DFCNN + Transformer模型完成中文语音识别(一)

DFCNN + Transformer模型完成中文语音识别
语音识别,通常称为自动语音识别,(Automatic Speech Recognition,ASR),主要是将人类语音中的词汇内容转换为计算机可读的输入,一般都是可以理解的文本内容,也有可能是二进制编码或者字符序列。但是,我们一般理解的语音识别其实都是狭义的语音转文字的过程,简称语音转文本识别( Speech To Text, STT )更合适,这样就能与语音合成(Text To Speech, TTS )对应起来。
语音识别系统的主要流程如下图所示。

本实践任务为搭建一个基于深度学习的中文语音识别系统,主要包括声学模型和语言模型,能够将输入的音频信号识别为汉字。
本实践使用的模型均为近年来在语音识别深度学习领域中表现较为突出的模型,声学模型为 DFCNN,语言模型为 Transformer,下面开始进行实践。
注意事项:
-
本案例使用框架**:** TensorFlow-1.13.1
-
本案例使用硬件规格**:** 8 vCPU + 64 GiB + 1 x Tesla V100-PCIE-32GB
-
切换硬件规格方法**:** 如需切换硬件规格,您可以在本页面右边的工作区进行切换
-
运行代码方法**:** 点击本页面顶部菜单栏的三角形运行按钮或按Ctrl+Enter键 运行每个方块中的代码
-
JupyterLab的详细用法**:** 请参考《ModelAtrs JupyterLab使用指导》
-
碰到问题的解决办法**:** 请参考《ModelAtrs JupyterLab常见问题解决办法》
1.准备源代码和数据
准备案例所需的源代码和数据,相关资源已经保存在 OBS 中,我们通过 ModelArts SDK 将资源下载到本地。
import os
import subprocess
from modelarts.session import Session
session = Session()
if session.region_name == 'cn-north-1':
bucket_path = 'modelarts-labs/notebook/DL_speech_recognition/speech_recognition.tar.gz'
elif session.region_name == 'cn-north-4':
bucket_path = 'modelarts-labs-bj4/notebook/DL_speech_recognition/speech_recognition.tar.gz'
else:
print("请更换地区到北京一或北京四")
if not os.path.exists('speech_recognition'):
session.download_data(bucket_path=bucket_path, path='./speech_recognition.tar.gz')
subprocess.run(['tar xf ./speech_recognition.tar.gz;rm ./speech_recognition.tar.gz'], stdout=subprocess.PIPE, shell=True, check=True)
上一步下载了speech_recognition.tar.gz,解压后文件夹结构如下:
speech_recognition
│
├─── data
│ ├── A2_0.wav
│ ├── A2_0.wav.trn
│ ├── A2_1.wav
│ ├── A2_1.wav.trn
│ ├── A2_2.wav
│ ├── A2_2.wav.trn
│ │ :
│ │ :
│ │ :
│ ├── A36_249.wav
│ └── A36_249.wav.trn
│
├─── acoustic_model
├─── language_model
└─── data.txt
2.数据集——THCHS-30
THCHS30是一个经典的中文语音数据集,包含了1万余条语音文件,大约40小时的中文语音数据,内容以新闻文章诗句为主,全部为女声。THCHS-30是在安静的办公室环境下,通过单个碳粒麦克风录取的,采样频率16kHz,采样大小16bits,录制对象为普通话流利的女性大学生。
thchs30数据库大小为6.4G。其中,这些录音根据其文本内容分成了四部分,A(句子的ID是1-250),B(句子的ID是251-500),C(501-750),D(751-1000)。ABC三组包括30个人的10893句发音,用来做训练,D包括10个人的2496句发音,用来做测试。其具体的划分如下表所示:
| 数据集 | 音频时长(h) | 句子数 | 词数 |
|---|---|---|---|
| train(训练) | 25 | 10000 | 198252 |
| dev(验证) | 2:14 | 893 | 17743 |
| test(测试) | 6:15 | 2495 | 49085 |
THCHS-30数据集可从 http://www.openslr.org/18/ 下载。其他常用的开源中文语音数据集还有 Aishell、Free ST Chinese Mandarin Corpus、Primewords Chinese Corpus Set、aidatatang_200zh 等,均可以从 http://www.openslr.org/resources.php 下载。
THCHS-30语音数据格式为.wav,对应的拼音和汉字的文本文件格式为.wav.trn。
在本实践中,选取A部分语音均放在data文件夹下进行训练和测试。
同时将所有数据的拼音和汉字文本整理在data.txt文件中,以方便使用。下面为读取data.txt文件十条内容。
with open('./speech_recognition/data.txt',"r", encoding='UTF-8') as f: #设置文件对象
f_ = f.readlines()
for i in range(10):
for j in range(3):
print(f_[i].split('\t')[j])
print('语音总数量:',len(f_),'\n')
A11_0.wav
lv4 shi4 yang2 chun1 yan1 jing3 da4 kuai4 wen2 zhang1 de di3 se4 si4 yue4 de lin2 luan2 geng4 shi4 lv4 de2 xian1 huo2 xiu4 mei4 shi1 yi4 ang4 ran2
绿是阳春烟景大块文章的底色四月的林峦更是绿得鲜活秀媚诗意盎然
A11_1.wav
ta1 jin3 ping2 yao1 bu4 de li4 liang4 zai4 yong3 dao4 shang4 xia4 fan1 teng2 yong3 dong4 she2 xing2 zhuang4 ru2 hai3 tun2 yi4 zhi2 yi3 yi1 tou2 de you1 shi4 ling3 xian1
他仅凭腰部的力量在泳道上下翻腾蛹动蛇行状如海豚一直以一头的优势领先
A11_10.wav
pao4 yan3 da3 hao3 le zha4 yao4 zen3 me zhuang1 yue4 zheng4 cai2 yao3 le yao3 ya2 shu1 di4 tuo1 qu4 yi1 fu2 guang1 bang3 zi chong1 jin4 le shui3 cuan4 dong4
炮眼打好了炸药怎么装岳正才咬了咬牙倏地脱去衣服光膀子冲进了水窜洞
A11_100.wav
ke3 shei2 zhi1 wen2 wan2 hou4 ta1 yi1 zhao4 jing4 zi zhi1 jian4 zuo3 xia4 yan3 jian3 de xian4 you4 cu1 you4 hei1 yu3 you4 ce4 ming2 xian3 bu2 dui4 cheng1
可谁知纹完后她一照镜子只见左下眼睑的线又粗又黑与右侧明显不对称
A11_102.wav
yi1 jin4 men2 wo3 bei4 jing1 dai1 le zhe4 hu4 ming2 jiao4 pang2 ji2 de lao3 nong2 shi4 kang4 mei3 yuan2 chao2 fu4 shang1 hui2 xiang1 de lao3 bing1 qi1 zi3 chang2 nian2 you3 bing4 jia1 tu2 si4 bi4 yi1 pin2 ru2 xi3
一进门我被惊呆了这户名叫庞吉的老农是抗美援朝负伤回乡的老兵妻子长年有病家徒四壁一贫如洗
A11_103.wav
zou3 chu1 cun1 zi lao3 yuan3 lao3 yuan3 wo3 hai2 hui2 tou2 zhang1 wang4 na4 ge4 an1 ning2 tian2 jing4 de xiao3 yuan4 na4 ge4 shi3 wo3 zhong1 shen1 nan2 wang4 de xiao3 yuan4
走出村子老远老远我还回头张望那个安宁恬静的小院那个使我终身难忘的小院
A11_104.wav
er4 yue4 si4 ri4 zhu4 jin4 xin1 xi1 men2 wai4 luo2 jia1 nian3 wang2 jia1 gang1 zhu1 zi4 qing1 wen2 xun4 te4 di4 cong2 dong1 men2 wai4 gan3 lai2 qing4 he4
二月四日住进新西门外罗家碾王家冈朱自清闻讯特地从东门外赶来庆贺
A11_105.wav
dan1 wei4 bu2 shi4 wo3 lao3 die1 kai1 de ping2 shen2 me yao4 yi1 ci4 er4 ci4 zhao4 gu4 wo3 wo3 bu4 neng2 ba3 zi4 ji3 de bao1 fu2 wang3 xue2 xiao4 shuai3
单位不是我老爹开的凭什么要一次二次照顾我我不能把自己的包袱往学校甩
A11_106.wav
dou1 yong4 cao3 mao4 huo4 ge1 bo zhou3 hu4 zhe wan3 lie4 lie4 qie ju1 chuan1 guo4 lan4 ni2 tang2 ban1 de yuan4 ba4 pao3 hui2 zi4 ji3 de su4 she4 qu4 le
都用草帽或胳膊肘护着碗趔趔趄趄穿过烂泥塘般的院坝跑回自己的宿舍去了
A11_107.wav
xiang1 gang3 yan3 yi4 quan1 huan1 ying2 mao2 a1 min3 jia1 meng2 wu2 xian4 tai2 yu3 hua2 xing1 yi1 xie1 zhong4 da4 de yan3 chang4 huo2 dong4 dou1 yao1 qing3 ta1 chu1 chang3 you3 ji3 ci4 hai2 te4 yi4 an1 pai2 ya1 zhou4 yan3 chu1
香港演艺圈欢迎毛阿敏加盟无线台与华星一些重大的演唱活动都邀请她出场有几次还特意安排压轴演出
语音总数量: 13388
3.首先加载需要的python库
import os
import numpy as np
import scipy.io.wavfile as wav
import matplotlib.pyplot as plt
import tensorflow as tf
/home/ma-user/anaconda3/envs/TensorFlow-1.13.1/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:526: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint8 = np.dtype([("qint8", np.int8, 1)])
/home/ma-user/anaconda3/envs/TensorFlow-1.13.1/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:527: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint8 = np.dtype([("quint8", np.uint8, 1)])
/home/ma-user/anaconda3/envs/TensorFlow-1.13.1/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:528: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint16 = np.dtype([("qint16", np.int16, 1)])
/home/ma-user/anaconda3/envs/TensorFlow-1.13.1/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:529: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint16 = np.dtype([("quint16", np.uint16, 1)])
/home/ma-user/anaconda3/envs/TensorFlow-1.13.1/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:530: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint32 = np.dtype([("qint32", np.int32, 1)])
/home/ma-user/anaconda3/envs/TensorFlow-1.13.1/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:535: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
np_resource = np.dtype([("resource", np.ubyte, 1)])
4.声学模型
在本实践中,选择使用**深度全序列卷积神经网络(DFCNN,Deep Fully Convolutional NeuralNetwork)**进行声学模型的建模。
CNN早在2012年就被用于语音识别系统,但始终没有大的突破。主要的原因是其使用固定长度的帧拼接作为输入,无法看到足够长的语音上下文信息;另外一个缺陷将CNN视作一种特征提取器,因此所用的卷积层数很少,表达能力有限。
DFCNN直接将一句语音转化成一张图像作为输入,即先对每帧语音进行傅里叶变换,再将时间和频率作为图像的两个维度,然后通过非常多的卷积层和池化层的组合,对整句语音进行建模,输出单元直接与最终的识别结果(比如音节或者汉字)相对应。DFCNN 的原理是把语谱图看作带有特定模式的图像,其结构如下图所示。
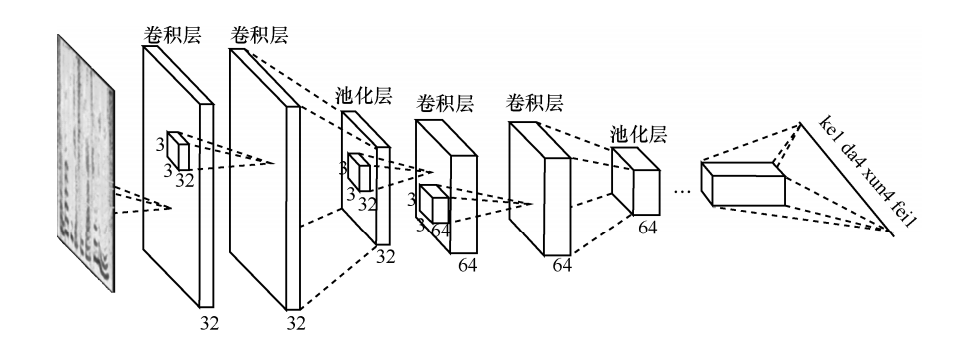
下面从输入端、模型结构和输出端三个方面来阐述 DFCNN 的优势:
首先,从输入端来看,传统语音特征在傅里叶变换之后使用各种人工设计的滤波器组来提取特征,造成了频域上的信息损失,在高频区域的信息损失尤为明显,而且传统语音特征为了计算量的考虑必须采用非常大的帧移,无疑造成了时域上的信息损失,在说话人语速较快的时候表现得更为突出。因此 DFCNN 直接将语谱图作为输入,避免了频域和时域两个维度的信息损失,相比其他以传统语音特征作为输入的语音识别框架相比具有天然的优势。
其次,从模型结构来看,DFCNN 借鉴了图像识别中效果最好的网络配置,每个卷积层使用 3x3 的小卷积核,并在多个卷积层之后再加上池化层,这样大大增强了 CNN 的表达能力,与此同时,通过累积非常多的这种卷积池化层对,DFCNN 可以看到非常长的历史和未来信息,这就保证了 DFCNN 可以出色地表达语音的长时相关性,相比 RNN 或者 LSTM 网络结构在鲁棒性上更加出色。
最后,从输出端来看,DFCNN 比较灵活,可以方便地和其他建模方式融合。比如,本实践采用的 DFCNN 与连接时序分类模型(CTC,connectionist temporal classification)方案结合,以实现整个模型的端到端声学模型训练,且其包含的池化层等特殊结构可以使得以上端到端训练变得更加稳定。与传统的声学模型训练相比,采用CTC作为损失函数的声学模型训练,是一种完全端到端的声学模型训练,不需要预先对数据做对齐,只需要一个输入序列和一个输出序列即可以训练。这样就不需要对数据对齐和一一标注,并且CTC直接输出序列预测的概率,不需要外部的后处理。
5.下面来建立DFCNN声学模型
import keras
from keras.layers import Input, Conv2D, BatchNormalization, MaxPooling2D
from keras.layers import Reshape, Dense, Dropout, Lambda
from keras.optimizers import Adam
from keras import backend as K
from keras.models import Model
from tensorflow.contrib.training import HParams
#定义卷积层
def conv2d(size):
return Conv2D(size, (3,3), use_bias=True, activation='relu',
padding='same', kernel_initializer='he_normal')
#定义BN层
def norm(x):
return BatchNormalization(axis=-1)(x)
#定义最大池化层
def maxpool(x):
return MaxPooling2D(pool_size=(2,2), strides=None, padding="valid")(x)
#定义dense层
def dense(units, activation="relu"):
return Dense(units, activation=activation, use_bias=True,
kernel_initializer='he_normal')
#两个卷积层加一个最大池化层的组合
def cnn_cell(size, x, pool=True):
x = norm(conv2d(size)(x))
x = norm(conv2d(size)(x))
if pool:
x = maxpool(x)
return x
#CTC损失函数
def ctc_lambda(args):
labels, y_pred, input_length, label_length = args
y_pred = y_pred[:, :, :]
return K.ctc_batch_cost(labels, y_pred, input_length, label_length)
#组合声学模型
class acoustic_model():
def __init__(self, args):
self.vocab_size = args.vocab_size
self.learning_rate = args.learning_rate
self.is_training = args.is_training
self._model_init()
if self.is_training:
self._ctc_init()
self.opt_init()
def _model_init(self):
self.inputs = Input(name='the_inputs', shape=(None, 200, 1))
self.h1 = cnn_cell(32, self.inputs)
self.h2 = cnn_cell(64, self.h1)
self.h3 = cnn_cell(128, self.h2)
self.h4 = cnn_cell(128, self.h3, pool=False)
self.h5 = cnn_cell(128, self.h4, pool=False)
# 200 / 8 * 128 = 3200
self.h6 = Reshape((-1, 3200))(self.h5)
self.h6 = Dropout(0.2)(self.h6)
self.h7 = dense(256)(self.h6)
self.h7 = Dropout(0.2)(self.h7)
self.outputs = dense(self.vocab_size, activation='softmax')(self.h7)
self.model = Model(inputs=self.inputs, outputs=self.outputs)
def _ctc_init(self):
self.labels = Input(name='the_labels', shape=[None], dtype='float32')
self.input_length = Input(name='input_length', shape=[1], dtype='int64')
self.label_length = Input(name='label_length', shape=[1], dtype='int64')
self.loss_out = Lambda(ctc_lambda, output_shape=(1,), name='ctc')\
([self.labels, self.outputs, self.input_length, self.label_length])
self.ctc_model = Model(inputs=[self.labels, self.inputs,
self.input_length, self.label_length], outputs=self.loss_out)
def opt_init(self):
opt = Adam(lr = self.learning_rate, beta_1 = 0.9, beta_2 = 0.999, decay = 0.01, epsilon = 10e-8)
self.ctc_model.compile(loss={'ctc': lambda y_true, output: output}, optimizer=opt)
def acoustic_model_hparams():
params = HParams(
vocab_size = 50,
learning_rate = 0.0008,
is_training = True)
return params
print("打印声学模型结构")
acoustic_model_args = acoustic_model_hparams()
acoustic = acoustic_model(acoustic_model_args)
acoustic.ctc_model.summary()
Using TensorFlow backend.
WARNING:tensorflow:From /home/ma-user/anaconda3/envs/TensorFlow-1.13.1/lib/python3.6/site-packages/tensorflow/python/framework/op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
打印声学模型结构
WARNING:tensorflow:From /home/ma-user/anaconda3/envs/TensorFlow-1.13.1/lib/python3.6/site-packages/keras/backend/tensorflow_backend.py:3445: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version.
Instructions for updating:
Please use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`.
WARNING:tensorflow:From /home/ma-user/anaconda3/envs/TensorFlow-1.13.1/lib/python3.6/site-packages/keras/backend/tensorflow_backend.py:4249: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
WARNING:tensorflow:From /home/ma-user/anaconda3/envs/TensorFlow-1.13.1/lib/python3.6/site-packages/keras/backend/tensorflow_backend.py:4229: to_int64 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
the_inputs (InputLayer) (None, None, 200, 1) 0
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, None, 200, 32 320 the_inputs[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, None, 200, 32 128 conv2d_1[0][0]
__________________________________________________________________________________________________
conv2d_2 (Conv2D) (None, None, 200, 32 9248 batch_normalization_1[0][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, None, 200, 32 128 conv2d_2[0][0]
__________________________________________________________________________________________________
max_pooling2d_1 (MaxPooling2D) (None, None, 100, 32 0 batch_normalization_2[0][0]
__________________________________________________________________________________________________
conv2d_3 (Conv2D) (None, None, 100, 64 18496 max_pooling2d_1[0][0]
__________________________________________________________________________________________________
batch_normalization_3 (BatchNor (None, None, 100, 64 256 conv2d_3[0][0]
__________________________________________________________________________________________________
conv2d_4 (Conv2D) (None, None, 100, 64 36928 batch_normalization_3[0][0]
__________________________________________________________________________________________________
batch_normalization_4 (BatchNor (None, None, 100, 64 256 conv2d_4[0][0]
__________________________________________________________________________________________________
max_pooling2d_2 (MaxPooling2D) (None, None, 50, 64) 0 batch_normalization_4[0][0]
__________________________________________________________________________________________________
conv2d_5 (Conv2D) (None, None, 50, 128 73856 max_pooling2d_2[0][0]
__________________________________________________________________________________________________
batch_normalization_5 (BatchNor (None, None, 50, 128 512 conv2d_5[0][0]
__________________________________________________________________________________________________
conv2d_6 (Conv2D) (None, None, 50, 128 147584 batch_normalization_5[0][0]
__________________________________________________________________________________________________
batch_normalization_6 (BatchNor (None, None, 50, 128 512 conv2d_6[0][0]
__________________________________________________________________________________________________
max_pooling2d_3 (MaxPooling2D) (None, None, 25, 128 0 batch_normalization_6[0][0]
__________________________________________________________________________________________________
conv2d_7 (Conv2D) (None, None, 25, 128 147584 max_pooling2d_3[0][0]
__________________________________________________________________________________________________
batch_normalization_7 (BatchNor (None, None, 25, 128 512 conv2d_7[0][0]
__________________________________________________________________________________________________
conv2d_8 (Conv2D) (None, None, 25, 128 147584 batch_normalization_7[0][0]
__________________________________________________________________________________________________
batch_normalization_8 (BatchNor (None, None, 25, 128 512 conv2d_8[0][0]
__________________________________________________________________________________________________
conv2d_9 (Conv2D) (None, None, 25, 128 147584 batch_normalization_8[0][0]
__________________________________________________________________________________________________
batch_normalization_9 (BatchNor (None, None, 25, 128 512 conv2d_9[0][0]
__________________________________________________________________________________________________
conv2d_10 (Conv2D) (None, None, 25, 128 147584 batch_normalization_9[0][0]
__________________________________________________________________________________________________
batch_normalization_10 (BatchNo (None, None, 25, 128 512 conv2d_10[0][0]
__________________________________________________________________________________________________
reshape_1 (Reshape) (None, None, 3200) 0 batch_normalization_10[0][0]
__________________________________________________________________________________________________
dropout_1 (Dropout) (None, None, 3200) 0 reshape_1[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, None, 256) 819456 dropout_1[0][0]
__________________________________________________________________________________________________
dropout_2 (Dropout) (None, None, 256) 0 dense_1[0][0]
__________________________________________________________________________________________________
the_labels (InputLayer) (None, None) 0
__________________________________________________________________________________________________
dense_2 (Dense) (None, None, 50) 12850 dropout_2[0][0]
__________________________________________________________________________________________________
input_length (InputLayer) (None, 1) 0
__________________________________________________________________________________________________
label_length (InputLayer) (None, 1) 0
__________________________________________________________________________________________________
ctc (Lambda) (None, 1) 0 the_labels[0][0]
dense_2[0][0]
input_length[0][0]
label_length[0][0]
==================================================================================================
Total params: 1,712,914
Trainable params: 1,710,994
Non-trainable params: 1,920
__________________________________________________________________________________________________
6.获取数据类
from scipy.fftpack import fft
# 获取信号的时频图
def compute_fbank(file):
x=np.linspace(0, 400 - 1, 400, dtype = np.int64)
w = 0.54 - 0.46 * np.cos(2 * np.pi * (x) / (400 - 1) )
fs, wavsignal = wav.read(file)
time_window = 25
window_length = fs / 1000 * time_window
wav_arr = np.array(wavsignal)
wav_length = len(wavsignal)
range0_end = int(len(wavsignal)/fs*1000 - time_window) // 10
data_input = np.zeros((range0_end, 200), dtype = np.float)
data_line = np.zeros((1, 400), dtype = np.float)
for i in range(0, range0_end):
p_start = i * 160
p_end = p_start + 400
data_line = wav_arr[p_start:p_end]
data_line = data_line * w
data_line = np.abs(fft(data_line))
data_input[i]=data_line[0:200]
data_input = np.log(data_input + 1)
return data_input
class get_data():
def __init__(self, args):
self.data_path = args.data_path
self.data_length = args.data_length
self.batch_size = args.batch_size
self.source_init()
def source_init(self):
self.wav_lst = []
self.pin_lst = []
self.han_lst = []
with open('speech_recognition/data.txt', 'r', encoding='utf8') as f:
data = f.readlines()
for line in data:
wav_file, pin, han = line.split('\t')
self.wav_lst.append(wav_file)
self.pin_lst.append(pin.split(' '))
self.han_lst.append(han.strip('\n'))
if self.data_length:
self.wav_lst = self.wav_lst[:self.data_length]
self.pin_lst = self.pin_lst[:self.data_length]
self.han_lst = self.han_lst[:self.data_length]
self.acoustic_vocab = self.acoustic_model_vocab(self.pin_lst)
self.pin_vocab = self.language_model_pin_vocab(self.pin_lst)
self.han_vocab = self.language_model_han_vocab(self.han_lst)
def get_acoustic_model_batch(self):
_list = [i for i in range(len(self.wav_lst))]
while 1:
for i in range(len(self.wav_lst) // self.batch_size):
wav_data_lst = []
label_data_lst = []
begin = i * self.batch_size
end = begin + self.batch_size
sub_list = _list[begin:end]
for index in sub_list:
fbank = compute_fbank(self.data_path + self.wav_lst[index])
pad_fbank = np.zeros((fbank.shape[0] // 8 * 8 + 8, fbank.shape[1]))
pad_fbank[:fbank.shape[0], :] = fbank
label = self.pin2id(self.pin_lst[index], self.acoustic_vocab)
label_ctc_len = self.ctc_len(label)
if pad_fbank.shape[0] // 8 >= label_ctc_len:
wav_data_lst.append(pad_fbank)
label_data_lst.append(label)
pad_wav_data, input_length = self.wav_padding(wav_data_lst)
pad_label_data, label_length = self.label_padding(label_data_lst)
inputs = {'the_inputs': pad_wav_data,
'the_labels': pad_label_data,
'input_length': input_length,
'label_length': label_length,
}
outputs = {'ctc': np.zeros(pad_wav_data.shape[0], )}
yield inputs, outputs
def get_language_model_batch(self):
batch_num = len(self.pin_lst) // self.batch_size
for k in range(batch_num):
begin = k * self.batch_size
end = begin + self.batch_size
input_batch = self.pin_lst[begin:end]
label_batch = self.han_lst[begin:end]
max_len = max([len(line) for line in input_batch])
input_batch = np.array(
[self.pin2id(line, self.pin_vocab) + [0] * (max_len - len(line)) for line in input_batch])
label_batch = np.array(
[self.han2id(line, self.han_vocab) + [0] * (max_len - len(line)) for line in label_batch])
yield input_batch, label_batch
def pin2id(self, line, vocab):
return [vocab.index(pin) for pin in line]
def han2id(self, line, vocab):
return [vocab.index(han) for han in line]
def wav_padding(self, wav_data_lst):
wav_lens = [len(data) for data in wav_data_lst]
wav_max_len = max(wav_lens)
wav_lens = np.array([leng // 8 for leng in wav_lens])
new_wav_data_lst = np.zeros((len(wav_data_lst), wav_max_len, 200, 1))
for i in range(len(wav_data_lst)):
new_wav_data_lst[i, :wav_data_lst[i].shape[0], :, 0] = wav_data_lst[i]
return new_wav_data_lst, wav_lens
def label_padding(self, label_data_lst):
label_lens = np.array([len(label) for label in label_data_lst])
max_label_len = max(label_lens)
new_label_data_lst = np.zeros((len(label_data_lst), max_label_len))
for i in range(len(label_data_lst)):
new_label_data_lst[i][:len(label_data_lst[i])] = label_data_lst[i]
return new_label_data_lst, label_lens
def acoustic_model_vocab(self, data):
vocab = []
for line in data:
line = line
for pin in line:
if pin not in vocab:
vocab.append(pin)
vocab.append('_')
return vocab
def language_model_pin_vocab(self, data):
vocab = ['<PAD>']
for line in data:
for pin in line:
if pin not in vocab:
vocab.append(pin)
return vocab
def language_model_han_vocab(self, data):
vocab = ['<PAD>']
for line in data:
line = ''.join(line.split(' '))
for han in line:
if han not in vocab:
vocab.append(han)
return vocab
def ctc_len(self, label):
add_len = 0
label_len = len(label)
for i in range(label_len - 1):
if label[i] == label[i + 1]:
add_len += 1
return label_len + add_len
未完待续

- 点赞
- 收藏
- 关注作者
评论(0)