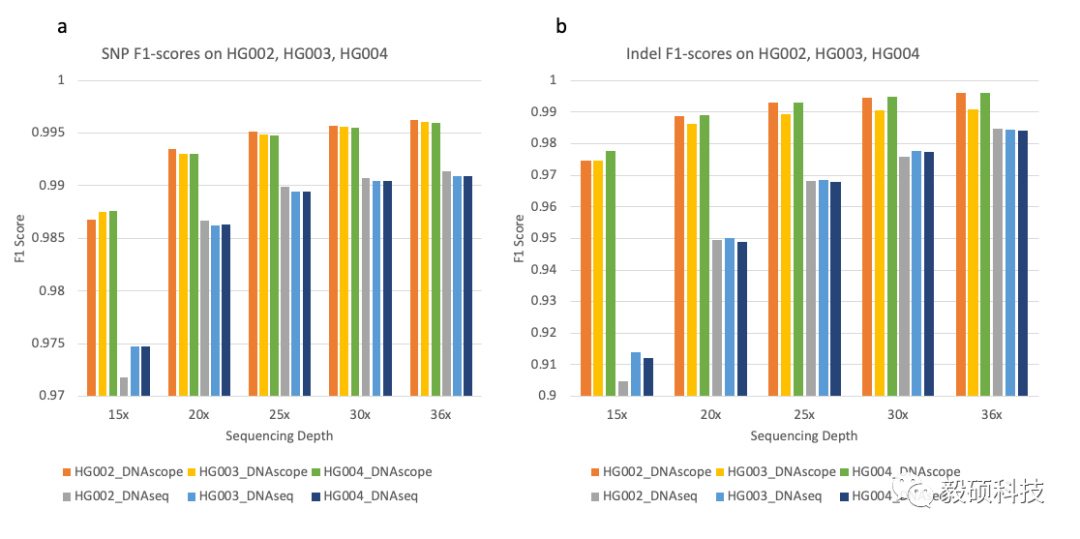
图a-b分别显示DNAscope和DNAseq 分析结果SNP及Indel的 F1评分。
多倍体重测序在农业基因组研究中十分普遍,但DNAscope的机器学习模型是基于二倍体样本建立的,所以当前版本的DNAscope并不支持非二倍体样本的分析。对此,我们尝试用DNAscope内置的贝叶斯基因分型模型(Bayesian genotyping model)对15x测序深度样本进行精确度评估,来模拟较难进行高深度测序的大型基因组序列分析。正如预期,DNAscope的贝叶斯基因分型模型整体的精确度比机器学习模型低,但在INDEL的表现上仍优于DNAseq,在SNP方面则与DNAseq表现相当。
15X HG002、HG003和HG004样本分析
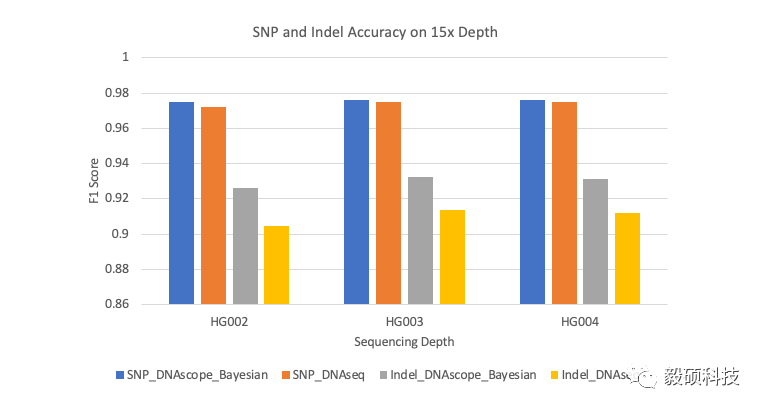
DNAscope_Bayesian以及DNAseq对15x测序深度的HG002、HG003和HG004样本进行分析的精确度对比,图中显示SNP及Indel结果的 F1评分。
最后我们也在标准云计算环境下对 DNAscope的运行速度进行了基准测试。我们在4个AWS C6i实例上分别对30x的HG002测序数据进行分析。如下图所示,在计算规模为96线程或以上时,DNAscope完成一个30x的测序数据分析用时低于1小时,分析速度与DNAseq相当且比开源的BWA/GATA分析流程快了将近5倍。此外,测试结果显示,DNAscope分析速度几乎与使用线程数呈线性关系,由此说明DNAscope的可扩展性优异,可对运算资源进行有效利用。
DNAscope并行计算扩展性评测
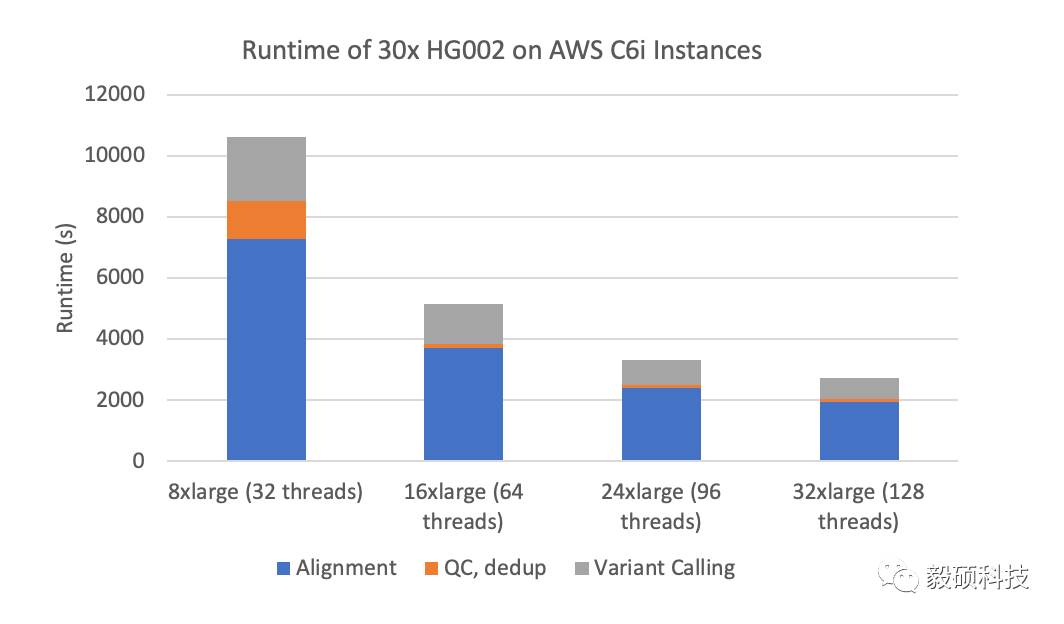
DNAScope在多个AWSC6i实例上的运行耗时。图中显示每个实例类型不同运行阶段的时长。
DNAscope评测结论
总体而言,DNAscope在不同的样本和测序深度下,精准度高于DNAseq。GA4GH基因区域多层次分区分析的结果表明,DNAscope在大多数复杂区域都能维持卓越的准确度表现。此外,DNAscope在融合了GATK HaplotypeCaller完整数学模型的基础上,引入机器学习技术,在实现高准确性的同时,保持优异的计算效率。
- 在30x的测序深度下,DNAscope在SNP与Indel变异检测中都达到了99.5%左右的准确度(F1-score),相比于GATK总体错误个数降低了两倍多,展现了显著的准确率提升。
- 在基因组分区分析中,发现DNAscope在比对(mapping)困难的高复杂区域,例如MHC区域中,相比GATK有着更加显著的准确度优势。
- 当测序深度降低时,DNAscope也可以保持相对较高的准确率,例如20x的DNAscope分析准确率已经超越了36x的GATK结果。
- DNAscope速度比GATK快5-10倍,在96线程节点上可以1小时完成30x全基因组数据分析。
- 支持非人物种分析,在使用内置贝叶斯模型分析15x深度数据时,准确率高于GATK流程。
DNAscope方法学
候选变异检测中的方法改进
Sentieon的Haplotyper (DNAseq)复现了GATK HaplotypeCaller数学模型,在做到结果高度匹配的同时还提高了算法的运行效率。Haplotyper 和 DNAscope 都使用与 HaplotypeCaller 相同的算法架构,包括活性区域检测、局部组装、基因型计算;同时通过去除降采样,实现软件的方法改进,资源管理优化等技术提高鲁棒性。此外, DNAscope 还包含其他的算法改进及下文所介绍的变异位点注释。
变异位点注释
DNAscope 新增了GATK 流程中所没有的额外的变异位点注释,这些额外添加的注释与原有标准注释将共同在基因分型过程中被输入到机器学习模型中。新增注释如下:
Entropy:定义为在局部组装过程中,所有被识别的单倍型的香农熵(Shannon entropy)。高熵(high entropy)是可能存在序列比对位置错误或比对结果错误的指标。
UDP:所有输入样本未经过滤的测序深度。该指标类似于深度“DP”,但是“DP”统计中会删除比对质量低或比对错误可能性高的序列。
NBQ:变异位点本身及其两边各5bp区域的的所有位点的平均碱基质量。
ReadPosEndDist:该变异位点到所有覆盖序列两端的平均距离。
基于模型的基因分型
DNAscope基因分型模型的设计能够将真实的胚系变异从系统噪声中分辨出来。通过机器学习,识别文库构建,测序和序列比对过程中出现的错误范式(error patterns),从检测困难区域提取有用信息。为了在分析准确性与计算效率方面超过深度学习方法,我们选择梯度提升机(Gradient Boosting Machines,GBMs)作为框架来学习结构化基因数据的错误范式。GBMs通过连续建立决策树,以序列集成的方式训练弱基学习器(base learner),逐步减少残差。在此过程中,模型通过学习率来控制每个基学习器的逐步改进过程,一旦在验证过程中观察到过拟合就可以尽早中止训练过程。
我们使用来自不同数据源的GIAB HG001和HG005(不含20号染色体)的标准品样本训练模型,其中90%的变异位点用作训练集,剩余的10%作为验证集,以优化模型的复杂度,在性能与泛用性方面寻求平衡,同时防止过拟合。模型过滤步骤的输入是高灵敏度模式下运行的DNAscope生成的VCF文件,此模式下只需要少量的序列支持就能够检测出候选的变异位点。随后,假定样本在所有位点上都是二倍体条件下,模型利用VCF 输出文件的位点注释作为特征将候选位点分类为4种基因型:“0/0”、“0/1”、“1/1”、“1/2”。基因型“0/0”表示报告的候选变异位点实际和参考基因组一致,并不是真实的变异位点。从最终变异位点列表VCF中可以看出,DNAscope 基因分型模型大大降低了错误发现率(false discovery rate),在赋予样本基因型的同时保持较高的灵敏度。此外,模型还在最终VCF文件中添加了“ML_PROB”注释,即模型计算出的此位点为假阳性的可能性。
测试基准
测试所使用的FASTQ数据均来自于公开数据,在“数据”部分有详细说明。
所有的FASTQ数据均使用标准化数据处理流程进行处理,包括使用经Sentieon优化的BWA-MEM v202112.01进行序列比对;使用v202112.01版本的Sentieon模块标记重复;使用 SAMtools v1.3.1(适用于某些样本)进行降采样;使用 DNAscope v202112.01、DNAscope Illumina 模型 v1.0和Haplotyper 202112.01进行变异检测;使用 hap.py v0.3.10( RTGtools vcfeval v3.8.2作为引擎),比对NIST真集v4.2.1用于进行变异位点准确性评估。
文件和工具
分析期间生成的中间文件和输出文件可以在 gs://dnascope-benchmarking 中找到。
使用 Google Colaboratory 上的交互式和协作式 Jupyter 笔记本分析 Hap.py 输出和其他输出文件。
相关链接
原文链接:https://www.biorxiv.org/content/10.1101/2022.05.20.492556v1
DNAscope模块帮助文档:https://support.sentieon.com/manual/DNAscope_usage/dnascope/
GIAB公共数据下载地址:ftp://ftp-trace.ncbi.nlm.nih.gov/giab/ftp/
DNAscope Machine Learning Model:https://github.com/Sentieon/sentieon-dnascope-ml

- 点赞
- 收藏
- 关注作者
评论(0)