大数据Flink进阶(十七):Apache Flink术语

Apache Flink术语
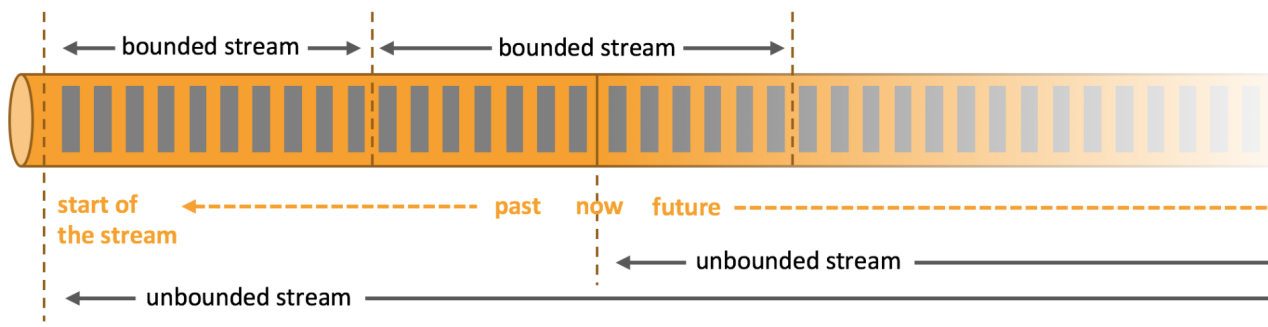
Flink计算框架可以处理批数据也可以处理流式数据,Flink将批处理看成是流处理的一个特例,认为数据原本产生就是实时的数据流,这种数据叫做无界流(unbounded stream),无界流是持续不断的产生没有边界,批数据只是无界流中的一部分叫做有界流(bounded stream),针对无界流数据处理叫做实时处理,这种程序一般是7*24不间断运行的;针对有界流数据处理叫做批处理,这种程序处理完当前批数据就停止。下面我们结合一些代码介绍Flink中的一些重要的名词术语。
一、Application与Job
无论处理批数据还是处理流数据我们都可以使用Flink提供好的Operator(算子)来转换处理数据,一个完整的Flink程序代码叫做一个Flink Application,像前面章节我们编写的Flink读取Socket数据实时统计WordCount代码就是一个完整的Flink Application:
/**
* 读取Socket数据进行实时WordCount统计
*/
public class SocketWordCount {
public static void main(String[] args) throws Exception {
//1.准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.读取Socket数据
DataStreamSource<String> ds = env.socketTextStream("node5", 9999);
//3.准备K,V格式数据
SingleOutputStreamOperator<Tuple2<String, Integer>> tupleDS = ds.flatMap((String line, Collector<Tuple2<String, Integer>> out) -> {
String[] words = line.split(",");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}).returns(Types.TUPLE(Types.STRING, Types.INT));
//4.聚合打印结果
tupleDS.keyBy(tp -> tp.f0).sum(1).print();
//5.execute触发执行
env.execute();
}
}一个完整的Flink Application一般由Source(数据来源)、Transformation(转换)、Sink(数据输出)三部分组成,Flink中一个或者多个Operator(算子)组合对数据进行转换形成Transformation,一个Flink Application 开始于一个或者多个Source,结束于一个或者多个Sink。

编写Flink代码要符合一定的流程,首先我们需要创建Flink的执行环境(Execution Environment),然后再加载数据源Source,对加载的数据进行Transformation转换,进而对结果Sink输出,最后还要执行env.execute()来触发整个Flink程序的执行,编写代码时将以上完整流程放在main方法中形成一个完整的Application。
一个Flink Application中可以有多个Flink Job,每次调用execute()或者executeAsyc()方法可以触发一个Flink Job ,一个Flink Application中可以执行多次以上两个方法来触发多个job执行。但往往我们在编写一个Flink Application时只需要一个Job即可。
二、DataFlow数据流图
一个Flink Job 执行时会按照Source、Transformatioin、Sink顺序来执行,这就形成了Stream DataFlow(数据流图),数据流图是整体展示Flink作业执行流程的高级视图,通过WebUI我们可以看到提交应用程序的DataFlow。

像之前提交的Flink 读取Socket数据实时统计WordCount在WebUI中形成的DataFlow如下,可以看到对应的Source、各个转换算子、Sink部分。

通常Operator算子和Transformation转换之间是一对一的关系,有时一个Transformation转换中包含多个Operator,形成一个算子链,这主要取决于数据之间流转关系和并行度是否相同,关于算子链内容在再做介绍。
三、Subtask子任务与并行度
在集群中运行Flink代码本质上是以并行和分布式方式来执行,这样可以提高处理数据的吞吐量和速度,处理一个Flink流过程中涉及多个Operator,每个Operator有一个或者多个Subtask(子任务),不同的Operator的Subtask个数可以不同,一个Operator有几个Subtask就代表当前算子的并行度(Parallelism)是多少,Subtask在不同的线程、不同的物理机或不同的容器中完全独立执行。

上图下半部分是多并行度DataFlow视图,Source、Map、KeyBy等操作有2个并行度,对应2个subtask分布式执行,Sink操作并行度为1,只有一个subtask,一共有7个Subtask,每个Subtask处理的数据也经常说成处理一个分区(Stream Partition)的数据。 一个 Flink Application 的并行度通常认为是所有Operator中最大的并行度 。上图中的Application并行度就为2。
Flink中并行度可以从以下四个层面指定:
- Operator Level (算子层面)
算子层面设置并行度是给每个算子设置并行度,直接在算子后面调用.setparallelism()方法,写入并行度即可,只是针对当前算子有效,注意一些算子不能设置并行度,例如:keyBy 返回的对象是KeyedStream,这种分组操作无法设置并行度,socketTextStream是非并行source,只支持1个并行度,也不能设置并行度。
#算子层面设置并行度
ds.flatMap(line=>{line.split(" ")}).setParallelism(2)- Execution Environment Level(执行环境层面)
执行环境层面设置并行度直接调用env.setParallelism()写入并行度即可,全局代码有效。
#执行环境层面设置并行度
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(3)- Client Level(客户端层面)
以上无论是算子层面还是执行环境层面设置并行度都会导致硬编码问题,修改并行度时不灵活,我们也可以在客户端提交Flink任务时通过指定命令参数-p来动态设置并行度,并行度作用于全局代码。
如果是基于WebUI提交任务,我们也可以基于WebUI指定并行度:

- System Level(系统层面)
我们也可以直接在提交Flink任务的节点配置$FLINK_HOME/conf/flink-conf.yaml文件配置并行度,这个设置对于在客户端提交的所有任务有效,默认值为1。
#配置flink-conf.yaml文件
parallelism.default: 5以上四种不同方式指定Flink 并行度的优先级为: Operator Level>Execution Environment Level>Client Level>System Level,本地编写代码时如果没有指定并行度,默认的并行度是当前机器的cpu core数。
四、Operator Chains 算子链
在Flink作业中,用户可以指定Operator Chains(算子链)将相关性非常强的算子操作绑定在一起,这样能够让转换过程上下游的Task数据处理逻辑由一个Task执行,进而避免因为数据在网络或者线程间传输导致的开销,减少数据处理延迟提高数据吞吐量。默认情况下,Flink开启了算子链。例如:下图流处理程序Source/map就形成了一个算子链,keyBy/window/apply形成了以算子链,分布式执行中原本需要多个task执行的情况由于有了算子链减少到由5个Subtask分布式执行即可。

我们在集群中提交Flink任务后,可以通过Flink WebUI中查看到形成的算子链:

那么在Flink中哪些算子操作可以合并在一起形成算子链进行优化?这主要取决于算子之间的并行度与算子之间数据传递的模式。一个数据流在算子之间传递数据可以是一对一(One-to-one)的模式传递,也可以是重分区(Redistributing)的模式传递,两者区别如下:
- One-to-one:
一对一传递模式(例如上图中的Source和map()算子之间)保留了元素的分区和顺序,类似Spark中的窄依赖。这意味着map()算子的subtask[1]处理的数据全部来自Source的subtask[1]产生的数据,并且顺序保持一致。例如:map、filter、flatMap这些算子都是One-to-one数据传递模式。
- Redistributing:
重分区模式(如上面的map()和keyBy/window之间,以及keyBy/window和Sink之间)改变了流的分区,这种情况下数据流向的分区会改变,类似于Spark中的宽依赖。每个算子的subtask将数据发送到不同的目标subtask,这取决于使用了什么样的算子操作,例如keyBy()是分组操作,会根据key的哈希值对数据进行重分区,再如,window/apply算子操作的并行度为2,流向了并行度为1的sink操作,这个过程需要通过rebalance操作将数据均匀发送到下游Subtask中。这些传输方式都是重分区模式(Redistributing)。
在Flink中 One-to-one 的算子操作且并行度一致,默认自动合并在一起形成一个算子链 ,由一个task执行对应逻辑。我们也可以通过代码禁用算子链或者进行细粒度的控制哪些算子可以合并形成算子链。
- 通过以下方式来禁用算子链
#禁用算子链
StreamExecutionEnvironment.disableOperatorChaining()编写代码,首先对数据进行过滤,然后进行转换操作,实时统计WordCount,代码中我们可以禁用算子链:
//1.准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.disableOperatorChaining();
//2.读取Socket数据
DataStreamSource<String> ds = env.socketTextStream("node5", 9999);
//3.对数据进行过滤
SingleOutputStreamOperator<String> filterDS = ds.filter(s -> s.startsWith("a"));
//4.对数据进行单词切分
SingleOutputStreamOperator<String> wordDS = filterDS.flatMap((String line, Collector<String> collector) -> {
String[] words = line.split(",");
for (String word : words) {
collector.collect(word);
}
}).returns(Types.STRING);
//5.对单词进行设置PairWord
SingleOutputStreamOperator<Tuple2<String, Integer>> pairWordDS =
wordDS.map(s -> new Tuple2<>(s, 1)).returns(Types.TUPLE(Types.STRING, Types.INT));
//6.统计单词
SingleOutputStreamOperator<Tuple2<String, Integer>> result = pairWordDS.keyBy(tp -> tp.f0).sum(1);
//7.打印结果
result.print();
//8.execute触发执行
env.execute();禁用算子链之后,打包执行,提交任务:
#提交任务命令
./flink run -m node1:8081 -p 2 -c com.lanson.flinkjava.code.chapter4.TestOperatorChain /root/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar我们禁用算子链之后再执行任务可以通过WebUI看到算子不再合并在一起执行,而是每个算子都由一个task执行。
默认开启算子链:

关闭算子链:

- 设置新的算子链
#从当前算子开始一个新的算子链
someStream.filter(...).map(...).startNewChain().map(...);以上是想从哪个算子开始新的算子链就在该算子后调用startNewChain()方法即可。修改代码:
//1.准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.读取Socket数据
DataStreamSource<String> ds = env.socketTextStream("node5", 9999);
//3.对数据进行过滤
SingleOutputStreamOperator<String> filterDS = ds.filter(s -> s.startsWith("a"));
//4.对数据进行单词切分
SingleOutputStreamOperator<String> wordDS = filterDS.flatMap((String line, Collector<String> collector) -> {
String[] words = line.split(",");
for (String word : words) {
collector.collect(word);
}
}).returns(Types.STRING);
//5.对单词进行设置PairWord
SingleOutputStreamOperator<Tuple2<String, Integer>> pairWordDS =
wordDS.map(s -> new Tuple2<>(s, 1)).returns(Types.TUPLE(Types.STRING, Types.INT)).startNewChain();
//6.统计单词
SingleOutputStreamOperator<Tuple2<String, Integer>> result = pairWordDS.keyBy(tp -> tp.f0).sum(1);
//7.打印结果
result.print();
//8.execute触发执行
env.execute();查看WebUI,展示的算子链结果如下:

- 在算子上禁用算子链
如果我们不想关闭整体作业的算子链,只想关闭某些算子的算子链,我们可以在某个算子后调用disableChaining()方法来打断Flink自动合并算子链。
#打断算子链
someStream.map(...).disableChaining();向从哪个算子开始不再自动合并算子链就在该算子上调用disableChaining()方法。根据以上代码执行的结果,我们看到FaltMap和Map自动合并形成了算子链,我们可以在map算子后调用disableChaining来切断两者形成算子链:
//1.准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.读取Socket数据
DataStreamSource<String> ds = env.socketTextStream("node5", 9999);
//3.对数据进行过滤
SingleOutputStreamOperator<String> filterDS = ds.filter(s -> s.startsWith("a"));
//4.对数据进行单词切分
SingleOutputStreamOperator<String> wordDS = filterDS.flatMap((String line, Collector<String> collector) -> {
String[] words = line.split(",");
for (String word : words) {
collector.collect(word);
}
}).returns(Types.STRING).startNewChain();
//5.对单词进行设置PairWord
SingleOutputStreamOperator<Tuple2<String, Integer>> pairWordDS =
wordDS.map(s -> new Tuple2<>(s, 1)).returns(Types.TUPLE(Types.STRING, Types.INT)).disableChaining();
//6.统计单词
SingleOutputStreamOperator<Tuple2<String, Integer>> result = pairWordDS.keyBy(tp -> tp.f0).sum(1);
//7.打印结果
result.print();
//8.execute触发执行
env.execute();在map算子上打断算子链,将以上代码打包执行,提交任务:
#提交任务命令
./flink run -m node1:8081 -p 2 -c com.mashibing.flinkjava.code.chapter4.TestOperatorChain /root/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar查看WebUI,展示的算子链结果如下:

在Flink编程中默认开启算子链即可,如果遇到一些算子操作非常复杂,我们想让处理该业务逻辑的task独占cpu资源这时可以细粒度管理算子链,大多数情况选择让Flink默认划分算子链即可。
- 点赞
- 收藏
- 关注作者
评论(0)