Java 实现可靠的 WAV 音频拼接:从结构解析到完整可播放的高质量合并方案

Java 实现可靠的 WAV 音频拼接:从结构解析到完整可播放的高质量合并方案
在音频相关的应用中,我们经常会接触到音频片段拼接的需求,例如:
- 文本转语音(TTS)平台将多段语音按段落拼合成完整音频;
- 语音导航系统需要按场景拼接提示音;
- 教育类产品中,将词音、释义、例句等片段组合成自然流畅的讲解音频;
- 录音编辑工具中对多个录音片段进行整合处理。
乍看之下,把多个 WAV 文件简单拼接似乎只是“把数据追加在一起”。但如果处理不当,就会出现一些典型问题:
| 问题现象 | 表现内容 |
|---|---|
| 播放异常 | 播放器只能播放第一段,后续内容消失 |
| 时间显示错误 | 播放器显示音频总时长为 0 秒或明显不对 |
| 声音失真或变速 | 合并后声音更快、变慢或音量变化不一致 |
| 文件无法识别 | 播放软件直接报错或者无法打开 |
这些问题的根本原因,往往不在音频本身,而在于 WAV 文件头和块结构没有被正确处理。
本章完整代码
📦 完整实现代码,之前已经在下面这篇文章内写过了,需要我的完整封装好的代码,可支持下面文章。
(包含完整类定义、异常处理与日志输出逻辑)
到下面文章中获取,亲测完整代码,可运行,目前没有发现bug,运行良好。
https://blog.csdn.net/weixin_52908342/article/details/154193622
一、深入理解 WAV 文件的结构
WAV 属于 RIFF (Resource Interchange File Format) 文件格式,这是一种由多个 Chunk(数据块) 组成的层级结构。
一个典型且最简单的 WAV 文件结构如下:
RIFF Header
└─ "fmt " Chunk(描述音频格式)
└─ "data" Chunk(原始音频数据)
但在 实际场景 中,很多 WAV 会包含额外的数据块,比如:
| 块名 | 作用解释 |
|---|---|
| LIST | 存放音乐元信息,如标题、艺术家、注释 |
| INFO | 更细化的记录属性信息 |
| JUNK | 占位/对齐块,为了对齐数据或者填充文件大小 |
| fact | 某些压缩格式下音频帧统计数 |
因此一个真实 WAV 文件结构可能是:
RIFF
└─ WAVE
├─ fmt (音频格式信息)
├─ LIST (可选元数据)
├─ JUNK (可选占位数据)
├─ fact (可选,压缩音频)
└─ data (真实 PCM 音频数据)
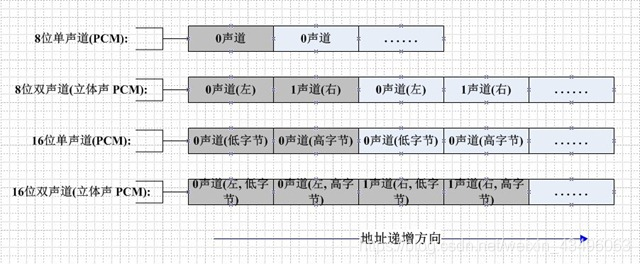
⚠ 关键点:
data 块的位置不固定,大小也不固定
因此,不能依赖“音频数据从第 44 字节开始”这种假设。
许多拼接失败,正是因为 错误地认为音频数据一定从 44 字节位置开始。
二、为什么会出现播放异常?
假设我们直接固定偏移读取音频数据,例如:
从第 44 字节读取剩余数据作为 PCM 数据
如果被处理的音频中包含 LIST 或 JUNK 块,则:
44 字节 ~ data 块之间 = 非音频信息
这些非音频内容被“当作音频写入”,就会导致:
| 影响 | 说明 |
|---|---|
| PCM 数据错位 | 导致播放出现噪声或破音 |
| 播放器无法识别真实 data 大小 | 导致显示时长异常或仅播放一段 |
| 文件结构损坏 | 播放器直接无法打开 |
因此,要正确拼接 WAV 文件,必须做到:
✅ 正确定位 data 块
✅ 正确累加 data 块长度
✅ 正确回写 RIFF 和 data 的长度字段
三、可行且鲁棒的 WAV 拼接策略

步骤 1:读取每个文件并逐块扫描
从音频文件第 12 字节(跳过 “RIFFxxxxWAVE”)开始:
循环读取 ChunkHeader (8 字节)
│
├─ 如果 ChunkID == "data" → 记下 data 的偏移位置和大小
└─ 否则 → 跳过该块的内容继续查找
这样可以确保:
- 不会把 LIST、JUNK、INFO 等扩展内容误当作音频数据
- 可以处理不同来源、不同结构的 WAV 文件
步骤 2:第一个文件写头部,其余文件只写数据
第一个文件:
- 保留 RIFF、fmt、可能存在的 LIST / JUNK 等块
- 但暂时不回写 data 块大小字段
后续文件:
- 只写 data 块的 PCM 数据部分
步骤 3:累加所有 data 块的真实长度
合并结束后,需要根据累加结果:
| 字段位置 | 更新值 |
|---|---|
| RIFF ChunkSize (偏移 4) | 总文件大小 - 8 |
| data Subchunk2Size | 所有音频数据长度之和 |
否则播放器会认为:
音频数据为 0 → 时长为 0 → 播放时只播放开头
四、效果验证与对比说明
假设有 3 个音频片段:
| 文件 | 时长 | 备注 |
|---|---|---|
| 01.wav | 2.1s | 单声道,44.1kHz |
| 02.wav | 3.4s | 格式一致 |
| 03.wav | 1.7s | 格式一致 |
拼接完成后:
✔ 播放顺序完整连贯
✔ 音质一致且没有卡顿或杂音
✔ 播放器显示总时长 ≈ 7.2 秒
✔ WaveLab、Audition、GoldWave 等软件均可正常打开与编辑
五、使用时注意事项
为了确保音频合并后质量一致,所有音频的参数必须一致:
| 参数名称 | 推荐一致性要求 |
|---|---|
| 采样率 | 44100 Hz / 48000 Hz 等 |
| 声道数 | 单声道 / 双声道必须一致 |
| 采样位宽 | 16-bit / 24-bit 必须一致 |
| 编码格式 | 必须为 PCM(AudioFormat = 1) |
如果参数不一致,应先做格式转换,否则音频会:
- 播放变快或变慢
- 左右声道不匹配导致声场错乱
- 振幅不一致导致出现突兀音量变化
六、总结
通过正确解析 WAV 文件内部结构,动态定位 data 块并更新头部,我们实现了一个:
- 稳定
- 通用
- 可大规模批处理
- 无需依赖第三方工具
- 能够处理实际复杂 WAV 文件
的音频拼接方案。
WAV 拼接表面上是一项简单的字节追加操作,但真正影响播放效果的核心在于 正确处理文件的块结构和头部信息。只有动态识别 data 块的位置、准确累计实际音频数据长度,并在合并完成后重写 RIFF 和 data 的长度字段,才能确保播放器在播放过程中能够正确识别完整音频。通过本次实践,我们从常见的“时长显示为 0、只能播放一段、拼接后出现杂音”等典型问题入手,逐步分析原因并构建了一个 通用、稳定、可扩展 的 WAV 拼接方案。该方法不仅适用于简单音频合并,也可为语音合成、录音编辑、自动播报生成等业务提供坚实基础。理解格式本身,往往比直接使用工具更重要。音频处理不是盲目操作字节,更是对数据结构的精准把控。

- 点赞
- 收藏
- 关注作者
评论(0)