RK3588部署CNN-LSTM驾驶行为识别模型【玩转华为云】

RK3588部署CNN-LSTM驾驶行为识别模型
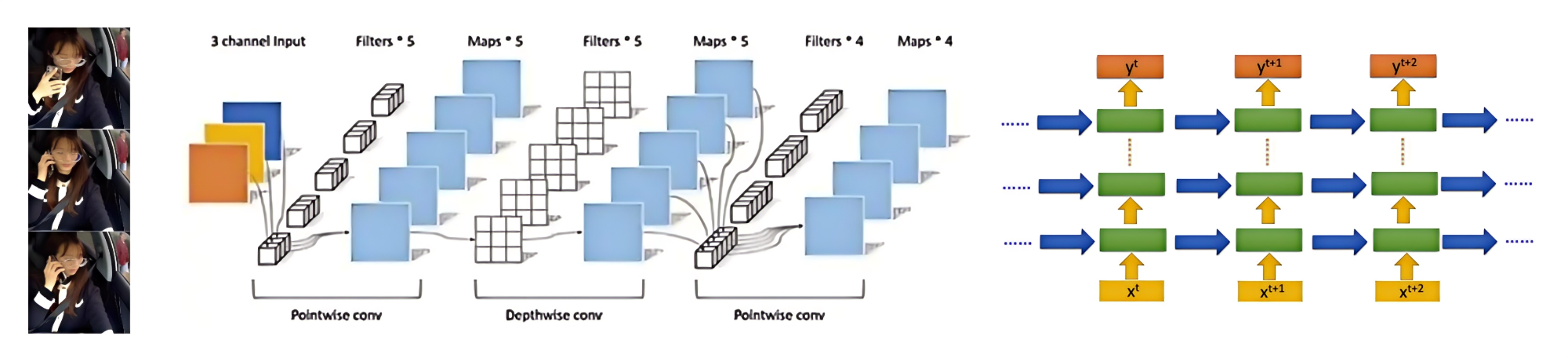
CNN(卷积神经网络)擅长提取图像的空间特征,LSTM(长短期记忆网络)则擅长处理序列数据的时间特征。首先使用CNN提取视频每一帧特征,之后将提取出的所有特征送入LSTM捕捉视频中的时空特征并对视频特征序列进行分类,实现正常驾驶、闭眼、打哈欠、打电话、左顾右盼5种驾驶行为的识别。
一. 模型训练

我们在ModelArts创建Notebook完成模型的训练,使用规格是GPU: 1*Pnt1(16GB)|CPU: 8核 64GB,镜像为tensorflow_2.1.0-cuda_10.1-py_3.7-ubuntu_18.04,首先下载数据集:
import os
import moxing as mox
if not os.path.exists('fatigue_driving'):
mox.file.copy_parallel('obs://modelbox-course/fatigue_driving', 'fatigue_driving')
if not os.path.exists('rknn_toolkit2-2.3.2-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl'):
mox.file.copy_parallel('obs://modelbox-course/rknn_toolkit2-2.3.2-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl',
'rknn_toolkit2-2.3.2-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl')
该数据集包含1525段视频,总共有5个类别:0:正常驾驶、1:闭眼、2:打哈欠、3:打电话、4:左顾右盼
我们从原视频中裁剪出主驾驶位画面,并将画面缩放到特征提取网络的输入大小:
def crop_driving_square(frame):
h, w = frame.shape[:2]
start_x = w // 2
end_x = w
start_y = 0
end_y = h
return frame[start_y:end_y, start_x:end_x]

使用在imagenet上预训练的MobileNetV2网络作为卷积基创建并保存图像特征提取器:
def get_feature_extractor():
feature_extractor = keras.applications.mobilenet_v2.MobileNetV2(
weights = 'imagenet',
include_top = False,
pooling = 'avg',
input_shape = (IMG_SIZE, IMG_SIZE, 3)
)
preprocess_input = keras.applications.mobilenet_v2.preprocess_input
inputs = keras.Input((IMG_SIZE, IMG_SIZE, 3))
preprocessed = preprocess_input(inputs)
outputs = feature_extractor(preprocessed)
model = keras.Model(inputs, outputs, name = 'feature_extractor')
return model
feature_extractor = get_feature_extractor()
feature_extractor.save('feature_extractor')
feature_extractor.summary()
Model: "feature_extractor"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 256, 256, 3)] 0
_________________________________________________________________
tf_op_layer_truediv (TensorF [(None, 256, 256, 3)] 0
_________________________________________________________________
tf_op_layer_sub (TensorFlowO [(None, 256, 256, 3)] 0
_________________________________________________________________
mobilenetv2_1.00_224 (Model) (None, 1280) 2257984
=================================================================
Total params: 2,257,984
Trainable params: 2,223,872
Non-trainable params: 34,112
设置网络的输入大小为256x256,每隔6帧截取一帧提取视频的图像特征,特征向量的大小为1280,最终得到每个视频的特征序列,序列的最大长度为40,不足用0补齐:
def load_video(file_name):
cap = cv2.VideoCapture(file_name)
frame_interval = 6
frames = []
count = 0
while True:
ret, frame = cap.read()
if not ret:
break
if count % frame_interval == 0:
frame = crop_driving_square(frame)
frame = cv2.resize(frame, (IMG_SIZE, IMG_SIZE))
frame = frame[:, :, [2, 1, 0]]
frames.append(frame)
count += 1
return np.array(frames)
def load_data(videos, labels):
video_features = []
for video in tqdm(videos):
frames = load_video(video)
counts = len(frames)
# 如果帧数小于MAX_SEQUENCE_LENGTH
if counts < MAX_SEQUENCE_LENGTH:
# 补白
diff = MAX_SEQUENCE_LENGTH - counts
# 创建全0的numpy数组
padding = np.zeros((diff, IMG_SIZE, IMG_SIZE, 3))
# 数组拼接
frames = np.concatenate((frames, padding))
# 获取前MAX_SEQUENCE_LENGTH帧画面
frames = frames[:MAX_SEQUENCE_LENGTH, :]
# 批量提取图像特征
video_feature = feature_extractor.predict(frames)
video_features.append(video_feature)
return np.array(video_features), np.array(labels)
video_features, classes = load_data(videos, labels)
video_features.shape, classes.shape
((1525, 40, 1280), (1525,))
总共提取了1525个视频的特征序列,按照8:2的比例划分训练集和测试集(batchsize的大小设为16):
batch_size = 16
dataset = tf.data.Dataset.from_tensor_slices((video_features, classes))
dataset = dataset.shuffle(len(videos))
test_count = int(len(videos) * 0.2)
train_count = len(videos) - test_count
dataset_train = dataset.skip(test_count).cache().repeat()
dataset_test = dataset.take(test_count).cache().repeat()
train_dataset = dataset_train.shuffle(train_count).batch(batch_size)
test_dataset = dataset_test.shuffle(test_count).batch(batch_size)
train_dataset, train_count, test_dataset, test_count
(<BatchDataset shapes: ((None, 40, 1280), (None,)), types: (tf.float32, tf.int64)>,
1220,
<BatchDataset shapes: ((None, 40, 1280), (None,)), types: (tf.float32, tf.int64)>,
305)
之后创建LSTM提取视频特征序列的时间信息送入Dense分类器,模型的定义如下:
def video_cls_model(class_vocab):
# 类别数量
classes_num = len(class_vocab)
# 定义模型
model = keras.Sequential([
layers.Input(shape=(MAX_SEQUENCE_LENGTH, NUM_FEATURES)),
layers.LSTM(64, return_sequences=True),
layers.Flatten(),
layers.Dense(classes_num, activation='softmax')
])
# 编译模型
model.compile(optimizer = keras.optimizers.Adam(1e-5),
loss = keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics = ['accuracy']
)
return model
# 模型实例化
model = video_cls_model([0, 1])
# 保存检查点
checkpoint = ModelCheckpoint(filepath='best.h5', monitor='val_loss', save_weights_only=True, save_best_only=True, verbose=1, mode='min')
# 提前终止
earlyStopping = EarlyStopping(monitor='val_loss', patience=50, mode='min', baseline=None)
# 减少learning rate
rlp = ReduceLROnPlateau(monitor='val_loss', factor=0.7, patience=30, min_lr=1e-15, mode='min', verbose=1)
# 模型结构
model.summary()
网络的输入大小为(N, 40, 1280),使用softmax进行激活,输出5个类别的概率:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm (LSTM) (None, 40, 64) 344320
_________________________________________________________________
flatten (Flatten) (None, 2560) 0
_________________________________________________________________
dense (Dense) (None, 5) 12805
=================================================================
Total params: 357,125
Trainable params: 357,125
Non-trainable params: 0
_________________________________________________________________
实验表明模型训练300个Epoch基本收敛:
history = model.fit(train_dataset,
epochs = 300,
steps_per_epoch = train_count // batch_size,
validation_steps = test_count // batch_size,
validation_data = test_dataset,
callbacks=[checkpoint])
plt.plot(history.epoch, history.history['loss'], 'r', label='loss')
plt.plot(history.epoch, history.history['val_loss'], 'g--', label='val_loss')
plt.title('LSTM')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.plot(history.epoch, history.history['accuracy'], 'r', label='acc')
plt.plot(history.epoch, history.history['val_accuracy'], 'g--', label='val_acc')
plt.title('LSTM')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
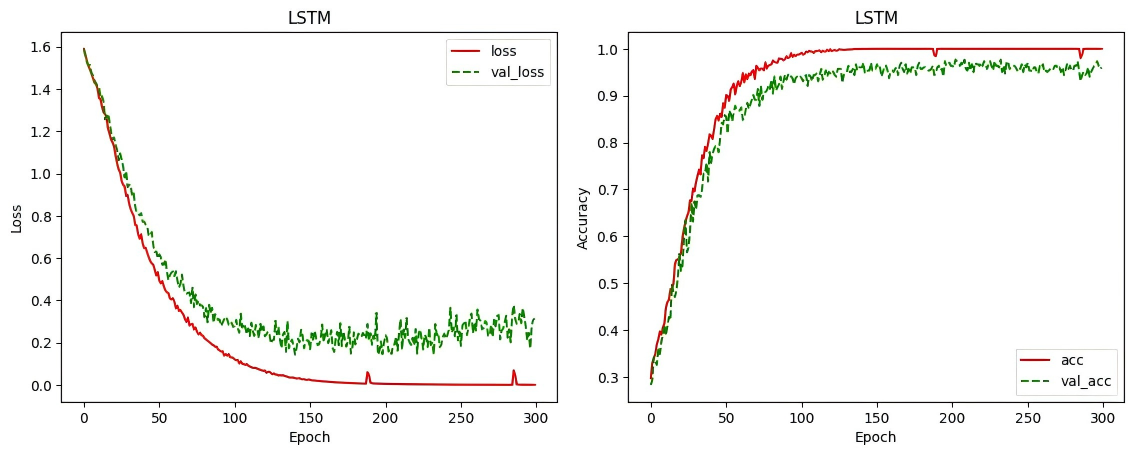
加载模型最优权重,模型在测试集上的分类准确率为95.8%,保存为saved_model格式:
model.load_weights('best.h5')
model.evaluate(dataset.batch(batch_size))
model.save('saved_model')
96/96 [==============================] - 0s 5ms/step - loss: 0.2169 - accuracy: 0.9580
[0.21687692414949802, 0.9580328]
二、模型转换
首先将图像特征提取器feature_extractor转为tflite格式,并开启模型量化:
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model('feature_extractor')
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS, tf.lite.OpsSet.SELECT_TF_OPS]
converter.post_training_quantize = True # 模型量化
tflite_model = converter.convert()
with open('mbv2.tflite', 'wb') as f:
f.write(tflite_model)
再将视频序列分类模型转为onnx格式,由于lstm参数量较少,不需要进行量化:
python -m tf2onnx.convert --saved-model saved_model --output lstm.onnx --opset 12
最后导出RKNN格式的模型,可根据需要设置target_platform为rk3568/rk3588:
from rknn.api import RKNN
rknn = RKNN(verbose=False)
rknn.config(target_platform="rk3588")
rknn.load_tflite(model="mbv2.tflite")
rknn.build(do_quantization=False)
rknn.export_rknn('mbv2.rknn')
rknn.release()
rknn = RKNN(verbose=False)
rknn.config(target_platform="rk3588")
rknn.load_onnx(
model="lstm.onnx",
inputs=['input_3'], # 输入节点名称
input_size_list=[[1, 40, 1280]] # 固定输入尺寸
)
rknn.build(do_quantization=False)
rknn.export_rknn('lstm.rknn')
rknn.release()
三、模型部署
我们在RK3588上部署MobileNetV2和LSTM模型,以下是板侧的推理代码:
import os
import cv2
import glob
import shutil
import imageio
import numpy as np
from IPython.display import Image
from rknnlite.api import RKNNLite
MAX_SEQUENCE_LENGTH = 40
IMG_SIZE = 256
NUM_FEATURES = 1280
def crop_driving_square(img):
h, w = img.shape[:2]
start_x = w // 2
end_x = w
start_y = 0
end_y = h
result = img[start_y:end_y, start_x:end_x]
return result
def load_video(file_name):
cap = cv2.VideoCapture(file_name)
# 每隔多少帧抽取一次
frame_interval = 6
frames = []
count = 0
while True:
ret, frame = cap.read()
if not ret:
break
# 每隔frame_interval帧保存一次
if count % frame_interval == 0:
# 中心裁剪
frame = crop_driving_square(frame)
# 缩放
frame = cv2.resize(frame, (IMG_SIZE, IMG_SIZE))
# BGR -> RGB [0,1,2] -> [2,1,0]
frame = frame[:, :, [2, 1, 0]]
frames.append(frame)
count += 1
cap.release()
return np.array(frames).astype(np.uint8)
# 获取视频特征序列
def getVideoFeat(frames):
frames_count = len(frames)
# 如果帧数小于MAX_SEQUENCE_LENGTH
if frames_count < MAX_SEQUENCE_LENGTH:
# 补白
diff = MAX_SEQUENCE_LENGTH - frames_count
# 创建全0的numpy数组
padding = np.zeros((diff, IMG_SIZE, IMG_SIZE, 3))
# 数组拼接
frames = np.concatenate((frames, padding))
# 取前MAX_SEQ_LENGTH帧
frames = frames[:MAX_SEQUENCE_LENGTH,:]
frames = frames.astype(np.float32)
# 提取视频每一帧特征
feats = []
for frame in frames:
frame = np.expand_dims(frame, axis=0)
result = rknn_lite_mbv2.inference(inputs=[frame])
feats.append(result[0])
return feats
rknn_lite_mbv2 = RKNNLite()
rknn_lite_lstm = RKNNLite()
rknn_lite_mbv2.load_rknn('model/mbv2.rknn')
rknn_lite_lstm.load_rknn('model/lstm.rknn')
rknn_lite_mbv2.init_runtime(core_mask=RKNNLite.NPU_CORE_0_1_2)
rknn_lite_lstm.init_runtime(core_mask=RKNNLite.NPU_CORE_0_1_2)
files = glob.glob("video/*.mp4")
for video_path in files:
label_to_name = {0:'正常驾驶', 1:'闭眼', 2:'打哈欠', 3:'打电话', 4:'左顾右盼'}
frames = load_video(video_path)
frames = frames[:MAX_SEQUENCE_LENGTH]
imageio.mimsave('test.gif', frames, durations=10, loop=0)
display(Image(open('test.gif', 'rb').read()))
feats = getVideoFeat(frames)
feats = np.concatenate(feats, axis=0)
feats = np.expand_dims(feats, axis=0)
preds = rknn_lite_lstm.inference(inputs=[feats])[0][0]
for i in np.argsort(preds)[::-1][:5]:
print('{}: {}%'.format(label_to_name[i], round(preds[i]*100, 2)))
rknn_lite_mbv2.release()
rknn_lite_lstm.release()
最终的视频识别效果如下:🚀
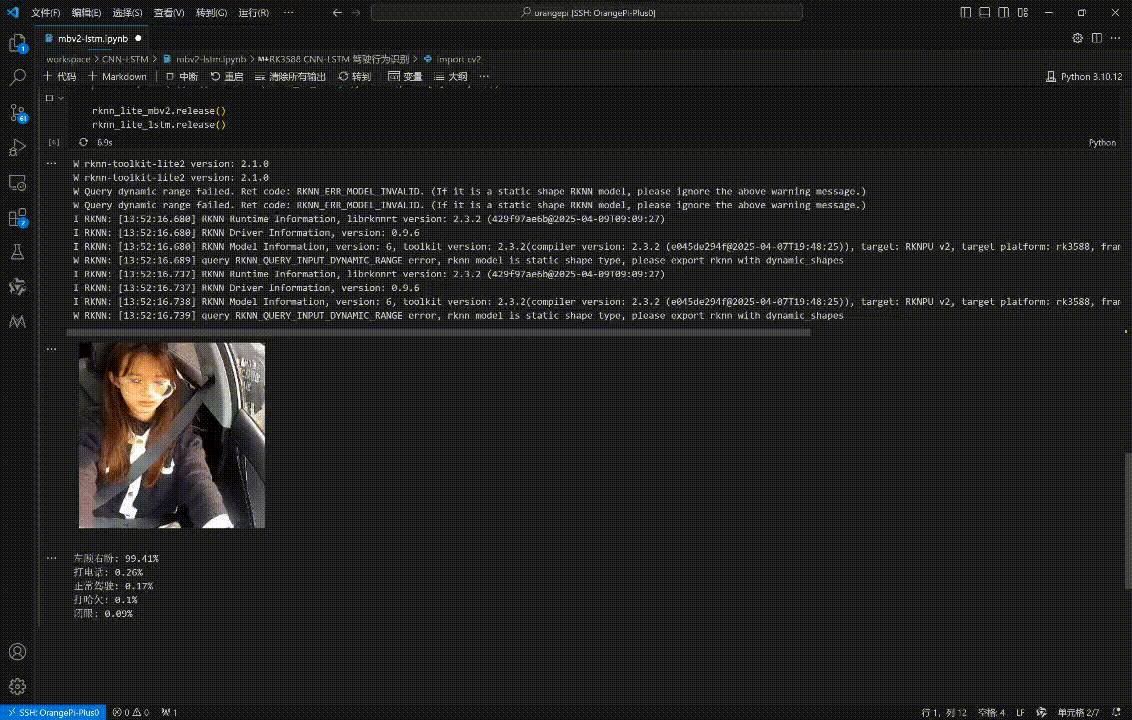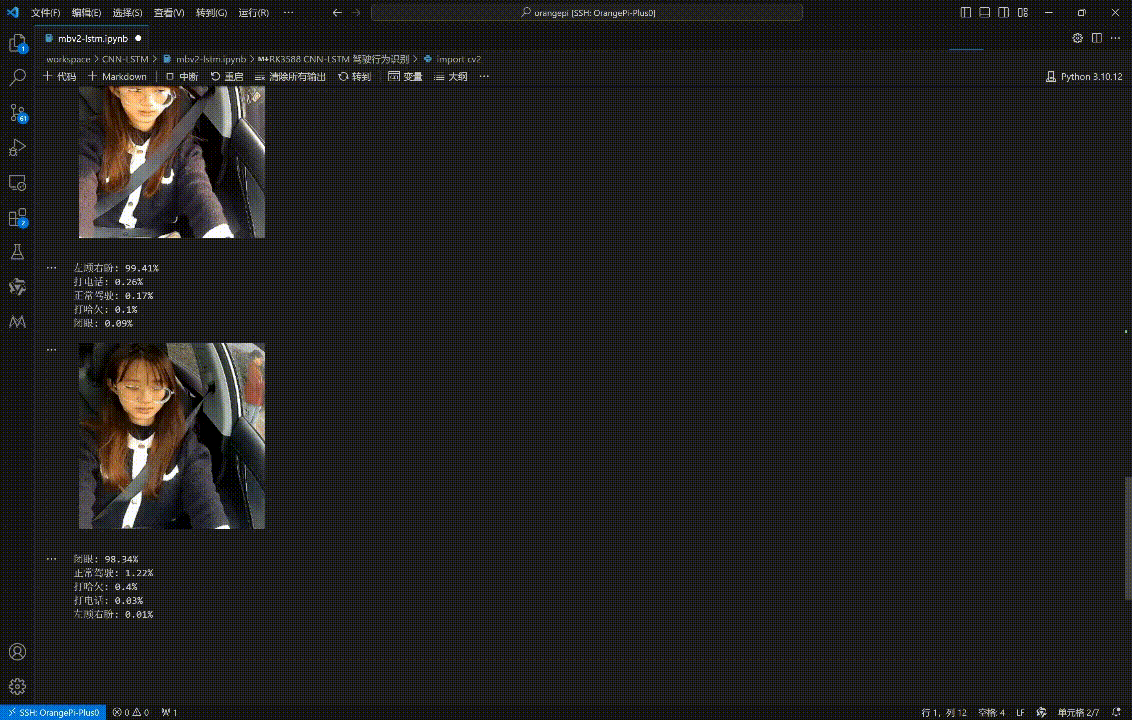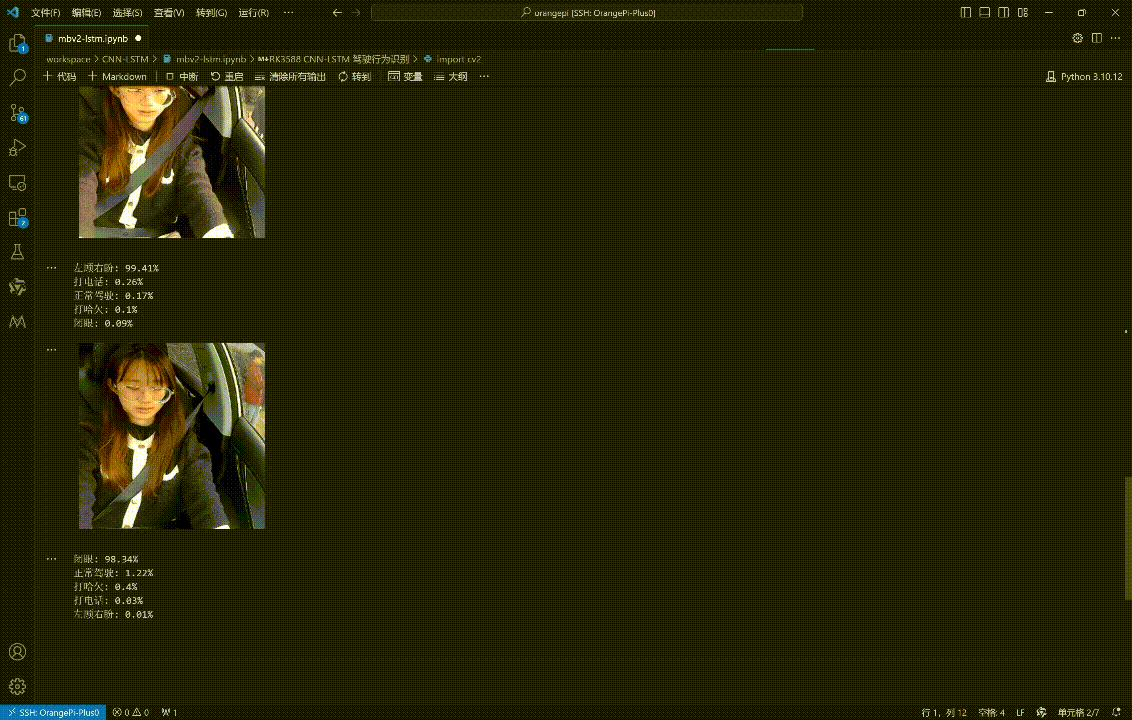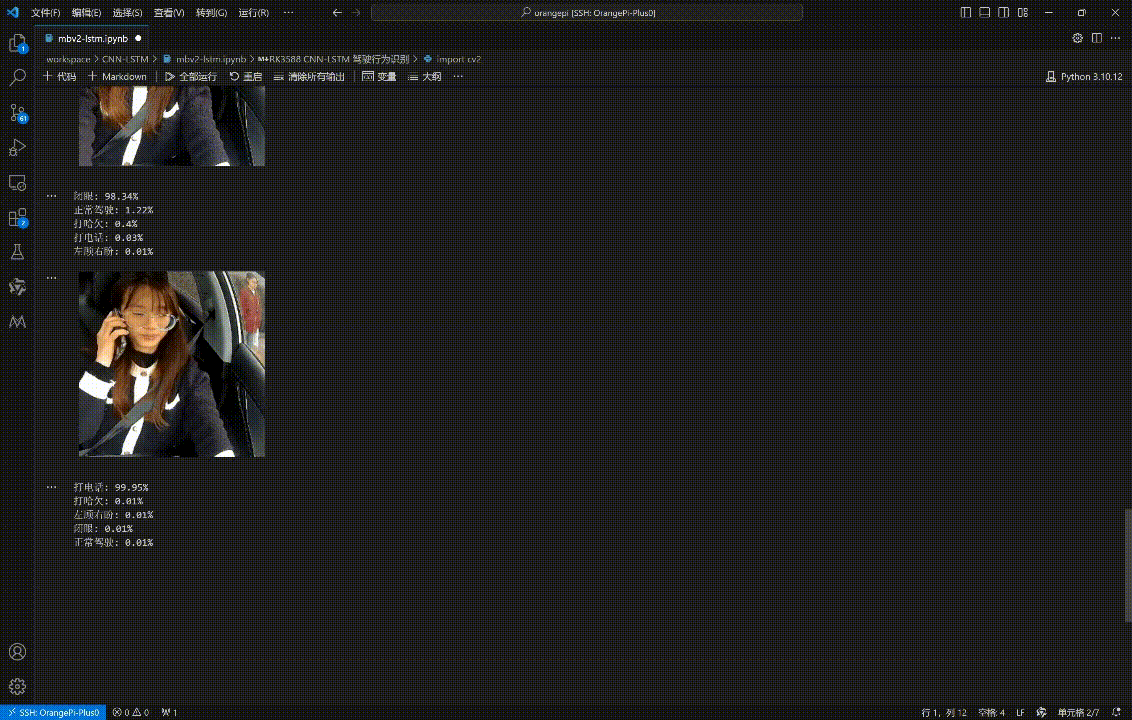
四、本文小结
本文详细阐述了基于RK3588平台的CNN-LSTM驾驶行为识别模型全流程,利用MobileNetV2提取图像的空间特征、LSTM处理视频的时序特征完成对正常驾驶、闭眼、打哈欠、打电话和左顾右盼5类驾驶行为的精准识别,在ModelArts上训练达到95.8%分类准确率,并分别将mbv2.tflite和lstm.onnx转换为RKNN格式实现板侧的高效推理部署。

- 点赞
- 收藏
- 关注作者
评论(0)