CLIP:多模态领域革命者

CLIP:多模态领域革命者
当前的内容是梳理《Transformer视觉系列遨游》系列过程中引申出来的。目前最近在AI作画这个领域 Transformer 火的一塌糊涂,AI画画效果从18年的 DeepDream[1] 噩梦中惊醒过来,开始从2022年 OpenAI 的 DALL·E 2[2] 引来插画效果和联想效果都达到惊人效果。虽然不懂,但是这个话题很吸引ZOMI,于是就着这个领域内容来看看有什么好玩的技术点。

但是要了解:Transformer 带来AI+艺术,从语言开始遇到多模态,碰撞艺术火花 这个主题,需要引申很多额外的知识点,可能跟 CV、NLP 等领域大力出奇迹的方式不同,AI+艺术会除了遇到 Transformer 结构以外,还会涉及到 VAE、ELBO、Diffusion Model等一系列跟数学相关的知识。
Transformer + Art 系列中,今天新挖一个 CLIP 的坑,多模态不是一个新鲜的瓜,随着 AI 的发展,多模态已经成为一种趋势,而 CLIP 就是在多模态领域里迈出了重要的一步。其具有非常好的迁移学习能力,预训练好的模型可以在任意一个视觉分类数据集上取得不错的效果,而且是 Zero-shot(不需要对新数据集重新训练,就能得到很好的结果)。
OpenAI 财大气粗力大砖飞搞出了 CLIP,在400M的图像-文本对数据上,用最朴素的对比损失训练双塔网络,利用text信息监督视觉任务自训练,对齐了两个模态的特征空间,本质就是将分类任务化成了图文匹配任务,效果可与全监督方法相当。在近 30 个数据集上 zero-shot 达到或超越主流监督学习性能。Let's dive in!
CLIP:《Learning Transferable Visual Models From Natural Language Supervision》

多模态
模态(modal)是事情经历和发生的方式,我们生活在一个由多种模态(Multimodal)信息构成的世界,包括视觉信息、听觉信息、文本信息、嗅觉信息等等,当研究的问题或者数据集包含多种这样的模态信息时我们称之为多模态问题,研究多模态问题是推动人工智能更好的了解和认知我们周围世界的关键。
通常主要研究模态包括"3V":即Verbal(文本)、Vocal(语音)、Visual(视觉)。
多模态发展历史
实际上,多模态学习不是近几年才火起来,而是近几年因为深度学习使得多模态效果进一步提升。下面梳理一下从1970年代起步,多模态技术经历的4个发展阶段,在2012后迎来 Deep Learning 阶段,在2016年后进入目前真正的多模态阶段。
- 第一阶段为基于行为的时代(1970s until late 1980s),这一阶段主要从心理学的角度对多模态这一现象进行剖析。
- 第二阶段基于计算的时代(1980 - 2000),这一阶段主要利用一些浅层的模型对多模态问题进行研究,其中代表性的应用包括视觉语音联合识别,多模态情感计算等等。
- 第三阶段基于交互的时代,这一阶段主要主要从交互的角度入手,研究多模态识别问题,其中主要的代表作品包括苹果的语音助手Siri等。
- 第四阶段基于深度学习的时代,促使多模态研究发展的关键促成因素有4个,1)更大规模的多模态数据集;2)更强大的算力(NPU/GPU/TPU);3)强大的视觉特征抽取能力;4)强大的语言特征抽取能力。
多模态核心任务
多模态机器学习的核心任务主要包括表示学习,模态映射,模态对齐,模态融合,协同学习。
表示学习
表示学习(Representation):主要研究如何将多个模态数据所蕴含的语义信息,数值化为实值向量,简单来说就是特征化。
单模态的表示学习负责将信息表示为计算机可以处理的数值向量或者进一步抽象为更高层的特征向量 Feature;而多模态表示学习通过利用多模态之间的互补性,剔除模态间的冗余性,从而学习到更好的特征 Feature。
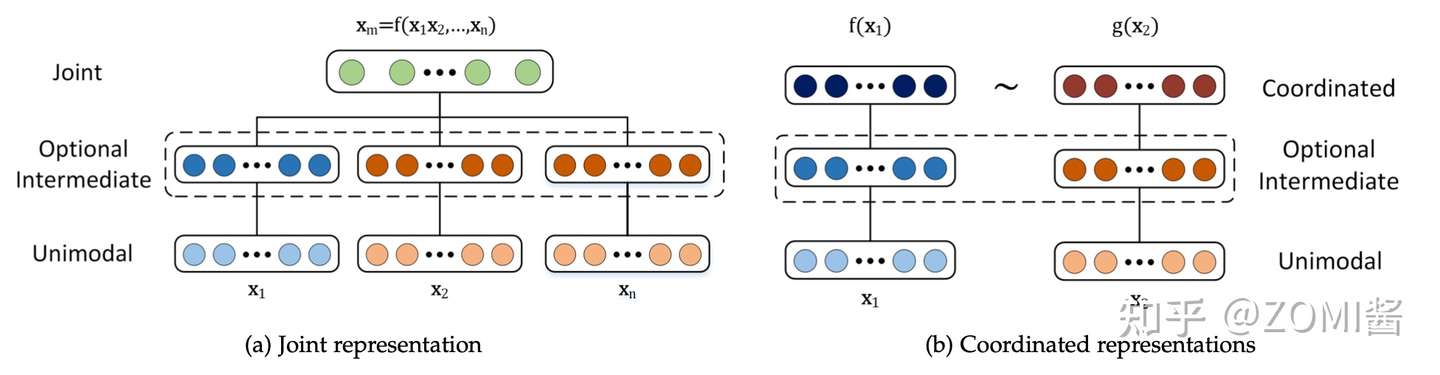
那在表示学习中主要包括两大研究方向:
- 联合表示(Joint Representations):将多个模态的信息一起映射到一个统一的多模态向量空间。(CLIP 和 DALL·E 使用简单的联合表示,不过效果出奇的赞)。
- 协同表示(Coordinated Representations):将多模态中的每个模态分别映射到各自的表示空间,但映射后的向量之间满足一定的相关性约束(例如线性相关)。
下游任务
上面讲的是表示学习用于提取多模态的特征,有了特性后在机器学习领域接着就是下游任务对特征进行理解(学术上也叫做内容理解),典型的下游任务包括视觉问答、视觉推理、视觉联合推理、图像检索、视频检索。
- 视觉问答(Visual Question Answering,VQA):根据给定的图片提问,从候选中选择出正确的答案,VQA2.0 中从 COCO 图片中筛选了超过100万的问题,训练模型来预测最常见的3129个回答,其本质上可以转化成一个分类问题。

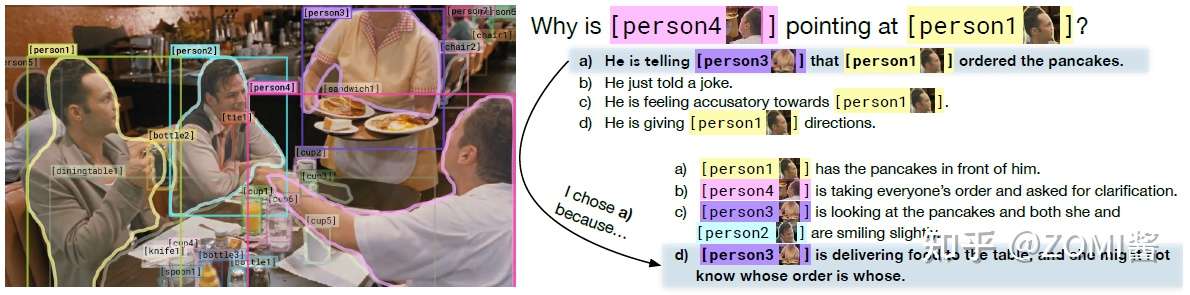
- 视觉推理(Visual Reasoning,VR):视觉推理相对视觉问答更为复杂, 其可以分解为两个子任务视觉问答(Q->A)和选出答案的原因(QA->R), 除了回答的问题需要用自然语言表达具有挑战性的视觉问题外, 模型还需要解释为什么作出这样的回答, 其最开始由华盛顿大学提出, 同时发布的 VCR 数据集包含 11 万的电影场景和 29 万的多项选择问题。
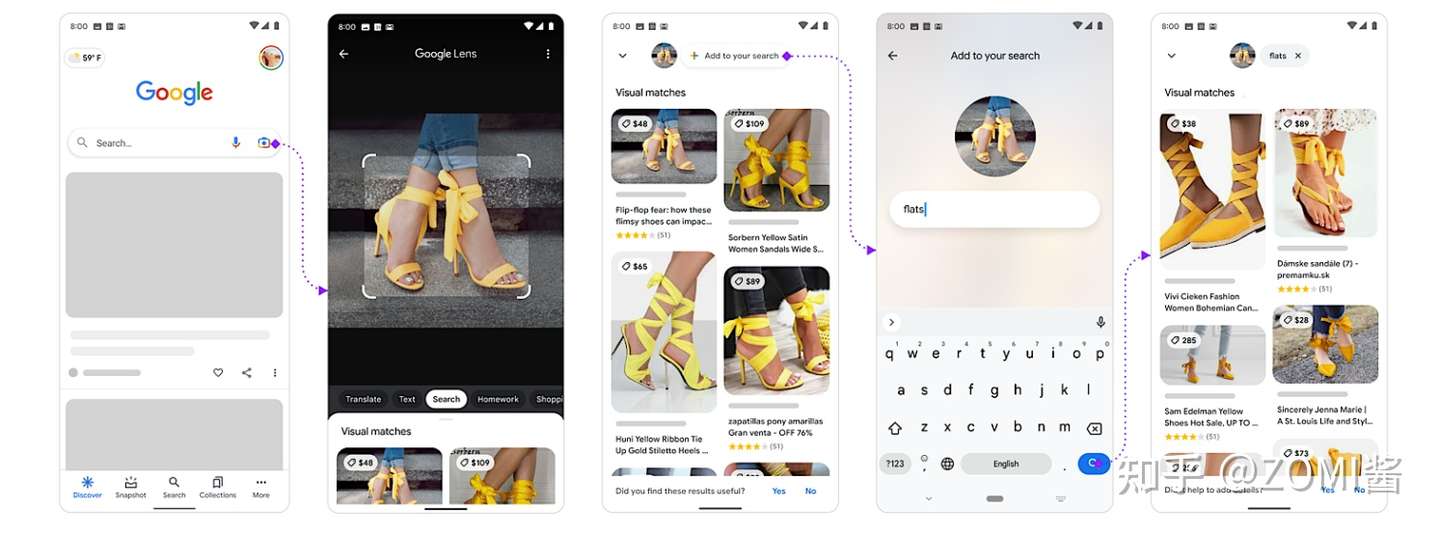
- 检索任务(Index Task):主要包括文本检索图片或者图片检索文本,检索任务应该不用加以过多的解释了,比较好理解,就是以文搜图或者以图搜文。下面图中就是Google 以图搜文的服务,当然包括华为手机里面的截图识字,淘宝拼多多的以文搜图等身边很多诸如此类的服务啦。
CLIP算法原理
CLIP 不预先定义图像和文本标签类别,直接利用从互联网爬取的 400 million 个image-text pair 进行图文匹配任务的训练,并将其成功迁移应用于30个现存的计算机视觉分类。简单的说,CLIP 无需利用 ImageNet 的数据和标签进行训练,就可以达到 ResNet50 在 ImageNet数据集上有监督训练的结果,所以叫做 Zero-shot。
CLIP(contrastive language-image pre-training)主要的贡献就是利用无监督的文本信息,作为监督信号来学习视觉特征。
CLIP 作者先是回顾了并总结了和上述相关的两条表征学习路线:
- 构建image和text的联系,比如利用已有的image-text pair数据集,从text中学习image的表征;
- 获取更多的数据(不要求高质量,也不要求full labeled)然后做弱监督预训练,就像谷歌使用的JFT-300M数据集进行预训练一样(在JFT数据集中,类别标签是有噪声的)。具体来说,JFT中一共有18291个类别,这能教模型的概念比ImageNet的1000类要多得多,但尽管已经有上万类了,其最后的分类器其实还是静态的、有限的,因为你最后还是得固定到18291个类别上进行分类,那么这样的类别限制还是限制了模型的zero-shot能力。
这两条路线其实都展现了相当的潜力,前者证明 paired image-text 可以用来训练视觉表征,后者证明扩充数据能极大提升性能,即使数据有noise。于是high-level上,CLIP 作者考虑从网上爬取大量的 image-text pair 以扩充数据,同时这样的 pairs 是可以用来训练视觉表征的。作者随即在互联网上采集了4亿个 image-text 对,准备开始训练模型。
数据准备
那这4亿image-text数据怎么整?
4亿训练数据数据用的是图像-文本(image-text)对是从网络上获取的。具体的方式是准备50k 个 text query,每个 query 抓至多 20k 张图,共 400m 个 pair 对。50k 个query 的来源是,先准备一个 base query list,由 Wikipedia 高频词组成,然后做bi-gram 形成一些高频词组,再补充一些 Wikipedia 高频文章名称和 WordNet 同义词组。每个 query 至多20k张图是考虑到了类别平衡。
网络模型
多模态的网络模型采用双塔结构,即一个 image encoder 和一个 text encoder。image encoder 是 ResNet 的改进版(添加了多个 stem 层和 attention pooling)或直接使用 Vision Transformer (ViT);text encoder 基于 GPT-2 的 transformer。两个 encoder 的输出相同维度的向量(假设 n 都为1024)。
CLIP流程
回答 CLIP 的流程最好的答案可能就是下面这张图。很直观,有三个阶段:
- Contrastive pre-training:对比预训练阶段,使用image-text对进行对比学习训练。
- Create dataset classifier from label text:提取预测类别文本特征。
- Use for zero-shot prediction:进行 Zero-Shot 推理预测。
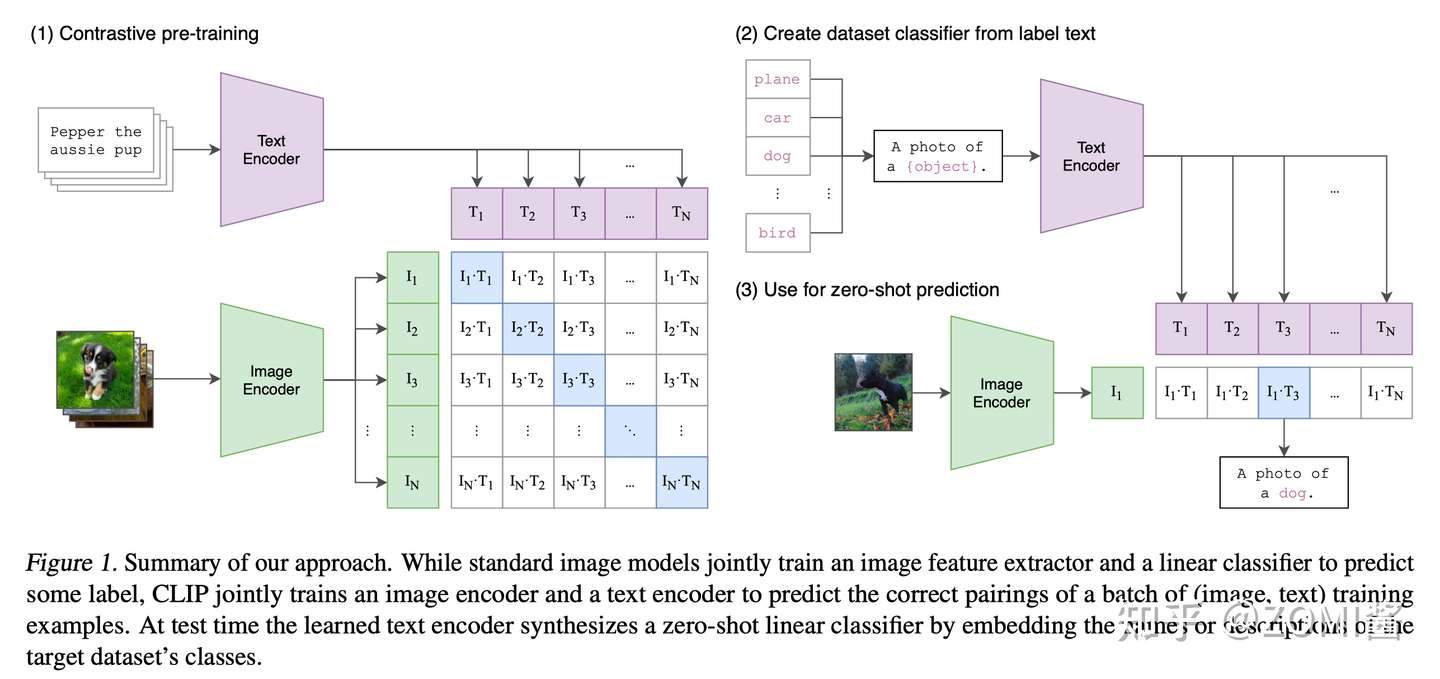
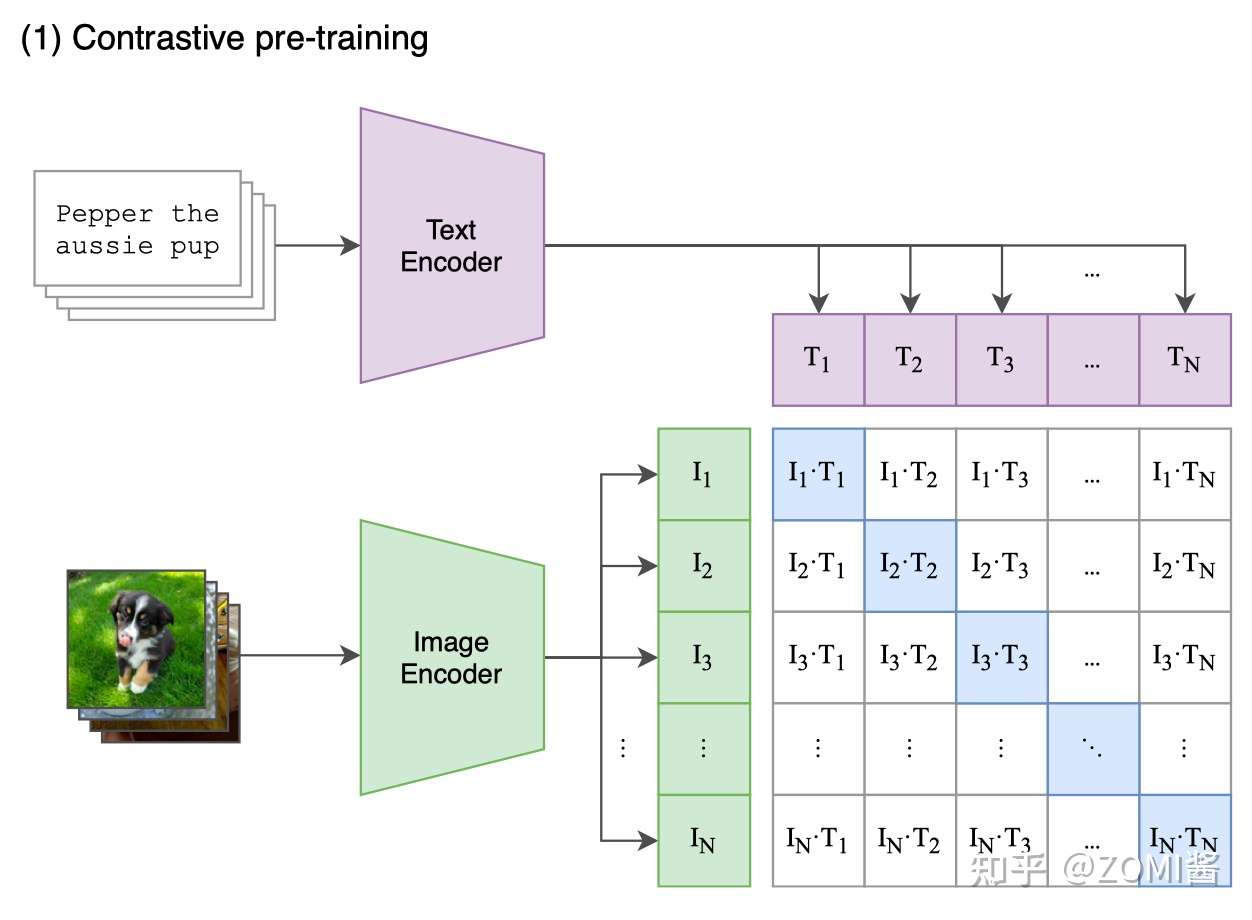
- 阶段一 Contrastive pre-training
在预训练阶段,对比学习十分灵活,只需要定义好 正样本对 和 负样本对 就行了,其中能够配对的 image-text 对即为正样本。具体来说,先分别对图像和文本提特征,这时图像对应生成 I1、I2 ... In 的特征向量(Image Feature),文本对应生成 T1、T2 ... Tn 的特征向量(Text Feature),中间对角线为正样本,其余均为负样本。
这样的话就形成了 n 个正样本,n^2 - n 个负样本。一旦有了正负样本,模型就可以通过对比学习的方式训练起来了,完全不需要手工的标注。当然,自监督的训练需要大量的数据,OPENAI 在数据准备阶段阶段使用的数据对在4亿的数量级。
在同一个batch里面算对比损失。由于4亿对 image-text pairs 训练数据巨大,训练是个十分耗费时间的事情,所以必须对训练策略进行一些改进以提升训练效率。
采用对比学习进行训练的一个重要原因也是考虑到训练效率。图中最下面的蓝线表示像 GPT2 这种预测型的任务(NLP预测型的任务是指,现在已经有一张图片拉,去预测图片对应的描述),可以看到是最慢的。中间黄线是指一种 bag of words 的方式,不需要逐字逐句地去预测文本,文本已经抽象成特征,相应的约束也放宽了,这样做训练速度提高了 3 倍。接下来进一步放宽约束,不再去预测单词,而是去判断 image-text pairs 是否一对,也就是绿色线的对比学习方法,效率进一步提升 4 倍。

- 阶段二 Create dataset classifier from label text
CLIP最牛逼的地方在于,基于400M数据上学得的先验,仅用数据集的标签文本,就可以得到很强的图像分类性能。现在训练好了,然后进入前向预测阶段,通过 prompt label text 来创建待分类的文本特征向量。
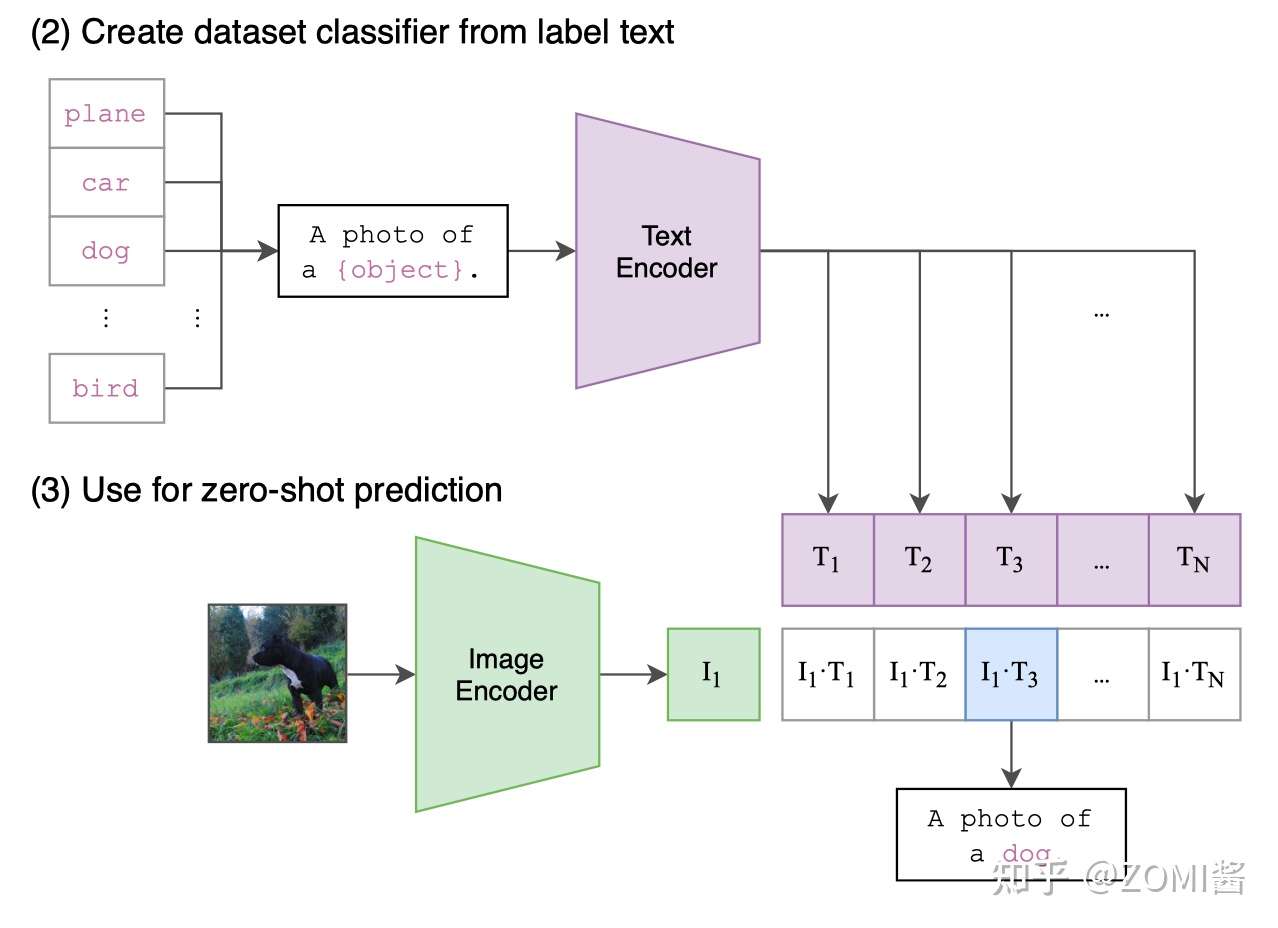
首先需要对文本类别进行一些处理,ImageNet 数据集的 1000 个类别,原始的类别都是单词,而 CLIP 预训练时候的文本端出入的是个句子,这样一来为了统一就需要把单词构造成句子,怎么做呢?可以使用 “A photo of a {object}.” 的提示模板 (prompt template) 进行构造,比如对于 dog,就构造成 “A photo of a dog.”,然后再送入 Text Encoder 进行特征提取。
具体地,用模板填空(promot)的方式从类别标签生成文本。将得到的文本输入Text Encoder。
openai_imagenet_template = [
lambda c: f'a bad photo of a {object}.',
lambda c: f'a photo of many {object}.',
lambda c: f'a sculpture of a {object}.',
lambda c: f'a photo of the hard to see {object}.',
lambda c: f'a low resolution photo of the {object}.',
......
lambda c: f'a toy {object}.',
lambda c: f'itap of my {object}.',
lambda c: f'a photo of a cool {object}.',
lambda c: f'a photo of a small {object}.',
lambda c: f'a tattoo of the {object}.',
]- 阶段三 Zero-shot prediction
最后就是推理见证效果的时候,对于测试图片,选择相似度最大的那个类别输出。
在推理阶段,无论来了张什么样的图片,只要扔给 Image Encoder 进行特征提取,会生成一个一维的图片特征向量,然后拿这个图片特征和 N 个文本特征做余弦相似度对比,最相似的即为想要的那个结果,比如这里应该会得到 “A photo of a guacamole.”,
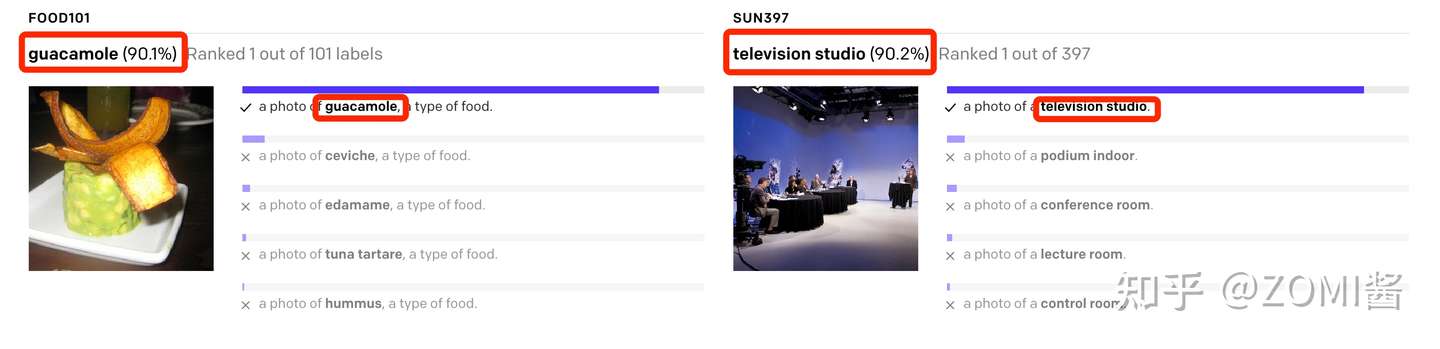
以上就是 CLIP 算法流程的总览,可以看到 CLIP 在一次预训练后,可以方便的迁移到其他视觉分类任务上进行 Zero-shot 的预测。这也是 DALL·E 在最后阶段使用 CLIP 的原因啦。
具体算法与实验
算法部分因为网络模型流程设计比较简单,因此算法伪代码也非常简单。另外 CLIP 这篇论文一共48页,从第6页开始后面都是实验部分,所以想写好论文实验部分,可以重点看看 CLIP 的实验部分,很有参考价值哦!
算法实现

其中重点是分别计算出图像和文本的 embedding 特征 I_e 和 T_e,通过矩阵乘法 dot 得到余弦相似度。接下来就是对称损失函数(symmetric loss function),而损失函数则采用对比学习常用的 InfoNCE。
对比损失函数的分子部分鼓励正例相似度越高越好,也就是在表示空间内距离越近越好;而分母部分,则鼓励任意负例之间的向量相似度越低越好,也就是距离越远越好。t 是温度系数超参,用来调节数据在单位超球面上的分布均匀性。这样,在优化过程中,通过 InfoNCE 损失函数指引,就能训练模型,以达成我们期望的目标,将成对的 image-text 映射到空间中接近的地方,和将非成对的 image-text 在表示空间内尽量推远。
重点实验
下面挑选了一些重点实验部分的结论来看看 CLIP的效果。
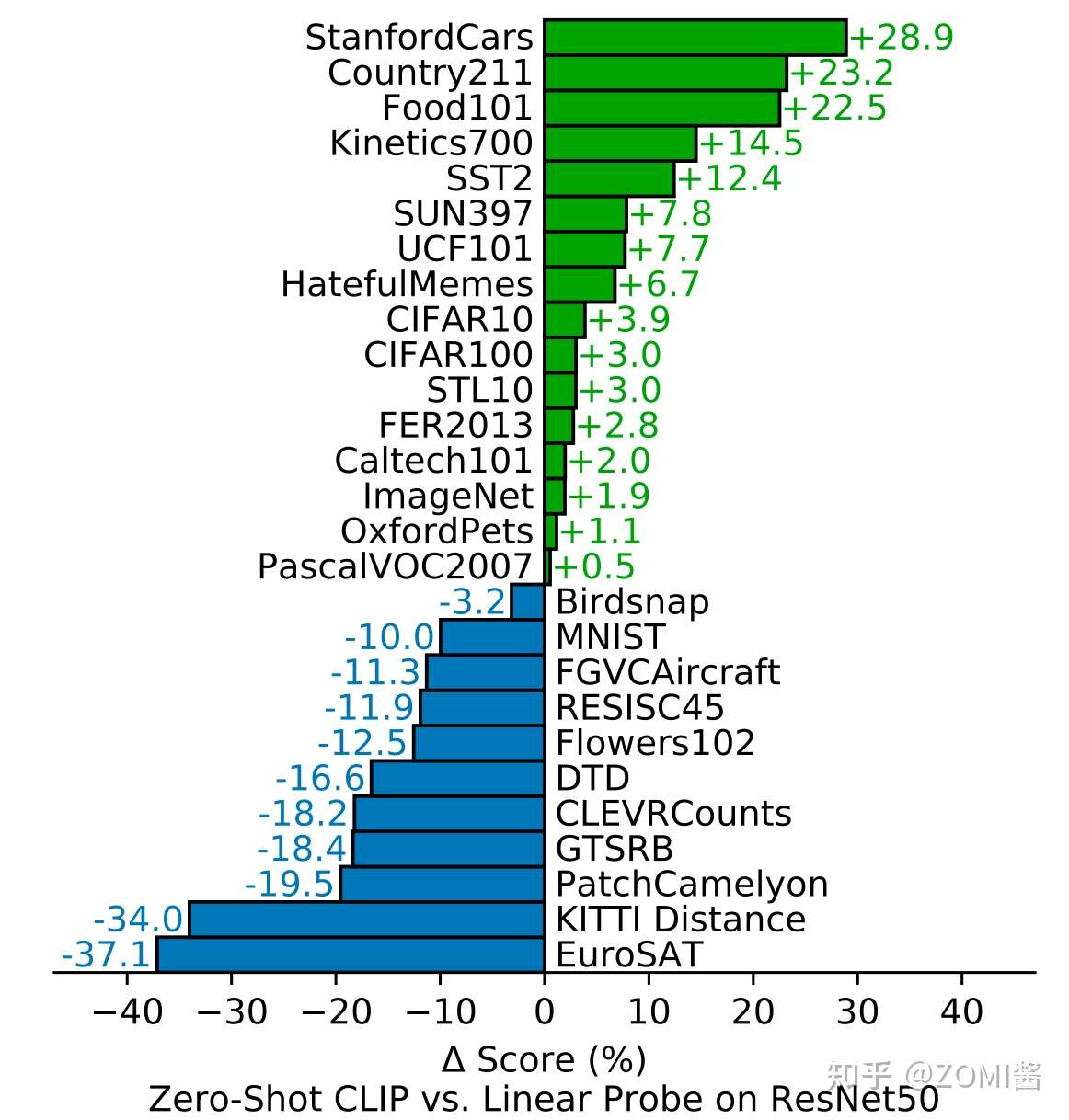
- Zero-shot CLIP v.s. Linear Probe on ResNet50
从图中可以看到,在不同的数据集上,CLIP 对比通用的 ResNet50 精度超过的有16/27,已经很强了,因为CLIP是zero-shot的,即没有用下游任务的数据,而linear probed ResNet50用了下游数据进行finetune逻辑回归分类器的参数。
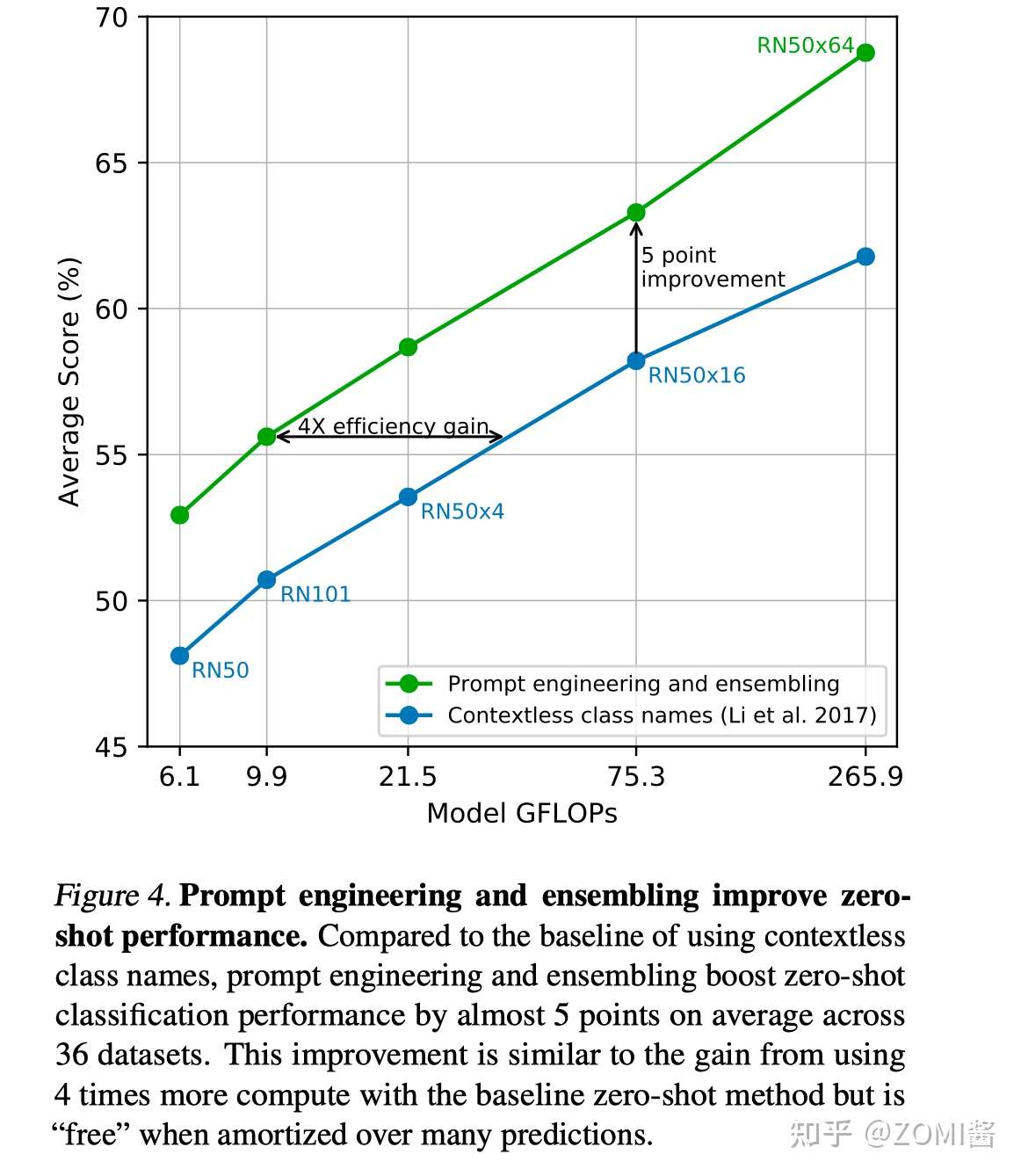
- Prompt engineering and ensembling
作者默认prompt模板是:"A photo of a {label}.",但作者发现这样的模板还是有点粗糙,可以考虑加一些context比如 "A photo of a {label}, a type of pet."。对于不同类型任务,作者做了一些手动的、特定的label prompt工程。
从另一个角度,一张图的text描述其实有很多种的,只要text的核心语义和image相同就行,那么我们还可以做一些ensemble,比如ensemble一下"A photo of a big {label}."和"A photo of a small {label}."。
可以从实验结果发现,采用 Prompt engineering + ensembling 的效果比只用没有上下文的类别名好得多。
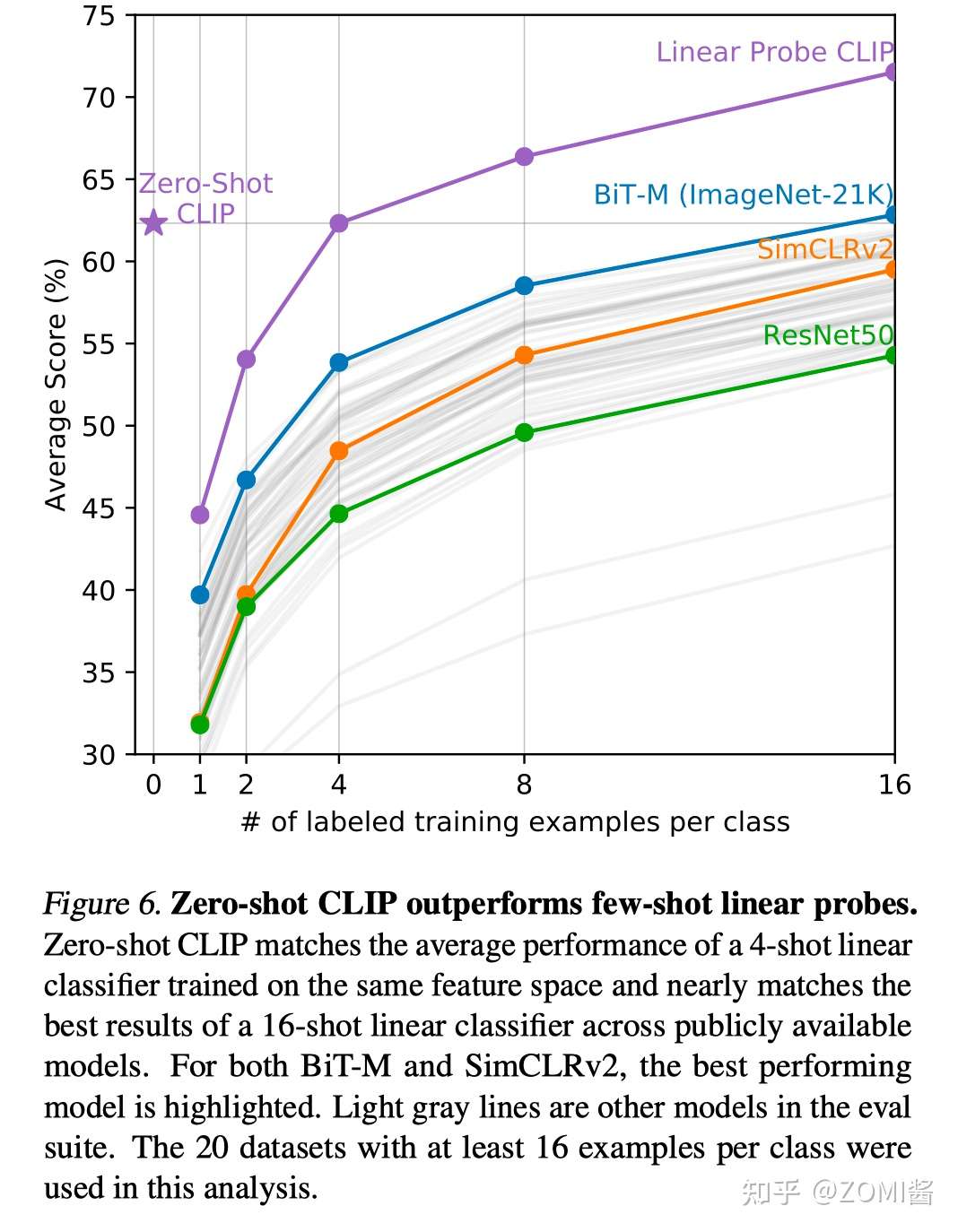
- Few-shot CLIP v.s. SOTA (ImageNet) SSL methods
作者实验分析使用了20个数据集,每个类至少有16个示例。结果看到,Zero-shot CLIP 的性能和4-shot CLIP差不多,Few-shot CLIP的performance远高于之前的SOTA模型(BiT-M/SimCLRv2/ResNet)。
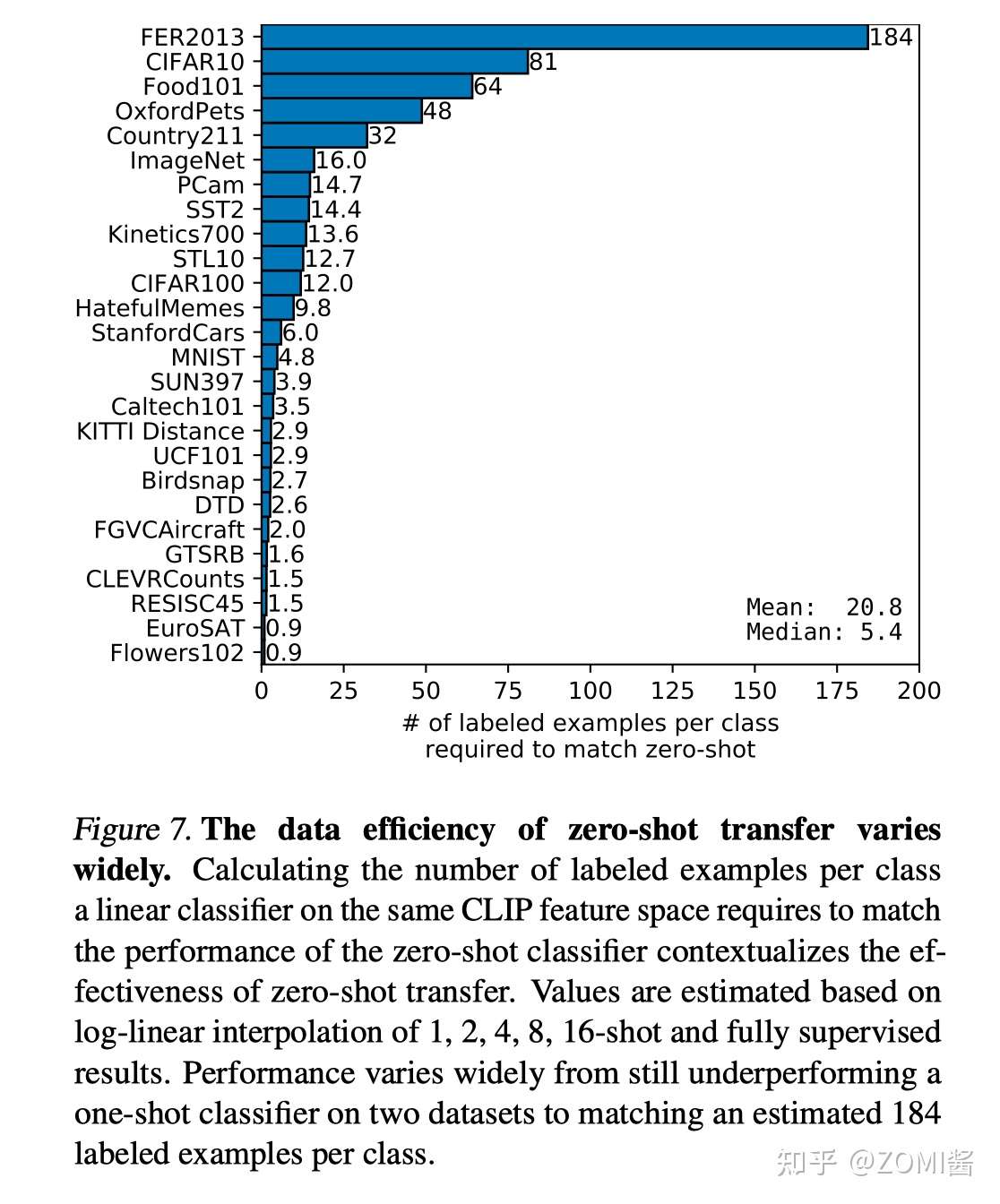
- How many shots is needed for achieving zero-shot performance
Few-shot (linear probing) CLIP (保持CLIP encoder 参数fixed,加一层逻辑回归分类器微调)平均需要 20.8-shots 才能 match zero-shot CLIP 性能。这里相当于保持了 the same CLIP feature space 上,观察 few-shot finetuning 和zero-shot 的性能差异。这里其实说明通过自然语言学到的视觉概念比少量样本 finetune 学到的好。
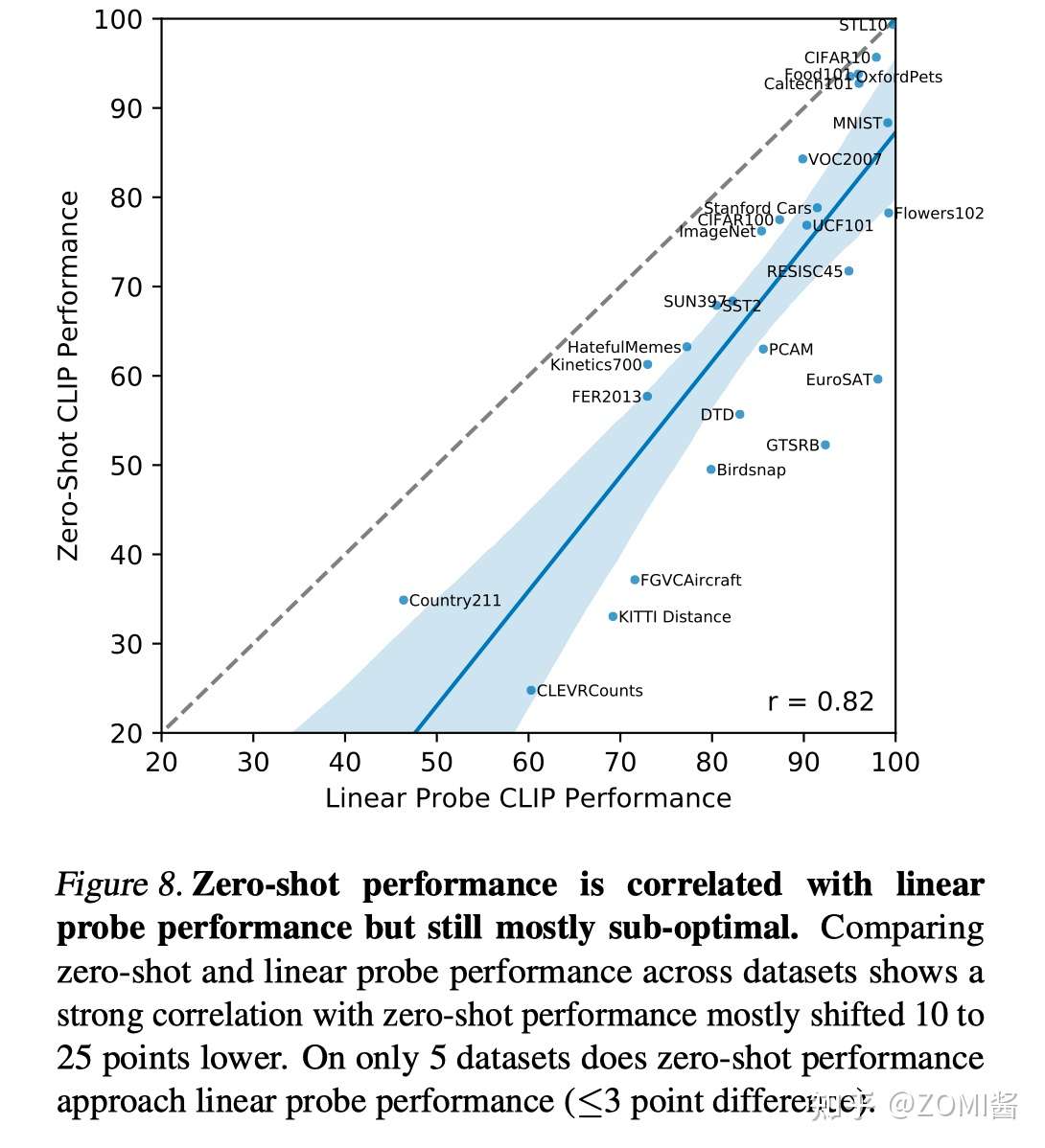
- Linear probing CLIP performance
这里不再是few-shot linear probing了,而是全量数据的linear probing,我们来看下其跟zero-shot性能的对比,实际上两者的性能是正相关的,此外,大部分情况下linear probing的性能要好不少。
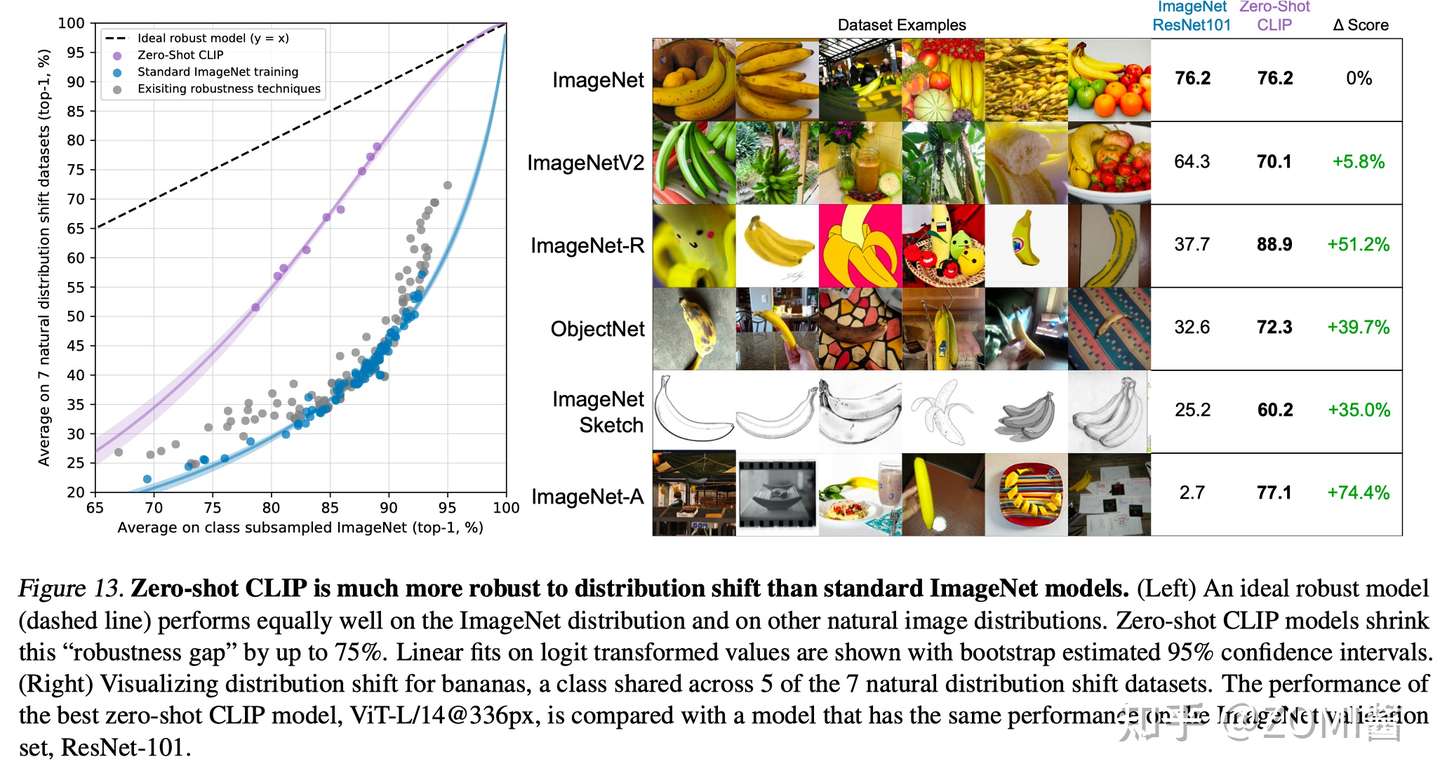
6. Robustness to Natural Distribution Shift
作者在ImageNet的7个shift datasets上观察各模型的平均性能,迁移应用于ImageNet的分类任务的,可以看到,不仅达到ResNet101的效果,且泛化能力远远强于有标签监督学习。
总结
CLIP 可以说是开辟了 CV+NLP 的多模态表征学习新时代。后面谷歌的ALIGN,微软的Florence,商汤 DeCLIP,快手 EfficientCLIP 都是研究相类似的任务。虽然 CLIP 在小部分任务上 zero-shot 精度一般,但是 CLIP 在多模态的 Encoders 能提供简单而又强大的视觉先验的表征能力。下面分开数据、精度、流程三方面来提出一些疑问和思考,希望能够帮助到更多的人去思考进一步值得研究的问题。
数据方面
论文中关于 400Million 的庞大数据集并没有提及太多(我其实很想看到他的数据集,毕竟AI是个数据驱动的时代)。如何在较小数据集上(例如Conceptual Caption,或者实验室的MEP-3M)保证学习结果值得探索。
CLIP的训练数据是从网上采集的,这些image-text pairs不确定做了哪些 data clear 和 de-bias,由于训练集的限制,可能会出现很多社会性偏见(social biases)问题,比如对不同种族性别年龄的倾向。
精度方面
CLIP 的 zero-shot 精度虽然总体上比 supervised baseline ResNet-50 要好,但其实在很多任务上比不过 SOTA methods,因此 CLIP 的 transfer learning有待挖掘。
CLIP 在 fine-grained 分类(花/车的分类)、抽象的任务(如计算图中 object 的个数)以及预训练时没见过的task(如分出相邻车辆的距离等任务 zero-shot 的精度有待提升。
Zero-shot CLIP 在真正意义上的 out-of-distribution data 上精度不好,比如在OCR中。尽管CLIP zero-shot classifier 能在很广泛的任务上 work,但究其本质CLIP 还是在有限的类别中进行对比、推理,而不能像 image caption 那样完全的flexible 地生成新的概念(如:词),这是 CLIP 功能上的缺陷,CLIP 终究不是生成模型。
流程方法
CLIP的方法论上也存在几个缺陷:在训练和挑选 CLIP 模型时,作者采用在几个数据的validation performance 来做指导,这其实是不准确的,因为它不能完全代表 CLIP 的 zero-shot 性能。如果,设计一套框架来 evaluate zero-shot performance 对于之后的研究是很重要的。
很多视觉任务很难用文本来进行表示,如何用更高效的 few-shot learning 方法优化 CLIP 也很重要。BTW,CLIP 仍然没有解决深度学习 poor data efficiency 的问题,结合 CLIP 和 self-training 可能是一个能提高 data efficiency 的方向。
虽然说 CLIP 是多模态时代的一个引领者,但究其本质仍然是Image-level的,如果是 Image-level的能不能将这个范式拓展成 dense prediction(object detection, semantic segmentation)的预训练能力呢?如果不是,那么更多模态的引入如何实现多模态数据的表征?
由于image encoder的监督信息来自且仅来自text encoder,它对文字的理解能力也就约束了图像特征的学习。提升text encoder能不能带来image encoder的提升?CLIP的text encoder能不能学到一些单模态Bert无法学到的东西?
引用
[1] 多模态定义与历史
[2] 极智AI | 多模态领域先行者 详解 CLIP 算法实现
[3] 2021.02【CLIP】Learning Transferable Visual Models From Natural Language Supervision
[4] 【多模态】CLIP模型
[5] CLIP论文 | Learning Transferable Visual Models From Natural Language Supervision
[6] CLIP:Learning Transferable Visual Models From Natural Language Supervision
[7] 【CLIP系列Paper解读】CLIP: Learning Transferable Visual Models From Natural Language Supervision
[8] Radford, Alec, et al. "Learning transferable visual models from natural language supervision." International Conference on Machine Learning. PMLR, 2021.
[9] Suzuki, Keisuke, et al. "A deep-dream virtual reality platform for studying altered perceptual phenomenology." Scientific reports 7.1 (2017): 1-11.

- 点赞
- 收藏
- 关注作者
评论(0)