为什么企业离不开元数据管理?——因为数据混乱,比加班更可怕!

为什么企业离不开元数据管理?——因为数据混乱,比加班更可怕!
作者|Echo_Wish(大数据领域自媒体老朋友)
说句实在话——在一家没有元数据管理(Data Catalog)的公司里做数据人,是一种什么体验?
就像深夜加班时饿得头晕,点外卖却发现:
菜单没有分类、菜名都是乱码、价格不明、图片全丢了。
你还得硬着头皮选一个,不然今天 KPI 就挂了。
是不是很熟悉?
这就是很多企业的数据现状:表太多、字段名神似天书、负责人不明、血缘追不到、质量全靠感觉。
于是业务问个“这个指标怎么算的?”
三个人给你五个版本,你最终挑一个最像真的。
今天,就跟大家聊聊——
为什么企业现在离不开元数据管理(Data Catalog)?
我保证,聊完你会觉得:
没有 Data Catalog 的数据平台,就是裸奔。
一、没有元数据管理,企业数据就是“盲人摸象”
1. 表多到爆炸,没有目录你根本找不到东西
许多企业的数仓长这样:
-
ODS 上千张表
-
DWD 数万张表
-
DM、ADS一堆“需求驱动型”表
-
每个业务线都各自起名,比如:
user_infot_userdwd_user_base_info_ditmp_user_info_20221204_bak
这还只是“人类能理解的那部分”。
更可怕的是没人告诉你哪个在用,哪个废了。
如果没人告诉你表的业务含义,你连用都不敢用。
2. 血缘关系不清,一个改动能炸整个链路
很多企业都靠 Excel 或人肉维护“血缘关系”。
然后某一天一个新人改了 DM 层字段名,第二天业务报表一片空白。
于是领导怒吼:
“谁动了我的指标?”
如果你有 Data Catalog,血缘就清清楚楚:
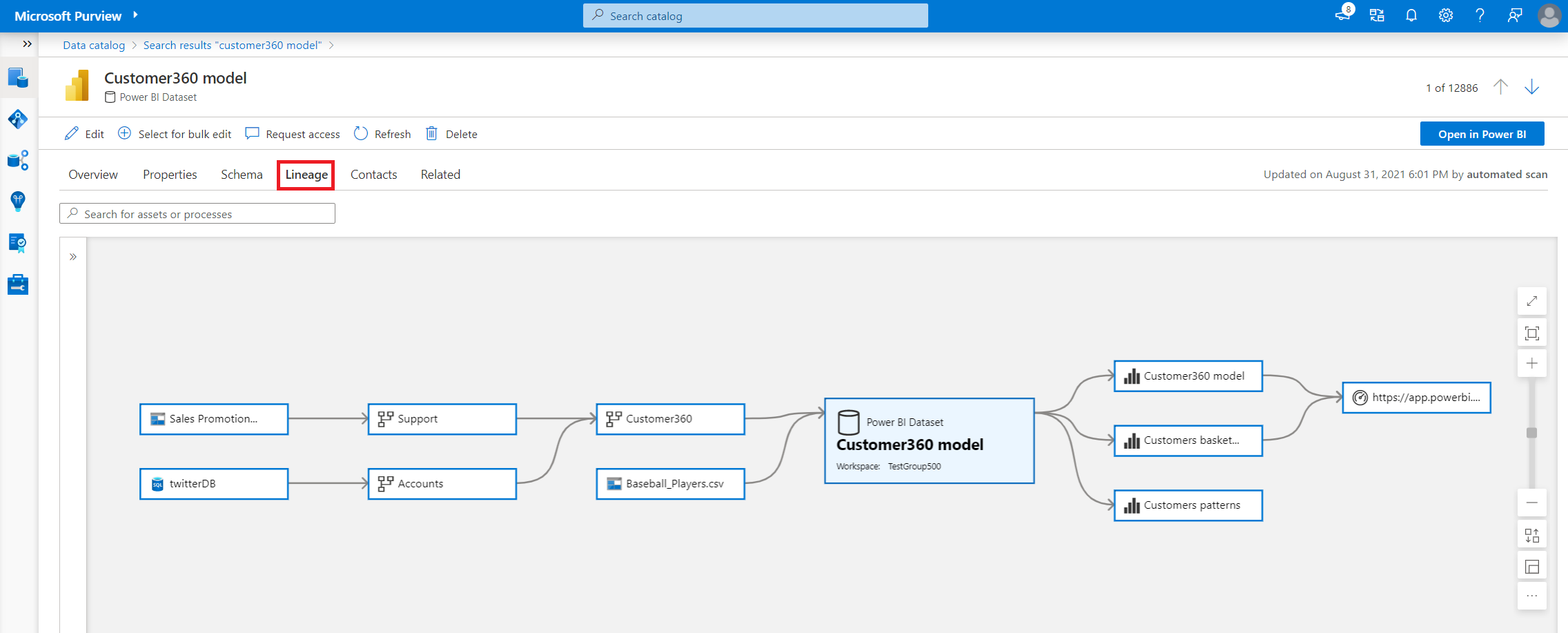

把字段一改,系统立刻告诉你:
- 会影响哪些数据集?
- 哪些报表会报错?
- 是否影响关键 KPI?
没有元数据管理?
你只能像排查电路短路一样,一个一个查。
3. 指标口径混乱,会议室里永远吵不完
“昨天 GMV 到底是多少?”
A 部门说 1000 万
B 部门说 1200 万
C 部门说 850 万
最终所有人盯着你,让你给一个“官方答案”。
但问题是:
根本没人知道哪个口径才是官方。
而 Data Catalog 可以让指标透明可追溯:
指标名称:GMV
定义:平台实际成交金额(不含虚假订单)
计算口径:sum(order.amount)
更新频率:每日
负责人:xxx
血缘:dwd_order → dws_order_summary → ads_gmv
所有人看到都是同一个“来源同一处”的指标,再也不会互相打架。
二、为什么 Data Catalog 一定要“系统化”?不是写个 Wiki 就行的吗?
很多公司喜欢用 Confluence、Excel、脑图当文档库。
但问题是:
写文档是人性中的最大弱点——没人坚持得了。
而真正的 Data Catalog 是这样的:
✔ 自动采集元数据
连接 Hive、MySQL、Kafka、对象存储……
自动抓取表结构、字段、分区、行数、更新时间等。
✔ 自动构建血缘
ETL、SQL、Spark、Flink 都能解析 lineage。
✔ 自动数据质量扫描
表是否空、字段是否异常、分区是否延迟,平台都能告诉你。
✔ 自动数据资产评分
哪些表常用?哪些表可废弃?哪些表风险高?
这和那种“靠人维护的Wiki”已经不是一个世界了。
下面给大家上一个简单示例,让你感受一下“机器自动做元数据”的好处。
三、用简单代码说明一下:什么叫“自动化血缘解析”?
比如,你的 Hive ETL SQL:
-- ads 层生成 GMV 汇总表
INSERT OVERWRITE TABLE ads_gmv
SELECT
date,
SUM(amount) AS gmv
FROM dwd_order
WHERE status = 'success'
GROUP BY date;
如果你自己做人肉血缘,你可能会写在 Excel:
ads_gmv <-- dwd_order
但 Data Catalog 会做更细致的数据血缘:
from lineage_parser import parse_sql
sql = """
INSERT OVERWRITE TABLE ads_gmv
SELECT
date,
SUM(amount) AS gmv
FROM dwd_order
WHERE status = 'success'
GROUP BY date;
"""
# 自动解析血缘
lineage = parse_sql(sql)
print(lineage)
输出可能像这样:
{
"inputs": ["dwd_order"],
"outputs": ["ads_gmv"],
"columns": {
"ads_gmv.date": "dwd_order.date",
"ads_gmv.gmv": "SUM(dwd_order.amount)"
}
}
这意味着:
- 你不用维护文档
- 你不用担心遗漏
- 你所有改动平台都会“全程跟踪”
这才叫工业级,而不是“学生作业级”。
四、Data Catalog 真正给企业带来了什么价值?
总结一句话:
让数据资产变得可找、可懂、可用、可控。
1. 数据可找:不是瞎猜,是搜索引擎级别的查找
你搜索“用户”
平台不仅告诉你字段名,还告诉你解释、负责人、使用频率、关联表。
就像你给数据装上了“百度搜索”。
2. 数据可懂:业务、技术一看就明白
每个表都有:
- 业务含义
- 字段解释
- 示例数据
- 表热度
- 下游报表列表
新人三天就能上手,而不是三个月。
3. 数据可用:质量安全全都有“体感保障”
如果表坏了,你能第一时间收到通知。
如果数据有风险,系统帮你标红。
4. 数据可控:完全掌握数据流动的全局
血缘让你知道:
- 哪些表是核心资产?
- 哪些表是废弃资产?
- 哪些表没人敢动?
数据资产管理不再是“玄学”,而是“工程化”。
五、为什么现在企业更离不开 Data Catalog?
因为:
数据规模增速远大于人类大脑容量。
过去一年一个业务线几十张表。
现在大模型场景、大数据湖架构下,一个业务线几百张、几千张表是常态。
没有 Data Catalog,你的数仓会变成“数字垃圾场”。
而有了 Data Catalog,数仓才能成为“数据生产力平台”。
六、写在最后:Data Catalog,不是锦上添花,而是“生存必需品”
很多企业一开始觉得:
“我们先做业务吧,元数据等以后再说。”
几年后:
- 业务线之间指标不统一
- 表太多根本没人敢删
- 质量问题层出不穷
- 整个数据部门天天背锅
这时候才后悔莫及。
我常说:
一个企业是否成熟,不看有没有大模型,而看有没有 Data Catalog。
元数据管理不是高级功能,也不是奢侈品——
它是数据平台的“地基”。

- 点赞
- 收藏
- 关注作者
评论(0)