深入解析华为昇腾 CANN 算子开发与抽象硬件架构

深入解析华为昇腾 CANN 算子开发与抽象硬件架构
随着人工智能计算需求的快速增长,硬件与软件的高效协同成为提升AI性能的关键。华为昇腾AI处理器(Ascend AI Processor)通过CANN(Compute Architecture for Neural Networks)框架,为开发者提供了高性能、可扩展的算子开发能力。在本文中,我们将深入解析昇腾AI Core的抽象硬件架构,并探讨算子开发中如何利用这些硬件特性实现高效计算。
一、华为昇腾AI Core概览
昇腾AI处理器内部由多个AI Core组成,每个AI Core都是一个独立的计算单元,集成了计算、存储和数据搬运功能。开发者在CANN框架下编程时,无需关心不同型号或硬件细节,通过硬件抽象层即可高效利用AI Core的计算能力。
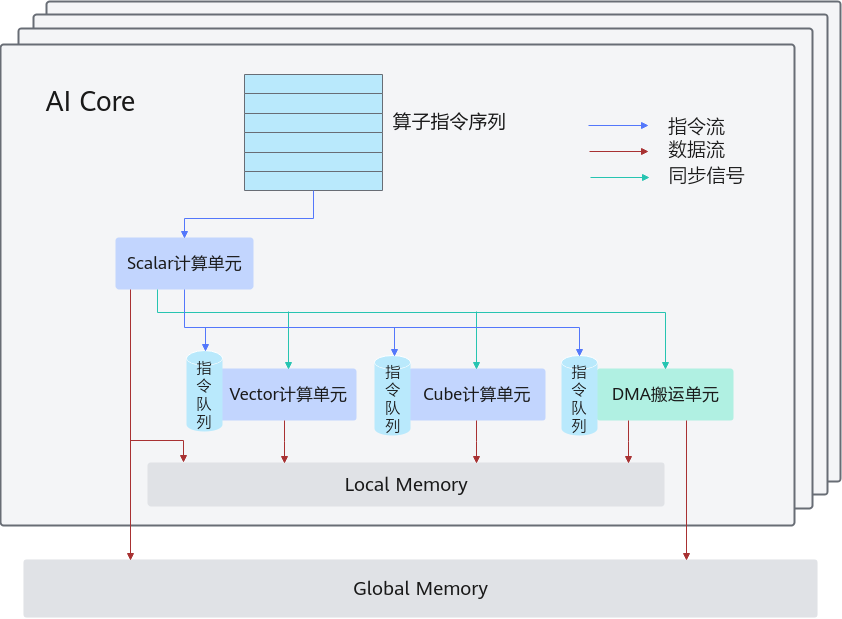
1.1 AI Core的核心组件
AI Core的内部架构可以抽象为三个核心模块:计算单元、存储单元和搬运单元。
-
计算单元(Compute Units)
计算单元负责执行各种数值运算,主要分为三类:- Scalar单元:处理标量计算,包括地址计算和循环控制,并向向量或矩阵单元发射计算指令。
- Vector单元:专注向量运算,适合深度学习中的张量处理。
- Cube单元:执行矩阵运算,是大规模矩阵乘法和卷积运算的核心。
-
存储单元(Memory Units)
存储单元负责数据的本地存储和管理:- Local Memory:AI Core的高速内部存储,用于缓存计算中间结果,对应LocalTensor数据类型。
- Global Memory:外部存储,可供AI Core访问,对应GlobalTensor数据类型,用于存储模型参数或输入输出数据。
-
搬运单元(DMA)
DMA(Direct Memory Access)负责数据搬运,支持:- Global Memory ↔ Local Memory的数据传输
- Local Memory不同层级之间的数据搬运
这些组件的有机协作,使AI Core能够在保证数据一致性的前提下,实现高效的异步并行计算。
二、AI Core的异步计算与指令流
理解AI Core的计算流程,对于开发高性能算子至关重要。AI Core内部的计算可以抽象为三条关键流:异步指令流、同步信号流和计算数据流。
2.1 异步指令流
Scalar单元从指令序列中解析控制逻辑,并将向量计算、矩阵计算以及数据搬运的指令异步发射给对应单元执行。这种设计允许Vector和Cube单元并行处理不同任务,大幅提高计算吞吐量。
2.2 同步信号流
尽管指令是异步执行的,但不同单元之间可能存在依赖关系。Scalar单元会下发同步指令,确保各个计算单元和搬运单元按照正确顺序执行操作,从而保证数据一致性和结果正确性。
2.3 数据流
AI Core内部的数据流同样遵循DMA搬运逻辑:
- DMA搬入:将数据从Global Memory搬入Local Memory。
- 计算单元处理:Vector/Cube单元在Local Memory中完成计算。
- DMA搬出:将结果写回Global Memory,供后续处理或外部访问。
这种数据流设计有效地减少了内存访问延迟,提高了算子计算效率。
三、CANN算子开发的核心要点
在了解了AI Core的硬件抽象后,开发高效算子需要关注以下几个方面:
3.1 充分利用Local Memory
算子开发应尽量在Local Memory中完成计算,减少对Global Memory的访问次数。LocalTensor的数据布局优化与缓存策略直接影响算子的性能。
3.2 异步指令调度
开发者可以利用Scalar单元的指令发射机制,实现向量和矩阵计算的异步调度,通过合理安排指令队列,提高计算资源利用率。
3.3 DMA搬运优化
数据搬运通常是性能瓶颈。通过双缓冲、流水线搬运和数据对齐优化,可以在计算过程中并行搬运数据,从而隐藏内存访问延迟。
3.4 并行计算策略
根据Tensor维度和计算量,合理划分Vector和Cube单元任务,充分发挥AI Core的并行计算能力,是高性能算子设计的核心。
四、总结与实践建议
昇腾AI Core通过计算、存储和搬运单元的高效协作,为算子开发提供了强大硬件支持。理解AI Core的异步指令流、同步信号流和数据流,是开发高性能算子的前提。实际开发中,算子优化不仅要关注计算逻辑,还需结合硬件特性进行存储布局、指令调度和DMA搬运优化。
未来,随着CANN框架和昇腾AI处理器的持续迭代,算子开发将更加高效灵活,为深度学习模型的训练和推理提供强大算力保障。


- 点赞
- 收藏
- 关注作者
评论(0)