AI编译器和推理引擎的区别

最近ZOMI这2/3周有幸被邀请去百度交流、去VIVO研究院交流、去MindSpore开源团队交流、去华为昇腾团队交流推理引擎。所以有些心得体会,恰好前不久又分享完课程和。
这里面提前抛转引入给出一个问题:到底推理引擎,有没有必要使用AI编译器实现?或者引入AI编译技术呢?
万能分割线~之前一直忙着做视频课程分享,基本上没怎么来知乎回答过问题了。这是半年来第一个正儿巴金回答得问题哈。
架构之间的区别
想要真正回答这个问题之间,我想先来看看什么是AI编译器,什么是AI推理引擎,他们之间的架构有什么不同,因为呢架构决定不同技术栈里面的技术功能点和模块,通过架构可以了解之前最明显的区别。
关于AI编译器的架构,具体大家可以参考一篇综述《The Deep Learning Compiler: A Comprehensive Survey》

AI编译器的架构
AI编译器的架构主要分为图层和kernel层,所谓的kernel大家简单理解为算子就好了。AI编译器主要分为前后端,分别针对于硬件无关和硬件相关的处理。每一个部分都有自己的 IR (Intermediate Representation,中间表达),每个部分也会对进行优化:
High-level IR:用于表示计算图,其出现主要是为了解决传统编译器中难以表达深度学习模型中的复杂运算这一问题,为了实现更高效的优化所以新设计了一套 IR。
Low-level IR:能够在更细粒度的层面上表示模型,从而能够针对于硬件进行优化,文中将其分为了三类。
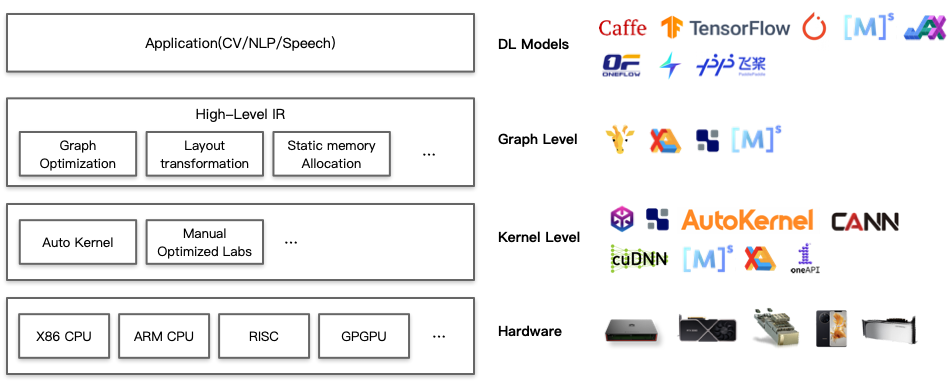
目前AI编译器,在性能上主要是希望打开计算图和算子的边界,进行重新组合优化,发挥芯片的算力。计算图层下发子图中的算子打开成小算子,基于小算子组成的子图,进行编译优化,包括buffer fusion、水平融合等,关键是大算子怎样打开、小算子如何重新融等。
表达上需要处理 yTorch 灵活表达 API 方式成为 AI 框架参考标杆,图层的神经网络编译器主要就是考虑如何把类 PyTorch 的表达转换到图层的IR进行优化;类PyTorch的Python原生表达,静态化转换;最后就是,AI专用编译器架构,打开图算边界进行融合优化叭叭叭。
因此总结下来有:
表达分离:计算图层和算子层仍然分开,算法工程师主要关注图层的表达,算子表达和实现主要是框架开发者和芯片厂商提供。
功能泛化:对灵活表达上的动静态图转换、动态 Shape、稀疏计算、分布式并行优化等复杂的需求难以满足。
平衡效率和性能:算子实现上在 Schedule、Tiling、Codegen 上缺乏自动化手段,门槛高,开发者既要了解算子计算逻辑,又要熟悉硬件体系架构。
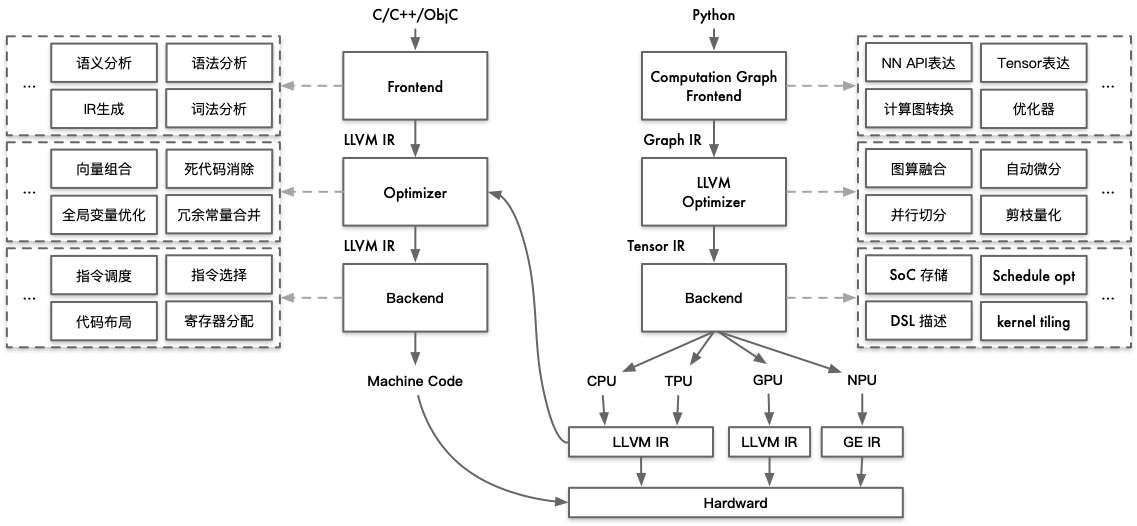
当然,我们从整体架构图可以看到,AI编译器就是针对具体的AI加速芯片硬件,对上层用户接触到的高级语言进行编译,为AI流程实现更加高效的执行,高级语言在AI流程表示的优化是AI编译器的重点。
对AI编译器有兴趣的可以深入了解下AI编译器的整体内容:

推理引擎的架构
大家可能关心到比较像的地方:推理引擎中的图优化部分,跟AI编译器中的图编译优化非常像,都是有算子融合、子表达式消除、数据布局转换等内容。
不过呢,推理引擎的整体架构,其实这只是图转换的一部分,而且具体的实现方式跟AI编译器完全不一样,轻便很多,下面的内容会重点讲讲实现细节,而这一节内容主要聚焦于架构。推理引擎的特点是:
需要对 iOS / Android / PC 不同硬件架构和操作系统进行适配,单线程下运行深度学习模型达到设备算力峰值。
针对主流加速芯片进行深度调优,如 OpenCL 侧重于推理性能极致优化,Vulkan 方案注重较少初始化时间。
编写SIMD代码或手写汇编以实现核心运算,充分发挥芯片算力,针对不同kernel算法提升性能。
支持不同精度计算以提升推理性能,并对 ARMv8.2 和 AVX512 架构的相关指令进行了适配。
架构分为2个主要的阶段:
优化阶段:模型转换工具,由转换和图优化构成;模型压缩工具、端侧学习和其他组件组成。
运行阶段:即实际的推理引擎,负责AI模型的加载与执行,可分为调度与执行两层。
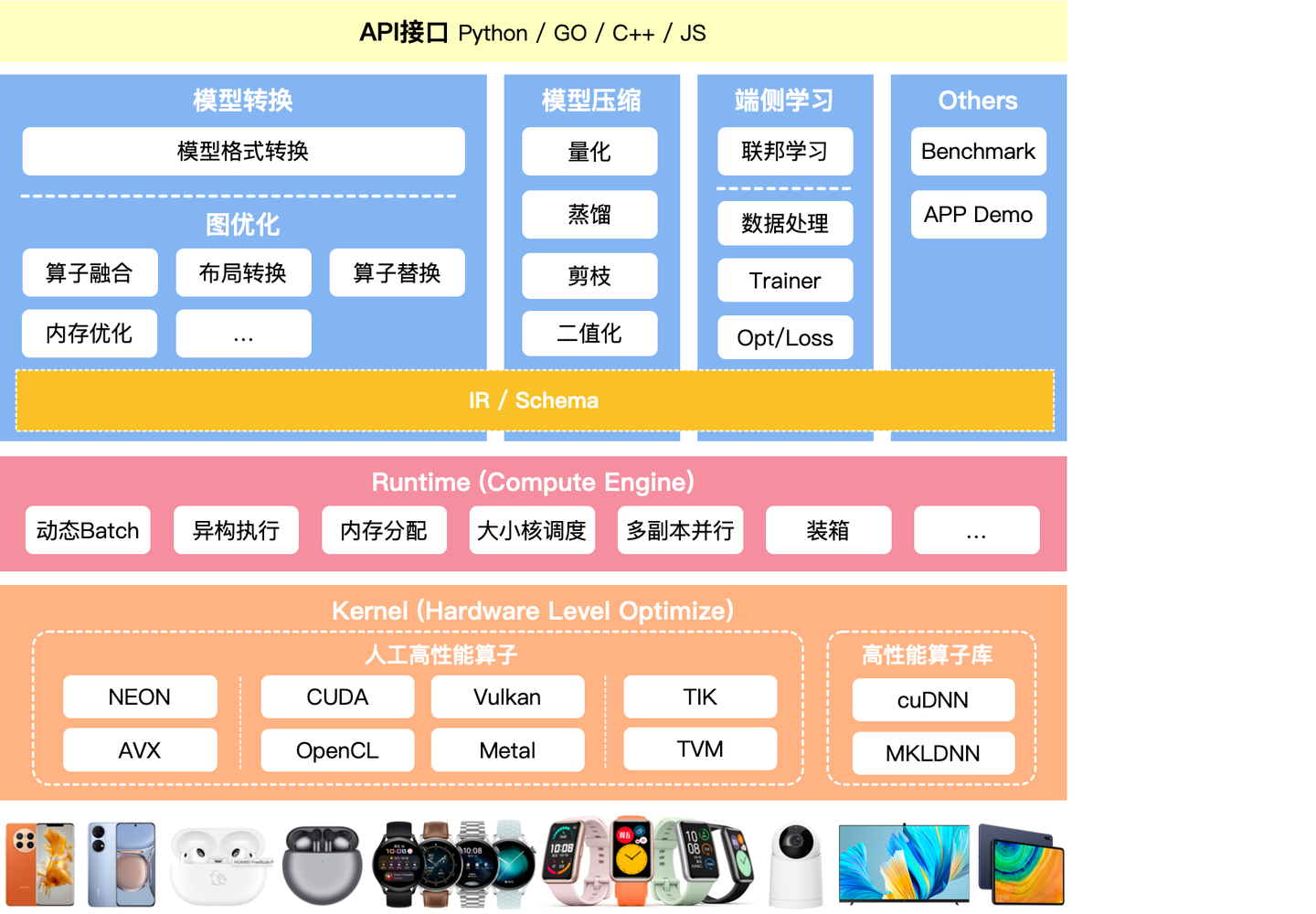
当然,我们从整体架构图可以看到,图优化在推理引擎中占了很小的一部分,推理引擎聚焦于Runtime执行部分和Kernel算子内核层,为不同的硬件提供更加高效、快捷的执行Engine。
对推理引擎有兴趣的可以深入了解下推理引擎的整体内容:

应用场景的区别
从应用场景来看,AI编译器的使用场景包括训练和推理,而推理引擎的聚焦点是推理场景。
AI编译器聚焦训练场景
AI编译器的使用场景包括训练和推理。下面来看看训练郭晨主要包括哪些过程:
训练过程通过设计合适 AI 模型结构以及损失函数和优化算法,将数据集以 mini-batch 反复进行前向计算并计算损失,反向计算梯度利用优化函数来更新模型,使得损失函数最小。训练过程最重要是梯度计算和反向传播。
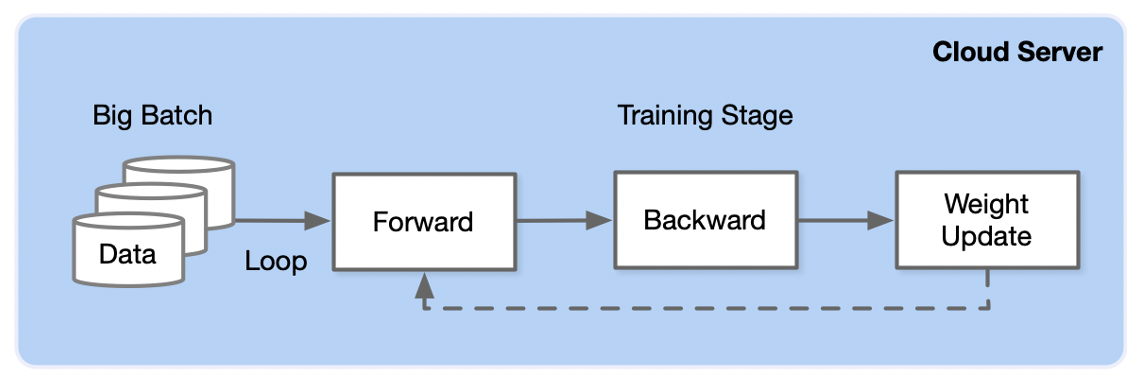
推理引擎针对推理场景
推理在训练好的模型结构和参数基础上,一次前向传播得到模型输出过程。相对于训练,推理不涉及梯度和损失优化。最终目标是将训练好的模型部署生产环境中。
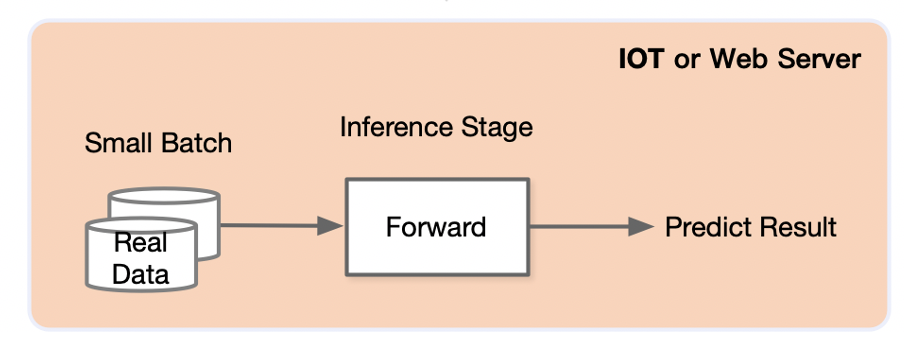
模型训练后会保存在文件系统中,随着训练处的模型效果不断提升,可能会产生新版本的模型,并存储在文件系统中并由一定的模型版本管理协议进行管理。之后模型会通过服务系统部署上线,推理系统首先会加载模型到内存,同时会对模型进行一定的版本管理,支持新版本上线和旧版本回滚,对输入数据进行批尺寸(Batch Size)动态优化,并提供服务接口(例如,HTTP,gRPC等),供客户端调用。用户不断向推理服务系统发起请求并接受响应。除了被用户直接访问,推理系统也可以作为一个微服务,被数据中心中其他微服务所调用,完成整个请求处理中一个环节的功能与职责。
技术实现的区别
到了这里,就回到ZOMI刚开始提出的疑问,到底推理引擎,有没有必要使用AI编译器实现?或者引入AI编译技术呢?
首先明确的是,AI编译器和推理引擎,都不是用Python来实现的,都是用一些比较底层的语言。
AI编译器的实现目前还处在百花齐放的阶段,具体还真的很复杂,特别是针对CODEGEN部分,不仅仅要对接底层LLVM到不同的硬件,甚至部分会对接到具体的硬件指令ISA;中间要管理各种专门针对AI流程进行优化的Pass;这些Pass之前需要把高级语言Python等实现的AI流程,转换成为计算图或者IR,然后才能给到具体的Pass去进行优化。
而推理引擎的实现相对来说,简单很多,围绕几个线程或者进程,实现不间断地调度也就是runtime的原型,从内存读取数据然后Keep 执行。针对不同的硬件实现不同的Kernel或者算子,这里面可能会用OpenCL、CUDA等API来实现,甚至出现汇编,但是总体比较聚焦,不会太多,因为推理不像训练场景有无限可能,部署会比较聚焦,具体算法也会进行定制化优化。
整体流程会轻便很多,如果有时间也希望可以一些小的demo项目跟大家一起练练手。
业界现状
开源AI编译器
最近很有意思的一个技术圈的消息就是,LLVM之父Chris Lattner 推出了新的AI编程语言MOJO和新的推理引擎,想要使用就过来申请啦。
目前大部分AI编译器,主要是聚焦解决训练场景算子大量泛化,第三方AI芯片厂商需要大量的开发新的算子,于是希望有AI编译器更好地帮助AI开发工程师开发新的算子(说白了自动生成 Auto Code Gen!!!)
针对这种情况呢,现在业界已有的AI编译器有,可以根据论文《The Deep Learning Compiler: A Comprehensive Survey》来横向了解下。
虽然nGraph和TC、GLOW都经历了失败或者没有再继续维护,不过里面的很多思想也被其他新出现的AI编译器所借鉴,例如TC里面的多面体,就被MindSpore的AKG所借鉴过来不断发展
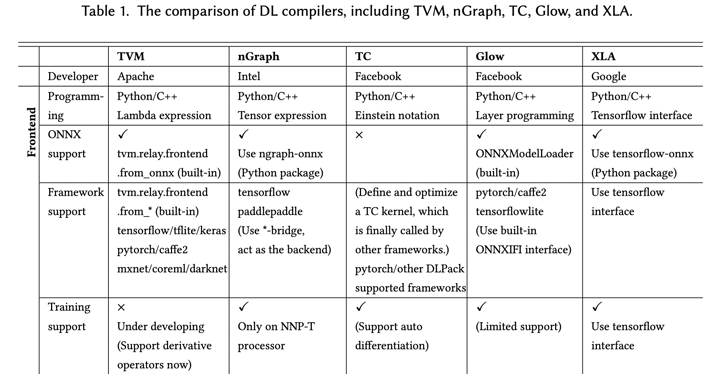
XLA:XLA(加速线性代数)是一种针对特定领域的线性代数编译器,能够加快 TensorFlow 模型的运行速度,而且可能完全不需要更改源代码。图层下发子图中的算子打开成小算子,基于小算子组成的子图进行编译优化,包括 buffer fusion、水平融合等,关键是大算子怎样打开、小算子如何重新融合、新的大算子如何生成,整体设计主要通过HLO/LLO/LLVMIR 实现,所有 Pass 规则都是手工提前指定。
TVM:为了使得各种硬件后端的计算图层级和算子层级优化成为可能,TVM 从现有框架中取得 DL 程序的高层级表示,并产生多硬件平台后端上低层级的优化代码,其目标是展示与人工调优的竞争力。分为Relay和TVM两层,Relay关注图层,TVM关注算子层,拿到前端子图进行优化,Relay关注算子间融合、TVM关注新算子和kernel生成,区别在于TVM 开放架构,Relay目标是可以接入各种前端,TVM也是一个可以独立使用的算子开发和编译的工具,算子实现方面采用 Compute(设计计算逻辑)和 Schedule(指定调度优化逻辑)分离方案。
TensorComprehensions:是一种可以构建 just in time(JIT)系统的语言,程序员可通过该语言用高级编程语言去高效的实现 GPU 等底层代码。子计算逻辑的较容易实现,但 Schedule 开发难,既要了解算法逻辑又要熟悉硬件体系架构,此外图算边界打开后,小算子融合后,会生成新算子和 kernel,新算子 Schedule 很难生成,传统方法定义 Schedule 模板;TC 希望通过 Polyhedral model 实现 auto schedule。
nGraph:nGraph运作应作为深度学习框架当中更为复杂的 DNN 运算的基石,并确保在推理计算与训练及推理计算之间取得理想的效率平衡点。
开源推理引擎
对于推理引擎,那可是每个厂商都不会放过的KPI哈哈。相对于AI编译器、AI训练框架,推理引擎实现起来其实从上面的架构简单介绍可以看出来,简单很多,主要包括3大模块(模型转换与优化、Kernel/算子层、Runtime执行引擎),有了这3大模块就可以很好地配合起来工作,至于其他额外模块就是一些差异化竞争力体现了。
LightSeq:大厂,专门针对NLP领域提出LightSeq的推理引擎,可以应用于机器翻译、自动问答、智能写作、对话回复生成等众多文本生成场景,大大提高线上模型推理速度,改善用户的使用体验,降低企业的运营服务成本。
AITemplate:Meta AI研究人员在昨天发布了一个全新的AI推理引擎AITemplate(AIT),该引擎是一个Python框架,它在各种广泛使用的人工智能模型(如卷积神经网络、变换器和扩散器)上提供接近硬件原生的Tensor Core(英伟达GPU)和Matrix Core(AMD GPU)性能。
MNN:国内比较早期也做的比较成熟的推理引擎,很多国内推理引擎多多少少都看到MNN的痕迹。MNN 负责加载网络模型,推理预测返回相关结果,整个推理过程可以分为模型的加载解析、计算图的调度、在异构后端上高效运行。
TensorRT:这个不用说大家都知道了,英伟达自家推理引擎,TensorRT 是一个高性能深度学习推理平台,能够为在英伟达 GPU 上运行的语音、视频等 APP 提供更低地延迟、更高的吞吐量。TensorRT 包含输入模型的解析器、支持全新 ops 的插件以及在利用优化进行推理之前的层。
OpenPPL/Paddle Lite:OpenPPL 是百度推出的高性能深度学习推理引擎,而 LSTM、GRU 以及 OneHot 是 NLP/语音领域的经典算子,这些算子在 OpenPPL 中的支持正处于缺失抑或是未经深度优化的状态。
当然还有华为MindSpore Lite,腾讯的NCNN,还有闭源的OPPO、VIVO自研推理引擎。基本上,你能接触到的一线/二线互联网厂商都会有自己的推理引擎,这里面就不在举例啦~~
吐槽!!!
真的是不想吐槽VIVO研究院,哈哈,还是忍不住吐槽一下。跟两位技术专家交流了大概1多小时,他们目前想实现一个AI编译器,去承接AI推理的业务,落入他们未来的ASIC或者推理专用芯片里面。
另外有一点我能理解一点就是,在手机上面一块SOC里面包含的IP包括DSP、Adreno GPU、ARM CPU、Mali GPU,有时候是高通呢、有时候是联发科技,说不定有时候是自研芯片(虽然OPPO的造芯部门ZEKU已经凉凉了)
因为对接的芯片IP越来越多,不同的IP需要实现各种各样的算子用来加速,特别是在异构IP上进行加速变成一个需要大量工程经验或者工程师的工作,而且算子层出不穷,一会来一个layer norm,一会来一个 batch norm,没想到还有group norm。
于是VIVO研究院就想搞一个编译器,实现图算融合+算子自动生成,面向之前总结的AI编译器第三阶段。不过沟通下来,他们好像没太分清楚目前AI编译器的现状,怎么把图算融合和算子自动生成分开,而是把他看成一个整体了。我觉得如果去了这个岗位,估计未来就跳坑,然后风风火火搞了1年多GG凉凉了,被迫转岗哈哈!!!嗷呜!!!
为什么这么说?目前第三阶段AI编译器技术成熟了吗?图算如何融合?算子生成如何打破图层?PT图层如何快速获取?CodeGen实现Gen什么代码?CodeGen能超过人工极致优化?选择什么编译技术路线?TVM和LMIR?到底推理引擎,有没有必要使用AI编译器实现?或者引入AI编译技术呢?
想不清楚就投入,这很危险呐~呐~~

- 点赞
- 收藏
- 关注作者
评论(0)