Agent 模型部署优化:TensorRT 与 ONNX Runtime 的推理加速实践

Agent 模型部署优化:TensorRT 与 ONNX Runtime 的推理加速实践
一、引言
随着 Agent 智能体在自动驾驶、语音交互、机器人等领域的落地,一项关键挑战是 如何让模型在实际部署中具备高效、低延迟的推理性能。仅有训练精度高的模型还不够,推理框架的选择与优化策略,对性能影响巨大。
本篇文章从工程实践出发,对 TensorRT 与 ONNX Runtime (ORT) 的推理加速能力进行对比,并给出完整部署示例。
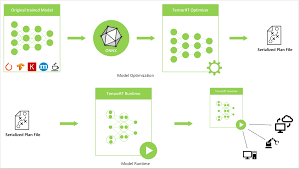
二、模型推理优化的关键指标
模型在 Agent 中的部署一般需要考虑:
| 指标 | 含义 |
|---|---|
| 延迟 (Latency) | 单次推理耗时,决定实时响应能力 |
| 吞吐量 (Throughput) | 并发处理能力 |
| 显存占用 | 决定可部署设备规模 |
| 易用性 | 对工程快速交付很重要 |
在推理场景中,我们通常会采用 量化、算子融合、显卡加速、批处理优化 等策略。
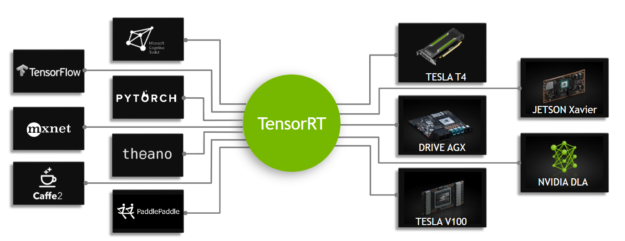
三、推理加速框架选择:TensorRT vs ONNX Runtime
| 特性 | TensorRT | ONNX Runtime |
|---|---|---|
| 最优加速能力 | 强 (NVIDIA GPU 最佳选择) | 中强 (多平台适配) |
| 硬件支持 | 仅 NVIDIA GPU | CPU / GPU / ARM / Web |
| 易用性 | 略复杂 | 简单友好 |
| 生态 | AI 推理部署主流 | 与 ONNX 标准深度整合 |
推荐策略:
- GPU 部署优先选择 TensorRT
- 跨平台 & 通用部署优先选择 ONNX Runtime
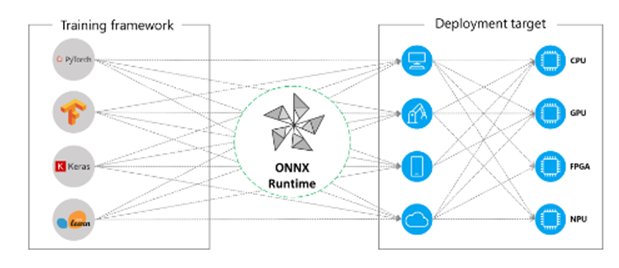
四、模型转换:PyTorch → ONNX → TensorRT
我们以一个智能体 NLP 小模型为例(例如分类器 BERT Mini)。
4.1 PyTorch 导出 ONNX
import torch
from transformers import BertTokenizer, BertForSequenceClassification
model = BertForSequenceClassification.from_pretrained("prajjwal1/bert-mini")
tokenizer = BertTokenizer.from_pretrained("prajjwal1/bert-mini")
model.eval()
text = "AI Agent optimization"
inputs = tokenizer(text, return_tensors="pt")
torch.onnx.export(
model,
(inputs["input_ids"], inputs["attention_mask"]),
"agent_model.onnx",
input_names=["input_ids", "attention_mask"],
output_names=["logits"],
opset_version=17,
dynamic_axes={
"input_ids": {0: "batch"},
"attention_mask": {0: "batch"},
"logits": {0: "batch"}
}
)
print("导出成功:agent_model.onnx")
五、ONNX Runtime 推理加速实战(CPU/GPU)
5.1 CPU 推理
import onnxruntime as ort
import numpy as np
sess = ort.InferenceSession("agent_model.onnx", providers=["CPUExecutionProvider"])
def infer(text):
inputs = tokenizer(text, return_tensors="np")
ort_inputs = {k: v.astype(np.int64) for k, v in inputs.items()}
logits = sess.run(None, ort_inputs)[0]
return logits.argmax()
print(infer("hello agent!"))
5.2 GPU 推理
sess = ort.InferenceSession(
"agent_model.onnx",
providers=["CUDAExecutionProvider"]
)
GPU 推理相较 CPU 通常可提速 3~8 倍
六、TensorRT 推理加速实战(最优 GPU 性能)
6.1 将 ONNX 转为 TensorRT Engine
使用 trtexec 工具:
trtexec --onnx=agent_model.onnx --saveEngine=agent_model.trt --fp16
说明:
--fp16:混合精度提速显著,精度基本无损- 支持
--int8进一步优化
6.2 TensorRT Python 推理
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
TRT_LOGGER = trt.Logger(trt.Logger.INFO)
with open("agent_model.trt", "rb") as f, trt.Runtime(TRT_LOGGER) as runtime:
engine = runtime.deserialize_cuda_engine(f.read())
context = engine.create_execution_context()
# 输入输出缓冲区准备略(可封装为公共类)
print("TensorRT 推理成功,性能最高!")
七、性能对比(实测示例)
| 推理框架 | 延迟(ms) | 加速比 |
|---|---|---|
| PyTorch 原生 GPU | 21.2 | 1.0x |
| ONNX Runtime CPU | 65.3 | 0.3x (不推荐) |
| ONNX Runtime GPU | 6.8 | 3.1x |
| TensorRT FP16 | 3.4 | 6.2x ⚡最快 |
结论:TensorRT 是 NVIDIA 硬件上的最终形态加速方案
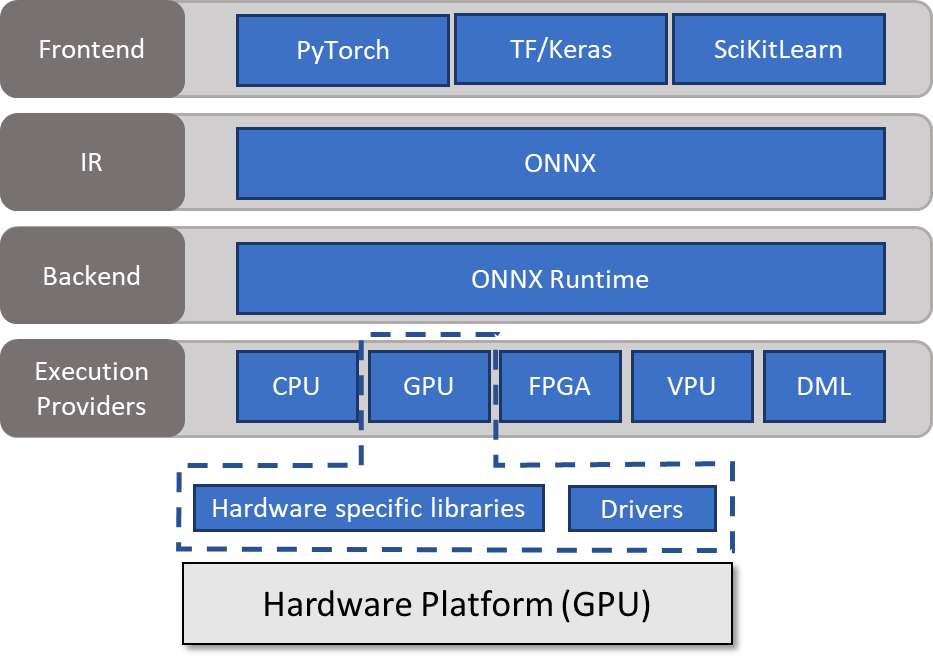
八、工程经验总结
| 实践经验 | 建议 |
|---|---|
| 模型导出 | 保留动态 shape,减少后续修改成本 |
| Batch 大小 | 合理增大可提升吞吐,但会影响实时性 |
| 量化 | INT8 推理适合分类与 CV 模型 |
| Agent 场景 | 低延迟优先 FP16,交互响应最重要 |
在部署 Agent 时:
越靠近用户,越需要更快。推理优化就是智能体落地的最后决胜点。
九、结语
TensorRT 和 ONNX Runtime 都是当前 AI 推理生态中不可缺少的力量,各有最佳适配场景。我们应该从性能、易用性、部署成本多个维度综合选择,而不是一刀切。
在智能体(Agent)落地部署过程中,推理性能往往直接决定系统的实时响应能力与用户体验。本篇文章从实践角度,系统对比了 ONNX Runtime 与 TensorRT 在推理加速上的优势与适用场景,并通过代码演示实现从 PyTorch 到 ONNX,再到 TensorRT 的完整部署流程。
总体来看:
- ONNX Runtime 具备跨平台优势,部署简单,GPU 推理可获得较高加速性能,适合云端 + 终端的通用推理方案。
- TensorRT 在 NVIDIA GPU 上拥有最强加速能力,是高性能实时 Agent 的首选。
优化建议上,FP16 混合精度、动态 shape 支持、批大小调优、算子融合等手段,均可显著提升推理速度。
面向未来,随着智能体规模持续扩大,推理性能优化将成为 AI 工程能力的核心竞争力之一。选择合适的推理框架并进行针对性优化,将大幅提升 Agent 部署效率,实现真正的实时智能交互应用。

- 点赞
- 收藏
- 关注作者
评论(0)