智能体知识更新机制:增量式知识图谱构建与融合技术

【摘要】 智能体知识更新机制:增量式知识图谱构建与融合技术 一、引言随着大模型驱动的 智能体(Agent) 在企业业务、搜索问答、自动化运营、RPA 流程中广泛应用,知识更新问题变得尤为突出。传统知识库构建方式往往是“全量构建”,一旦知识发生变化,需要重新爬取、处理、训练或重建索引,成本高且不可实时。而智能体需要:识别新知识是否已存在将新知识增量式注入知识图谱自动融合冲突信息实时影响推理过程不中断系...
智能体知识更新机制:增量式知识图谱构建与融合技术
一、引言
随着大模型驱动的 智能体(Agent) 在企业业务、搜索问答、自动化运营、RPA 流程中广泛应用,知识更新问题变得尤为突出。
传统知识库构建方式往往是“全量构建”,一旦知识发生变化,需要重新爬取、处理、训练或重建索引,成本高且不可实时。
而智能体需要:
- 识别新知识是否已存在
- 将新知识增量式注入知识图谱
- 自动融合冲突信息
- 实时影响推理过程
- 不中断系统运行
因此,“增量式知识图谱构建与融合(Incremental KG Construction & Fusion)”成为智能体落地的核心能力之一。
本文系统介绍智能体的增量知识更新体系,并提供一个 Python 版知识图谱增量构建代码实战。
二、智能体知识更新机制概述
2.1 三类知识更新模式
| 更新模式 | 特点 | 适用场景 |
|---|---|---|
| 全量更新(Full Rebuild) | 一次性重建全部知识 | 小型知识库、结构稳定 |
| 批次更新(Batch Update) | 定期增量、按批次更新 | 中型知识库、更新频率适中 |
| 实时增量更新(Incremental Update) | 每条知识都实时更新并融合 | 智能体实时问答、监控、自动决策 |
智能体通常需要 实时增量 模式。
三、增量式知识图谱构建流程
完整流程如下:
新数据流入 → 信息抽取 → 知识对齐/消歧 → 图谱增量更新 → 冲突融合 → 推理索引更新
3.1 信息抽取(NER / RE)
智能体通过 LLM 或规则抽取:
- 实体(Entity)
- 关系(Relation)
- 属性(Attribute)
例如从文本 “张三是华为的软件工程师” 中抽取:
{
"entity": ["张三", "华为"],
"relation": [
["张三", "就职于", "华为"],
["张三", "职位", "软件工程师"]
]
}
3.2 知识对齐与消歧(Entity Alignment)
智能体判断新实体是否已存在:
- 文本相似度
- 语义向量距离
- 属性匹配(公司、邮箱、ID)
例如“华为技术有限公司” ≈ “华为”。
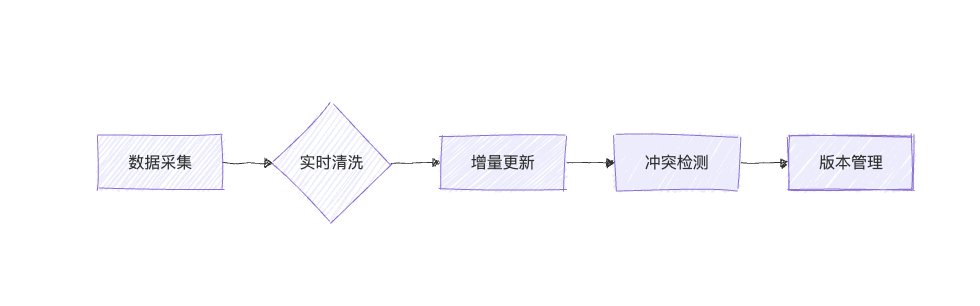
3.3 图谱增量更新(Graph Update)
增量更新关键技术:
- 节点重复检测(Duplicate Check)
- 关系冲突解决(Conflict Resolution)
- 时间戳与版本管理(Versioning)
3.4 冲突融合(Knowledge Fusion)
三类融合方式:
| 融合类型 | 特点 |
|---|---|
| 优先级融合 | 权重高的知识覆盖低权重 |
| 证据投票 | 多来源数据投票决定可信度 |
| 时间序列融合 | 新知识覆盖旧知识 |
四、系统架构设计
一个典型的智能体增量知识图谱系统包含:
┌──────────────┐
Data Source → │ 信息抽取模块 │→ 实体/关系
└──────────────┘
↓
┌──────────────┐
│ 对齐/消歧模块 │
└──────────────┘
↓
┌────────────────┐
│ 图谱增量更新模块│
└────────────────┘
↓
┌──────────────┐
│ 冲突融合模块 │
└──────────────┘
↓
┌──────────────┐
│ 查询与推理层 │
└──────────────┘
五、代码实战:基于 NetworkX 构建简易增量知识图谱系统
本示例将展示:
- 如何增量加入实体与关系
- 如何处理重复实体
- 如何自动融合更新属性
使用 Python + NetworkX 进行模拟(真实系统可用 Neo4j / ArangoDB / Nebula / RDF)。
5.1 安装依赖
pip install networkx
5.2 基础图谱骨架
import networkx as nx
class KnowledgeGraph:
def __init__(self):
self.graph = nx.MultiDiGraph()
# 增量添加实体
def add_entity(self, entity_id, attrs):
if entity_id not in self.graph:
self.graph.add_node(entity_id, **attrs)
else:
# 属性融合:新属性覆盖旧属性
existing = self.graph.nodes[entity_id]
existing.update(attrs)
# 增量添加关系
def add_relation(self, src, relation, dst):
self.graph.add_edge(src, dst, relation=relation)
# 打印图谱
def show(self):
for node in self.graph.nodes(data=True):
print("Node:", node)
for edge in self.graph.edges(data=True):
print("Edge:", edge)
5.3 增量知识注入(含消歧与融合)
定义:基于相似度判断是否需要复用节点。
实战中通常采用 embedding(如 BERT)计算语义相似度,本示例用简单字符串相似度作演示。
from difflib import SequenceMatcher
def similar(a, b):
return SequenceMatcher(None, a, b).ratio()
智能体增量更新逻辑
class IncrementalAgent:
def __init__(self, kg: KnowledgeGraph, threshold=0.7):
self.kg = kg
self.threshold = threshold
# 简单的实体对齐
def align_entity(self, new_name):
for exist in self.kg.graph.nodes:
if similar(exist, new_name) > self.threshold:
return exist
return new_name
# 增量注入一条知识
def inject(self, entity, attrs, relation, target):
# 实体消歧
entity_id = self.align_entity(entity)
target_id = self.align_entity(target)
# 写入实体(自动融合属性)
self.kg.add_entity(entity_id, attrs)
self.kg.add_entity(target_id, {})
# 写入关系
self.kg.add_relation(entity_id, relation, target_id)
5.4 测试增量更新代码
kg = KnowledgeGraph()
agent = IncrementalAgent(kg)
# 第一条知识
agent.inject("华为", {"type": "Company"}, "雇佣", "张三")
agent.inject("张三", {"title": "软件工程师"}, "就职于", "华为")
# 第二条知识(同实体不同写法,会自动对齐到“华为”)
agent.inject("华为技术有限公司", {"location": "深圳"}, "旗下", "荣耀")
# 第三条知识(属性融合:覆盖/新增属性)
agent.inject("张三", {"title": "高级工程师"}, "参与项目", "Atlas 900")
kg.show()
5.5 运行结果示例(示意)
Node: ('华为', {'type': 'Company', 'location': '深圳'})
Node: ('张三', {'title': '高级工程师'})
Node: ('荣耀', {})
Node: ('Atlas 900', {})
Edge: ('华为', '张三', {'relation': '雇佣'})
Edge: ('张三', '华为', {'relation': '就职于'})
Edge: ('华为', '荣耀', {'relation': '旗下'})
Edge: ('张三', 'Atlas 900', {'relation': '参与项目'})
可以看到:
- “华为技术有限公司” 自动对齐到 华为
- 张三 的 title 属性被融合并更新为 “高级工程师”
- 图谱结构实现增量式扩展
六、增量知识融合中的技术难点
6.1 消歧精度与误判
需结合:
- 文本相似度
- Embedding 语义距离
- RDF 属性匹配
- 图结构上下文
6.2 知识冲突处理
常见冲突:
- 属性冲突
- 时间冲突
- 数据来源可信度冲突
6.3 图谱规模增长与性能
百万级节点后需考虑:
- 图数据库索引优化
- 分布式图存储
- 流式写入(Streaming Write)
七、典型应用场景
| 场景 | 描述 |
|---|---|
| 企业知识库实时更新 | 文档、FAQ、规范持续变化 |
| 实时监控智能体 | 新事件即时写入并触发推理 |
| 金融风控图谱 | 客户/交易/风险节点实时更新 |
| RAG Agent 知识补全 | 外部知识动态扩展 |
| 推荐系统用户画像 | 用户行为增量更新 |
八、总结
增量式知识图谱是智能体从“静态问答”迈向“持续进化”的关键能力。
本文从架构、流程、关键技术、冲突融合等角度展开,同时提供了一个可运行的 增量图谱构建与融合代码案例。
未来方向包括:
- 融合 RAG 与 KG 的混合检索
- 大模型驱动的自动消歧
- 事件图谱(Event Graph)实时流处理
- 图谱 + 大模型联合推理

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)