Learning to Learn:基于元学习的 Agent 少样本环境迁移方法研究

基于元学习的 Agent 快速适应:少样本场景下的环境迁移学习
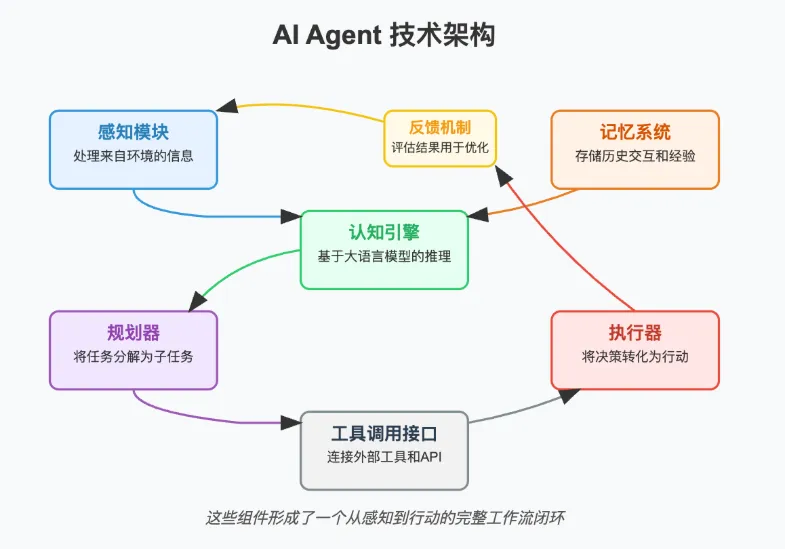
一、背景与问题定义
在强化学习(Reinforcement Learning, RL)和智能 Agent 领域,一个长期存在的核心问题是:Agent 在新环境中往往需要大量交互样本才能学会有效策略。然而在现实世界中,数据获取成本高昂、环境不可逆(如机器人真实操作)、或任务变化频繁,这使得“从零开始训练”变得不可行。
典型场景包括:
- 🤖 机器人从仿真环境迁移到真实环境(Sim2Real)
- 🎮 游戏 Agent 在新地图或新规则下快速上手
- 🏭 工业控制中设备型号变化导致环境动力学发生漂移
- 🧠 大模型 Agent 在不同工具、API 或业务流程中的快速适配
这些问题的共同点是:新任务样本极少(Few-shot)但与历史任务存在结构相似性。
解决这一问题的关键思想是:
不是让 Agent 学会一个任务,而是让 Agent 学会“如何快速学会一个新任务”。
这正是 元学习(Meta-Learning) 在 Agent 快速适应中的核心价值。
二、元学习核心思想:Learning to Learn
2.1 传统学习 vs 元学习
| 维度 | 传统机器学习 | 元学习 |
|---|---|---|
| 学习目标 | 学会一个任务 | 学会快速学习新任务 |
| 数据分布 | 单一任务分布 | 多任务分布 |
| 泛化能力 | 样本内泛化 | 跨任务泛化 |
在元学习中,我们通常假设存在一个 任务分布:
目标是学习一个元参数 (\theta),使得在面对一个新任务 (\mathcal{T}_{new}) 时,仅需少量样本和少数梯度更新即可获得高性能策略。
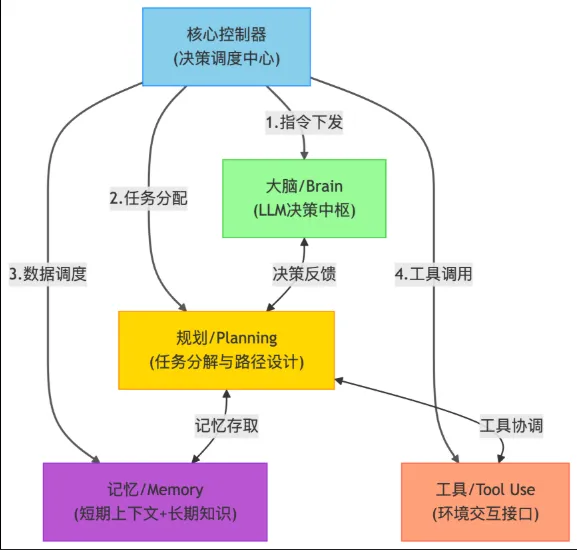
三、Agent 场景下的元学习建模
在强化学习中,引入元学习通常形成 Meta-RL 框架,其结构可以抽象为两层学习:
- 内循环(Inner Loop):Agent 在具体任务上的快速适应
- 外循环(Outer Loop):跨任务优化“初始策略”或“更新规则”
任务 T1 ┐
任务 T2 ├─> 元学习器(Outer Loop) → θ*
任务 T3 ┘ ↑
└─ Inner Loop(少量更新)
在 Agent 系统中,常见的元学习形式包括:
- 基于梯度的元学习(MAML / Reptile)
- 基于记忆的元学习(RNN / Transformer-based Agent)
- 基于策略条件化(Context-based Meta-RL)
下面我们重点讨论 MAML(Model-Agnostic Meta-Learning) 在 Agent 快速适应中的应用。
四、MAML:让 Agent 学会“如何初始化”
4.1 算法直觉
MAML 的核心思想是:
学习一组参数 (\theta),使其在任意新任务上,经过 1~K 步梯度下降 后都能取得较好性能。
4.2 MAML 在强化学习中的结构
在 RL 场景中:
- (\mathcal{L}_{\mathcal{T}_i}):策略梯度损失(如 REINFORCE / PPO)
- 内循环:少量 episode 更新策略
- 外循环:通过任务集合反向传播更新初始策略参数
五、示例代码:基于 MAML 的元强化学习 Agent(简化版)
下面给出一个 PyTorch + Gym 风格 的简化示例,用于说明元学习在 Agent 快速适应中的核心流程(示意性代码)。
⚠️ 为突出思想,代码省略了工程细节(如并行采样、PPO clip 等)。
5.1 策略网络定义
import torch
import torch.nn as nn
import torch.optim as optim
from torch.distributions import Categorical
class PolicyNet(nn.Module):
def __init__(self, obs_dim, act_dim):
super().__init__()
self.net = nn.Sequential(
nn.Linear(obs_dim, 64),
nn.ReLU(),
nn.Linear(64, act_dim)
)
def forward(self, x):
logits = self.net(x)
return Categorical(logits=logits)
5.2 单任务内循环更新(Fast Adaptation)
def inner_update(policy, trajectories, lr=0.1):
"""
单任务快速适应(Inner Loop)
"""
loss = 0
for obs, act, reward in trajectories:
dist = policy(obs)
log_prob = dist.log_prob(act)
loss -= log_prob * reward # REINFORCE
grads = torch.autograd.grad(loss, policy.parameters(), create_graph=True)
adapted_params = []
for param, grad in zip(policy.parameters(), grads):
adapted_params.append(param - lr * grad)
return adapted_params
5.3 元更新(Outer Loop)
def meta_update(meta_policy, task_batch, meta_lr=1e-3):
meta_loss = 0
for task_data in task_batch:
# 1. 使用少量样本进行快速适应
adapted_params = inner_update(meta_policy, task_data['support'])
# 2. 在 query 集上评估
loss_q = 0
for obs, act, reward in task_data['query']:
dist = meta_policy.forward_with_params(obs, adapted_params)
loss_q -= dist.log_prob(act) * reward
meta_loss += loss_q
meta_loss /= len(task_batch)
optimizer = optim.Adam(meta_policy.parameters(), lr=meta_lr)
optimizer.zero_grad()
meta_loss.backward()
optimizer.step()
直观理解:
- 内循环:模拟“Agent 在新环境中试跑几次”
- 外循环:优化一个“最容易被微调的初始策略”
六、少样本环境迁移中的关键挑战
6.1 奖励与动力学同时变化
真实场景中,任务变化往往不仅体现在奖励函数,还体现在环境动力学(Transition)。
解决思路包括:
- Latent Context Encoder(如 PEARL)
- 基于 Transformer 的历史轨迹建模
- 世界模型 + 元学习结合
6.2 稳定性与计算成本
MAML 在 RL 中面临:
- 二阶梯度带来的计算与显存开销
- 高方差策略梯度导致训练不稳定
工程实践中常用:
- First-Order MAML(FOMAML)
- Reptile
- PPO + Meta-Gradient Trick
七、与大模型 Agent 的结合趋势
随着 LLM Agent 的兴起,元学习思想正在以新的形式回归:
- Prompt 级元学习(Prompt Initialization)
- Tool 使用策略的快速迁移
- Memory-based Few-shot Adaptation
本质上,这些方法仍然遵循同一目标:
在极少交互成本下,实现对新环境、新任务、新工具的快速适应。
八、总结
本文围绕 基于元学习的 Agent 快速适应 这一主题,讨论了:
- 少样本环境迁移的现实挑战
- 元学习在 Agent 系统中的核心建模方式
- MAML 在强化学习中的基本原理与代码结构
- 工程落地时的关键问题与发展趋势
元学习并不是让模型变得更复杂,而是让学习过程本身更高效。
在 Agent 越来越走向真实世界、多任务、多环境的今天,
“学会如何学习”将比“学会某个任务”更加重要。

- 点赞
- 收藏
- 关注作者
评论(0)