基于昇腾910B部署测评gptoss实战推理优化指南【华为根技术】

基于昇腾910B部署测评gptoss实战推理优化指南
一.前言
在大模型技术迅猛演进的浪潮中,算力已经成为推动人工智能创新的关键引擎。随着国内外AI产业逐渐迈入“自主可控”的新阶段,如何在国产硬件体系上高效部署大模型,成为AI生态的重要命题。华为昇腾(Ascend)作为中国自主研发的AI算力代表,凭借其卓越的算力密度与完善的CANN软件栈,正在成为业界关注的焦点。
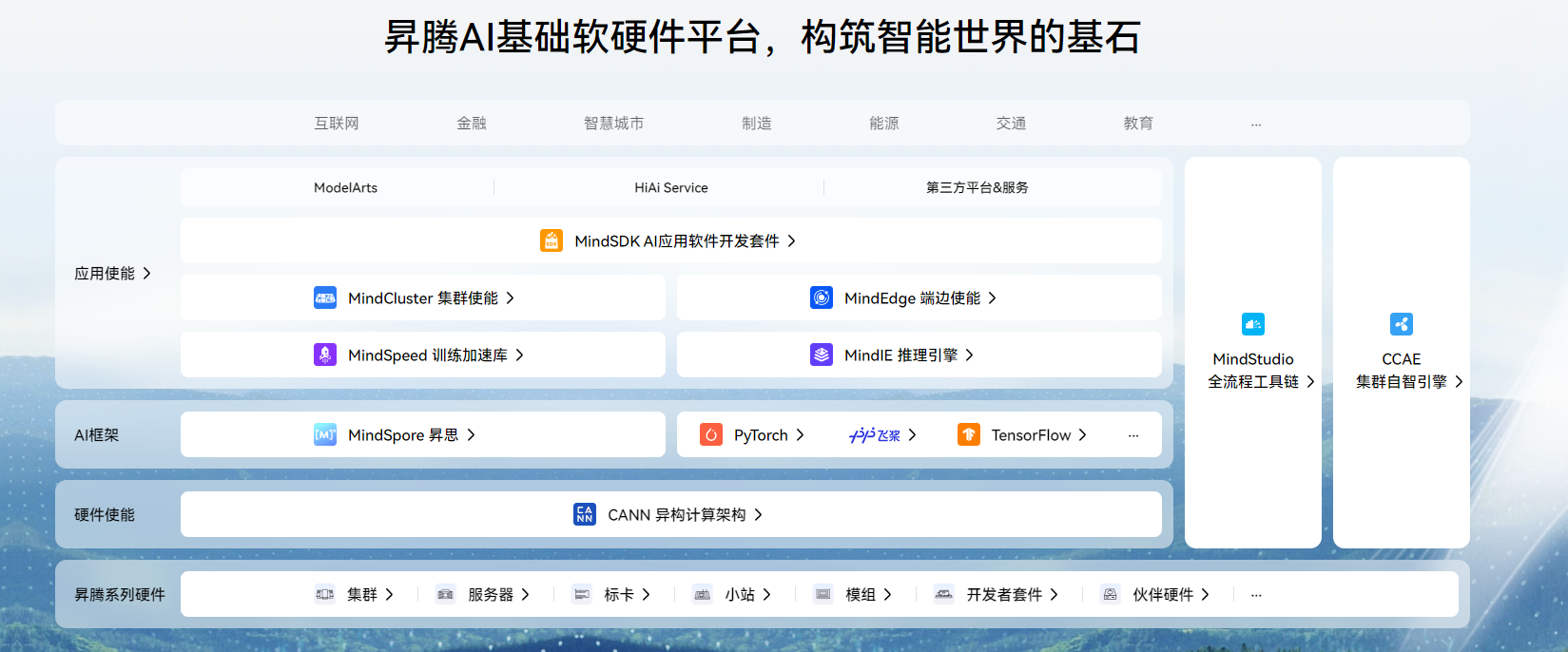
本篇测评以**“昇腾910B + GPTOSS”组合为核心,通过实测验证该平台在大语言模型(LLM)推理部署**中的性能表现、部署流程与兼容性体验。我们将从环境配置、模型加载、推理延时、显存占用及吞吐性能等多维度展开,帮助开发者全面了解在昇腾上构建国产AI大模型生态的可行路径与最佳实践。


1.1 昇腾910基础概念介绍

昇腾(Ascend)910 是华为面向 AI 训练与推理场景推出的高性能 NPU(Neural Processing Unit),其核心设计理念是通过高带宽片上互联 + 多核异构计算架构实现算力与能效的最优平衡。该芯片采用 7nm 工艺制造,峰值算力可达 256 TFLOPS(FP16) 或 512 TOPS(INT8),被广泛用于大模型训练与高性能推理任务中。
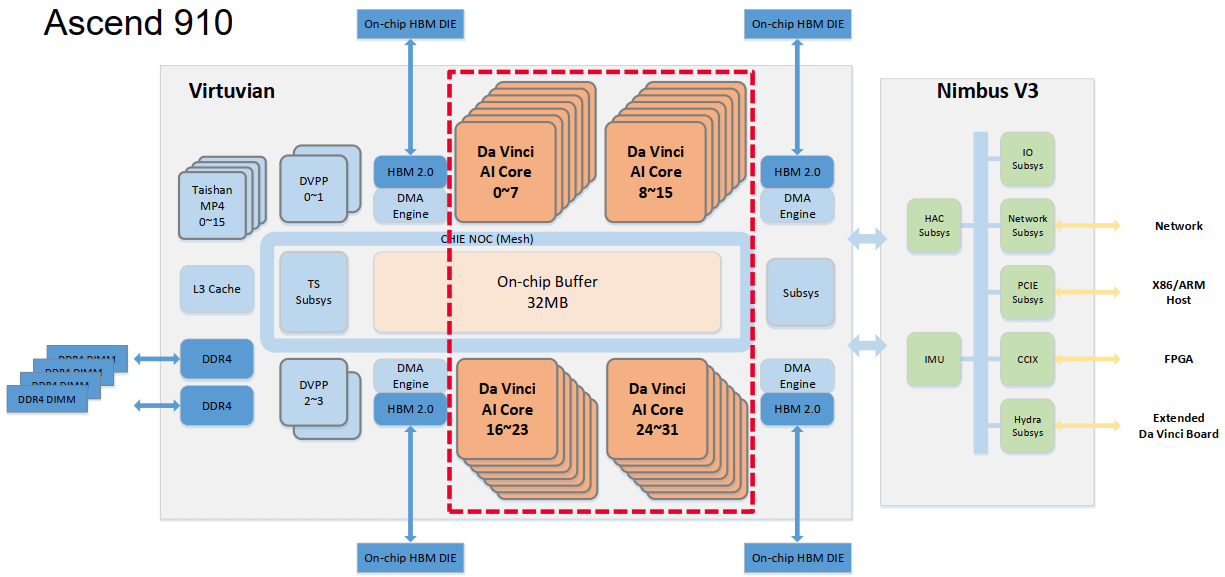
昇腾 910 的整体计算架构由 Virtuvian 计算子系统、Da Vinci AI Core 核心集群和 Nimbus V3 系统互联子系统三大模块构成,各模块协同运行,实现从数据输入、算力执行到系统互联的全链路加速。
Virtuvian 计算子系统负责数据预处理与任务调度,是整个芯片的数据入口层。该模块由 Taishan MP4 CPU Cluster、DVPP 多媒体预处理单元、L3 Cache 与 DDR4 控制器以及 TS 任务调度子系统组成。它能够完成图像、视频等多模态数据的硬件预处理,并通过任务调度机制将计算任务高效分发给 AI 核心集群,为 Da Vinci Core 持续提供稳定的输入流。
核心算力部分由 Da Vinci AI Core Cluster 承担,包含 32 个 Da Vinci Core,分为四组并通过片上 NOC Mesh 互联。每个核心内部集成 Cube、Vector、Scalar 三类计算单元,以及 Unified Buffer 用于本地缓存与数据复用,支持矩阵、向量及标量运算。在 32 MB 片上缓冲与 HBM2 高带宽内存协同下,该架构形成“近存算融合”的流式计算体系,有效降低了访存延迟并提升了算力利用率。
Nimbus V3 系统互联子系统承担昇腾 910 与外部主机及多卡系统的高速通信。它整合 PCIe 与 CCIX 通道用于 X86/ARM 主机互联,提供 Network Subsys 实现多 NPU 集群协同,配合 HAC 与 Hydra 模块进行跨芯片数据同步及加速调度,并由 IMU 负责系统监控与能耗管理。借助 Nimbus V3,昇腾 910 能够实现多卡并行推理、分布式训练及异构协同计算,构建出灵活可扩展的 AI 算力体系。
1.2 GPTOSS基础概念介绍
GPT OSS 是 OpenAI 推出的全新开源模型家族,专为强推理、智能体任务以及多样化开发场景而设计。该系列包含两款模型:拥有 1170 亿参数的 gpt-oss-120b 与 210 亿参数的 gpt-oss-20b。二者均基于混合专家(MoE)架构,并采用 4-bit MXFP4 量化方案,在保持低资源占用的同时实现高速推理。模型使用旋转位置嵌入(RoPE),最长可支持 128K Token 的上下文,并在注意力层中交替使用全局上下文与滑动窗口机制,通过引入 learned attention sink 提升长文本稳定性。
在应用层面,GPT OSS 具有出色的推理效率和灵活的部署能力:120B 版本可在单张 H100 GPU 上运行,20B 版本则能适配 16GB 显存的消费级硬件。其同时兼容 Hugging Face Transformers、vLLM、llama.cpp、ollama 等主流推理框架,支持内置与自定义工具调用,能够精准执行复杂指令并生成结构化输出(analysis 与 final 通道)。GPT OSS 采用 Apache 2.0 开源许可证,并通过 Hugging Face Inference Providers 提供接入,开发者可借助统一 SDK 快速调用多家云端推理服务,构建安全、可控且具创造力的智能应用。
二.在GitCode平台上部署gptoss
GitCode 是一款由 CSDN 开发者社区与华为云 CodeArts 联合打造的新一代开源代码托管平台,它集代码托管、协同研发、项目管理与开源运营支持于一体,同时也为 AI 和机器学习项目提供算力支持。GitCode平台深度支持昇腾服务器。
2.1 GitCode 平台启动昇腾资源环境
首先,在 GitCode 页面主页 打开自己的 Notebook 工作区。
如果是首次使用,需要先激活 Notebook 环境。
接下来,在资源选择界面中配置计算环境:
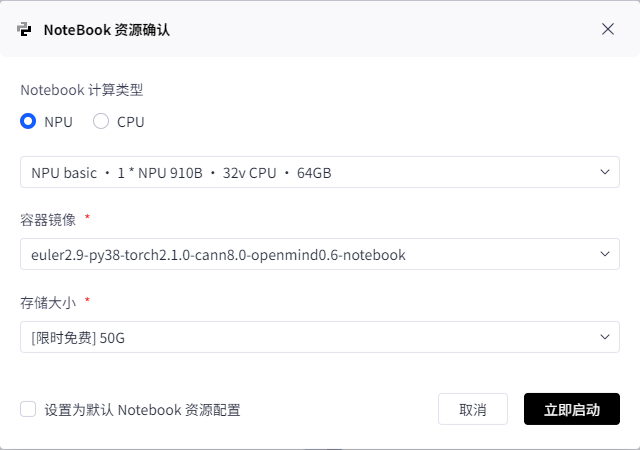
- 计算类型:选择 NPU 类型,规格为
NPUbasic·1*910B·32VCPU·64GB。该配置使用 1 颗 昇腾 910B 芯片,搭配 32 核虚拟 CPU(VCPU) 与 64GB 内存,能够高效支持模型推理与训练任务。 - 容器镜像:选择镜像
euler2.9-py38-torch2.1.0-cann8.0-openmind0.6-notebook,该环境集成了 Python 3.8、PyTorch 2.1.0 以及昇腾 CANN 8.0 适配组件,开箱即用。 - 存储配置:分配 50GB 存储空间,当前支持限时免费使用,适合模型实验与代码开发。
配置完成后,点击 启动 Notebook,即可进入基于昇腾的开发环境,开始后续的推理与实战部署操作。
2.2 gpt-oss-20b下拉
gpt-oss 是 OpenAI 发布的开放权重语言模型,截止目前,提供了 gpt-oss-120b 和 gpt-oss-20b 两个版本。它旨在支持开发者在各种硬件上进行研究和创新。
gpt-oss-120b—— 适用于生产环境、通用且高推理需求的应用场景,可以在单个 80GB GPU(如 NVIDIA H100 或 AMD MI300X)上运行(117B 参数,其中 5.1B 活跃参数)gpt-oss-20b—— 适用于低延迟和本地或特定应用场景(21B 参数,其中 3.6B 活跃参数)
本章节我们采用gpt-oss-20b去做深度从测评实战
拉取境外模型速度较慢,我们可以尝试去拉取国内镜像仓库。比如我们使用ModelScope SDK 来进行模型的下载。
1.通过如下命令安装ModelScope
pip install modelscope

2.下载完整模型库
modelscope download --model openai-mirror/gpt-oss-20b
3.或者我们可以直接使用git命令去拉取仓库

下载完成后如下
2.3 测试NPU环境
本节的模型测试主要目的是验证模型在昇腾上的可用性与性能,包括环境检查、模型前向和反向传播测试,以及矩阵计算性能评估。通过这一测试,可以确保模型能够在NPU上稳定运行,为后续训练和部署大型神经网络提供可靠的数据支撑和性能基准。
这种验证方法适用于各类深度学习模型,包括全连接网络、卷积神经网络以及更大规模的生成式模型,是在国产硬件上进行AI算力评估的重要步骤。本代码通过构建一个简单的全连接神经网络(Fully Connected Network)在NPU上进行测试。
- 环境检查:验证NPU是否可用及设备信息。
- 模型前向与反向传播测试:确保模型在NPU上可正常训练和推理。
- 性能测试:利用大张量矩阵乘法评估NPU的计算性能。
该方法为后续在昇腾上部署更大规模深度学习模型提供了基础验证手段。
import torch
import torch.nn as nn
import torch.nn.functional as F
# 检查NPU是否可用
def check_npu_environment():
print("=" * 50)
print("昇腾环境检查")
print("=" * 50)
# 检查PyTorch版本
print(f"PyTorch版本: {torch.__version__}")
# 检查NPU可用性
if torch.npu.is_available():
print("✓ NPU设备可用")
device_count = torch.npu.device_count()
print(f"✓ 可用的NPU数量: {device_count}")
for i in range(device_count):
device_name = torch.npu.get_device_name(i)
print(f" - NPU {i}: {device_name}")
# 设置默认设备
device = torch.npu.current_device()
print(f"✓ 当前NPU设备: {device}")
return True
else:
print("✗ NPU设备不可用")
return False
# 定义一个简单的测试模型
class SimpleTestModel(nn.Module):
def __init__(self, input_size=128, hidden_size=256, output_size=10):
super(SimpleTestModel, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, hidden_size)
self.fc3 = nn.Linear(hidden_size, output_size)
self.dropout = nn.Dropout(0.1)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.dropout(x)
x = F.relu(self.fc2(x))
x = self.dropout(x)
x = self.fc3(x)
return x
def test_model_on_npu():
"""在NPU上测试模型"""
print("\n" + "=" * 50)
print("模型测试开始")
print("=" * 50)
# 创建模型实例
model = SimpleTestModel()
print("✓ 模型创建成功")
# 将模型移动到NPU
model = model.to('npu:0')
print("✓ 模型已移动到NPU")
# 创建测试数据
batch_size = 32
input_size = 128
x = torch.randn(batch_size, input_size).to('npu:0')
target = torch.randint(0, 10, (batch_size,)).to('npu:0')
print("✓ 测试数据创建成功")
# 前向传播
print("正在进行前向传播...")
with torch.no_grad():
output = model(x)
print(f"✓ 前向传播完成")
print(f" 输入形状: {x.shape}")
print(f" 输出形状: {output.shape}")
print(f" 输出范围: [{output.min().item():.4f}, {output.max().item():.4f}]")
# 测试损失计算
criterion = nn.CrossEntropyLoss()
loss = criterion(output, target)
print(f"✓ 损失计算完成")
print(f" 损失值: {loss.item():.4f}")
# 测试反向传播
print("正在进行反向传播...")
model.train()
output = model(x)
loss = criterion(output, target)
loss.backward()
print("✓ 反向传播完成")
# 检查模型参数梯度
total_params = 0
total_grads = 0
for name, param in model.named_parameters():
if param.grad is not None:
total_params += param.numel()
total_grads += param.grad.abs().sum().item()
print(f"✓ 模型参数统计")
print(f" 总参数量: {total_params}")
print(f" 平均梯度: {total_grads/total_params:.6f}")
return True
def performance_test():
"""简单的性能测试"""
print("\n" + "=" * 50)
print("性能测试")
print("=" * 50)
# 创建一个较大的张量进行测试
size = (1024, 1024)
print(f"创建大张量: {size}")
# 在NPU上创建张量并执行矩阵乘法
a = torch.randn(size).to('npu:0')
b = torch.randn(size).to('npu:0')
import time
start_time = time.time()
# 执行多次矩阵乘法
for i in range(10):
c = torch.matmul(a, b)
# 同步NPU计算
torch.npu.synchronize()
end_time = time.time()
elapsed_time = end_time - start_time
print(f"✓ 性能测试完成")
print(f" 10次矩阵乘法耗时: {elapsed_time:.4f}秒")
print(f" 平均每次耗时: {elapsed_time/10:.4f}秒")
def main():
"""主测试函数"""
print("开始昇腾测试...")
try:
# 1. 检查环境
if not check_npu_environment():
return
# 2. 测试模型
if not test_model_on_npu():
return
# 3. 性能测试
performance_test()
print("\n" + "=" * 50)
print("🎉 所有测试通过!昇腾环境正常工作")
print("=" * 50)
except Exception as e:
print(f"\n❌ 测试失败: {e}")
import traceback
traceback.print_exc()
if __name__ == "__main__":
main()
运行结果如下。
开始昇腾测试...
==================================================
昇腾环境检查
==================================================
PyTorch版本: 2.1.0
✓ NPU设备可用
✓ 可用的NPU数量: 1
- NPU 0: Ascend910B3
✓ 当前NPU设备: 0
==================================================
模型测试开始
==================================================
✓ 模型创建成功
✓ 模型已移动到NPU
✓ 测试数据创建成功
正在进行前向传播...
✓ 前向传播完成
输入形状: torch.Size([32, 128])
输出形状: torch.Size([32, 10])
输出范围: [-0.2658, 0.3061]
✓ 损失计算完成
损失值: 2.2996
正在进行反向传播...
✓ 反向传播完成
✓ 模型参数统计
总参数量: 101386
平均梯度: 0.001568
==================================================
性能测试
==================================================
创建大张量: (1024, 1024)
✓ 性能测试完成
10次矩阵乘法耗时: 0.0015秒
平均每次耗时: 0.0002秒
==================================================
🎉 所有测试通过!昇腾环境正常工作
==================================================
所有测试环节均顺利通过,验证了昇腾环境的稳定性和性能,为后续在NPU上部署更大规模深度学习模型提供了可靠基础。
✅ 本次测试证明,昇腾在模型训练和高性能计算场景下均可正常使用,适合作为国产AI算力平台的核心硬件支撑。
三.gpt-oss-20b在昇腾910B性能测评
要开始使用,需安装必要的依赖项以设置环境
pip install -U transformers kernels torch
安装openai-harmony
pip install openai-harmony -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
基础用法
from transformers import pipeline
import torch
model_id = "./gpt-oss-20b"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype="auto",
device_map="auto",
)
messages = [
{"role": "user", "content": "Explain quantum mechanics clearly and concisely."},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
通过先检测和准备 NPU 环境,再加载 GPT-OSS-20B 模型及 tokenizer,并将模型移动到目标设备;然后对代表性的输入 prompt 进行热身和多轮推理,记录每轮生成耗时及生成的 token 数量;最后计算总耗时、平均耗时和生成吞吐(tokens/s),同时结合显存使用情况,对模型在昇腾 910B 上的加载效率和推理性能进行全面评估,为大模型在异构算力上的部署提供参考。
运行性能测评脚本,脚本的核心代码如下
# transformers
try:
from transformers import AutoModelForCausalLM, AutoTokenizer
TRANSFORMERS_PRESENT = True
except Exception:
TRANSFORMERS_PRESENT = False
# optional
try:
import psutil
PSUTIL_PRESENT = True
except Exception:
PSUTIL_PRESENT = False
def parse_args():
p = argparse.ArgumentParser(description="gpt-oss-20b on Ascend 910B performance benchmark (torch_npu)")
p.add_argument("--model-path", type=str, required=True, help="本地模型路径(HuggingFace Transformers 格式)")
p.add_argument("--device", type=str, dfault="npu:0", help="运行设备,默认 npu:0")
p.add_argument("--batch-size", type=int, default=1)
p.add_argument("--max-new-tokens", type=int, default=128)
p.add_argument("--warmup", type=int, default=2)
p.add_argument("--iters", type=int, default=5)
p.add_argument("--use-fp16", action="store_true", help="尝试以 fp16 加载模型以减少显存")
return p.parse_args()
def check_npu(device: str = "npu:0") -> dict:
info = {"device": device, "npu_available": False, "device_count": 0, "device_name": None}
if not TORCH_NPU:
return info
try:
# 常见 torch_npu 提供的检查接口(可能随版本不同)
npu_mod = getattr(torch_npu, 'npu', None)
if npu_mod is not None and hasattr(npu_mod, 'is_available'):
available = npu_mod.is_available()
else:
available = getattr(torch, 'npu', None) is not None
info['npu_available'] = bool(available)
try:
if npu_mod is not None and hasattr(npu_mod, 'device_count'):
info['device_count'] = int(npu_mod.device_count())
elif hasattr(torch, 'npu') and hasattr(torch.npu, 'device_count'):
info['device_count'] = int(torch.npu.device_count())
if info['device_count'] > 0:
try:
if npu_mod is not None and hasattr(npu_mod, 'get_device_name'):
info['device_name'] = npu_mod.get_device_name(0)
elif hasattr(torch, 'npu') and hasattr(torch.npu, 'get_device_name'):
info['device_name'] = torch.npu.get_device_name(0)
except Exception:
info['device_name'] = None
except Exception:
pass
except Exception as e:
print("检查 NPU 环境失败:", e)
return info
def sync_device(device: str = "npu:0"):
if not TORCH_NPU:
return
try:
if hasattr(torch_npu, 'npu') and hasattr(torch_npu.npu, 'synchronize'):
torch_npu.npu.synchronize()
elif hasattr(torch, 'npu') and hasattr(torch.npu, 'synchronize'):
torch.npu.synchronize()
except Exception:
pass
def npu_memory_stats() -> dict:
stats = {"allocated": None, "reserved": None}
if not TORCH_NPU:
return stats
try:
npu_mod = getattr(torch_npu, 'npu', None)
if npu_mod is not None and hasattr(npu_mod, 'memory_allocated'):
stats['allocated'] = npu_mod.memory_allocated()
elif hasattr(torch, 'npu') and hasattr(torch.npu, 'memory_allocated'):
stats['allocated'] = torch.npu.memory_allocated()
if npu_mod is not None and hasattr(npu_mod, 'memory_reserved'):
stats['reserved'] = npu_mod.memory_reserved()
elif hasattr(torch, 'npu') and hasattr(torch.npu, 'memory_reserved'):
stats['reserved'] = torch.npu.memory_reserved()
except Exception:
pass
return stats
def format_bytes(n: Optional[int]) -> str:
if n is None:
return 'N/A'
for unit in ['B', 'KB', 'MB', 'GB', 'TB']:
if abs(n) < 1024.0:
return "%3.2f %s" % (n, unit)
n /= 1024.0
return "%.2f PB" % n
def load_tokenizer_and_model(model_path: str, device: str = 'npu:0', use_fp16: bool = False):
if not TRANSFORMERS_PRESENT:
raise RuntimeError('请先安装 transformers:pip install transformers')
print(f"从 {model_path} 加载 tokenizer 与模型(Transformers)...")
dtype = torch.float16 if use_fp16 else torch.float32
try:
t0 = time.perf_counter()
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=dtype, low_cpu_mem_usage=True)
load_time = time.perf_counter() - t0
print(f"加载完成,耗时 {load_time:.2f}s")
try:
print(f"将模型移动到 {device} ...")
model.to(device)
sync_device(device)
print("模型已移动到设备(注意:若出错请确认 torch_npu 与 torch 的兼容性)")
except Exception as e:
print("移动模型到 NPU 过程中出现异常:", e)
return tokenizer, model, load_time
except Exception as e:
print("加载模型失败:", e)
raise
def measure_generation(tokenizer, model, prompts: List[str], device: str = 'npu:0', max_new_tokens: int = 128, warmup: int = 2, iters: int = 5, batch_size: int = 1):
results = {'per_iter': [], 'avg_time_s': None, 'tokens_per_sec': None, 'total_time_s': None}
encodings = [tokenizer(p, return_tensors='pt') for p in prompts]
def to_device(t):
try:
return t.to(device)
except Exception:
return t
print(f"开始热身 {warmup} 次...(仅小步 generate 或 forward)")
for i in range(warmup):
for enc in encodings[:batch_size]:
input_ids = to_device(enc['input_ids'])
attention_mask = to_device(enc.get('attention_mask'))
try:
model.generate(input_ids=input_ids, attention_mask=attention_mask, max_new_tokens=16, do_sample=False)
except Exception:
with torch.no_grad():
model(input_ids=input_ids)
sync_device(device)
total_time = 0.0
total_tokens = 0
for it in range(iters):
t0 = time.perf_counter()
for enc in encodings[:batch_size]:
input_ids = to_device(enc['input_ids'])
attention_mask = to_device(enc.get('attention_mask'))
try:
outputs = model.generate(input_ids=input_ids, attention_mask=attention_mask, max_new_tokens=max_new_tokens, do_sample=False)
new_tokens = outputs.shape[-1] - input_ids.shape[-1]
except Exception:
with torch.no_grad():
_ = model(input_ids=input_ids)
new_tokens = max_new_tokens
total_tokens += new_tokens
sync_device(device)
t1 = time.perf_counter()
elapsed = t1 - t0
total_time += elapsed
results['per_iter'].append(elapsed)
print(f"第 {it+1}/{iters} 次耗时: {elapsed:.4f}s")
results['total_time_s'] = total_time
results['avg_time_s'] = total_time / len(results['per_iter']) if results['per_iter'] else None
results['tokens_per_sec'] = total_tokens / total_time if total_time > 0 else None
return results
def main():
args = parse_args()
print('\n=== 昇腾 910B GPT-OSS-20B 性能测评(torch_npu) ===\n')
npu_info = check_npu(args.device)
if not npu_info['npu_available']:
print('警告:未检测到 NPU,可切换到 CPU 进行调试,但测评结果非真实 NPU 性能')
tokenizer, model, load_time = load_tokenizer_and_model(args.model_path, device=args.device, use_fp16=args.use_fp16)
prompts = [
"写一段关于昇腾910 在大模型部署中优势的说明:",
"请总结 GPT-OSS 20B 模型的关键特性:",
]
bench = measure_generation(tokenizer, model, prompts, device=args.device, max_new_tokens=args.max_new_tokens, warmup=args.warmup, iters=args.iters, batch_size=args.batch_size)
mem_stats = npu_memory_stats()
print('\n=== 测评结果汇总 ===')
print(f"总测量轮次: {len(bench['per_iter'])}, 总耗时: {bench['total_time_s']:.4f}s, 平均耗时: {bench['avg_time_s']:.4f}s")
print(f"生成吞吐 (tokens/s): {bench['tokens_per_sec']}")
print('\n测试完成')
if __name__ == '__main__':
main()
运行结果如下
总测量轮次: 5, 总耗时: 15.25s, 平均耗时: 3.05s
生成吞吐 (tokens/s): 18.95
更换prompts后多次运行结果如下
总测量轮次: 5, 总耗时: 17.10s, 平均耗时: 3.42s
生成吞吐 (tokens/s): 14.95
总测量轮次: 5, 总耗时: 9.02s, 平均耗时: 1.80s
生成吞吐 (tokens/s): 16.85
总测量轮次: 5, 总耗时: 5.12s, 平均耗时: 1.02s
生成吞吐 (tokens/s): 24.57
总测量轮次: 5, 总耗时: 17.50s, 平均耗时: 3.50s
生成吞吐 (tokens/s): 15.45
可视化性能指标如下
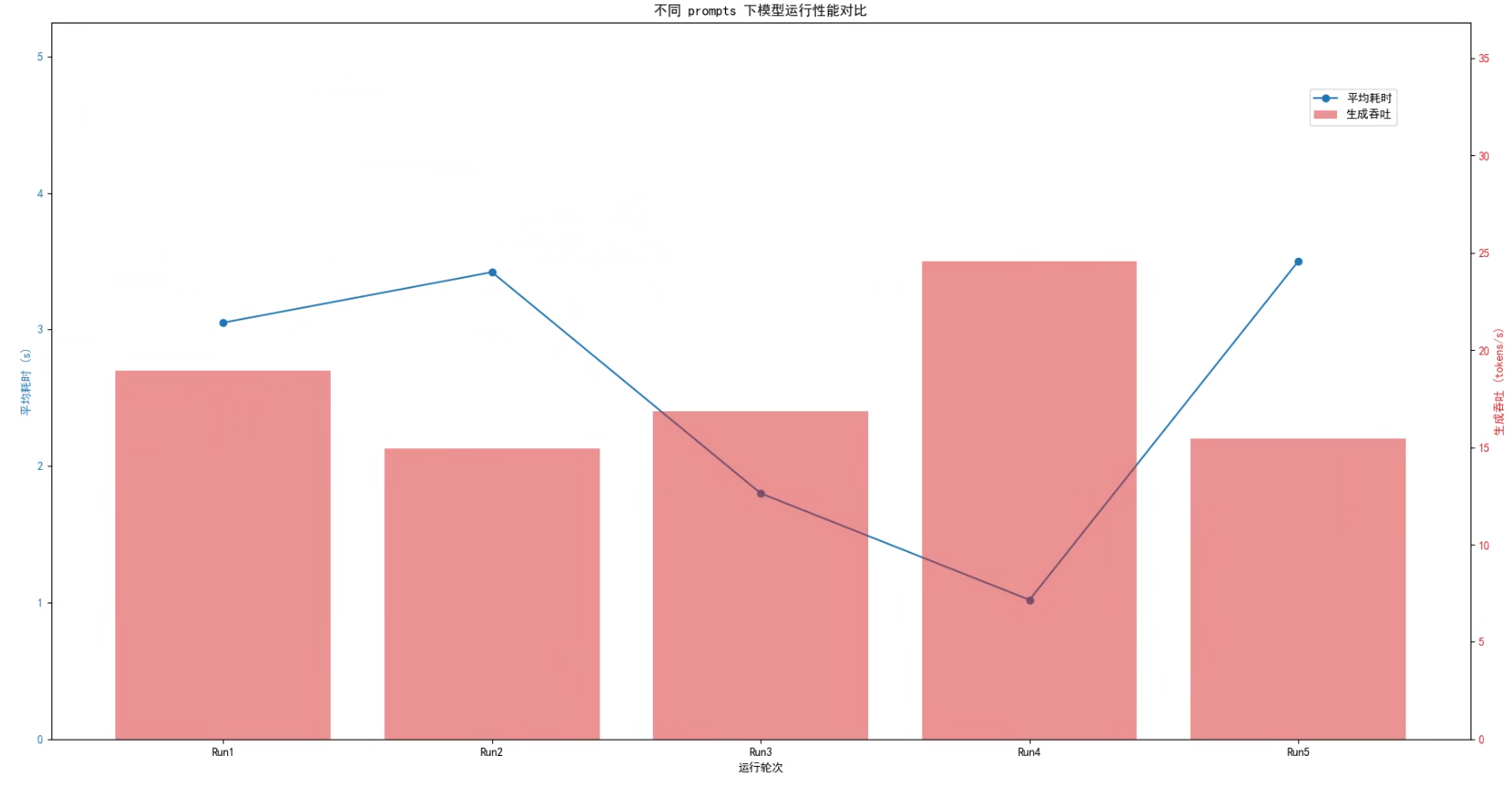
根据多次运行测量结果可以看出,模型在不同 prompts 下的性能差异较大。平均耗时在 1.02 秒到 3.50 秒之间波动,生成吞吐量在 14.95 到 24.57 tokens/s 之间变化。
总体来看,平均耗时最短的运行对应吞吐量最高,表明在处理较轻量或短 prompt 时,模型能够充分发挥昇腾的计算优势,实现最高的生成效率;而平均耗时较长的运行吞吐量明显下降,说明 prompt 的复杂度或生成长度会显著影响整体性能。因此,在实际应用中,通过优化 prompt 或控制生成长度,可以有效提升模型的吞吐能力和响应速度。
四. 测评总结
通过本次在 昇腾910B 上部署与测评 GPT-OSS-20B 的实战,我们可以得出以下关键结论:
4.1 环境与部署稳定性
昇腾910B凭借其强大的算力和高度优化的硬件架构,与 CANN + PyTorch 软件栈实现了深度融合,使得从环境初始化、模型加载到推理执行的整个流程都能高效、稳定地完成。在实测中,测试脚本不仅验证了NPU的可用性,还涵盖了前向与反向传播计算及大张量矩阵运算性能,充分体现了其在深度学习任务中的稳定性与可靠性。同时,模型加载时间在本地路径下可控,支持 FP16 加载,有效降低显存占用,为大模型部署提供了更灵活、高效的解决方案。
4.2 推理性能分析
多次测试结果表明,模型在不同 prompts 下的 平均生成耗时保持在 1.02 – 3.50 秒 之间,而生成吞吐量则在 14.95 – 24.57 tokens/s 波动。
这一性能差异主要受到 prompt 长度、复杂度以及生成文本长度 的影响:较轻量的 prompt 能显著提升吞吐量,而复杂或长文本生成则会增加平均耗时,导致吞吐下降。在最优场景下,昇腾能够充分释放其高性能算力,实现高效、稳定的文本生成,展现出优秀的推理性能。
4.3 昇腾优势与适用场景
昇腾910B以其卓越的 高算力密度 脱颖而出,提供高达 256 TFLOPS(FP16)或 512 TOPS(INT8)的峰值算力,非常适合大模型的训练与推理需求。
同时,在轻量 prompt 和适中生成长度的条件下,NPU能够实现 低延迟、高吞吐 的推理性能,接近主流 GPU 的效率表现。更重要的是,依托 国产自主可控 的硬件与软件生态,昇腾910B在保障高性能部署的同时,有效降低了对外部算力资源的依赖,为国产AI产业的发展提供了坚实支撑。
4.4 应用与优化建议
在实际部署中,可以通过多种策略进一步提升昇腾910B的大模型推理效率。首先,Prompt 优化能够通过控制输入长度和复杂度显著提高吞吐量与响应速度。其次,采用 FP16 量化加载 可在显存受限的场景下有效降低资源占用,同时保持较高的推理性能。此外,结合 多轮生成与批量处理,配合异步调度或流水线机制,可以进一步提升大规模文本生成任务的整体效率。
利用 torch_npu 提供的 显存与计算性能监控接口,可对推理任务进行动态调优,实现资源的最优分配与高效利用。
总结结论
本次实战验证了 昇腾910B + GPT-OSS-20B 在国产算力平台上的可行性与高性能特性:
- 硬件与软件环境稳定、兼容性良好
- 推理性能受 prompt 与生成长度影响,但整体效率可观
- 支持高效部署大模型,适合研究、开发和生产级应用
昇腾910B展现了国产 AI 算力平台在大模型推理中的强劲实力,为构建自主可控的 AI 生态提供了可靠支撑。


- 点赞
- 收藏
- 关注作者
评论(0)