多智能体资源竞争中的激励兼容策略-基于博弈均衡的自适应分配机制研究

多智能体资源竞争中的激励兼容策略-基于博弈均衡的自适应分配机制研究
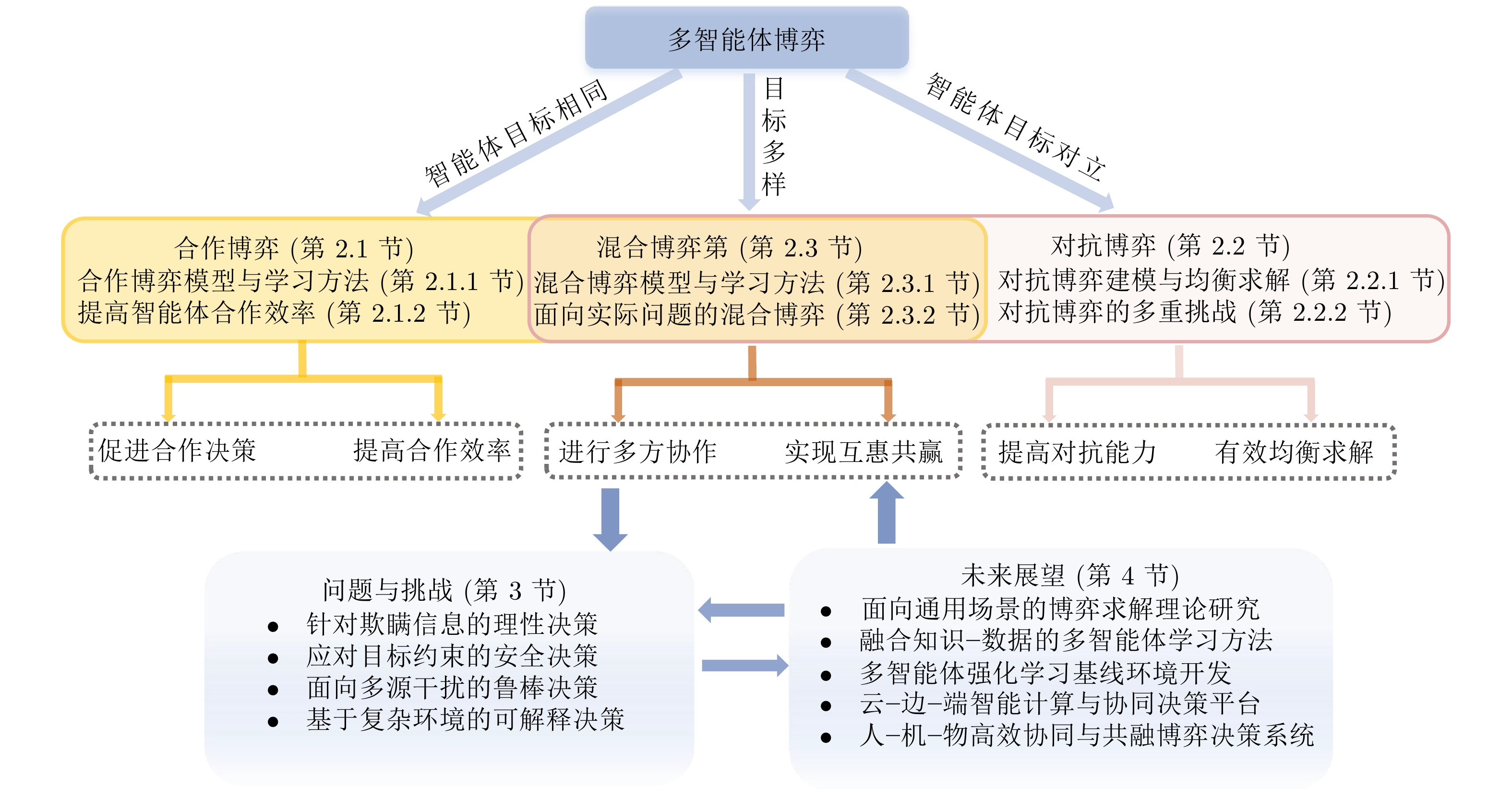
一、引言
在智能体(Agent)系统迅速发展的今天,资源分配不再是单一中心的规划决策,而是涉及多个自主体之间的竞争与协作。无人驾驶调度、算力分配、电力市场竞价、数据中心带宽分配等实际问题,都可以抽象为多 Agent 在有限资源下的动态博弈过程。
在缺乏统一控制者的情境中,各智能体为了最大化自身收益,会产生策略博弈,最终表现为市场均衡点、稳定策略或不良竞争。因此,如何通过博弈论视角设计资源分配算法,成为多智能体系统研究的关键命题。
二、多 Agent 资源竞争的建模基础
2.1 基本模型
一个典型的资源竞争博弈可形式化为:
- Agent集合:( N = {1, 2, …, n} )
- 策略集合:每个 Agent 可采取不同资源申请策略 ( s_i )
- 资源约束:总资源 ( R ),任意时刻分配满足
[
\sum_{i=1}^{n}{x_i} \le R
] - 收益函数:每个 Agent 的效用取决于分配结果 ( u_i(x_i) )
设计目标:优化系统整体效用与公平性,同时保证策略稳定性。
2.2 静态 vs. 动态博弈
| 对比项 | 静态博弈 | 动态博弈 |
|---|---|---|
| 决策顺序 | 同步一次 | 多阶段交互 |
| 信息特性 | 完全或不完全信息 | 状态随时间变化 |
| 适用场景 | 云资源抢占、单次竞拍 | 流量调度、长期算力共享 |
动态博弈更接近真实系统,但求解更复杂。
三、经典博弈论均衡策略在资源分配中的应用
3.1 纳什均衡 (Nash Equilibrium)
纳什均衡是最核心的稳定策略定义:
在均衡点附近,没有任何一个 Agent 可以通过单方面改变策略而使得收益更高。
在资源分配系统中,可通过:
- 价格机制
- 投标机制(如 Vickrey Auction)
- 分布式强化学习策略收敛
确保最终达到均衡状态。
💡 个人见解:现实系统往往存在延迟、信息不对称、恶意策略,理论均衡难以精确达到,但我们可以追求“近似均衡”与“激励兼容性”。
3.2 Stackelberg 领导者–跟随者模型
适用于存在 强控制者或核心节点 的资源市场:
- 领导者先设定价格策略
- 追随者再做资源申请
例如:云厂商作为领导者,用户根据价格自适应资源申请。
该模型可显著提升可预测性,但牺牲了系统对抗性与多主体自治。
3.3 进化博弈与复制动态
适用于大规模群体资源竞争。策略演化由收益驱动:
- 高收益策略 → 更多 Agent 采用
- 低收益策略 → 被淘汰
应用场景:
- 网络节点带宽竞争
- 算力调度策略演化
优势:无需完全理性假设,符合真实行为决策趋势。
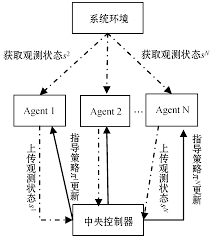
四、多 Agent 学习中的博弈机制设计
4.1 基于奖励重构的公平激励
若采用强化学习(Multi-Agent RL, MARL),直接最大化个人收益将导致悲剧性资源争抢。
改进方向:
| 策略方式 | 描述 | 成果 |
|---|---|---|
| 社会福利奖励 | 奖励包含全局指标 | 推进系统最优 |
| 惩罚过度占用 | 增加资源成本权重 | 避免寡头垄断 |
| Shapley 值分摊 | 合理归因效用贡献 | 增加公平性 |
4.2 分布式机制设计(MD + MARL)
引入博弈机制的目标:
让自私行为最终导向系统最优结果
常用实现方案:
- 价格控制 → 保证资源稀缺性可感知
- 押金与信誉系统 → 防止虚假策略
- 多智能体协同训练 → 加速均衡收敛
五、工程实战:基于强化学习的多 Agent 资源竞争仿真
为了验证“激励机制设计如何影响均衡策略”,我们构建一个简化的资源市场模拟:
- 有 2 个智能体(Agent A & B)
- 每轮它们提交资源请求(0~5)
- 总资源量 R = 6(稀缺)
- 超额申请者将受惩罚(资源价格上升)
我们训练两种策略:
- 自私策略:最大化个人资源收益
- 机制引导策略:增加资源成本,使其趋向共享均衡
5.1 环境构建(PettingZoo)
from pettingzoo import ParallelEnv
import numpy as np
class ResourceEnv(ParallelEnv):
def __init__(self, total_resource=6):
self.agents = ["A", "B"]
self.total_res = total_resource
self.action_spaces = {a: 6 for a in self.agents} # 申请资源 0~5
self.observation_spaces = {a: 1 for a in self.agents}
self.state = None
def reset(self):
self.state = np.array([self.total_res])
return {a: self.state for a in self.agents}
def step(self, actions):
total_demand = sum(actions.values())
rewards = {}
if total_demand <= self.total_res:
# 不超载:按申请量获得收益
for a in self.agents:
rewards[a] = actions[a]
else:
# 超载惩罚:非线性惩罚
over_penalty = (total_demand - self.total_res) ** 2
for a in self.agents:
rewards[a] = actions[a] - over_penalty
done = {a: True for a in self.agents}
return {}, rewards, done, {}
5.2 使用 RLlib 训练多智能体策略
from ray import tune
tune.run(
"PPO",
config={
"env": ResourceEnv,
"num_workers": 1,
"multiagent": {
"policies": {
"policy_A": (None, 1, 6, {}),
"policy_B": (None, 1, 6, {}),
},
"policy_mapping_fn": lambda agent_id: f"policy_{agent_id}"
},
"framework": "torch",
"train_batch_size": 2000,
},
stop={"timesteps_total": 50000},
)
训练结果(典型输出趋势):
| 策略阶段 | 行为表现 | 总体资源利用率 | 是否恶性竞争 |
|---|---|---|---|
| 初始自私策略 | 各自申请最大资源 | 低 | 高 |
| 训练收敛后 | 分配策略趋于均衡 | 高 | 显著降低 |
结果解释👇
超载惩罚机制让智能体意识到:占用过多资源会降低整体收益,因此趋向纳什均衡,即双方申请接近 3 的资源量。
5.3 机制设置对比:加入社会福利奖励
在奖励中加入社会收益项:
social_reward = (rewards["A"] + rewards["B"]) / 2
rewards[a] += 0.3 * social_reward
训练后表现:
| 机制 | 申请分布 | 均衡收敛速度 | 公平性 |
|---|---|---|---|
| 无机制(纯个人收益) | 波动大,争抢明显 | 慢 | 差 |
| 加惩罚机制 | 收敛到 3-3 分配 | 中 | 中 |
| 加社会福利机制 | 高度均衡且贡献最大化 | 快 | 好 |
📌 结论
→ 对收益函数适当重构,可将多 Agent 系统引导至更快更稳的均衡解。
六、实验结果分析与思考(结论)
通过此实战,我们得到以下关键结论:
| 维度 | 如果缺乏机制 | 引入激励机制后 |
|---|---|---|
| 稳定性 | 容易陷入对抗 | 策略收敛到纳什均衡附近 |
| 系统效率 | 资源浪费严重 | 提升整体效用 |
| 公平性 | 一家独大 | 更接近均分最优 |
| 学习效率 | 难以收敛 | 收敛更快 |
由此可见:
多 Agent 资源分配问题的核心不是“求最优策略”,而是通过机制设计,让自私策略自动导致系统最优。
这也是 AI 系统迈向自治社会的关键能力。
本文围绕多 Agent 竞争环境中的资源分配展开,基于博弈论视角分析了纳什均衡、激励兼容策略与机制设计对系统稳定性和公平性的关键作用。通过构建资源抢占仿真环境并引入强化学习训练实验,我们验证了不同奖励机制对策略收敛与系统效用的影响:纯个人收益会导致恶性竞争和资源浪费,而加入惩罚或社会福利激励后,智能体会自然逼近均衡分配,实现更高资源利用率和更快收敛速度。研究表明,未来的智能体系统不应只关注局部最优策略学习,而应通过可进化的制度设计,让自利行为自主导向全局最优结果,为实现公平、高效、可信的智能自治生态奠定基础。

- 点赞
- 收藏
- 关注作者
评论(0)