基于 YOLOv8 的智能车牌定位检测系统设计与实现—从模型训练到 PyQt 可视化落地的完整实战方案

基于 YOLOv8 的智能车牌定位检测系统设计与实现—从模型训练到 PyQt 可视化落地的完整实战方案
一、项目背景与研究意义
随着智慧交通与城市智能化建设的不断推进,车牌识别(License Plate Detection & Recognition) 已成为交通管理、停车系统、电子收费、高速卡口等场景中的关键技术模块。
在整个车牌识别流程中,车牌位置检测 是最基础、也是最关键的一步。如果检测阶段出现漏检或定位不准,将直接影响后续 OCR 识别效果。
传统基于规则或颜色特征的方法存在明显局限:
- 对光照变化敏感
- 难以适应复杂背景
- 泛化能力差
- 实际工程中误检率高
近年来,基于深度学习的目标检测算法 在该领域表现突出,尤其是 YOLO 系列模型,在实时性和精度之间取得了良好平衡。
因此,本文将完整介绍一个 基于 YOLOv8 的车牌位置实时检测系统,从数据集、模型训练到 PyQt5 图形界面部署,给出一套可直接运行、可二次开发、可用于课程设计或毕设的完整工程方案。
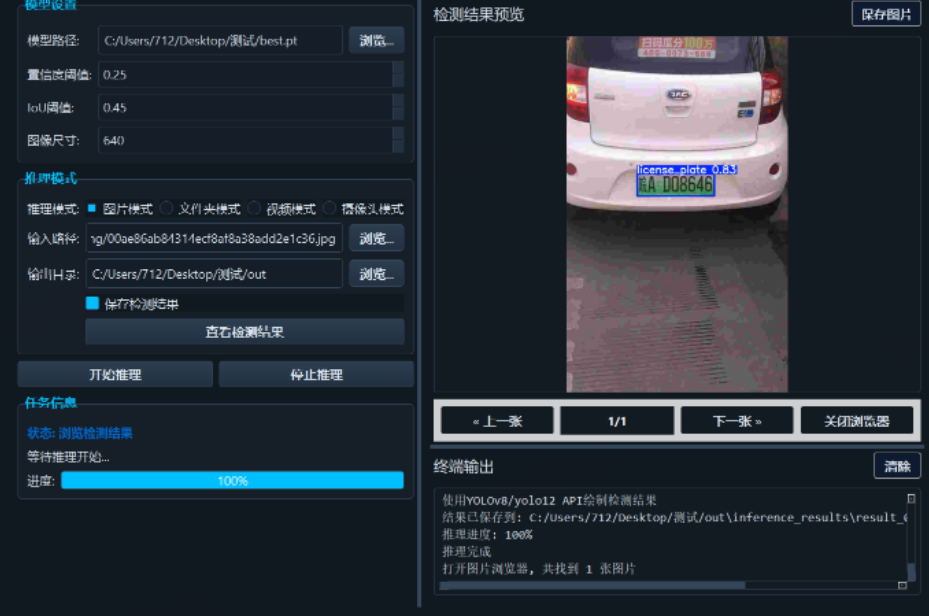
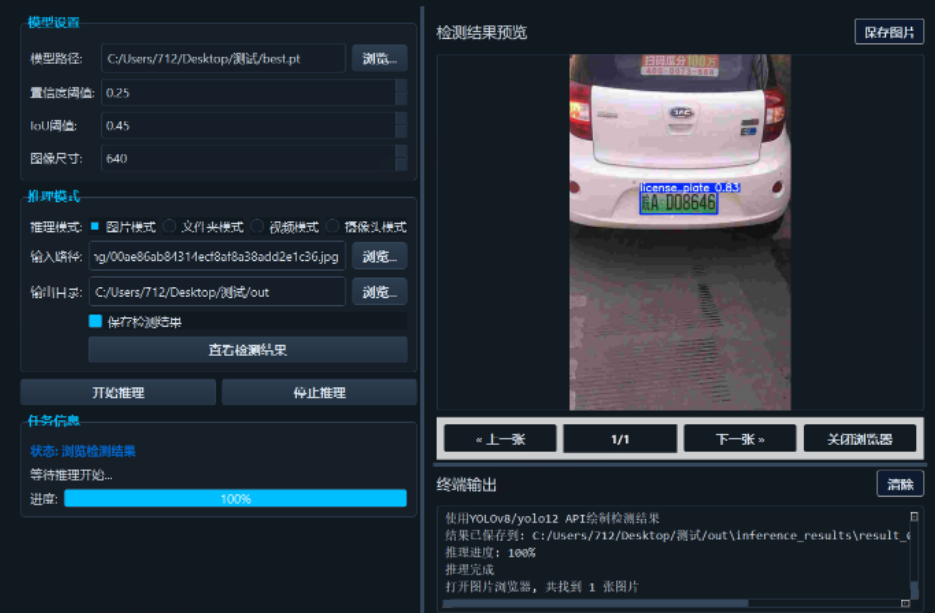
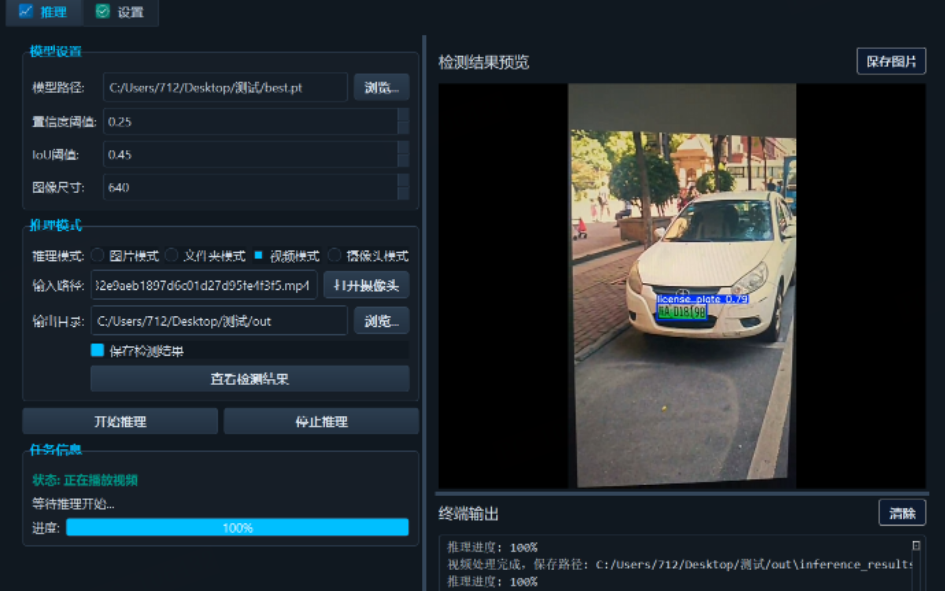
源码下载与效果演示
哔哩哔哩视频下方:
https://www.bilibili.com/video/BV1ZZ7szhEdM
二、系统总体设计
2.1 系统架构概览
本系统采用典型的 “模型 + 推理接口 + GUI 前端” 架构,整体流程如下:
输入源(图片 / 视频 / 摄像头)
↓
YOLOv8 目标检测模型
↓
检测结果解析(边框、类别、置信度)
↓
PyQt5 图形界面实时显示与结果保存
2.2 功能模块划分
系统主要包含以下功能模块:
-
输入模块
- 单张图片检测
- 文件夹批量检测
- 视频文件检测
- 摄像头实时检测
-
模型推理模块
- YOLOv8 权重加载
- GPU / CPU 自动适配
- 置信度阈值可配置
-
结果展示模块
- 实时绘制检测框
- 类别与置信度标注
- 检测结果保存
-
训练支持模块
- 数据集结构说明
- YOLOv8 训练命令
- 模型评估指标输出
三、YOLOv8 模型原理简析
3.1 YOLOv8 技术特点
YOLOv8 是 Ultralytics 于 2023 年发布的新一代 YOLO 模型,相较于 YOLOv5 / YOLOv7,在工程实践中具有以下优势:
- Anchor-Free 设计
- 更高的检测精度
- 更快的推理速度
- 原生支持多任务(检测 / 分割 / 姿态)
- 模型结构更清晰,便于二次开发
本项目使用 YOLOv8 的 Detection(目标检测)分支,仅关注车牌区域的定位问题。
3.2 网络结构说明(简要)
YOLOv8 网络主要由三部分构成:
-
Backbone
- 提取多尺度特征
- 使用 C2f 等轻量化模块
-
Neck
- FPN + PAN 结构
- 融合不同层级特征
-
Head
- Anchor-Free 检测头
- 直接预测中心点、宽高与类别
四、数据集构建与格式规范
4.1 数据集组织结构
采用标准 YOLO 格式组织数据:
dataset/
├── images/
│ ├── train/
│ └── val/
├── labels/
│ ├── train/
│ └── val/
4.2 标签格式说明
每张图像对应一个 .txt 标签文件,格式如下:
class_id x_center y_center width height
其中坐标全部为 归一化数值(0~1)。
示例:
0 0.5123 0.3784 0.4012 0.1856
本项目仅设置一个类别:
license_plate
五、模型训练流程详解
5.1 环境准备
pip install ultralytics
确认 GPU 环境(可选):
nvidia-smi
5.2 训练配置文件
data.yaml 示例:
path: dataset
train: images/train
val: images/val
names:
0: license_plate
5.3 启动训练
yolo detect train \
data=data.yaml \
model=yolov8n.pt \
epochs=100 \
batch=16 \
imgsz=640
训练完成后,将在 runs/detect/train 目录生成:
weights/best.ptresults.pngconfusion_matrix.png
5.4 模型评估指标
重点关注以下指标:
- Precision
- Recall
- mAP@0.5
- mAP@0.5:0.95
在车牌检测任务中,若 mAP@0.5 达到 90% 以上,即可满足大多数工程需求。
六、模型推理与结果解析
6.1 Python 推理示例
from ultralytics import YOLO
model = YOLO("best.pt")
results = model("test.jpg", conf=0.25, save=True)
6.2 推理结果内容
每个 results 对象包含:
- 边框坐标(xyxy)
- 类别 ID
- 置信度
- 原始图像路径
- 保存结果路径
七、PyQt5 图形界面设计与实现
7.1 界面设计目标
- 零命令行操作
- 所见即所得
- 支持实时检测
- 支持结果保存
7.2 核心界面功能
- 文件选择按钮
- 视频/摄像头切换
- 置信度调节
- 检测结果显示区域
7.3 实时检测流程
- 获取图像帧
- 调用 YOLOv8 推理
- 绘制检测框
- 显示到 GUI 界面

八、系统运行与部署方式
8.1 直接运行(推荐)
python main.py
项目已集成:
- 训练完成权重
- 推理逻辑
- UI 界面
无需再次训练即可使用。
8.2 二次开发方向
- 接入 OCR 模块 实现车牌字符识别
- 多目标联合检测(车辆 + 行人 + 车牌)
- 导出 ONNX / TensorRT
- 部署至 Jetson / 边缘设备
九、工程应用价值分析
本项目具备以下实际价值:
- ✔ 适合作为 课程设计 / 毕设项目
- ✔ 适合学习 YOLOv8 工程化落地
- ✔ 可直接扩展为完整车牌识别系统
- ✔ 界面友好,适合非算法人员使用

十、总结
本文完整介绍了一个 基于 YOLOv8 的车牌位置检测系统,从模型原理、数据准备、训练评估到 PyQt5 可视化部署,构建了一套可复现、可运行、可扩展的工程方案。
如果你希望:
- 快速掌握 YOLOv8 实战
- 构建真实可用的检测系统
- 为毕设或项目准备高质量工程
那么该方案将是一个非常理想的参考起点。
如果本文对你有所帮助,欢迎点赞、收藏与交流 🚀

- 点赞
- 收藏
- 关注作者
评论(0)