面向动态环境的 Agent 系统容错任务调度策略研究

【摘要】 面向动态环境的 Agent 系统容错任务调度策略研究在多 Agent 系统(MAS,Multi-Agent System)中,系统的整体功能依赖于各个 Agent 的协作完成。然而,在现实分布式环境中,单个 Agent 可能因为硬件故障、网络中断或软件异常而失效,如果没有有效的容错与鲁棒性设计,系统的整体性能和可靠性将受到严重影响。本文将深入分析 Agent 系统中的容错机制与鲁棒性设计策...
面向动态环境的 Agent 系统容错任务调度策略研究
在多 Agent 系统(MAS,Multi-Agent System)中,系统的整体功能依赖于各个 Agent 的协作完成。然而,在现实分布式环境中,单个 Agent 可能因为硬件故障、网络中断或软件异常而失效,如果没有有效的容错与鲁棒性设计,系统的整体性能和可靠性将受到严重影响。本文将深入分析 Agent 系统中的容错机制与鲁棒性设计策略,并通过 Python 示例展示如何在 Agent 故障发生时保持系统功能的连续性。
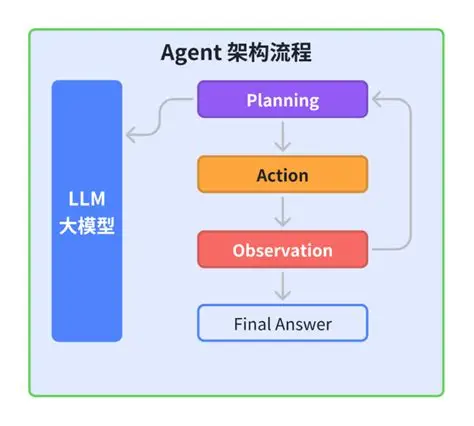
一、Agent 系统中的故障类型
在分布式 Agent 系统中,故障通常分为以下几类:
- Crash 故障:Agent 意外停止运行,不再响应请求。
- 通信故障:Agent 仍运行,但与其他 Agent 的消息传递中断或延迟。
- 逻辑错误:Agent 内部算法出现异常,导致输出错误结果。
- 性能退化:Agent 处理速度异常缓慢,影响整个系统协作效率。
二、容错与鲁棒性设计策略
为了提升系统的鲁棒性,通常采用以下策略:
1. 冗余 Agent 设计
- 为关键任务分配多个 Agent 副本,即使部分 Agent 故障,其他 Agent 仍能完成任务。
- 常用于数据采集、模型训练和消息转发等关键模块。
2. 心跳检测机制
- 定期向系统报告状态,如果超时未收到心跳,判定 Agent 故障。
- 可与自动重启或任务迁移机制结合,保证任务不中断。
3. 任务动态迁移
- 当 Agent 故障或性能下降时,将其未完成任务迁移到其他空闲 Agent。
- 支持负载均衡和任务连续性。
4. 结果校验与投票机制
- 对多个 Agent 计算结果进行交叉验证或投票融合,减少单个 Agent 输出错误对系统影响。
- 适用于聚类、分类或预测任务等多 Agent 协同场景。
5. 异常检测与自愈机制
- 通过监控日志、性能指标或模型输出异常检测异常 Agent。
- 系统可自动重启、回滚或重新分配任务,实现自愈。
三、Python 示例:简单多 Agent 容错系统
下面以分布式计算任务为例,演示如何在单个 Agent 故障时,保持系统任务完成。
import random
import time
import threading
class Agent(threading.Thread):
def __init__(self, agent_id, task_queue, result_dict):
super().__init__()
self.agent_id = agent_id
self.task_queue = task_queue
self.result_dict = result_dict
self.alive = True
def run(self):
while self.alive:
if not self.task_queue:
break
task = self.task_queue.pop(0)
# 模拟故障:10%概率崩溃
if random.random() < 0.1:
print(f"Agent {self.agent_id} crashed!")
self.alive = False
break
result = task ** 2 # 简单计算任务
print(f"Agent {self.agent_id} processed {task}, result={result}")
self.result_dict[self.agent_id].append(result)
time.sleep(0.1)
def monitor_agents(agents, task_queue):
while any(agent.is_alive() for agent in agents):
for agent in agents:
if not agent.is_alive() and agent.alive: # 崩溃未处理
print(f"Restarting Agent {agent.agent_id} to continue tasks...")
new_agent = Agent(agent.agent_id, task_queue, agent_results)
agents.append(new_agent)
new_agent.start()
time.sleep(0.5)
# 任务和结果存储
tasks = [i for i in range(1, 21)]
agent_results = {i: [] for i in range(3)}
# 创建 Agent
agents = [Agent(i, tasks.copy(), agent_results) for i in range(3)]
# 启动 Agent
for agent in agents:
agent.start()
# 启动监控线程
monitor_thread = threading.Thread(target=monitor_agents, args=(agents, tasks))
monitor_thread.start()
# 等待完成
for agent in agents:
agent.join()
monitor_thread.join()
print("All tasks completed. Results:")
print(agent_results)
示例说明:
- 系统包含三个 Agent 并行处理平方计算任务。
- 每个 Agent 有 10% 概率随机崩溃。
- 监控线程检测崩溃的 Agent,并自动重启以完成剩余任务。
- 任务结果存储在
agent_results,保证即使部分 Agent 故障,系统任务仍能完成。
四、系统特点
- 高鲁棒性:单个 Agent 故障不会阻塞整个系统,任务可以动态迁移或重新分配。
- 可扩展性:新增 Agent 只需加入任务队列和监控机制即可。
- 实时监控与自愈:结合心跳检测和监控线程,实现故障检测和自动恢复。
- 灵活容错策略:可扩展为投票融合、结果校验或副本冗余等高级策略。
五、总结
在多 Agent 系统中,容错与鲁棒性是保证系统可靠性与持续性的核心设计要素。通过冗余设计、心跳监控、任务动态迁移及结果校验等策略,可以有效减轻单个 Agent 故障对整体系统的影响。本文的示例演示了如何通过简单 Python 机制实现基本的容错功能,为实际分布式 AI 系统提供参考方案。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)