深入解析华为昇腾CANN的静态Tensor算子编程

深入解析华为昇腾CANN的静态Tensor算子编程
随着AI计算需求的爆炸式增长,算子性能优化成为神经网络推理和训练中的关键环节。华为昇腾(Ascend)平台的CANN(Compute Architecture for Neural Networks)为开发者提供了丰富的算子开发框架,其中静态Tensor编程范式因其低运行时开销和灵活性而备受关注。本文将深入解析静态Tensor编程的设计理念、内存管理策略、同步控制机制及流水优化方法,帮助开发者掌握在Ascend C环境下实现高性能算子的关键技术。
一、静态Tensor编程的设计理念
在传统的Pipe(TPipe类)编程范式下,开发者通过框架管理Device端内存、DoubleBuffer流水和同步事件,能够快速构建算子,但会带来一定的运行时开销,例如TPipe创建和InitBuffer操作通常消耗数百纳秒。
静态Tensor编程范式的出现,正是为了解决这一问题。通过直接构造指定地址和存储位置的LocalTensor,开发者可以完全掌控内存分配和计算流程,从而显著降低运行时开销。这种方式适合追求极致性能的场景,但也对开发者提出了更高的要求:需要手动管理DoubleBuffer、同步流水,并仅能使用Ascend C提供的基础API。
简单来说,静态Tensor编程追求的是“以最小开销实现最优性能”的编程哲学。
二、AI Core架构与编程范式映射
Ascend AI Core是CANN算子执行的核心单元,其硬件架构包括多条计算流水和多种内存单元:
- 内存单元:Unified Buffer用于矢量计算,L1/L0A/B/C Buffer用于矩阵计算。
- 计算流水:Vector、Cube、Scalar计算流水,以及MTE1、MTE2、MTE3数据搬运流水。
在静态Tensor编程方式下,开发者需要自主管理这些硬件资源,通过调用搬运和计算API完成算子实现。每条流水间的数据依赖关系必须通过手动插入同步事件来维护,以保证计算的正确性和性能最优。
例如,对于一个典型矢量算子,开发者会先对数据进行分块,然后根据数据依赖插入同步事件,确保数据搬入、计算和搬出顺序正确。
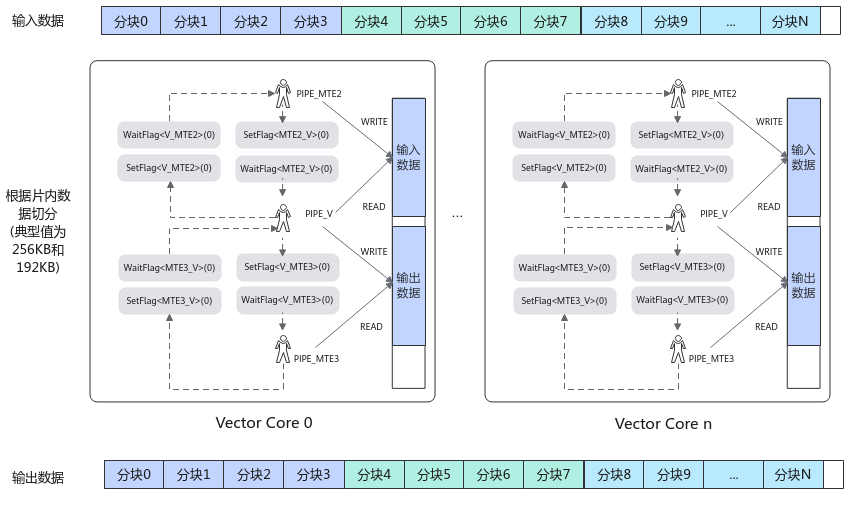
三、内存管理策略
静态Tensor编程下,内存管理主要有两种方式:
-
LocalMemAllocator分配
通过线性分配器在硬件位置分配Tensor,简化算子开发。示例:AscendC::LocalMemAllocator<AscendC::Hardware::UB> ubAllocator; AscendC::LocalTensor<float> xLocal = ubAllocator.Alloc<AscendC::TPosition::VECCALC, float, TILE_LENGTH>(); -
LocalTensor直接构造
高性能场景推荐直接指定内存地址,实现完全自主管理,支持内存复用和Bank冲突优化:AscendC::LocalTensor<float> xLocal(AscendC::TPosition::VECCALC, xAddr, TILE_LENGTH);
这种方式下,开发者无需申请和释放内存,但必须确保地址在物理存储上限内,并根据需求复用内存以优化性能。
四、同步控制机制
在AI Core内部,多条流水异步并行执行时,数据依赖必须通过同步事件保障计算正确性。静态Tensor编程中常用的同步事件有:
-
正向同步(循环内依赖)
例如MTE2搬运流水等待Vector计算流水完成,确保数据搬入后再进行计算。 -
反向同步(循环间依赖)
确保上一次循环的数据搬出或计算完成后,本次循环再开始,防止数据覆盖。
核心API包括:
AscendC::SetFlag<AscendC::HardEvent::MTE2_V>(EVENT_ID0);
AscendC::WaitFlag<AscendC::HardEvent::MTE2_V>(EVENT_ID0);
需要注意的是,事件ID 6和7不可使用,以避免与硬件内部事件冲突。此外,由于同步接口依赖ISASI硬件体系结构,算子可能无法跨硬件版本兼容。
五、流水优化与DoubleBuffer
在基于TPipe的编程中,DoubleBuffer可自动开启以提高Vector流水的时间利用率。静态Tensor编程下,开发者需手动实现DoubleBuffer:
// Ping-pong双缓冲
AscendC::LocalTensor<float> xPing(...), xPong(...);
for (int i = 0; i < loopCount; i++) {
auto &xLocal = (i % 2 == 0 ? xPing : xPong);
AscendC::WaitFlag<AscendC::HardEvent::MTE3_MTE2>(eventID);
AscendC::DataCopy(xLocal, xGm[i * TILE_LENGTH], TILE_LENGTH);
...
}
使用DoubleBuffer可以有效减少等待时间,提升算子整体性能。
六、使用约束与支持API
静态Tensor编程方式有以下限制:
- 禁止使用TPipe/TQue等高层框架接口,避免未定义行为。
- 仅能使用Ascend C提供的基础API。
- 同步事件需手动管理。
- Kernel入口需调用
InitSocState初始化全局状态寄存器。
支持的API范围包括标量计算、矢量计算、矩阵计算、数据搬运、内存管理、同步控制和原子操作等,详见官方文档表格。
七、总结
静态Tensor编程范式提供了对AI Core硬件资源的最大掌控,使得开发者可以在牺牲易用性的前提下追求极致性能。它不仅要求开发者熟悉内存分配、流水同步和DoubleBuffer管理,更需要深刻理解硬件流水和数据依赖关系。
对于追求算子性能优化、对低延迟和高吞吐有极高要求的场景,静态Tensor编程无疑是Ascend CANN开发的利器。而在日常开发中,可以先使用TPipe框架快速验证算子逻辑,再在性能关键路径切换到静态Tensor编程方式,实现高性能算子落地。


- 点赞
- 收藏
- 关注作者
评论(0)