[机器学习Lesson3] 梯度下降算法

1. Gradient Descent(梯度下降)
梯度下降算法是很常用的算法,可以将代价函数J最小化。它不仅被用在线性回归上,也被广泛应用于机器学习领域中的众多领域。
1.1 线性回归问题应用
我们有一个函数J(θ0,θ1),要使其最小化minJ(θ0,θ01):

Outline
对θ0,θ1开始进行一些猜测
通常将初θ0,θ1初始化为0在梯度算法中,要做的就是不停的一点点改变θ0和θ1试图通过这种改变使得J(θ0,θ1)变小,直到找到J的最小值或者局部最小值。
1.2 梯度算法工作原理

现在我们把这个图像想象为一座山,想像类似这样的景色 :公园中有两座山,想象一下你正站立在山的这一点上 站立在你想象的公园这座红色山上。在梯度下降算法中,我们要做的就是旋转360度,看看我们的周围,并问自己,我要在某个方向上,用小碎步尽快下山。如果我想要下山。如果我想尽快走下山,这些小碎步需要朝什么方向? 如果我们站在山坡上的这一点,你看一下周围,你会发现最佳的下山方向,大约是那个方向。
现在你在山上的新起点上 你再看看周围 然后再一次想想 我应该从什么方向迈着小碎步下山? 然后你按照自己的判断又迈出一步 往那个方向走了一步 然后重复上面的步骤。从这个新的点,你环顾四周并决定从什么方向将会最快下山。然后又迈进了一小步,并依此类推,直到你接近这里,直到局部最低点的位置。

现在想象一下,我们在刚才的右边一些的位置,对梯度下降进行初始化。想象我们在右边高一些的这个点。开始使用梯度下降。如果你重复上述步骤,停留在该点,并环顾四周,往下降最快的方向迈出一小步,然后环顾四周又迈出一步,然后如此往复。如果你从右边不远处开始梯度下降算法将会带你来到这个右边的第二个局部最优处。 如果从刚才的第一个点出发,你会得到这个局部最优解 但如果你的起始点偏移了一些,起始点的位置略有不同 你会得到一个非常不同的局部最优解。这就是梯度下降算法的一个特点。
1.3 梯度下降算法定义。

:=:赋值符号(Assignment).α:这里的α是一个数字,被称为学习速率(learning rate)。在梯度下降算法中,它控制了我们下山时会迈出多大的步子。微分项。
在梯度下降中,我们要更新θ0和θ1。当 j=0 和 j=1 时 会产生更新。所以你将更新J、θ0还有θ1。实现梯度下降算法的微妙之处是,在这个表达式中,如果你要更新这个等式,你需要同时更新 θ0和θ1。

θ0和θ1需要同步更新,右侧是非同步更新,错误。
1.4 梯度下降和代价函数
梯度下降是很常用的算法,它不仅被用在线性回归上 和线性回归模型还有平方误差代价函数。
当具体应用到线性回归的情况下,可以推导出一种新形式的梯度下降法方程:

m:训练集的大小
θ0与θ1同步改变
xi和yi:给定的训练集的值(数据)。
我们已经分离出两例θj:θ0和θ1为独立的方程;在θ1中,在推导最后乘以Xi。以下是推导∂/∂θjJ(θ)的一个例子:

这一切的关键是,如果我们从猜测我们的假设开始,然后反复应用这些梯度下降方程,我们的假设将变得越来越精确。
因此,这只是原始成本函数J的梯度下降。这个方法是在每个步骤的每个训练集中的每一个例子,被称为批量梯度下降。注意,虽然梯度下降一般容易受到局部极小值的影响,但我们在线性回归中所提出的优化问题只有一个全局,没有其他局部最优解,因此梯度下降总是收敛(假定学习率α不是太大)到全局最小值。实际上,j是凸二次函数。这里是一个梯度下降的例子,它是为了最小化二次函数而运行的。
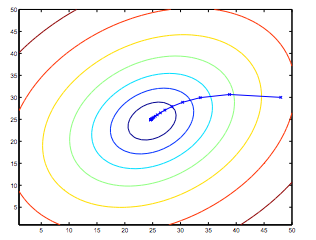
上面所示的椭圆是二次函数的轮廓图。也表明是通过梯度下降的轨迹,它被初始化为(48,30)。X在图(连接的直线)的标志,θ梯度穿过它收敛到最小的连续值。
本文资料部分来源于吴恩达 (Andrew Ng) 博士的斯坦福大学机器学习公开课视频教程。
[1]网易云课堂机器学习课程:
http://open.163.com/special/opencourse/machinelearning.html
[2]coursera课程:
https://www.coursera.org/learn/machine-learning/

- 点赞
- 收藏
- 关注作者
评论(0)