昇腾CANN算子-基于 TBE DSL 的自定义算子开发全流程解析

CANN算子-基于 TBE DSL 的自定义算子开发全流程解析(训练营深度实践篇)
在昇腾生态不断扩大、多样化 AI 工作负载日益增长的今天,如何高效、安全、可控地构建自定义算子成为许多开发者的核心诉求。华为 CANN(Compute Architecture for Neural Networks)提供的 TBE(Tensor Boost Engine)算子开发框架,不仅包含传统 Schedule 写法,还提供了一套更易用、更工程化的 DSL(Domain-Specific Language)开发模式,将算子开发复杂度大幅降低。
本文将从 DSL 框架原理、Auto Schedule 调度机制,到完整的算子开发流程与示例,系统解析一个 TBE DSL 自定义算子从“计算逻辑描述”到“可编译运行”的实现全链路。
1. 为什么要使用 TBE DSL?
传统算子开发通常需要编写大量调度(Schedule)细节,包括:
- 数据在各级存储中的布局
- 计算指令顺序
- Tile 划分逻辑
- Pipeline、Double Buffer 等性能优化策略
这些内容对于入门者来说门槛较高,也容易写错。TBE DSL 的目标是——
让开发者专注于算子的数学逻辑,由系统自动完成调度与底层优化。
使用 DSL,你只需描述“我要算什么”,而不需要关心“怎么在昇腾硬件上算得最快”。
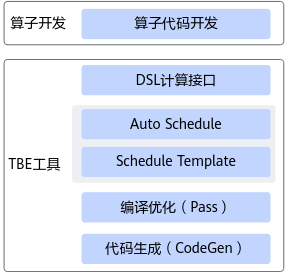
2. TBE DSL 框架:从表达计算到生成可执行算子
TBE DSL 的整体流程如图所示(文字版):
计算描述(DSL API)
↓
Auto Schedule(自动调度)
↓
IR(中间表示)
↓
Pass 优化(指令映射、流水线、双缓冲等)
↓
CodeGen(生成 C-like 临时代码)
↓
编译器 → 生成可执行算子(.o + json)
它的核心理念是:
- 开发者使用 DSL API 组装计算表达式
- TBE 自动识别 pattern(elewise / reduce / conv 等)
- Auto Schedule 选择合适的调度模板
- Pass 层进行智能优化
- 最终生成可被模型直接调用的算子文件
因此,DSL 不是一个函数库,而是一套完整的算子构建语言。
3. DSL 核心能力:覆盖 AI 算子的主流计算模式
TBE DSL 提供多类计算接口,包括但不限于:
- Element-wise(加减乘除、指数、倒数…)
- Reduce(sum / max / mean 等)
- NN 类、卷积、深度卷积
- 矩阵运算(matmul、转置)
- Broadcast 操作
- Segment、concat 等结构性算子
其语义与 TVM 保持一致,因此对于有 TVM/TensorIR 经验的开发者来说几乎没有学习成本。
4. Auto Schedule:昇腾算子性能优化的关键机制
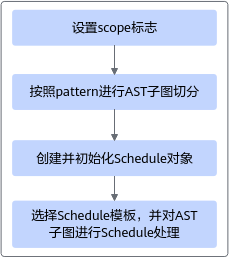
算子描述写完之后,下一步就是如何让它在昇腾芯片上跑得快。DSL 通过 tbe.dsl.auto_schedule() 将所有底层调度逻辑自动化。
Auto Schedule 的核心步骤包括:
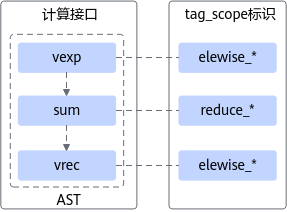
4.1 计算 AST 标注与模式识别
开发者描述的每个 compute 节点在编译阶段会被自动附加 tag_scope,用于标识其计算类别。
例如:
with tvm.tag_scope("elewise"):
out = tvm.compute(...)
这些标签帮助系统识别算子的结构模式,以便后续进行 AST 切分。
4.2 AST 子图切分
TBE 会根据 pattern 规则对计算图切块,例如:
| Pattern | 是否可融合 |
|---|---|
| elewise | 可与 elewise 融合 |
| reduce | 不能再与 elewise/conv 混合 |
| conv | 单独分块 |
| concat / segment | 需要独立子图 |
切分后的每个子图会单独调度。
4.3 为每类子图选择调度模板
如:
- elewise 模板:向量化、流水线、Cache 优化
- reduce 模板:多模态分块、流水线多阶段 reduce
- conv 模板:Cube 单元映射优化
- matmul 模板:Tilng + Fragment mapping
开发者不需要关注模板本身,只需调用 auto_schedule,即可获得高性能执行方案。
5. 完整开发流程示例:自定义 Add 算子
下面以内置 Add 的 DSL 版本为例,演示如何从零开发一个算子。
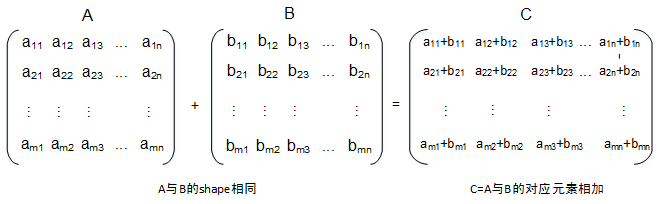
5.1 功能分析
Add 算子数学表达式:
[y = x_1 + x_2]
特性要求:
- 支持 float16 / float32 / int32
- 支持不同 shape 输入 → 需要 broadcast
- 输出 shape = broadcast 后的 shape
- 支持 ND / NCHW / NHWC / NC1HWC0 等格式
5.2 计算逻辑实现(Compute 函数)
@tbe.common.register.register_op_compute("add", op_mode="static")
def add_compute(input_x, input_y, output_z, kernel_name="add"):
shape_x = shape_util.shape_to_list(input_x.shape)
shape_y = shape_util.shape_to_list(input_y.shape)
# 广播 shape
shape_x, shape_y, shape_max = shape_util.broadcast_shapes(
shape_x, shape_y,
param_name_input1="input_x",
param_name_input2="input_y"
)
input_x = dsl.broadcast(input_x, shape_max)
input_y = dsl.broadcast(input_y, shape_max)
# 关键计算:向量加法
res = dsl.vadd(input_x, input_y)
return res
这里体现 DSL 的特点:
- 开发者只关注数学逻辑
- vadd 会被自动识别为
elewise - 调度与优化完全交给 Auto Schedule
5.3 算子定义函数(调度 + 构建)
def add(input_x, input_y, output_z, kernel_name="add"):
dtype = input_x.get("dtype").lower()
para_check.check_dtype(dtype, ("float16", "float32", "int32"))
shape_x, shape_y, shape_max = shape_util.broadcast_shapes(
input_x["shape"], input_y["shape"],
)
# placeholder
data_x = tvm.placeholder(shape_x, dtype=dtype, name="data_1")
data_y = tvm.placeholder(shape_y, dtype=dtype, name="data_2")
res = add_compute(data_x, data_y, output_z, kernel_name)
with tvm.target.cce():
schedule = dsl.auto_schedule(res)
config = {
"name": kernel_name,
"tensor_list": (data_x, data_y, res),
}
dsl.build(schedule, config)
此函数是算子“可编译”的关键:
- auto_schedule → 自动调度
- dsl.build → 生成临时代码、编译为
.o和.json
5.4 验证编译
在文件末尾添加 main:
if __name__ == "__main__":
io_desc = {
"shape": (4, 8),
"dtype": "float16",
"format": "ND",
"ori_shape": (4, 8),
"ori_format": "ND",
}
add(io_desc, io_desc, io_desc, kernel_name="add")
执行:
python3 add.py
如果运行成功,将生成:
kernel_meta/add.o
kernel_meta/add.json
至此,一个完整的 DSL 自定义算子开发完成。
6. DSL 开发的优势与局限
优势
| 优点 | 说明 |
|---|---|
| 开发简单 | 无需关心调度,只描述数学逻辑 |
| 易维护 | 算子复杂度降低,代码简洁 |
| 自动优化 | 自动完成指令映射、流水线等 |
| 高性能 | 由昇腾官方模板调度,性能更稳 |
局限
- Auto Schedule 对特殊结构的算子可能不够精细
- 当算子有强算子级性能诉求时,可能仍需手写 Schedule
- 某些高级算子类型 DSL 还不完全覆盖
不过对于大多数 AI 算子,DSL 足够强大。
7. 总结
华为 CANN 的 TBE DSL 提供了一种高度工程化的算子开发方式:
- 描述式计算逻辑
- 智能化自动调度
- 完整的 IR → Pass → CodeGen 流水线
- 极低的入门门槛
- 可稳定生成高性能算子
对于希望快速扩展算子能力的开发者来说,DSL 既能降低开发复杂度,也能确保算子在昇腾硬件上获得高效执行。

- 点赞
- 收藏
- 关注作者
评论(0)